

新智元报道
新智元报道
【新智元导读】李飞飞、谢赛宁团队又有重磅发现了:多模态LLM能够记住和回忆空间,甚至内部已经形成了局部世界模型,表现了空间意识!李飞飞兴奋表示,在2025年,空间智能的界限很可能会再次突破。

论文地址:https://arxiv.org/abs/2412.14171
这些测试,大模型被人类完败







多模态大模型已经展现出空间思维
毫无疑问,视频理解就是下一个前沿领域,然而,并非所有视频都是相似的。 现在,模型还可以根据YouTube剪辑和故事片进行推理,但对于日常生活中的空间,我们以及未来的AI助手能够作何应对呢? 为此,谢赛宁团队进行了一项最新研究,探索多模态大语言模型(MLLM)如何感知、记忆和回忆空间的。 

在视觉领域,我们人类能够处理空间,却很少进行推理;而多模态大语言模型则善于思考,却往往忽略了空间逻辑。 
然而,对于人类来说,无论是参加心理旋转测试,还是为新家挑选家具,我们都极度依赖于空间和视觉思维,而这种思维方式,却并不总能很好地转化为文字。 

视频是一种自然媒介,反映了我们体验世界的方式,并且需要更长形式的推理,以及世界建模。 为了探索这一点,团队研究了涵盖各种视觉空间智能任务(包括关系和度量任务)的新基准。 所以,这个过程是如何获取数据和注释的呢?团队在之前CV工作的基础上,重新利用了已有的空间扫描视频(起初是用于3D重建),使用其真实注释来自动生成VQA问题。 同时,人类仍然参与其中,进行质量控制。 
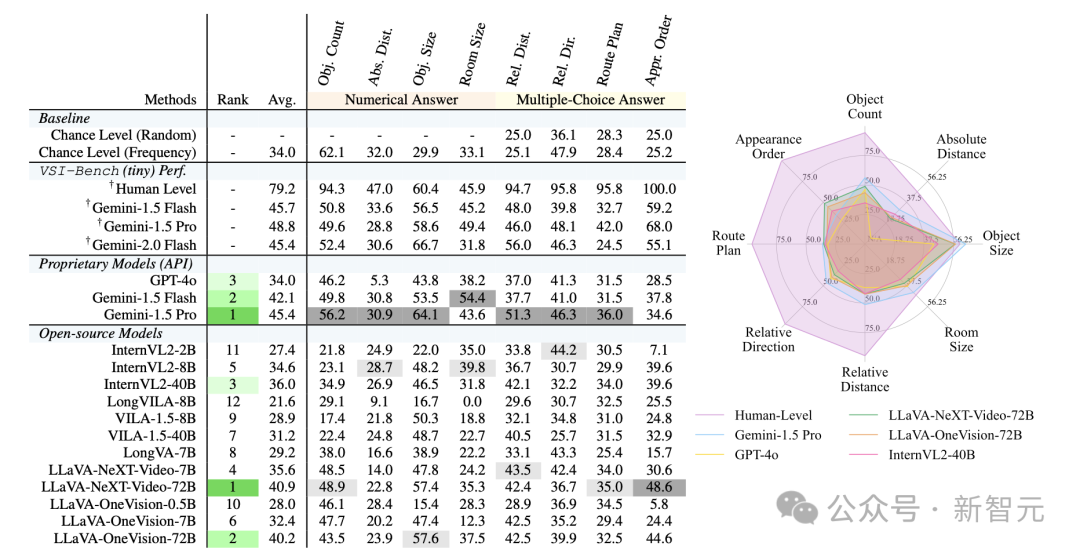
