

本文全面分析了今年 AI 的发展,包含 AI 技术栈的基础设施层、基础模型层、应用层、工具层,尤其是各个层面的主要收获、值得关注的趋势与值得关注的初创公司。此外,本文还概括了 AI 领域的投资和并购情况,以及其他 AI 趋势。
需要指出的是,可能限于作者 Kelvin Mu 的关注重心,本文除了对中国基础模型的介绍,没有更多关于中国 AI 其他技术栈的进展。不过,这并不妨碍本文仍是我们了解 2024 年 AI 产业全局的绝佳文本。
1. 整个基础设施堆栈正在经历一次重大改造,类似于互联网和云计算的建设。对推理的需求才刚刚开始加速,将由 GenAI 的日益普及、新的多模态应用以及不断演变的模型架构推动。
2. 随着规模扩展定律开始趋于平稳,模型开发正从大型预训练转向推理时的逻辑推演。这一转变使模型能够处理更复杂的逻辑推理任务。同时,更小、更专业模型的兴起为用户提供了更高的效率和灵活性。
3. AI 在企业环境中首次带来了实际的投资回报,例如代码生成、客户服务和搜索正在引发可衡量的影响。下一个前沿领域在于 AI 智能体的普及,但只有在我们构建了支持多智能体交互所需的底层架构之后,它们的真正潜力才能得以实现。
4. 对 AI 的投资持续增长,特别是在基础设施和基础模型层。大多数退出将通过并购实现,但投资者的高期望可能与市场现实相冲突,从而影响未来的估值。
5. AI 的快速采用已经超过了监管框架的步伐,引发了关于版权和知识产权等话题的争论。同时,各国越来越多地将 AI 视为主权问题,导致对 AI 生态系统区域化的关注增加。
在本文中,作者 Kelvin Mu 融合了个人观点,以及与研究人员、投资机构、超过 300 家 AI 初创企业的对话中收集到的见解。此外,本文还利用了作者所在的 Translink Capital 在过去 16 年中建立的广泛企业关系网络。
Kelvin Mu 是 Translink Capital 的投资主管,专注于人工智能和机器学习。他关注 AI 技术栈中的各种机会,包括基础设施、基础模型、工具和应用。在加入 Translink 之前,Kelvin 在美国和加拿大担任过多种业务运营、战略咨询和投资银行的职位。
引言
基础设施层

I. 关键要点:
我们正在见证新的基础设施范式的曙光。在现代历史上,只有两次完全重新定义了全新的基础设施和计算堆栈——20 世纪末的互联网和电信繁荣,以及云计算和 SaaS 的兴起。现在,随着生成式 AI 的发展,我们正在进入第三阶段。
生成式 AI 的发展仍处于早期阶段。在互联网建设期间,1996 年至 2001 年间投资了超过 1 万亿美元的资本。目前的生成式 AI 建设在过去两年中仅投资了 3000 亿美元。以此衡量,我们仍处于早期阶段。(关于这个话题的更多细节,请参阅我深入比较当前 AI 周期与互联网泡沫周期的文章,https://kelvinmu.substack.com/p/ai-are-we-in-another-dot-com-bubble)。
对推理(inference)的需求才刚刚开始。由于Scaling Law正在放缓,对训练的需求可能正在成熟(稍后会详细讨论),但对推理的需求才刚刚开始。大致来说,有三个原因:
早期采用。企业对生成式 AI 的采用仍处于起步阶段,但正在迅速加速。OpenAI 提供了一个有用的指标:尽管过去一年每 token API 成本降低了 10 倍以上,但其收入从 10 亿美元增长到 40 亿美元的年运转率,这意味着使用量增加了约 40 倍。*这种增长水平表明我们仍处于采用的早期阶段。
多模态用例即将推出。目前大多数生成式 AI 应用都是基于文本的。多模态用例(例如,文本到视频、文本到 3D)在很大程度上仍未被开发,但它们对计算资源的需求要大得多。例如,生成 AI 视频所需的能量大约是等效文本文档的 100 倍。如果广告、媒体和娱乐等整个行业采用生成式 AI ,这将对推理产生指数级的需求。随着多模态 AI 的最新进展,这可能很快就会实现。
模型架构的演变。像 OpenAI o1 这样的推理模型正在转向更多的推理时间的逻辑推演(也称为测试时计算),结合了思维链和强化学习。这种架构本质上为模型提供了额外的处理时间来思考和完成任务,但这同时也意味着更高的计算需求。例如,新的 o1 模型每个 token 的成本比 GPT-4o 高出 3-4 倍。随着越来越多的工作负载转向这种模型架构,对推理的需求将持续增长。
衡量当前基础设施建设的投资回报率(ROI)是困难的。今年夏天,红杉发表了一篇文章,质疑 6000 亿美元的收入从何获取,以证明当前 AI 基础设施建设的合理性。一个合理的解释是,当今的大部分计算能力都在支持内部项目,而不是新的创收产品——比如 Notion 的生成式 AI 功能或 Klarna 的 AI 客户服务代理。这些项目提高了运营效率,而不是创造新的净收入,这使得它们的 ROI 更难量化。作为背景,6000 亿美元仅占全球 100 万亿美元 GDP 的 0.6%——这可能低估了 AI 的长期潜力。
AI 云市场正变得越来越分散。
虽然超大规模企业(亚马逊、谷歌、微软)继续主导当今的 AI 云市场,但 CoreWeave、Lambda Labs 和 Tensorwave 等新兴企业正在提供具有成本效益的专用 AI 基础设施。Pitchbook 的 Brendan Burke 估计,这个新的 AI 云市场目前价值 40 亿美元,并将在 2027 年增长到 320 亿美元。
像 Nvidia 和 AMD 这样的芯片制造商也在投资这些专业供应商。其中一个原因是,这些芯片制造商希望减少对超大规模云服务提供商的依赖,而这些超大规模云服务提供商同时也在开发自己的芯片。例如,谷歌的 TPU 芯片现在已被苹果等公司采用。AI 云市场的进一步碎片化似乎不可避免。
AI 硬件初创公司面临高资本支出要求。
越来越多的初创公司正在为 AI 工作负载设计定制的 ASIC 芯片(例如Groq、Cerebras)。这些公司不仅在芯片开发方面,而且在数据中心建设方面都面临着巨大的资金需求。
硬件初创公司涉足数据中心建设是必要的,因为超大规模公司拥有自己的芯片研发能力,不太可能在其自己的数据中心采用第三方初创公司的芯片。例如,芯片初创公司 Groq 最近宣布,他们正与 Amarco Digital 合作在沙特阿拉伯建设自己的推理数据中心。
这些初创公司能否从现有企业那里夺取市场份额还有待观察。到目前为止,在这些初创公司中,Cerebras 似乎领先一步,2024 年上半年收入为 1.36 亿美元,但这仍然仅占英伟达数据中心收入的 0.1%。
*此估计不包括 OpenAI 的 B2C 订阅收入,但总体趋势方向是准确的。
II. 未来值得关注的趋势:
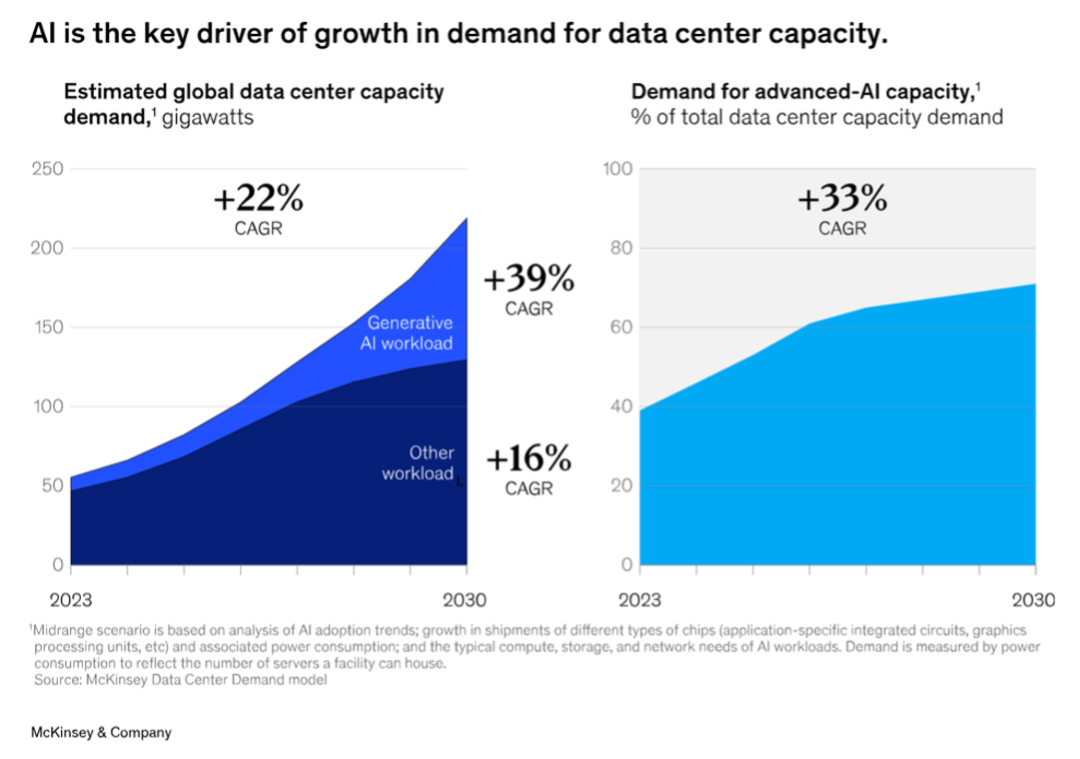
数据中心 2.0。目前,数据中心的全球电力使用量约占 1-2%,但预计到 2030 年,这一数字将上升到总电力的 3-4%,主要由 AI 驱动(在美国,这一比例接近 8%)。总体而言,麦肯锡估计数据中心的容量从现在到 2030 年之间以 22%的复合年增长率增长。
专门用于 AI 的数据中心与传统的云计算数据中心有很大的不同,主要是因为其更高的功率密度,这推动了诸如下一代液体冷却等创新技术的需求。AI 训练和推理的特殊需求还要求高带宽、低延迟的网络连接。这推动了下一代网络和互连技术的发展,以减少多 GPU 集群中的瓶颈。
AI 本身可以用于优化数据中心,例如在预测性维护、动态工作负载分配和能源效率方面。例如,Phaidra是一家正在研究使用强化学习(RL)进行数据中心自主控制冷却系统的初创公司。
