
在人工智能领域,强化学习(RL)一直被视为解决复杂序列决策问题的有力工具。这项技术不仅在电子游戏、棋类智能、机器人控制、自动驾驶等前沿领域大放异彩,还在大语言模型(LLM)的微调、对齐、推理等关键阶段发挥着重要作用。
然而,RL的训练过程常常表现出显著的不稳定性,这不仅影响了算法的最终性能,也限制了其在真实物理场景中大规模应用的潜力。
面对这一挑战,清华大学智能驾驶课题组(iDLab)提出了RL专用的神经网络优化方法——RAD优化器(Relativistic Adaptive gradient Descent)。
相较于9个主流神经网络优化器(包括SGD-M,Adam和AdamW等),在12个测试环境(包括1个CartPole任务、6个MuJoCo任务、4个Atari任务和1个自动驾驶任务)及5种主流RL算法(包括DQN、DDPG、TD3、SAC和ADP)下,RAD综合性能均排名第一。特别在图像类标准测试环境Seaquest任务中,RAD性能达到Adam优化器的2.5倍,得分提升了155.1%。

- 论文标题:Conformal Symplectic Optimization for Stable Reinforcement Learning
- 论文地址:https://ieeexplore.ieee.org/document/10792938
- 代码仓库:https://github.com/TobiasLv/RAD
神经网络参数优化=动力学系统状态演变
价值函数和策略函数是RL算法的关键部件,二者交替迭代更新是RL训练的核心步骤。当前主要以深度神经网络作为价值函数和策略函数的载体,其训练过程通常依赖于神经网络优化器以实现参数更新。
然而,目前主流的神经网络优化器(如SGD-M、Adam和AdamW等)虽然在缓解局部最优和加速收敛方面有所帮助,但其算法设计和参数选择均依赖于人工经验和实用技巧,缺乏对优化动态特性的解释与分析,难以从理论上保障RL训练的稳定性。
清华大学的研究者从动力学视角出发,将神经网络参数的优化过程建模为多粒子相对论系统状态的演化过程,通过引入狭义相对论的光速最大原理,抑制了网络参数的异常更新速率,同时提供了各网络参数的独立自适应调节能力,从理论上引入了对RL训练稳定性和收敛性等动态特性的保障机制。
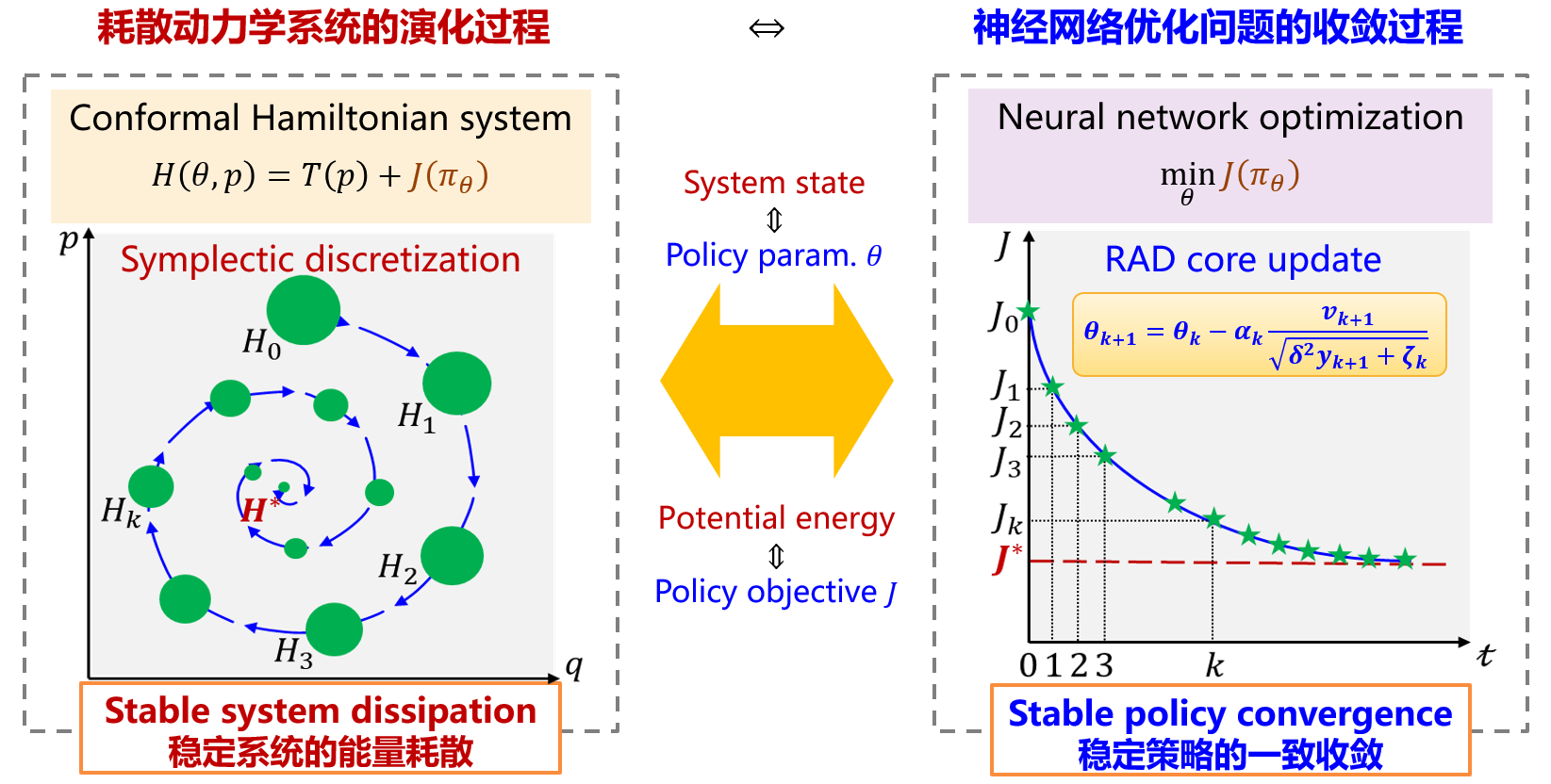
进而,研究者提出了既具备稳定动力学特性又适用于深度神经网络非凸随机优化的RAD优化器(伪代码见算法3)。