超过5000个问答对显示,MLLM居然展现出了具有竞争力的视觉空间智能! 其中,Gemini Pro的表现最为亮眼。 当然,它们仍然和人类存在差距。 这些任务对人类而言也并非易事(毕竟,我们自己也经常迷路),不过,人类会通过调整和优化自己的心智模型来适应,而目前的LLM,暂时还无法做到这一点。 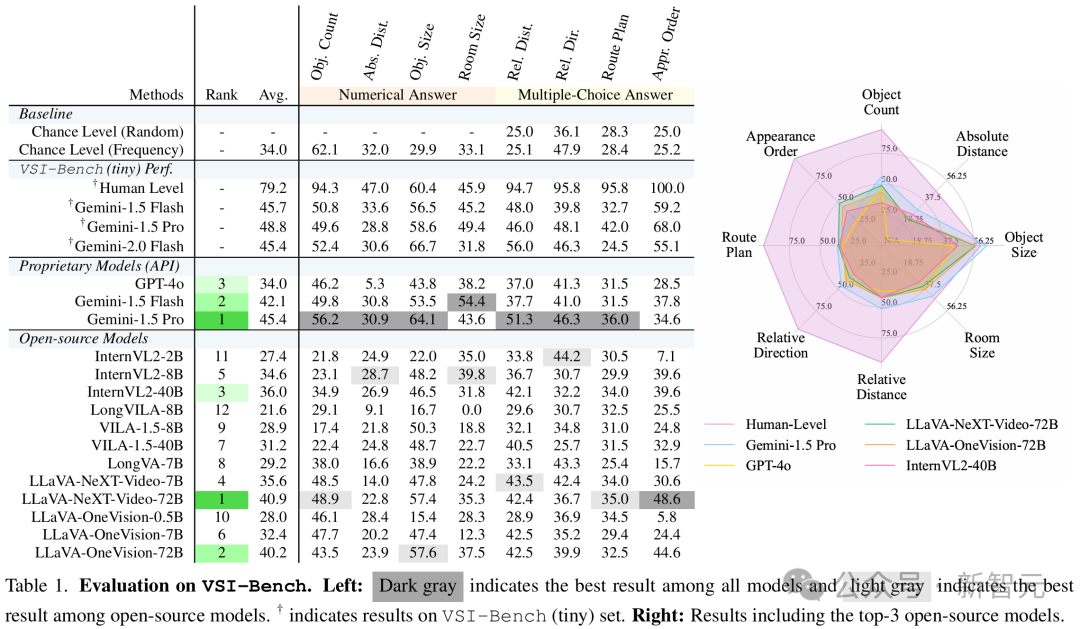
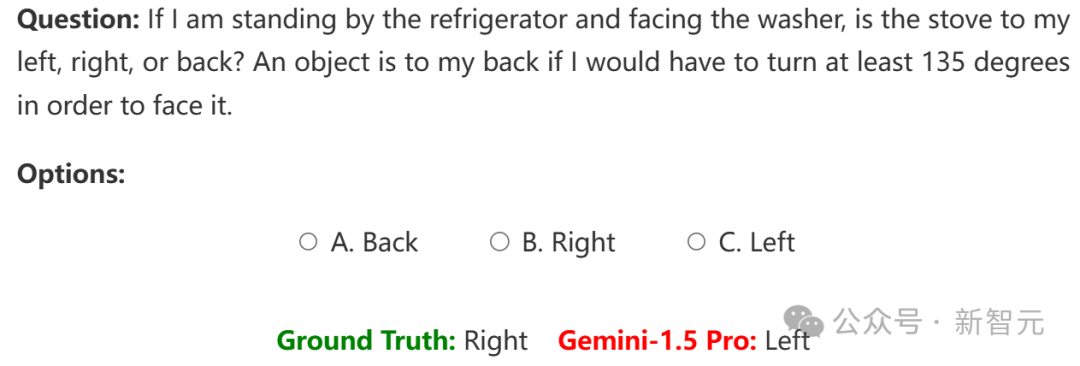
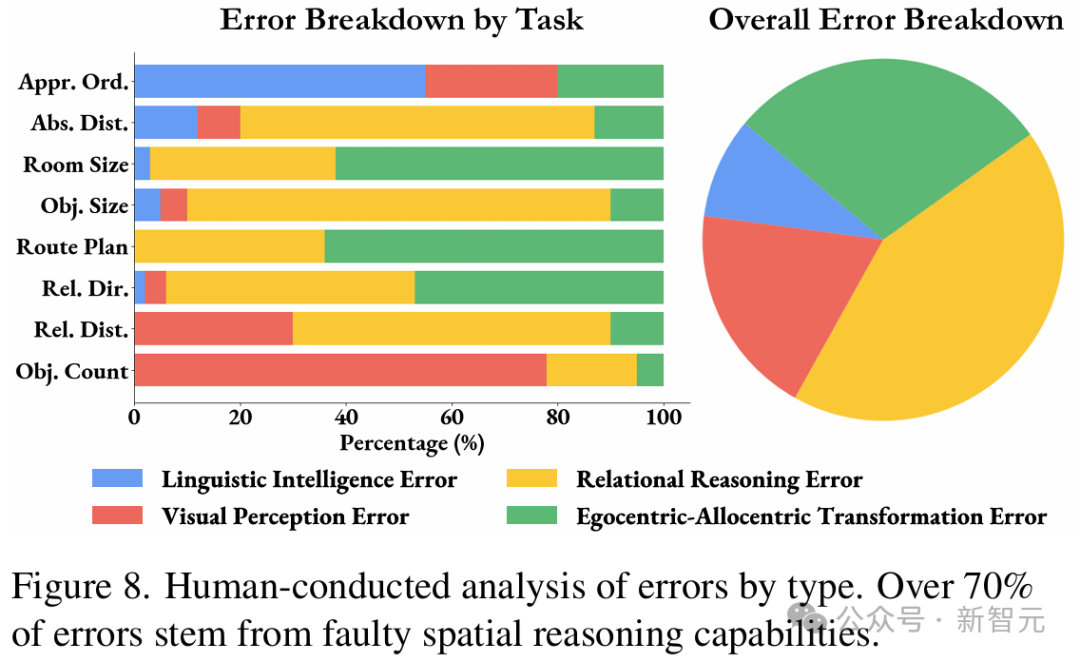
谢赛宁表示,自己在研究中最喜欢的部分,就是分析这些任务跟以语言为中心的智能有多么不同。 当被要求解释自己的推理过程时,LLM就暴露出了自己的弱点:空间推理是它们的主要瓶颈,而非物体识别或语言能力。 在换位思考、第一到客观视角的转变上,它们通常表现得极其困难,并且在更长时间的推理过程中,容易失去对物体的追踪。 