Nvidia 在硬件领域的主导地位。Nvidia 现在是全球市值最高的公司,今年纳斯达克的涨幅中有 40% 归功于这一家公司。然而,历史上很少有公司在整个过程中保持 90% 以上的市场份额。
Nvidia 在可预见的未来可能会继续主导市场,但竞争可能会更加激烈。一个竞争对手是 AMD——AMD 的数据中心业务目前只有 Nvidia 的 10%(35 亿美元对 308 亿美元),但同比增长了 122%。该公司也在大型企业中取得进展——例如,Open AI 最近宣布将开始使用 AMD 的 MI300,联想表示对 AMD 的 MI300 的需求创历史新高。
另一个主要的竞争来源是超大规模企业本身。他们的一大优势是内部对 AI 训练和推理的巨大需求。在 CSP 中,谷歌领先最多,新的 TPU V5p 比上一代产品提供了 2 倍的 FLOPs 和 3 倍的高带宽内存(HBM)。
边缘 AI 和边缘/云协作将获得更多关注。这里有一个有趣的事实:全球计算能力(以 FLOPs 衡量)中,不到 1% 由超大规模提供商拥有。虽然这乍看之下可能令人惊讶,但当你考虑到包括笔记本电脑和智能手机在内的边缘设备数量时,这就说得通了。释放这种潜在的计算能力可能会成为改变游戏规则的关键。我们已经见证了可以在边缘设备上部署的小型语言模型(SLMs)的爆发。
一些专家认为,最终可以将高达一半的 AI 工作负载从云端转移到边缘。我见过的一个早期想法是构建一个云/边缘路由器,可以根据功耗、成本和延迟要求等标准动态地在云端和边缘设备之间路由 AI 工作负载。最后,边缘 AI 还可以通过减少发送到云端进行处理的数据量来帮助推测性解码。
中国在 AI 领域的跟进。围绕 AI 芯片的出口管制可能会在短期内阻碍中国的进展。但从长远来看,这可能会迫使中国在基础设施和模型方面更具创新性。例如,最近有报道称,中国已经在多个数据中心和 GPU 架构上训练了一个单一模型,这是首次有国家这样做。尽管计算能力有限,中国的 LLM 已经证明他们可以与最好的闭源模型竞争。特别是,阿里巴巴的 Qwen 模型和 DeepSeek 模型已经显示出它们可以与西方的 GPT-4o 等模型相匹敌。这表明,尽管硬件限制可能带来一些挑战,但中国实验室正在找到解决办法,并继续保持跟进。
AI 对可持续性的影响:超大规模企业到 2030 年已做出气候承诺。例如,微软设定了到 2030 年实现碳负排放的雄心勃勃的目标。然而,AI 能源消耗的快速增长正将这些承诺推向错误的方向。例如,微软最近报告称,自 2020 年以来,二氧化碳排放量增加了近 30%,主要由数据中心扩张推动。同样,谷歌 2023 年的温室气体排放量比 2019 年高出 50%,很大程度上也是由于 AI 数据中心。我们认为,这一趋势将迫使企业决策更加关注可持续性。从长远来看,那些希望了解 AI 的人也需要了解能源市场。
III. 值得关注的初创公司:
AI 云和计算:
Coreweave、Crusoe、FoundryML、Lambda labs、Rescale*、SF Compute、Shadeform*、Tensorwave*、Together AI
AI 芯片公司:
Blaize、Cerebras、D-Matrix、Etched、Groq、Graphcore、Lightmatter、Rebellions、SambaNova、Tenstorrent、Hailo
数据中心外设:
Celestial AI 、Corintis、Liquidstack、Jetcool、Phaidra、Thintronics*、Xconn Technologies*
模型层

I. 关键要点:
对小型语言模型(SLMs)的关注日益增加。去年,我们预测 SLMs 将出现增长趋势,但它们的快速进步已经超出了我们的预期。今天,一个 30 亿参数的模型可以与原始的 1750 亿参数的 ChatGPT 模型相媲美,在短短 24 个月内,参数效率提高了 50 多倍。这一显著的进步源于更好的压缩技术(例如,蒸馏、量化、剪枝)和高质量合成数据的使用。2023 年的一篇论文“超越神经缩放定律”研究表明,通过精心选择数据集并移除低质量数据,可以用小得多的规模实现更好的性能。这是 SLMs 背后的核心理念。
因此,边缘 AI 变得越来越可行。随着 SLM 性能的提高和边缘硬件(CPU、NPU)变得更强大,在边缘部署 AI 工作负载变得越来越可行。如今,7B 模型可以在笔记本电脑上高效运行。值得注意的 SLM 包括微软的 Phi-3 模型、谷歌的 Gemini Flash 以及 Llama 1B 和 3B 模型。边缘 AI 还具有提高隐私和安全性、降低延迟和成本的优势。这特别适用于实时语音识别或离线设置等用例。有关设备上语言模型的全面综述,请参阅 Meta 和 Nexa AI 的论文(https://arxiv.org/pdf/2409.00088)。
我们正在转向复合型模型网络。LLM的架构正从大型单体系统演变为较小的、专业化的模型(类似于 MoE 方法)组成的分布式网络。这涉及到一个主模型协调这些较小的、专用模型之间的任务。Meta 最近的研究表明,平行使用多个较小的模型可以持续超越单一的大型模型。这种方法类似于人脑,人脑不是一个单一的均匀结构,而是由海马体(记忆)、额叶(逻辑)和枕叶(视觉)等专业化区域组成。我们还相信这种架构也将适用于 AI 智能体(稍后详述)。
模型正朝着更多推理时间的逻辑推演方向发展。OpenAI 的最新 o1 模型标志着使用诸如思维链和强化学习等技术向推理时间的逻辑推演转变。o1 模型通过试错学习最优路径,就像人类解决问题时涉及大量的自我反思和错误纠正。这使得模型在复杂的推理任务中表现出色,例如数学、编程和科学查询。然而,这种能力是有代价的,o1 的每 token 价格比 GPT-4o 高 3-4 倍。另一个类似的模型是中国实验室 DeepSeek 的 R1-lite-preview。与o1 的简明摘要不同,R1-Lite-Preview 会实时向用户展示其完整的链式思维过程。这种对推理时逻辑推演的日益重视可能会增加对低延迟计算的需求。
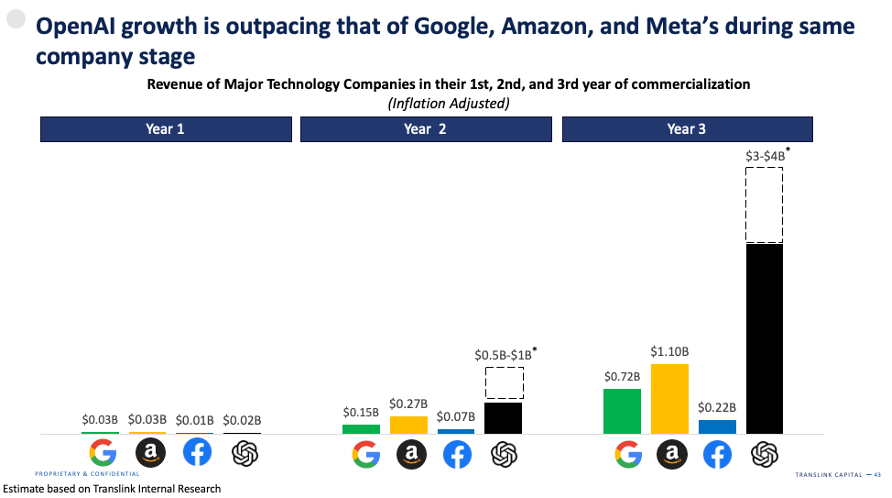
OpenAI 经历了内部动荡。今年,OpenAI 经历了很多内部动荡,包括 Sam Altman 作为 CEO 的突然被解雇和随后的复职。在原始创始人中,只有 Greg Brockman 和 Wojciech Zaremba 仍然留在公司,而像 Ilya Sutskever、John Schulman 和 Mira Murati 这样的关键人物都已离开。尽管面临这些挑战,OpenAI 在最新一轮融资中以 1500 亿美元的估值筹集了 65 亿美元,并有望成为历史上增长最快的科技公司,远远超过了亚马逊、谷歌和 Meta 的增长速度。
Meta 的开源策略正在取得成效。Meta 继续其大胆的开源方法,扎克伯格承诺向 Llama 和 Meta 更广泛的生成式 AI 计划投入数十亿美元。这种方法被证明是有效的,Llama 模型今年的下载量接近 3.5 亿次——比去年增长了 10 倍以上。在 C 端用户方面,Meta 正在将 LLM 集成到现有的消费者应用程序中,如 Facebook 和 Instagram,以防止竞争对手构建独立的 LLM 界面,如 ChatGPT 或 Perplexity。在企业方面,Meta 已经与 AT&T、DoorDash 和高盛等大型企业合作。看来,闭源专有模型和开源模型之间的差距已经大大缩小,这在很大程度上要归功于 Meta 的努力。
