
【论文标题】Neuro-Symbolic Representations for Video Captioning: A Case for Leveraging Inductive Biases for Vision and Language 【作者团队】Hassan Akbari,Hamid Palangi,Jianwei Yang,Sudha Rao,Asli Celikyilmaz,Roland Fernandez,Paul Smolensky,Jianfeng Gao,Shih-Fu Chang 【发表时间】2020/11/18 【论文链接】https://arxiv.org/abs/2011.09530 【代码链接】https://github.com/hassanhub/R3Transformer
【推荐理由】 本文出自哥伦比亚大学,针对视频描述任务,作者基于字典学习方法提出了一种新的能够学习多模态神经符号表征的模型架构,可以有效学习视频与相对应的文本描述之间的关系。
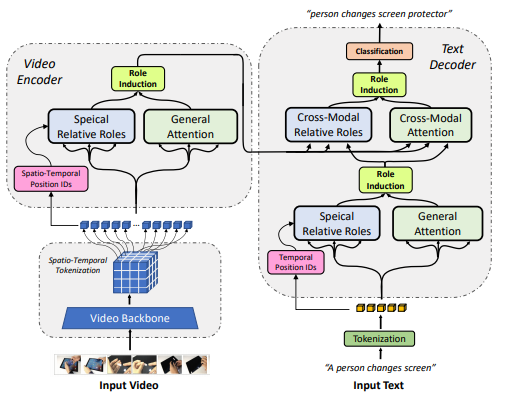
近年来,多项研究成果表明,「神经-符号」表征在学习视觉和语言的结构信息时是十分有效的。在本文中,作者提出了一种新的、为视频描述学习多模态神经符号表征的模型架构。本文提出的方法使用基于字典学习的方法来学习视频和与其配对的文本描述之间的关系。本文作者将这些关系称为「相对角色」,并利用它们使用注意力机制使每个词例都与这种角色相关。通过这种方法,作者构建了一种更加结构化和可解释的架构,该架构向视频描述任务中融入了特定模式的归纳偏置。直观地说,该模型能够为给定的一对视频和文本学习空间、时序和跨模态的关系。本文提出的方案所实现的解耦赋予了模型更强的捕获多模态结构的能力,从而产生了质量更高的视频描述。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