团队的另一个发现是,语言提示技术在这一领域并不奏效——像CoT或多数投票等方法,居然对任务产生了负面影响! 然而,这些技术在一般的视频分析任务(如VideoMME)中,却是很有效的。 这就再次突显出一个重要区别:并非所有视频都是相同的,理解电影情节这样的任务更多依赖于基于语言的智能,而非视觉空间智能。 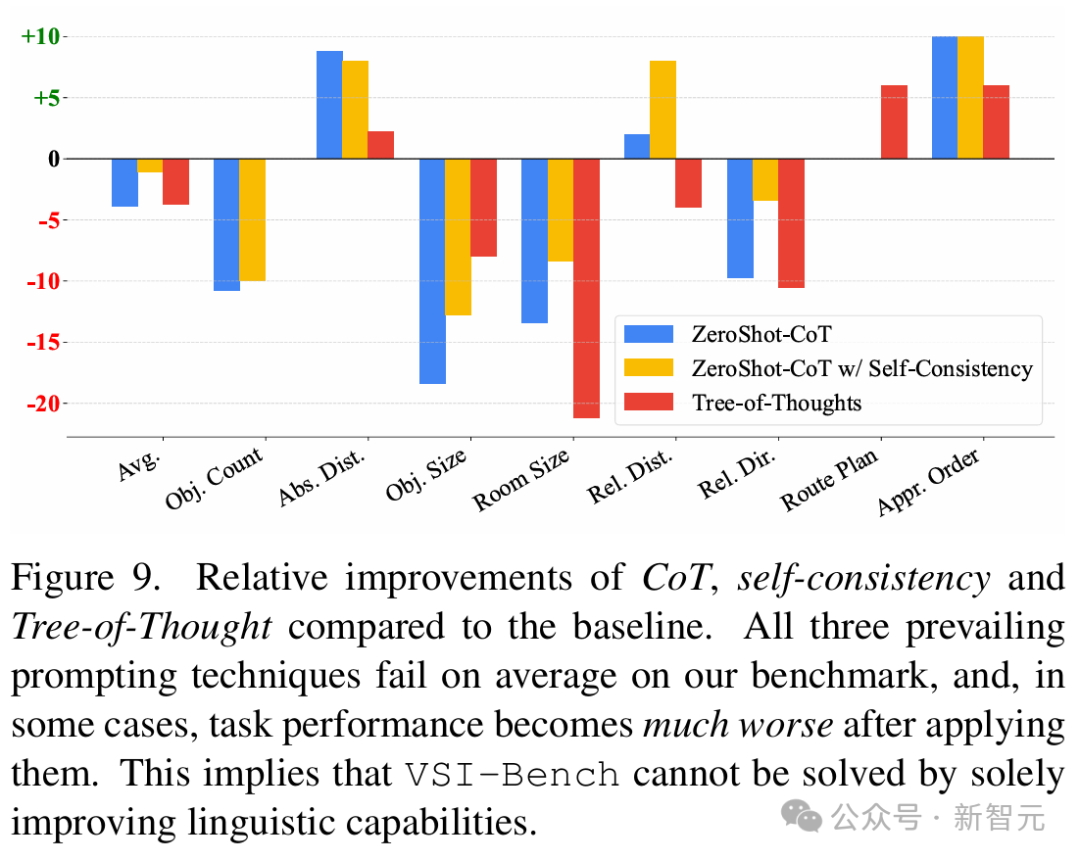
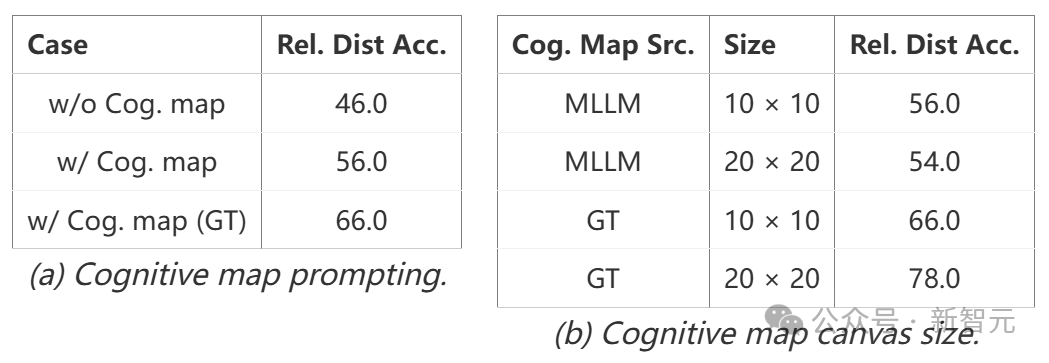
而最后这个结论,就更震撼了。 团队通过提示模型在笛卡尔网格上「可视化」其记忆,来探测它的能力,其中每个被占据的单元格代表一个物体的中心。 