在过去的一年里,OpenAI 与其他研究实验室之间的性能差距已经缩小。尽管 OpenAI 仍然领先,但其主导地位已不如以前显著。在初创企业中,Anthropic 因其在模型升级、产品发布和人才引入方面的显著进展而脱颖而出,并且据传其收入运行率接近 10 亿美元。看来,在 AI 时代,先发优势可能不会那么持久。一种假设是,在当今这个互联互通的世界中,成熟的通信基础设施如互联网和社交媒体使得专有技术和知识的传播比以往任何时候都要快,从而减少了技术壁垒。因此,模型性能越来越依赖于资本和计算能力的获取,而不是任何专有技术。在这方面,明年值得关注的一家初创企业是 xAI ——他们已经拥有世界上最大的超级计算机之一,拥有超过 10 万个 H100(据马斯克称,很快将达到 20 万个)。马斯克暗示,他们即将推出的模型 Grok 3 可能已经是最先进的,并且可以与 GPT-4o 相媲美。
基础模型公司在短期内可能会保持亏损状态。据 The Information 报道,OpenAI 的训练和推理总计算费用预计将达到 50 亿美元,超过其 40 亿美元的收入。假设推理和托管成本构成了销售成本的大部分,OpenAI 的毛利率约为 40%。这与其他基础模型公司的情况一致,但远低于软件业务中通常看到的利润率。
低利润率的一个原因是,模型提供商之间的持续性 token 价格战,这使得今年的价格下降了 10 倍以上。除了计算成本外,其他支出似乎相对较低,员工工资、一般和管理(G&A)费用以及销售和营销费用合计仅占收入的 40%。展望未来,随着行业的成熟,基础模型公司是否最终能够实现类似软件的利润率将值得关注。无论如何,我们认为短期内不会实现盈亏平衡。

对模型公司多元化的需求日益增长。随着基础模型层的日益商品化,AI 实验室可能需要多元化其业务。token 价格正在下降,但采用率和收入增长的提高目前有助于抵消这一下降。例如,尽管 token 价格大幅下降,OpenAI 今年的收入仍预计增长 4 倍,而 Anthropic 据传增长了 10 倍。然而,从长远来看,模型公司可能需要考虑垂直整合以抵消模型层的商品化。
在基础设施层,OpenAI 正与 Broadcom 和 TSMC 合作开发其首款自研芯片。此外,它还与微软合作开展“Project Stargate”项目,这是一个 5 GwH 价值 1000 亿美元的数据中心计划。
在应用和工具层,OpenAI 正在扩展到新产品,如 ChatGPT 搜索、类似 Perplexity 的搜索工具和 OpenAI Swarm,这是一种构建智能体的框架。为了确保长期增长,基础模型公司可能需要从纯粹提供模型转向开发工具和终端用户应用程序。
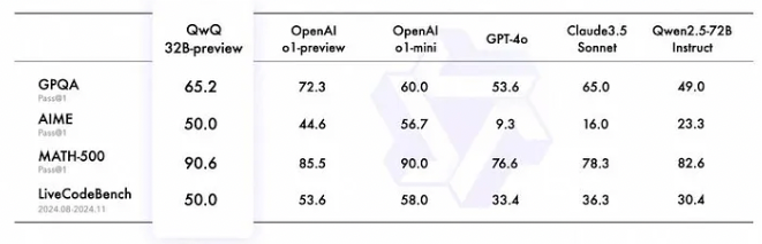
来自中国的模型正在变得越来越好。中国的 AI 实验室继续推出令人印象深刻的模型,如阿里巴巴的 Qwen 系列和 Deepseek。阿里巴巴最新的 Qwen 2.5-Coder 系列和 QwQ-32B-preview 是顶级的开源代码模型,其能力可与 Open AI 和 Anthropic 的模型相媲美。QwQ-32B 预览版和 Deepseek 的 R1 在 MATH 和 AIME 等流行基准测试中击败了 OpenAI 的 o1。
规模扩展定律可能很快达到顶峰。最近的发展表明,规模扩展定律可能很快达到其极限,这些定律历史上通过更大的预训练数据集推动了模型的改进。Ilya Sutskever 最近在接受路透社采访时也表达了这一观点。大约在同一时间,The Information 发表了一篇文章,讨论了 OpenAI 的下一个旗舰模型 Orion 可能无法实现早期迭代中所见的显著性能飞跃。这种转变表明,简单的扩展可能正在让位于模型创新的新范式。
新模型开发范式:推理(inference)优先于预训练。展望未来,模型性能将不再那么依赖于大量的预训练数据,而是更多地依赖于推理时的高级逻辑推演能力。像 o1 这样的模型正在使用思维链和强化学习,这赋予了模型更高级的逻辑推理能力。除了明显的性能优势外,另一个好处是它允许客户根据任务的复杂性来选择模型。需要复杂逻辑推理的任务,如并购谈判的助手,可以选择最大限度地利用推理时间的逻辑推理。而像摘要这样的简单任务,则可能寻求最小化推理时逻辑推理。这种方法为最终用户提供了更多的灵活性,并有助于降低总体成本。
合成数据的角色。随着公开可用的训练数据逐渐耗尽,合成数据将发挥更加重要的作用。合成数据在预训练和后训练中的使用越来越广泛。无论是较小的微软 Phi 模型,还是 OpenAI 和 Anthropic 的最大模型,都在训练中融入了合成数据。然而,保持合成数据集的分布和熵以确保模型的鲁棒性是具有挑战性的部分。
无监督/强化学习在模型开发中的作用。现在 LLM 已经内置了一些基础智能,我们认为 RL 将在它们的发展中发挥更大的作用。Genie(在 ICML 2024 上获得最佳论文奖)通过创建一个 110 亿参数的“世界基础模型”展示了这一点,该模型能够从无监督训练中生成交互式环境,训练数据来自未标记的互联网视频。这种无需任何真实值或标记数据的训练方式将是大型模型开发的未来。随着时间的推移,模型将开始在正反馈循环中自我改进,解锁之前不存在的新可能性。
LLM 的演变反映了人类认知发展的各个阶段。第一阶段主要依赖于扩展和预训练,类似于胎儿或新生儿大脑的早期发育——专注于扩展和构建基础结构。现在,我们正进入第二阶段,模型的“幼儿期”大脑超越了其有机的基础结构。在这个阶段,它通过试错学习、观察和积极探索其环境来变得更聪明——这实际上就是 RL。
多模态 AI 的进步。多模态 AI 有望成为下一个主要的计算需求驱动力。尽管采用仍处于早期阶段,但它正在迅速扩展。OpenAI 的 Sora 在今年早些时候发布时吸引了整个行业的关注。随后,Runway、Luma、Pika Labs 和 Genmo 等初创公司也推出了自己的文本到视频模型。然而,到目前为止,这些模型的使用主要局限于专业消费者市场,因为它们缺乏企业级所需的稳健性。另一方面,语音/文本到语音的应用正在企业中获得显著采用。这些应用包括内容创作和客户服务。该领域的领导者之一 Elevenlabs 据传其收入运行率接近 1 亿美元。另一家上市公司 Soundhound(Translink 投资组合公司)预计在 2025 年将产生 1.55 亿至 1.75 亿美元的收入。
专用模型的崛起。随着通用模型的规模越来越大,我们预计,专用模型也会相应增加。这些模型并不总是基于文本的。一些更有趣的领域包括:
时序模型——作为时序分析的基础模型,如亚马逊 Chronos,将时间序列数据视为可以使用 transformer 架构建模的“语言”。时间序列模型的一个关键优势在于它们能够应用迁移学习——利用来自不同领域的多样化数据集来提高泛化能力。我们认为,时间序列预测的基础模型代表了一个尚未完全探索的令人兴奋的前沿领域。然而,它的主要挑战在于获得足够的训练数据。与通用 LLM 不同,后者可以依赖公共网络进行预训练数据,大多数时间序列数据可能被锁定在企业内部。
物理学/世界模型——从定义上讲,大型语言模型具有有限的归纳偏见——因此,对现实世界物理学的理解有限。为了解决这个问题,像 World Labs 这样的公司正在开发能够理解和与 3D 物理世界互动的模型,类似于人类的空间智能。这在机器人技术等领域尤为重要。这一任务尤其重要但具有挑战性,因为我们认为物理世界运作在一个远比语言世界更高维度的空间中。考虑一个看似简单的动作,比如从 100 米高的建筑物上掉落一个球:虽然重力(9.8 m/s²)是一个已知的基本因素,但许多其他因素如球的重量、空气阻力(海拔、湿度等)、风等都会起作用。考虑到这些随机因素,使得理解和模拟物理世界异常具有挑战性。
