

人工智能的未来不仅仅是预测下一个词语,更是理解下一个想法!

Large Concept Models: Language Modeling in a Sentence Representation Space
https://arxiv.org/abs/2412.08821
https://github.com/facebookresearch/large_concept_model
什么是 LCMs?LCMs 与 LLMs 有何不同
自 2022 年底 ChatGPT 诞生以来,我们一直生活在生成式人工智能时代,“LLMs”一词已成为每个人生活的核心。
但最近,你一定听说过一些“技术大佬(big tech guys)”提到 LLMs 的增长正在趋于平稳。
那么,接下来该怎么做?
Meta 最近推出了 LCMs(大概念模型),这看起来是下一个重大步骤,是 LLMs 的重大升级。
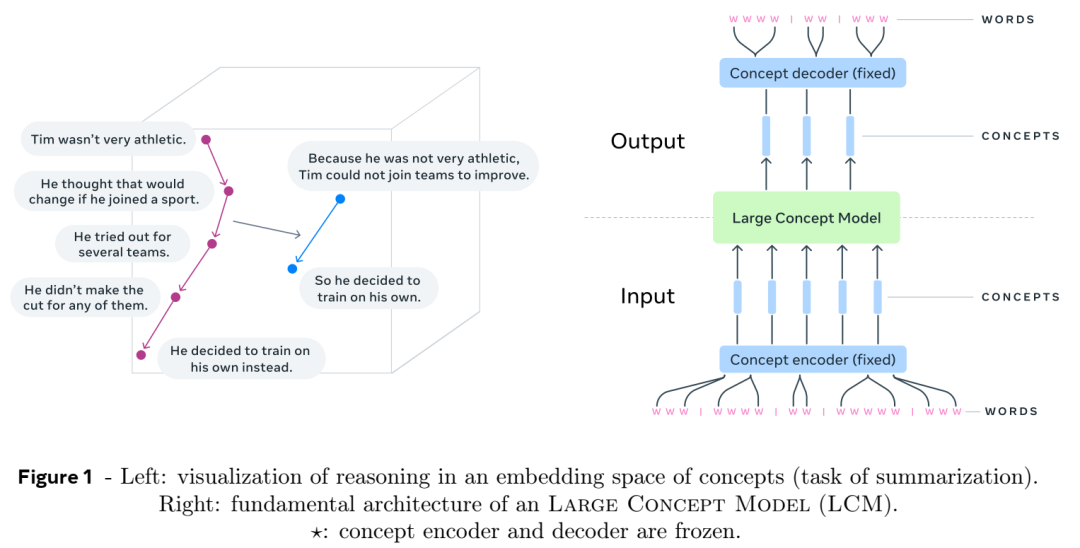
什么是大概念模型(Large Concept Models)?
Meta 的大概念模型 (LCM)代表了一种新颖的语言建模方法,与传统的大型语言模型 (LLM)相比,它在更高的抽象层次上运行。
LCM 不是在标记级别处理文本,而是处理概念,概念是与语言和模态无关的高级想法或动作的表示。
在 Meta 的 LCM 框架中,概念被定义为抽象的原子想法。在实践中,概念通常对应于文本中的句子或等效的语音话语。这使得模型能够在更高的语义层面上进行推理,而不受特定语言或模态(例如文本、语音或图像)的影响。
这到底意味着什么?
让我们看一个例子

传统语言模型 (LLM):逐词预测
想象一下,您正在写一个故事,并且正在使用像 ChatGPT 这样的传统语言模型。它的工作原理是根据您已经写过的单词来预测下一个单词(或“token”)。例如:
你写道:“猫坐在…”
该模型预测:“mat”。
这就像是一次填一个单词。这种方法效果很好,但它过于关注个别单词,而并不总是考虑大局或句子的整体含义。

Meta 的大概念模型 (LCM):逐个想法的预测
现在,想象一下,模型不再预测下一个单词,而是预测下一个想法或概念。概念就像一个完整的想法或句子,而不仅仅是一个单词。例如:
你写道:“猫坐在垫子上。那是一个阳光明媚的日子。突然……”
模型预测:“厨房里传来一声巨响。”
在这里,模型不只是猜测下一个单词;它正在思考接下来应该出现的整体想法。这就像以块为单位规划故事的下一部分,而不是逐字逐句地规划。
这为什么很酷?