研究结果表明,在处理空间信息时,MLLM并不是构建一个连贯的全局模型,而是从给定的视频中生成一系列局部化的世界模型。 但问题涉及相距较远的对象时,模型的性能会迅速下降,此时这种限制尤为明显。 这些观察表明,该领域未来研究的一个关键方向,就是开发更有效的空间记忆机制。 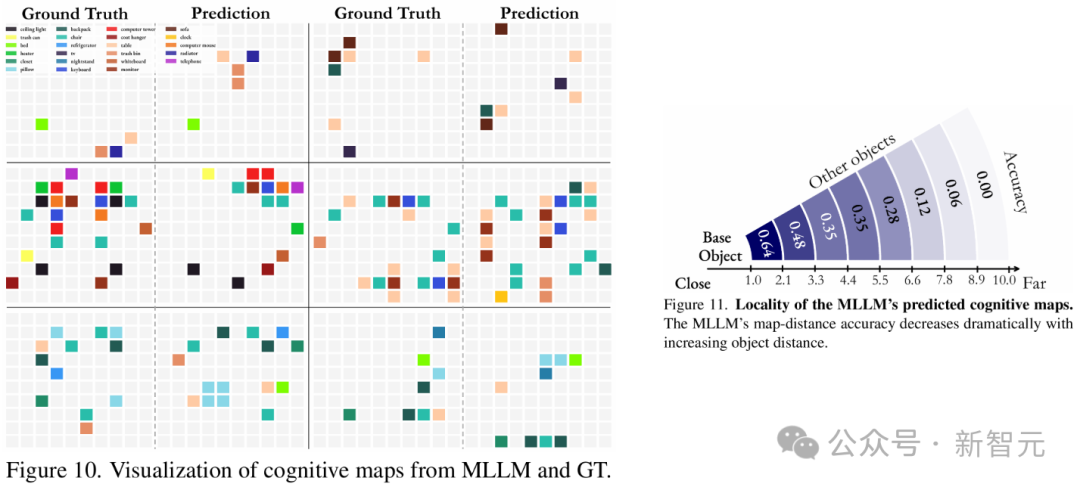
网友表示,这项关于「空间思维」的见解实在太精彩了。提高MLLM的视觉空间智能,可能会彻底改变AI助手。AI在日常空间中的未来,实在令人兴奋。 
有人说,从基于主观事实的模型中提取客观事实,看起来比LLM跟特斯拉FSD相结合更具挑战性,因为后者已经推理出了客观事实。 
不过也有人说,视频理解的确是下一个前沿,但MLLM恐怕无法真正代表人类智能理解动态视觉信息的方式。 
项目介绍
项目介绍

VSI-Bench