另一个世界模型的例子是微软的 Aurora 模型——一个基于超过 100 万小时的天气和气候数据预训练的环境基础模型。Aurora 模型在不到一分钟的时间内生成 5 天的全球空气污染预测和 10 天的高分辨率天气预报,其表现优于最先进的经典模拟工具。虽然其最明显的影响是改善天气预报,但还有更多潜在应用,如保险和风险评估、金融交易和农业管理。
生物学模型——以生物学为重点的基础模型,如 AlphaFold 3,代表了结构生物学的突破性进展。这些模型可以准确预测复杂生物分子(包括蛋白质、核酸和小分子)的联合结构,使科学家能够生成全新的蛋白质序列。在 AlphaFold 等模型出现之前,确定单个蛋白质结构可能需要博士生花费整个研究生涯——通常为 4-5 年。相比之下,AlphaFold 在不到一年的时间内预测了超过 2 亿个蛋白质结构,这一成就从根本上改变了我们理解生命基本构建单元的能力。随着这些模型的不断发展,它们将革新药物发现和个性化医疗等领域。有关此主题的进一步阅读,请参阅 Rob Towes 在 Radical Ventures 发表的这篇 Forbes 文章(https://www.forbes.com/sites/robtoews/2023/07/16/the-next-frontier-for-large-language-models-is-biology/)。
从长远来看,基础模型可以用于进行科学研究和发现新知识。一个这样的潜在例子是由东京的 Sakana AI 开发的“ AI 科学家”。AI 科学家是一个全面的系统,用于自动化科学发现。它自动化了整个研究生命周期,从生成新的研究想法、编写和必要的代码、执行实验到以学术报告的形式呈现发现。正如 AI 开始自己学习编程和生成软件一样,我们相信 AI 的新兴能力将扩展到更广泛的科学知识和发现领域。这样的进步可以通过加速多个科学学科的发现步伐,从根本上重塑人类进步的轨迹。

III. 值得关注的初创公司:
基础模型/研究实验室:
01.AI、Anthropic、Deepseek、Imbue、MiniMax、Mistral、Moonshot AI、OpenAI、Reka AI、Safe SuperIntelligence、Sakana AI*、Stability AI、xAI、Zhipu
小型语言模型(SLMs):
Arcee.AI、Bespoke labs、Nexa AI、Predibase
多模态(图像和视频):
Black Forest Labs、Genmo、Higgsfield、Luma AI、Midjourney、Pika labs、Runway ML、Stability AI、Tavus、Twelve Labs
Multimodal (voice): 多模态(语音):
Assembly AI、DeepL、Deepgram、Elevenlabs、PlayHT、Poly AI、Resemble AI、Suno、Symbl.AI、Udio
专用基础模型:
Archetype AI、 Cradle、Cusp AI、EvolutionaryScale、Formation Bio、Generate:Biomedicines、Hume AI、Illoca、Luminance、Nabla Bio、Orbital Materials、Pantheon AI、Physical Intelligence、Silurian AI、Synthefy、World Labs
工具层

I. 关键要点:
RAG 是目前大多数公司使用的主要技术方法。根据 Menlo VC 的最新报告,检索增强生成(RAG)的采用率已增加到 51%,而去年为 31%。与此同时,微调仍然不常见,只有 9% 的生产模型进行了微调。随着基础模型的不断改进,我们预计这一趋势将继续有利于 RAG。
RAG 提供了显著的优势,但也带来了自身的一系列挑战。RAG 的主要优势在于将模型的推理层与数据层分离,使响应能够基于实时的真实世界数据,并最小化幻觉的风险。然而,RAG 仍然面临诸如缺乏领域特定知识和上下文不足等问题,这可能导致检索准确性降低。优化分块和检索在这一点上仍然更多是艺术而非科学,最后一英里尤其难以正确实现。
许多人正在将基于确定性的结构与 RAG 结合,以帮助提高性能。为了解决其中的一些挑战,许多公司正在将确定性结构或本体论与 RAG 结合,以增强性能。例如,知识图谱在数据点之间添加了一层结构化的语义关系,使得为给定查询检索精确和相关信息变得更加容易。这与传统的 RAG 形成对比,后者通常仅基于数据点之间的距离来衡量相似性,缺乏更深层次的语义理解。结合这些结构可以提高检索的整体准确性,特别是在医疗保健、金融服务和法律等对准确性要求较高的领域尤为重要。
越来越多的企业选择内部构建解决方案。Menlo 报告显示,近一半的生成式 AI 解决方案现在是内部开发的,而去年这一比例仅为 20%。我们听到的最常见的企业选择内部构建的原因之一是,他们不愿意将数据交给第三方。另一个原因是,希望进行更多的定制以满足特定的业务需求。随着开源模型逐渐缩小与闭源模型的差距,我们预计内部构建的趋势将持续下去。
企业面临的最大瓶颈通常是数据管理和准备阶段。现在众所周知, AI 团队大部分时间都花在数据准备上,而实际的模型开发和部署时间则较少。组织可获得的大部分数据都是非结构化数据,占当今总数据的约 80%。这些数据可以是电子邮件、文档、合同、网站、社交媒体、日志等形式。将这些数据转换为可用于机器学习部署的格式需要进行大量的清理和标准化。一旦收集并清理了数据,就必须将其向量化,通常通过利用向量数据库来实现。这些步骤并非微不足道,需要深厚的技术和领域专业知识。
工具层的商业化有时会很具挑战性。商业化通常很困难,原因包括竞争激烈、开源替代品的可用性以及已有玩家进入市场。例如,尽管 Pinecone 被广泛认为是向量数据库的领导者,但它面临着来自 Milvus(Zilliz)、Weaviate、Chroma 和 Qdrant 等开源项目的竞争。此外,MongoDB 和 Elastic 等主要数据库公司都引入了各自的向量搜索功能,进一步加剧了竞争压力。
此外,云提供商也涉足这一领域。像 AWS Sagemaker、Azure Machine Learning 和 Google Vertex AI 这样的产品都提供了完全托管的服务。这些端到端的解决方案是构建、训练和部署机器学习模型的一站式平台。
推理优化一直是热门且竞争激烈的领域。在过去的一年里,我们看到四家推理优化公司被大型公司收购——Run:AI 、Deci 和 Octo AI 被 Nvidia 收购,Neural Magic 被 Red Hat 收购。Deci 的投资者可能表现良好(收购价格为 3 亿美元,而总融资额为 5700 万美元),而 OctoAI 的投资者可能回报有限(收购价格为 2.5 亿美元,而总融资额为 1.33 亿美元)。
其他值得注意的参与者包括 BentoML、Baseten、Fireworks、Lamini 和 Together AI 。其中一些公司选择通过自己购买 GPU 并提供更全面的解决方案来采取更集成的方法。这些公司是作为独立的上市公司蓬勃发展,还是最终像他们的同行一样被收购,仍有待观察。
II. 未来值得关注的趋势:
评估仍然是生成式 AI 中的一个重要但未解决的问题。为了类比,考虑信用评分,其中像 Experian、Equifax 和 TransUnion 这样的信用机构评估人类的信用度。评估信用度相对直接,因为决定信用度的因素是明确定义的,且人类的金融行为大致相似。这使得创建标准化的指标成为可能。