独立于语言:
该模型并不关心输入的是英语、法语还是其他语言。它根据句子的含义进行分析,而不是根据具体的单词进行分析。例如:
输入英文:“猫饿了。”
用法语输入:“Le chat a faim。”
这两个句子的意思相同,因此模型将它们视为相同的概念。
多模态(适用于文本,语音等):
该模型还可以处理语音甚至图像。例如:
如果你说“猫饿了”,或者展示一张饥饿猫的图片,模型就会理解同样的概念:“猫需要食物”。
更适合长篇内容:
在撰写长篇故事或文章时,模型可以规划思路的流程,而不是停留在个别单词上。例如:
如果您正在撰写研究论文,该模型可以帮助您概述要点(概念),然后对其进行扩展。
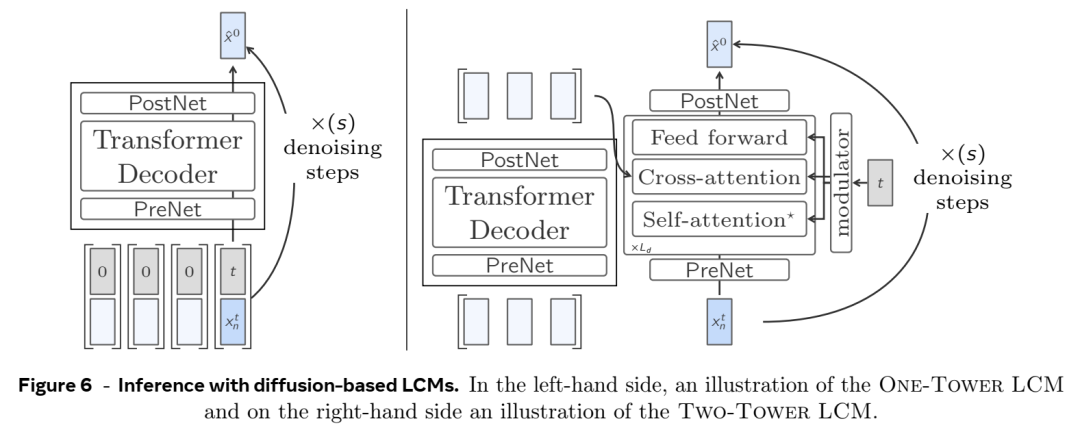
架构
输入处理:
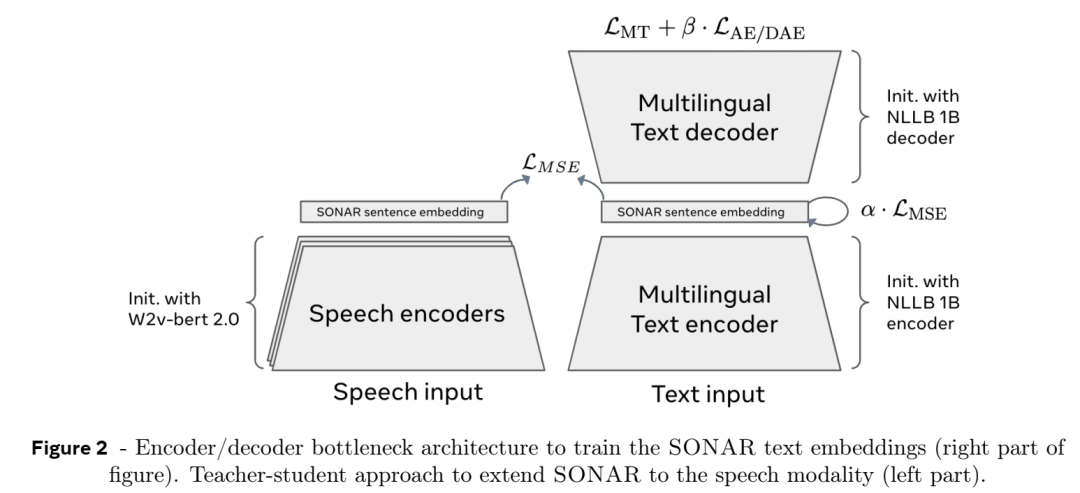
输入文本首先被分割成句子,然后使用预先训练的句子编码器(例如SONAR )将每个句子编码为固定大小的嵌入。SONAR 支持多达 200 种语言,可以处理文本和语音输入。
这些嵌入表示输入序列中的概念。
大概念模型(LCM):
LCM 处理概念嵌入序列并预测序列中的下一个概念。该模型经过训练可在嵌入空间中执行自回归句子预测。
LCM 的输出是概念嵌入的序列,然后可以使用 SONAR 解码器将其解码回文本或语音。

输出生成:
生成的概念嵌入被解码为文本或语音,产生最终输出。由于 LCM 在概念层面运行,因此相同的推理过程可以应用于不同的语言或模态,而无需重新训练。