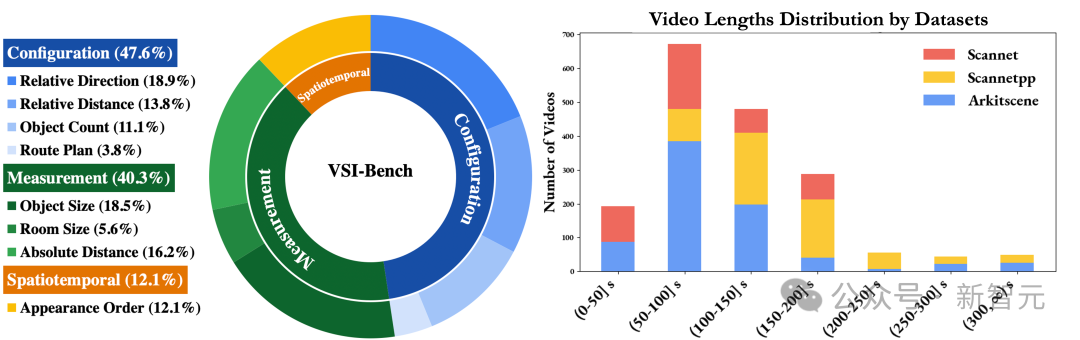
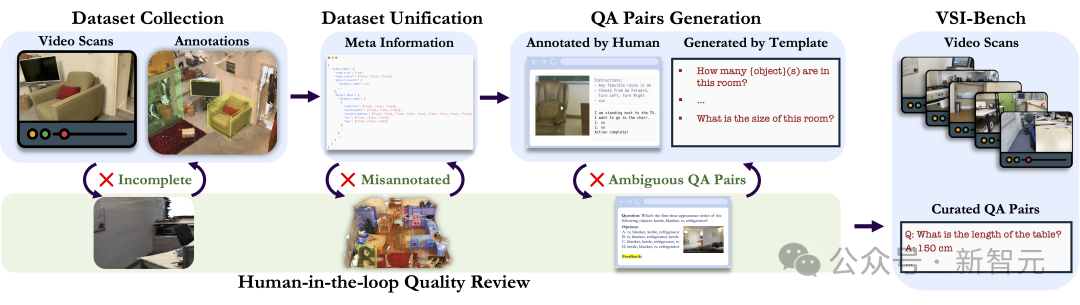
VSI-Bench评估
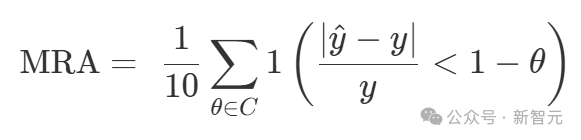
在空间中,MLLM如何以语言思考

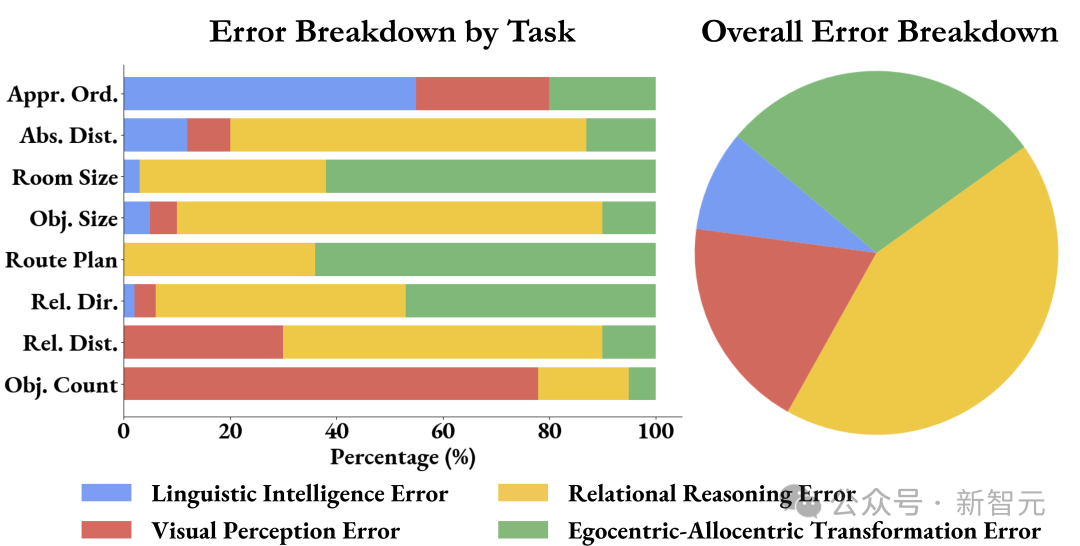
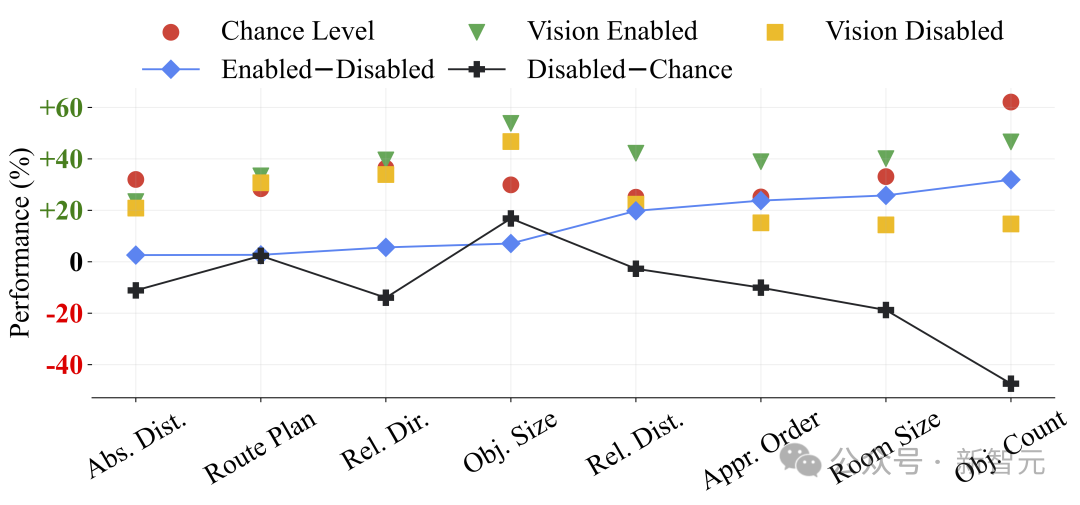
发现 1:空间推理是MLLM在VSI-Bench上表现的主要瓶颈
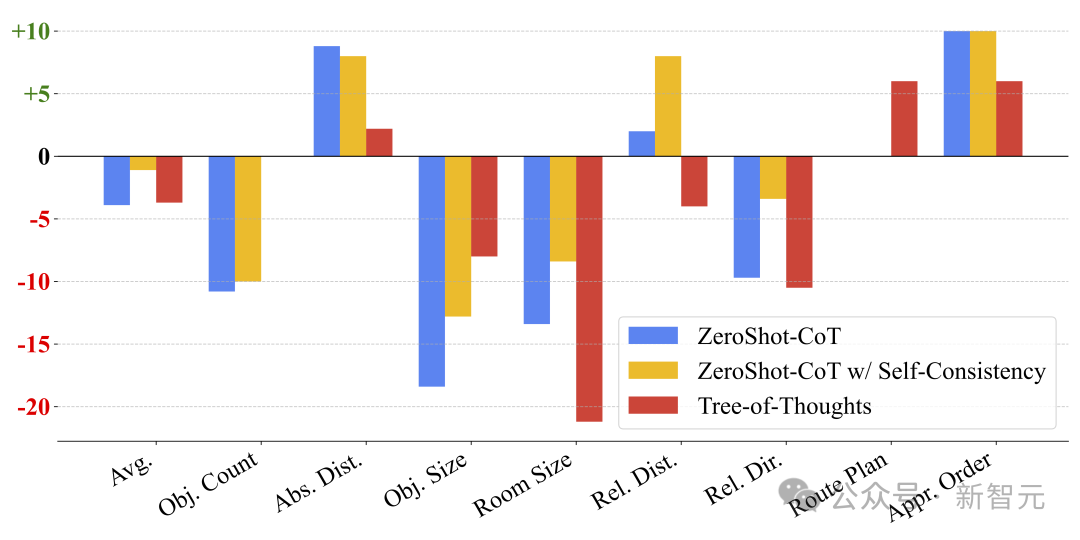
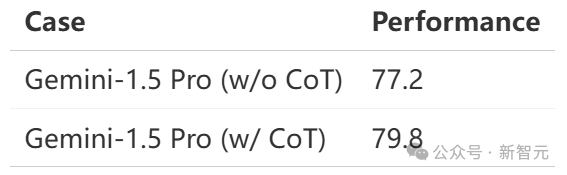