与信用评分不同,评估 LLM 要复杂得多,因为问答、总结、代码生成和创意写作这样的应用是多样化的,且通常具有行业特性。例如,医疗保健所需的评估指标与法律行业不同。因此,没有一种“一刀切”的指标能够有效评估 LLM 在所有环境中的表现,这与信用机构使用的标准化方法不同。此外,与基于客观指标的信用评分不同,LLM 评估涉及诸如创造力和独创性等主观因素,这些因素更难以量化。
初创公司和 AI 实验室正在积极应对评估挑战。一些初创公司,如 Braintrust 正试图建立一个更加领域无关的端到端平台,配备自动评估功能。OpenAI 最近也发布了 SimpleQA,这是一个简单的评估模型,用于检查响应的事实性。尽管做出了这些努力,但尚未建立普遍接受的框架来有效评估LLM。
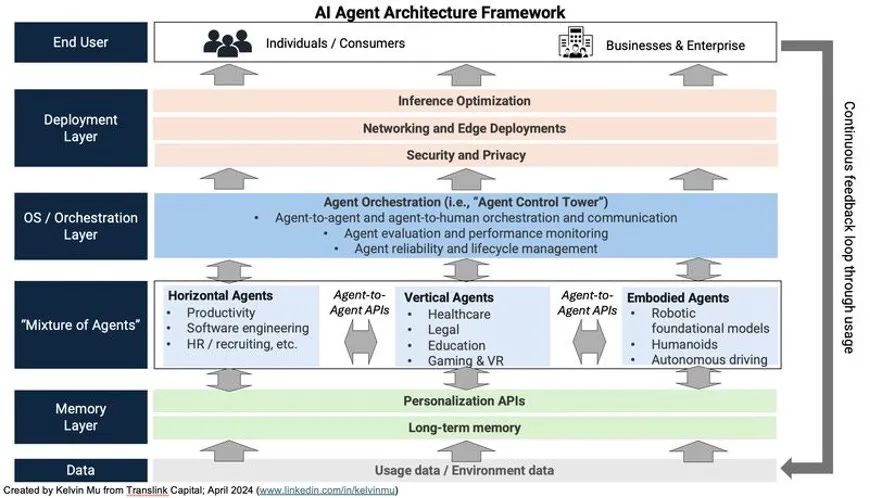
AI 工具的未来很可能会围绕智能体展开。不过,构建支持充满智能体世界的基础架构是第一步。以电子商务智能体为例——这些智能体有一天可以代表你自主进行购买,使这样的智能体能够工作远比仅仅赋予其搜索和推理能力要复杂得多。它需要一个强大的支持基础设施:智能体如何安全地提供凭证?如何确保适当的认证以验证智能体是否合法地代表个人行事?需要什么样的新支付系统/轨道来促进智能体交易?我们认为,围绕智能体的支持基础设施,而不是智能体本身,将成为广泛采用的最大瓶颈。
智能体之间的协作也将在未来占据中心位置。就像我们有系统和框架来评估人与人之间的互动一样,我们也需要类似的系统来管理智能体之间的互动。需要一个智能体编排层来协调智能体之间的通信。它还可以负责评估智能体性能、设置防护栏以及确保遵守其预期的授权。随着智能体获得更多的自主权,确保数据安全和隐私将变得越来越重要。将需要新的标准和法规来管理智能体行为,就像 GDPR 和类似的框架指导人类数据使用一样。(请参见下图以了解智能体框架的一个示例)
最后,为了让智能体在大规模应用上取得成功,我们必须开发有效的反馈和学习机制。智能体需要从成功和失败中学习,以不断改进。这将需要一个强大的反馈系统,使智能体能够在保持安全和合规的同时动态改进。
III. 值得关注的初创公司:
数据:
Cleanlabs、Datalogy AI、Hugging Face、Marqo、Scale AI、Shakudo、Snorkel AI、SuperAnnotate、Unstructured.io、Weka、Zillis
RAG / 模型定制:
Cohere、Contextual AI、Upstage AI、Vectara
向量数据库 / 嵌入模型:
Chroma、Milvus、Pinecone、Qdrant、Voyage AI、Weaviate
模型服务:
Anyscale、Baseten、BentoML、CentML、Clika AI、Fireworks、Lamini、Lightning AI、Modular、OpenPipe、Replicate、TensorOpera、Together AI
评估与可观测性:
Arize AI、Braintrust、Dynamo AI、Fiddler AI、Galileo、Galileo AI、Observe、Weights and Biases、WhyLabs
安全性:
Calypso AI、Grey Swan、Hidden Layer、Protect AI、Robust Intelligence (acquired by Cisco)、Troj.AI
智能体编排/工具:
Emergence AI、Langchain、MemGPT、Tiny Fish、UnifyApps
应用层

I. 关键要点:
GenAI 的采用正在迅速增长。Menlo估计,2024 年在生成式 AI 应用上的支出为 46 亿美元,比去年的 6 亿美元增长了近 8 倍。我们预计,随着许多目前处于概念验证阶段的项目转化为全面部署,增长将在明年继续。这在情理之中,因为当 ChatGPT 在 2022 年 11 月推出时,大多数公司的 2023 年预算已经最终确定。因此,2024 年是公司真正有预算进行 AI 实验的第一年。展望未来,我们预计 2025 年及以后的 AI 相关预算将进一步扩大。毕马威对 225 名高管进行的一项调查显示,83%的受访者计划在未来三年内增加对 GenAI 的投资。
代码生成——在谷歌最近的财报电话会议上,透露出该公司目前有 25% 的代码是由 AI 生成的。这个领域的领头羊微软 GitHub Copilot 已达到约 3 亿美元的年经常性收入(ARR),现在占 GitHub 收入增长的 40%。包括 Cursor、Poolside、Codeium 和 Cognition 在内的几家初创公司也已进入市场,共同筹集了超过 10 亿美元,以挑战 GitHub 的主导地位。虽然一些初创公司取得了令人印象深刻的进展(年经常性收入超过 5000 万美元),但大多数仍处于商业化的早期阶段。
搜索——Perplexity 已经成为生成式 AI 领域最知名的新创公司之一,并迅速推出了 Perplexity Finance 和 Perplexity Shopping Assistant 等功能。然而,随着 OpenAI 推出 ChatGPT 搜索和 Meta 引入自己的 AI 驱动搜索引擎,竞争预计将加剧。Perplexity 据传的 5000 万美元年经常性收入对于与其创立时间相似的初创公司来说是一个令人印象深刻的里程碑,但这仅占谷歌 2000 亿美元搜索收入的 0.025%,这既突显了竞争的规模之大,也表明了其巨大的增长潜力。Perplexity 在广告领域的推进能否帮助其进一步侵蚀谷歌在搜索市场的份额,还有待观察。
智能体——智能体初创公司正在获得关注,特别是在客户支持、销售与营销领域的公司。像 Sierra、Maven AGI 和 Ema 这样的公司瞄准了企业级市场,而 11x、Artisan 和 Style AI 等公司则更多地关注中小企业和中端市场。大型玩家也在进入这一领域,通常采用更广泛的平台方法:谷歌有 Vertex AI Agent Builder,微软有 Copilot Studio Agent Builder,亚马逊有 Amazon Bedrock,Salesforce 有 Agentforce。目前,我们看到的智能体只能处理相对简单的任务,但随着基础模型的改进,特别是像 OpenAI 的 o1 模型这样的高级逻辑推理能力,我们预计它们将变得更加有能力。

GenAI 正在改变 SaaS 业务模式。Wing Capital 的 Tanay Jaipuria 在他最近的文章中指出(https://www.tanayj.com/p/the-evolution-of-saas-pricing-in),GenAI 正导致公司采用更多基于使用的定价。例如,Salesforce 每次对话收费 2 美元,而 Intercom 每解决一张工单收费 0.99 美元。正如 SaaS 通过将技术创新与商业模式创新(从许可和维护转向定期订阅)相结合,彻底改变了软件行业一样,我们认为 ,AI 也有潜力推动另一波商业模式创新。
企业从生成式 AI 中实现真正的投资回报。AI 正在为企业带来切实的价值。例如,Klarna 报告称(https://downloads.ctfassets.net/4pxjo1vaz7xk/161qRVqB2B2N8MYwLl9x5A/abcc53df5acfac3fa4bb36d4621db99c/Klarna_Holding_AB_Interim_Report_2024__ENG_.pdf),其 AI 驱动的智能体完成了相当于 700 名客户服务代表的工作。尽管收入增长了 27%,Klarna 还是将其员工人数从 5000 人减少到 3800 人,并计划进一步减少到 2000 人。这些裁员并非由于增长放缓,而是由于 AI 带来的效率提升。如果类似的生产率提高(约 5%)被复制在全球 2000 强企业(这些企业共同创造了约 52 万亿美元的收入),潜在的价值创造可能达到 2.5 万亿美元。