LCM 支持零样本泛化,这意味着它可以应用于未明确训练的语言或模式,只要 SONAR 编码器和解码器支持它们。
这里需要理解的几个关键点是:
SONAR 嵌入空间:
SONAR 是一个多语言和多模态句子嵌入空间,支持 200 种文本语言和 76 种语音语言。
SONAR 的嵌入是固定大小的向量,可以捕捉句子的语义,使其适合概念级推理。
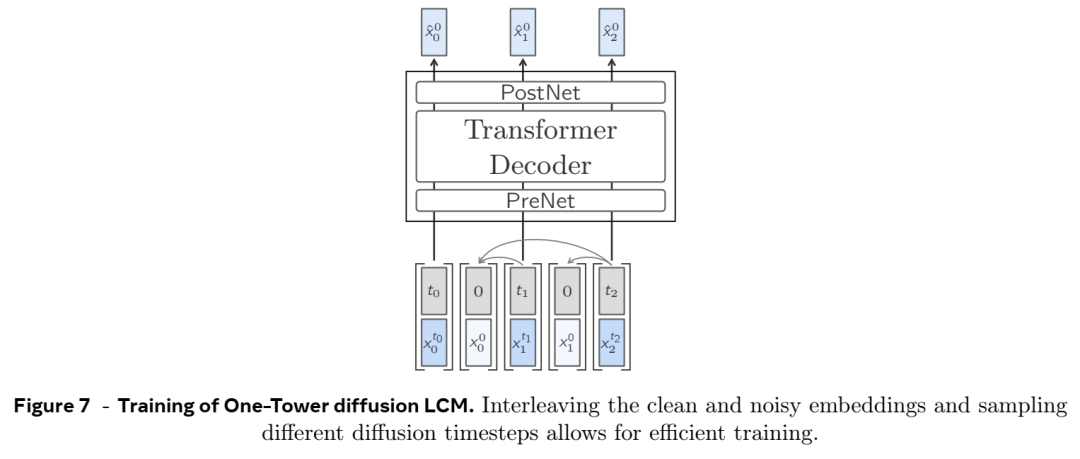
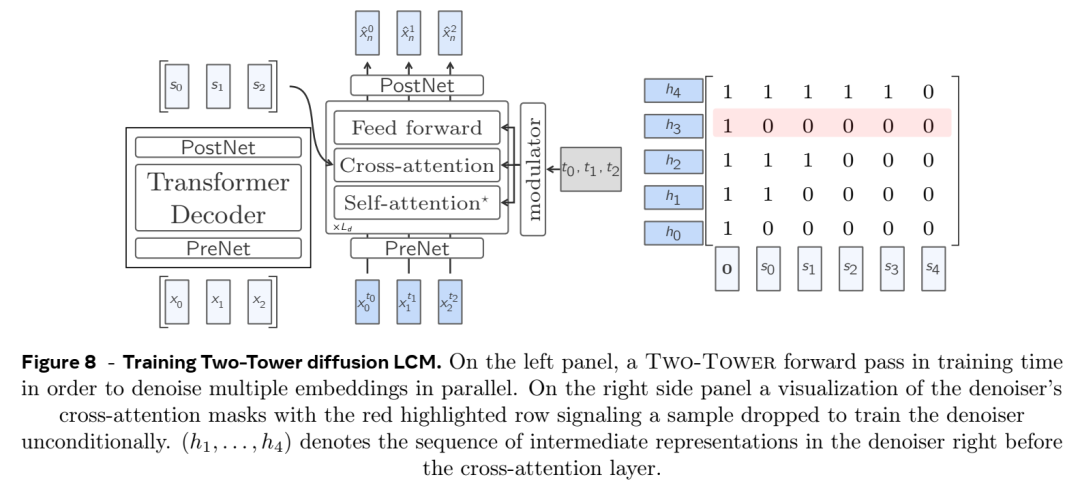
基于扩散和量化的生成:
Meta 探索了几种训练 LCM 的方法,包括基于扩散的生成。扩散模型用于通过学习连续嵌入空间上的条件概率分布来预测下一个概念嵌入。
另一种方法是将 SONAR 嵌入量化为离散单元,并训练 LCM 预测下一个量化概念。这可以实现更可控的生成和采样,类似于 LLM 从词汇表中采样标记的方式。
LCM 与 LLM
1.抽象层次
LLM :在标记级别工作,预测序列中的下一个单词或子词。
LCM :在概念层面上工作,预测序列中的下一个句子或想法。
2. 输入表示
LLM:处理特定语言中的单个标记(单词或子单词)。
LCM:处理与语言和模态无关的句子嵌入(概念)。
3. 产出生成
LLM:逐字生成文本,注重局部连贯性。
LCM:逐句生成文本,注重整体连贯性和高级推理。
4. 语言和模态支持
LLM:通常针对特定语言和模态(例如文本)进行训练。不过,多模态 LLM 可以支持多种模态。
LCM :旨在通过共享概念空间处理多种语言和模式(例如文本、语音、图像)。