发现2:尽管语言提示技术在语言推理和通用视觉任务中有效,但对空间推理而言往往有害。
在视觉上,MLLM如何思考空间
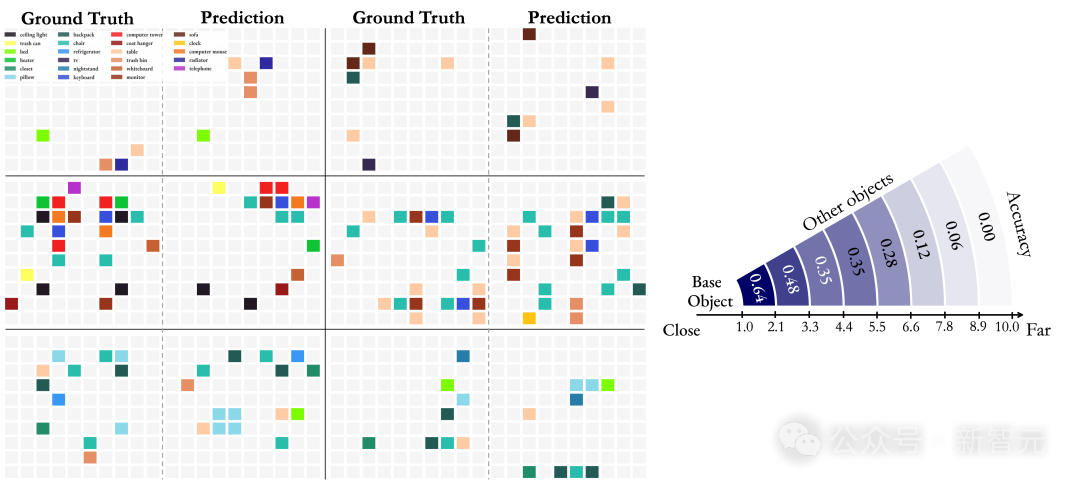
发现 3:在记忆空间时,MLLM从给定视频中在其「脑海中」形成一系列局部世界模型,而非统一的全局模型
LLM距离「既能理解,又能生成」视觉内容,还有多远?
无独有偶,谢赛宁和LeCun的团队,前不久还刚刚提出了一种全新的多模态理解与生成模型——MetaMorph。 简单来说,当与视觉理解任务联合训练时,仅需极少量的生成数据即可激发LLM的视觉生成能力。

论文地址:https://arxiv.org/abs/2412.14164




内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