最终,投资 AI 应用公司与传统软件投资并没有太大不同。在投资 AI 应用初创公司时,我们自问的一个关键问题是,基础模型的改进是否会令初创公司受益或受损。那些主要依赖底层模型实力的简单包装公司可能会被淘汰;然而,我们认为那些从深入了解客户旅程和相关工作流程开始的公司可能会受益。这就像制造汽车:首先专注于开发周围的组件——底盘、内饰、软件等——然后随着更好的发动机出现而简单地进行更换,而不是试图自己制造发动机。
对于一家 AI 原生应用公司而言,其关键区别因素与传统 SaaS 应用公司并无不同——关键在于真正理解用户的需求痛点,满足他们的需求,并为他们提供愉悦的体验。AI 只是一个推动者,而不是区别性因素。
机器人领域正焕发新机,这得益于开发类似于 LLM 的基础模型的潜力。最新一代的机器人初创公司正在远离基于启发式和规则的编程,转而专注于端到端的神经网络。特斯拉最新的 FSD 软件就是一个端到端神经网络的例子,主要依赖于视觉和数据,而不是明确编码的控制。
然而,机器人技术继续面临显著的数据瓶颈,研究者正在探索各种技术来应对这一挑战。
虽然模仿学习和远程操作提供了高质量的数据,但它们可能无法单独扩展。最近,使用视频和模拟进行训练成为另一个有前景的方向,英伟达 Isaac Sim 和一些初创公司正在这方面进行研究。从概念上讲,谷歌的 RT-2 模型通过利用在互联网规模的视觉和语言数据上训练大型模型,并使用较小规模的机器人数据进行微调,展示了通用机器人性能的潜力。
在仿真中的主要挑战在于创建逼真的地面实况表示,以最小化仿真到现实的差距。这尤其困难,因为机器人具有多样的实体和形态,使得数据收集和标准化具有挑战性。最终,我们认为没有单一的方法能够解决所有这些挑战;需要结合远程操作、仿真和视频等多种技术才能使其发挥作用。如需进一步阅读此主题,请参阅 Spectrum.ieee 的文章(https://spectrum.ieee.org/solve-robotics)。
II. 未来值得关注的趋势:
“软件即服务”——AI 不仅为颠覆 4000 亿美元的全球 SaaS 市场提供了机会,也为颠覆 4 万亿美元的服务市场提供了机会。如今许多工作涉及重复性任务,使它们成为 AI 驱动自动化的理想候选。考虑到这些市场的规模,潜在影响显而易见:
总计,这代表了约 1.2 亿工人和近 4 万亿美元的薪资。对于这一主题的更详细分析,请参阅 Foundation Capital 的 Joanne Chen 和 Jaya Gupta 的文章(https://foundationcapital.com/ai-service-as-software/)。
“计算机使用(Computer Use)”是一个重要的转折点——Anthropic 最近引入了“计算机使用”,这使得开发人员可以指示 Claude 以智能体方式使用计算机——点击按钮、输入文本等。Claude 查看用户可见的屏幕截图,然后计算需要移动多少像素才能将光标移动到正确的位置点击。(有关计算机使用的深入案例研究,请参阅论文https://arxiv.org/pdf/2411.10323)
总的来说,使能 AI 智能体执行任务有两种方法。第一种是基于 API 的方法,将任务分解为子任务并通过串联 API 调用来执行。第二种方法,如 Anthropic 的“计算机使用”,是基于 UI 的方法,利用视觉和强化学习直接与浏览器交互以执行任务。换句话说,它教会模型像人类一样使用计算机。虽然后一种方法在较低级别的端到端方法中理论上更简单,但它需要更多的训练数据,可能计算成本更高。最终状态可能是基于视觉的,但目前,可能需要结合这两种方法的混合方法来优化性能和成本。这类似于在全自动驾驶(FSD)领域中发生的情况,完全依赖视觉的端到端神经网络逐渐取代了基于规则的控制。
计算机使用是机器人流程自动化(RPA)的一个重要突破。传统的 RPA 工具由于其脆弱性,经常面临挑战,因为当界面发生变化时,工作流程经常中断,需要持续的维护。通过 Anthropic 的计算机使用功能, AI 模型现在可以适应各种界面,减少了对硬编码脚本的依赖。这一突破已经产生了影响:在 Anthropic 宣布计算机使用后,UiPath 迅速将其 3.5 版 Sonnet 集成到其三个关键产品中。这一快速采用强调了计算机使用在推动 RPA 和智能自动化下一波浪潮中可能具有的变革性。然而,我们认为现在还为时过早——再次使用 FSD 类比,我们认为智能自动化仍处于 L1/L2 阶段。有关 RPA 的更详细讨论,请参阅 A16z 的 Kimberly Tan 的文章(https://a16z.com/rip-to-rpa-the-rise-of-intelligent-automation/)。
新的硬件形态。今年,出现了旨在补充甚至取代智能手机的新型硬件形态。尽管引起了关注,但迄今为止成功有限。例如,尽管Humane 的 AI 驱动的可穿戴别针筹集了 2 亿美元的资金,但其终身销售额仅略超过 900 万美元。更糟糕的是,据报道,每日退货率已经超过了新销售额。同样,Rabbit R1 也遭遇了极其糟糕的评价。
一个显著的成功案例是第二代 Meta + Ray-Ban 智能眼镜。这些设备在短短几个月内就超过了前一代两年的销售数字,并获得了普遍的好评。与此同时,主要的研究实验室和技术巨头也在探索这一领域。例如,OpenAI 最近聘请了前 Meta AR 硬件负责人 Caitilin Kalinowski,负责其机器人和消费硬件。此外,苹果设计偶像 Jony Ive 已与 Sam Altman 合作开展一个新的 AI 硬件项目。将大型生成式 AI 与新的硬件形态结合的潜力代表了一个令人兴奋的前沿。
具有增强的推理时能力的模型可以应对日益复杂的科学挑战。在这个领域中,最有希望的机会在于药物发现/生物医学、材料科学和物理/机器人技术。作为对开源的重大支持,Google DeepMind 最近发布了 AlphaFold 3 的代码和权重。这一意外宣布发生在系统创建者 Demis Hassabis 和 John Jumper 获得 2024 年诺贝尔化学奖后的几周内,以表彰他们的贡献。
在科学领域,初创公司可能会追求多种商业化路径:有些选择将其工具作为 SaaS 平台提供,有些则采用许可证模式,还有一些可能会作为主要智能体,直接将其解决方案推向市场,以捕获更大的 TAM(Total Addressable Market,总可寻址市场)。
正如 SaaS 从横向解决方案发展到垂直解决方案,我们预计 AI 领域也会出现类似的转变。在一个市场的生命周期早期,由于横向工具对广大市场具有广泛的吸引力而迅速获得关注。然而,随着市场的成熟和竞争的加剧,初创公司通常会转向专业化的、垂直的或特定领域的解决方案以实现差异化。在 AI 领域,这种向垂直化的转变似乎比在 SaaS 中更快,原因有几个关键点:
AI 依赖特定领域的数据:当 AI 在特定行业或用例的数据上进行训练时,其表现最佳。许多行业拥有高度专业化的数据集,使得专业化或垂直化训练更加有效。例如,在 RAG 中,理解领域上下文对于检索准确性至关重要。