5. 训练目标
LLM:经过训练以最小化token 预测误差(例如交叉熵损失)。
LCM:训练以最小化概念预测误差(例如,嵌入空间中的均方误差)。
6.推理和规划
LLM:隐式学习分层推理但在本地进行操作(逐个标记)。
LCM:明确地模拟层次推理,在句子或想法层面进行规划。
7.零样本泛化
LLM :在未受过训练的语言或模式下进行零样本任务时遇到困难。
LCM:由于采用基于概念的方法,因此在跨语言和模态的零样本泛化方面表现出色。
8. 长上下文的效率
LLM :由于注意力机制的二次复杂性,处理长上下文时存在困难。
LCM :在处理长上下文时效率更高,因为它处理的句子嵌入序列比标记序列短。
9. 应用
LLM:最适合文本完成、翻译和问答等字级任务。
LCM:最适合句子级任务,如总结、故事生成和多模态推理。
10.灵活性
LLM:仅限于基于文本的任务,需要重新培训新的语言或模式。
LCM:得益于基于概念的设计,它可以灵活地跨语言和模式,无需再培训。
总之,Meta 的大概念模型 (LCM) 代表了语言建模的重大飞跃。通过在概念层面进行操作,LCM 提供了一种更抽象、与语言无关和多模态的推理和生成方法。虽然 LLM 擅长逐字任务,但 LCM 在总结、故事生成和跨模态理解等更高级别的应用中大放异彩。随着人工智能的不断发展,LCM 可以为更直观、更像人类的机器交互铺平道路,将行业从教育转变为娱乐。



内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