特别的,当速度系数\( \delta \)设为1且保辛因子\( \zeta_k \)固定为小常数时,RAD优化器将退化为深度学习中广泛采用的Adam优化器。这一发现也为从动力学视角探究其他主流自适应梯度优化方法(如AdaGrad、NAdam、AdamW和Lion等)开辟了全新路径。
标准测试任务的实验分析
研究者在5种主流RL算法(包括DQN、DDPG、TD3、SAC和ADP)和12个测试环境(包括1个CartPole任务、6个MuJoCo任务、4个Atari任务和1个自动驾驶任务)中对RAD优化器进行了广泛测试,并与9种主流神经网络优化器(包括SGD、SGD-M、DLPF、RGD、NAG、Adam、NAdam、SWATS和AdamW)进行了比较,以下介绍部分重要结果。
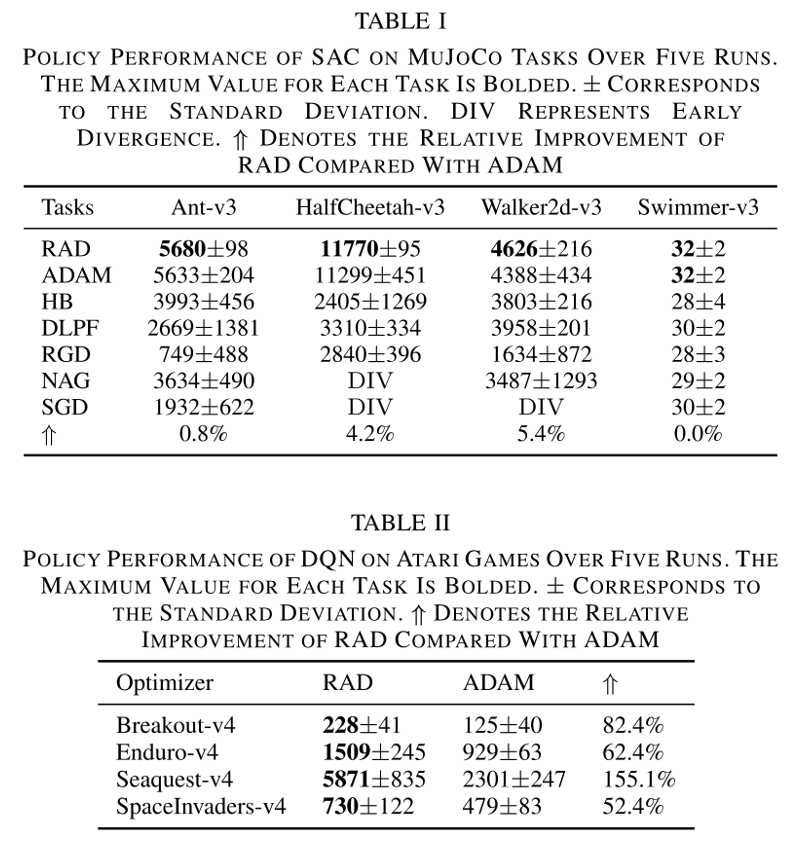
MuJoCo多关节机器人控制任务和Atari游戏环境的测试表明,RAD在所有基准测试中均展现出卓越的收敛速度和性能。与RL领域广泛使用的Adam优化器相比,RAD在Walker2d任务中的性能提升了5.4%(见表I),而在Seaquest任务中的性能提升更是达到了显著的155.1%(见表II)。