拥挤的横向市场:与 SaaS 早期不同,许多已有的市场领导者已经在大力投资生成式 AI ,并推出横向解决方案。这些市场领导者通常已经是他们目标用例的记录系统,无论是 Salesforce 的 CRM,SAP 的 ERP,或其他系统。这使得市场领导者在分销和集成方面具有显著优势。对于初创企业,瞄准垂直化或专业化的市场可能使它们能够开辟出更可防御的市场地位,从而提高成功的机会。
关键行业的监管严格性:受监管的行业如医疗保健、法律和金融有严格的监管要求。这些要求最有效地通过针对每个行业独特需求的垂直化方法来满足。
GenAI 消费者公司尚未爆发。今年,许多领先的 AI 消费者初创公司最终被收购。例如,我们在消费者 GenAI 领域观察到了两起人才收购——Google 与 Character.AI 的交易和 Microsoft 与 Inflection 的交易。我们认为,消费者 GenAI 应用尚未爆发,主要原因是两个:
首先,除了像 ChatGPT 和 Perplexity 这样的聊天机器人之外,还没有出现杀手级的消费者使用案例。虽然 Character.AI 可以说已经实现了产品与市场的契合,但其相对狭窄的人群吸引力——超过一半的用户年龄在 18 到 24 岁之间——限制了其更广泛的发展潜力。我们认为,下一个变革性的消费者应用将是一个功能强大的个人助手(一个更智能的 Siri),长远的愿景是为每个人提供个性化的数字孪生。
其次,成功的消费者应用通常在初期需要病毒式采用,有时由公司提供的前期使用补贴推动。然而,目前的 token 成本——尤其是多模态模型的 token 成本仍然过高,无法实现大规模补贴的经济可行性。随着 token 成本的降低和/或更多工作负载转移到边缘,我们预计,新一代的生成式 AI 消费者公司将会出现。
III. 值得关注的初创公司:
开发者 / 代码生成:
Augment Code、CodeComplete、Codeium、Cognition、Cursor、Magic.dev、Poolside、TabbyML、Tabnine、Tessl
企业生产力:
Consensus、Dust.AI、Exa、Fireflies.AI、Glean、Highlight、Mem、Otter.AI、Read.AI、Taskade、Wokelo AI
消费者:
Genspark、MultiOn、Liner、Ninjatech.AI、Perplexity、Simple AI、You.com
多模态:
Black Forest Labs、Captions、Coactive、Creatify、Deepbrain、Descript、HeyGen、Ideogram、Luma、Openart.AI、Opus Clip、PhotoRoom、Runway、Synthesia、Viggle AI
下一代 RPA:
Automat、Caddi、HappyRobot、Orby、Sola、Tektonic AI
通用机器人:
ANYbotics、Bright Machines、Field AI 、Hillbot、Path Robotics、Physical Intelligence、Skild AI、Swiss-Miles、World labs
人形机器人:
1x Technologies、Figure AI
通用智能体 / 补全助手:
DeepOpinion、Ema、FactoryAI 、Gumloop、Jasper、Lyzr、Relevance AI、Sierra、Squid AI、Stack AI、Tektonic AI、Wordware、Writer
人力资源/招聘:
Converz AI、Eightfold、Jobright.AI、Mercor、Micro1、Moonhub
客户支持:
AptEdge、Cresta、Decagon、MavenAGI
销售和市场:
11x、Adsgency、Artisan AI、Bounti. AI、Connectly AI、Typeface、Style AI、Mutiny、Nectar AI、Nooks、Omneky、Rox、Simplified
产品设计与工程:
Ambr、Skippr、Uizard、Vizcom
芯片设计:
Astrus、Mooreslab
演示文稿编辑:
Beautiful.AI、Gamma、Tome
垂直领域——医疗保健:
Abridge, Ambience Healthcare、Atropos Health、C AI r Health*、Hippocratic AI、Hyro、Nabla、Scribenote、Segmed.AI、Slingshot AI、Suki AI、Tennr
垂直领域 - 财务和采购:
AskLio*、Auditoria. AI、Finpilot、Hebbia、Klarity、Kipoparts、Linq Alpha、Menos AI、Rogo、Spine AI *
垂直领域——法律:
Casetext (Thomson Reuters)、Cicero、EvenUp、Genie AI、Harvey AI、Leya、Robin AI、Solomon AI, Solve Intelligence*、Spellbook/Rally
垂直领域——教育和语言:
Elsa、Eureka Labs、MagicSchool AI、Pace AI、Praktika、Riiid、Sana、Speak、Uplimit*
垂直领域——游戏和娱乐:
Altera、Inworld AI
垂直领域——合规:
Greenlite、Norm AI
垂直领域——房地产:
Elise AI
垂直领域——汽车维修:
Carvis. AI、Revv
AI投资与并购
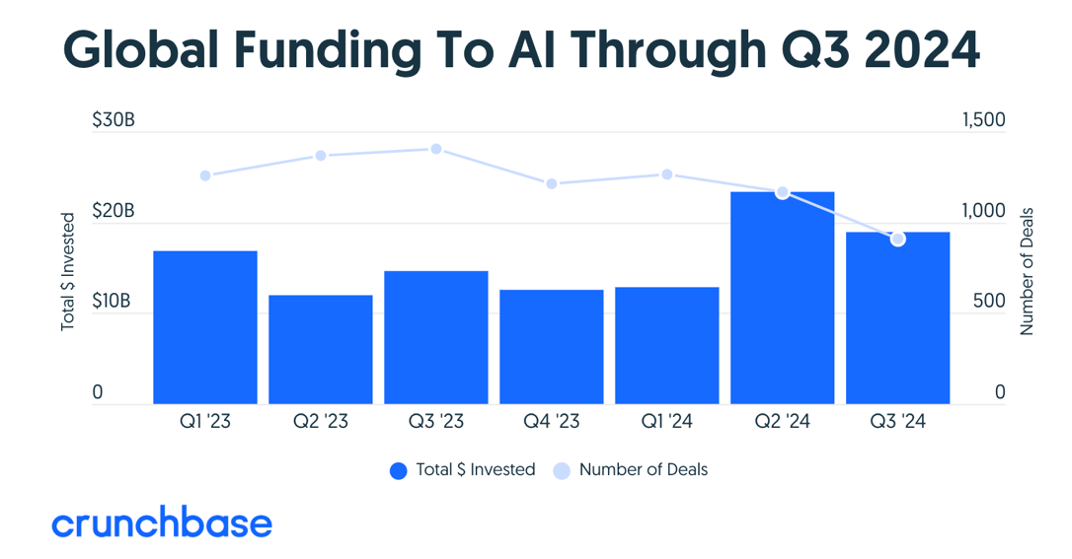
AI投资:
截至今年(YTD)的 AI 投资已超过 600 亿美元,占所有风险投资的三分之一以上。最大的融资轮次继续集中在基础设施和模型层,主要融资来自 OpenAI(66 亿美元)、x AI(50 亿美元)、Anthropic(40 亿美元)、SSI(10 亿美元)和 CoreWeave(10 亿美元)。不断增长的计算需求仍然是关键驱动因素,仅 OpenAI 今年预计就将花费 30 亿美元用于训练计算。
一些应用公司,特别是在代码生成领域,也筹集了大量资金,因为他们正在预训练自己的代码生成模型。其他获得投资者广泛关注的领域包括 AI 芯片、 AI 云、机器人基础模型和企业 AI 。要查看今年筹集超过 1 亿美元的 AI 初创公司完整名单,请参阅 TechCrunch 的文章(https://techcrunch.com/2024/11/15/heres-the-full-list-of-44-us-ai-startups-that-have-raised-100m-or-more-in-2024/)。
投资者对 AI 初创企业的需求依然强劲,许多公司在其生命周期的早期就获得了大量资金。像 SSI 和 World Labs 这样的初创公司已经达到了独角兽地位,这得益于其创始团队的卓越背景。尽管整体 AI 估值仍然很高——平均收入倍数为 26 倍——但由于大量新的初创公司在这一领域建立,投资者变得更加挑剔。例如,最近的 YC 夏季批次创业公司中中, AI 初创企业占 75%。
并购
“反向收购雇佣(reverse acquihires)”的兴起。即现有公司雇佣初创公司大部分团队,有时还会获得其技术许可,从而绕过全面收购的复杂性。这种策略使大型科技公司能够在避免监管审查的同时增强其 AI 能力。关键例子包括:
微软 / Inflection AI——微软从 Inflection AI 招募了关键人员,最著名的是首席执行官 Mustafa Suleyman,他现在负责微软的整个 AI 产品组合,包括 Copilot、Bing 和 Edge,并直接向纳德拉汇报。鉴于 Mustafa 角色的范围,这个价格标签可能是值得的。
亚马逊 / Adept AI——亚马逊收购了 Adept AI 三分之二的员工,包括首席执行官 David Luan,并获得了该公司基础模型的非独家许可。该公司以 2500 万美元的价格达成了许可协议,而其投资者,此前向公司投资了 4.14 亿美元,将大致收回他们的投资成本。
Google / Character.AI——通过此次收购,Google 迎来了 CEO Noam Shazeer、总裁 Daniel De Freitas 以及 Character.AI 约 30 名员工,这笔交易的估值为 27 亿美元,超过该公司上次估值的 2.5 倍。
今年的总并购活动(估计约为 20 亿至 30 亿美元)相对较为平静。这与去年类似,去年只有三笔重大收购(MosaicML、CaseText、Neeva)。有趣的是,今年 8 笔知名收购中有 5 笔是在工具层,其中 4 笔在推理优化领域(OctoAI 、Deci、Run:AI 、Neural Magic)。知名的收购包括:
Snowflake 收购 Datavolo(金额未披露)
Red Hat 收购 Neural Magic(金额未披露)
Nvidia 以约 2.5 亿美元收购 Octo AI
Nvidia 收购 Deci,金额约为 3 亿美元
Nvidia 以约 7 亿美元收购 Run: AI
DocuSign 以约 1.65 亿美元收购 Lexion
思科收购了 Robust Intelligence(金额未披露)
Canva 收购了 Leonardo.AI (金额未披露)
短期内,由于收购方和初创公司之间的期望差异,我们可能会看到有限的并购活动。尽管收购方兴趣浓厚,但由于估值预期的差距,并购活动可能仍会受到限制。一家领先的 SaaS 公司的企业发展主管指出,虽然他们对收购 AI 初创公司感兴趣,但通常存在显著的估值差距。现有收购方认为,由于他们已有的客户基础和分销优势,他们应该获得收购折扣,而 AI 初创公司及其投资者则期望获得溢价,部分原因是市场估值较高。这种期望的不匹配可能会继续抑制短期内的并购活动。
并购整合可能会在 AI 周期的末期发生。在电信/互联网时代,大多数并购交易发生在十年的后半段。仅 1999 年一年,就有超过 3 万亿美元的并购交易。通常,当经济变得更加成熟,赢家基本确定时,整合就会发生。今天 AI 领域缺乏显著的整合,这也表明我们仍处于 AI 发展的早期阶段。
7
其他 AI 趋势:主权 AI 、版权和法规
主权 AI:
随着 AI 的普及,主权 AI 的概念正引起越来越多的关注。许多政府的核心关切是,他们是否愿意让敏感数据在像 ChatGPT 这样的平台上处理,而这些平台由其他国家控制。更广泛的地缘政治裂痕在 AI 世界的微观层面上日益显现,导致不同地区出现了各自独立的 AI 生态系统。
一个关键的考虑是:主权 AI 将在 AI 堆栈的哪一层出现?当前的发展表明,它主要将在基础设施和模型层显现。对于投资者来说,这为支持特定地区的初创公司提供了独特的机会,因为全球各地正在形成不同的生态系统。成功不一定需要支持全球领导者;区域冠军也能在本地市场中脱颖而出。
让我们简要回顾一下各主要地区的一些 AI 发展和战略:
美国:美国在生成式 AI(GenAI)的所有技术栈层面上继续引领创新。像 OpenAI 、Anthropic 和 Meta 这样的主要 AI 实验室在深厚人才库和世界级学术机构的支持下,主导了技术进步。在基础设施方面,美国的超大规模云服务提供商提供了无与伦比的计算能力,而 Nvidia 在硬件方面保持领先地位。这种集成的生态系统使美国在短期内至中期内具有显著优势。
中国:为应对半导体出口管制,中国正优先发展其国内芯片产业。5 月,政府宣布设立 475 亿美元的国家半导体投资基金,以增强其芯片产业。尽管硬件方面落后,中国的 LLM,如阿里巴巴的 Qwen 和 DeepSeek,仍然具有高度竞争力。令人惊讶的是,中国在生成式 AI 采用方面处于领先地位,83%的公司正在测试或实施该技术——超过了美国(65%)和全球平均水平(54%)。
欧洲:欧洲的严格法规,如欧盟 AI 法案,可能会抑制 AI 创新。法规已经导致包括 Meta 和 X 在内的美国科技巨头推迟在该地区的 AI 部署。苹果也因类似原因决定不在欧洲推出其最新 iPhone 的 Apple Intelligence。尽管欧洲拥有 Mistral AI 等杰出实验室,但它们目前是否有能力独立与美国的云服务提供商和 AI 实验室竞争仍不清楚,尤其是在监管障碍的背景下。
日本:日本在数据中心基础设施方面正经历显著增长。甲骨文最近宣布将投资 80 亿美元建设新的数据中心,紧随微软 30 亿美元的投资承诺。在模型层面上,Sakana AI 已成为关键参与者,最近完成了 2 亿美元的 A 轮融资(Translink 是投资者之一)。日本政府通过宽松的监管和强有力的支持来促进 AI 创新,认识到 AI 是应对老龄化人口和日益增长的自动化需求的关键技术。巨大的市场机遇加上政府的支持,使日本成为 AI 创新和初创企业的有前景市场。
AI 和版权:
随着生成式 AI 内容变得越来越普遍, AI 与版权法的交汇正成为一个关键问题。最近的争议,如苹果、英伟达和 Anthropic 被指控未经许可使用 YouTube 视频训练 AI 模型,突显了知识产权侵权的担忧。同样,环球、索尼和华纳等主要唱片公司正在起诉 Suno 和 Udio 等 AI 初创公司,原因是这些公司使用受版权保护的音乐生成内容。这些纠纷凸显了创新与保护创意资产之间的紧张关系。
新闻行业也在应对这些挑战。新闻集团最近因涉嫌虚假归属和与其出版物相关的幻觉问题起诉了 Perplexity AI ,同时与 Open AI 达成了 2.5 亿美元的合作伙伴关系,以提供对其档案的访问。这些举措反映了 AI 对传统媒体带来的风险和机遇。
尽管存在这些争议,一些平台正在利用 AI 来增强创造力和合规性。例如,Spotify 正在使用生成式 AI 来个性化用户体验,同时遵守版权法。这表明,只要存在明确的框架, AI 和知识产权可以共存。
一些公司正在努力解决这个问题。一个有趣的初创公司是 Tollbit,它通过帮助出版商将其内容商业化,来弥合出版商和 AI 开发者之间的差距。另一个是 ProRata. AI ,它正在开发归属技术,以实现对内容所有者的公平补偿。在创新与保护创作者权利之间取得平衡将是未来几年的关键话题。
AI 法规:
欧盟 AI 法案发布了此类法规的首个全面框架,根据风险级别对 AI 系统进行分类:不可接受、高、有限和最小。被认为“不可接受风险”的系统,如政府的社会评分或操纵性 AI 将被禁止,而关键领域的“高风险”系统将面临严格的要求。
关键条款包括强制性合规评估、强有力的文档记录和欧洲 AI 委员会的监督。不合规可能导致最高 3000 万欧元或全球收入 6% 的罚款。
2024 年 11 月连任后,特朗普宣布将在上任后废除拜登的 AI 行政命令。特朗普政府认为,现有的规定抑制了创新,给企业带来了不必要的负担。相反,他们主张采取更有利于行业的做法,强调自愿指南和减少联邦监管,以促进 AI 的发展。
结语

即刻体验加速版DeepSeek-V2.5
cloud.siliconflow.cn
扫码加入用户交流群

内容中包含的图片若涉及版权问题,请及时与我们联系删除


评论
沙发等你来抢