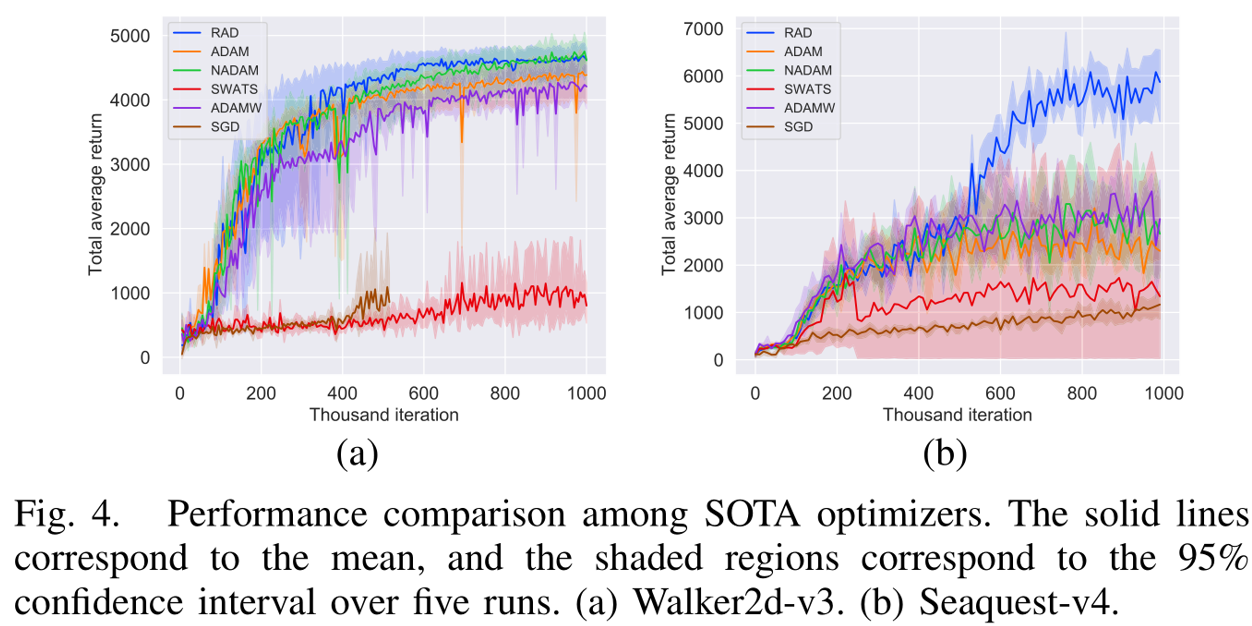
与其他SOTA自适应梯度优化器相比,RAD在保持计算效率和内存占用相当的情况下(均维护一阶动量v和二阶动量y),同样表现出优越性(见图4)。研究者还指出,诸如NAdam和AdamW等Adam变体所采用技术与RAD互补,未来工作将探索将这些技术整合到RAD中,以期进一步提高性能。
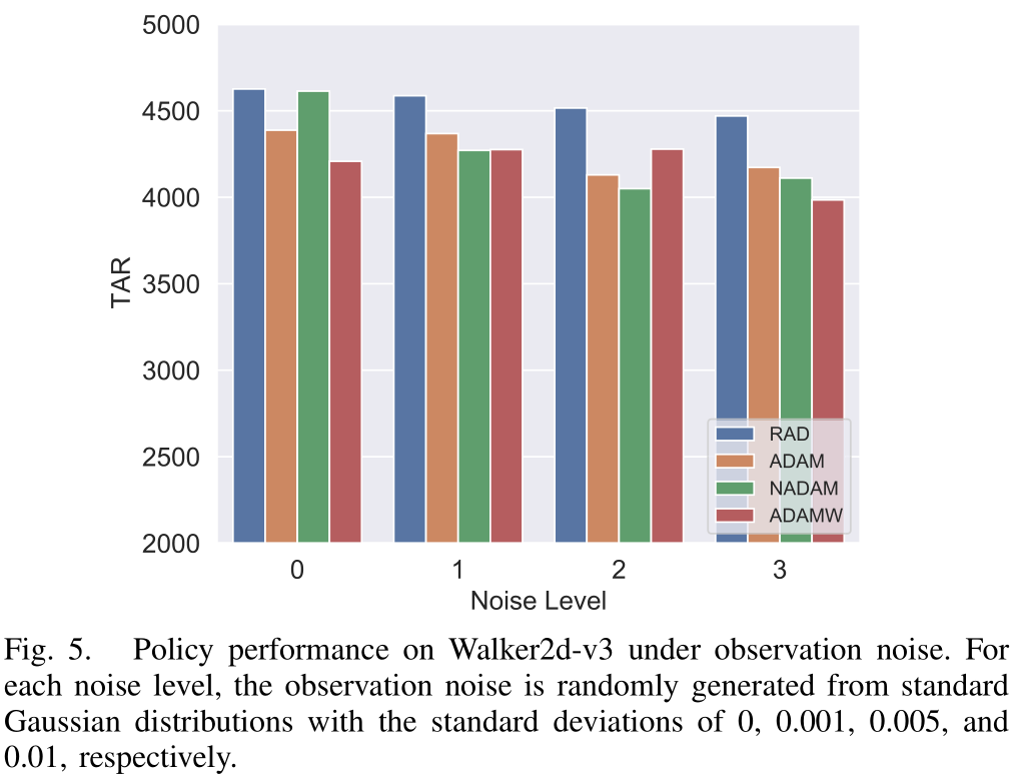
为评估RAD在受扰动环境中的鲁棒性,研究者在Walker2d任务中针对不同观测噪声水平进行了对比实验。结果表明(见图5),RAD因其出色的保辛性质(保留原动力学系统的稳定演化和收敛特性),展现出对噪声的显著抵抗力。即使在最高噪声水平下,RAD性能下降也相对较小,仅为3.4%;相比之下,NAdam的性能下降达到了10.9%。
以上结果证明了RAD优化器在所有RL基准测试中均达到SOTA性能,可有效解决RL算法长时域训练的失稳难题,是解决各类RL训练任务(特别是那些对长期稳定性和收敛性能有高要求的复杂任务)的一个强有力的优化工具。
参考链接
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