
自然语言处理被誉为人工智能皇冠上的明珠,一方面指实现语言智能十分艰难。当我们叹服于机器人在电竞、围棋频频超越人类水准时,现有的语言系统,仍然无法达到3、4岁孩童的语言和理解能力。另一个方面也是因为自然语言处理本身对于实现智能的重要性,论坛主持人孙茂松认为,自然语言处理是机器智能难以逾越的鸿沟,已经成为限制人工智能取得更多突破的瓶颈之一。因此,本论坛汇聚了从事自然语言处理、知识图谱、计算机视觉等领域的众多顶尖学者,针对当前自然语言处理领域的发展提出思考和看法,并从多学科的角度,为启发新一代的自然语言处理技术,解决其当前面临的三大真实挑战,积极交流了看法。
 从左到右:孙茂松、张家俊、何晓东、颜水成、宋森、万小军、赵鑫、刘知远
从左到右:孙茂松、张家俊、何晓东、颜水成、宋森、万小军、赵鑫、刘知远
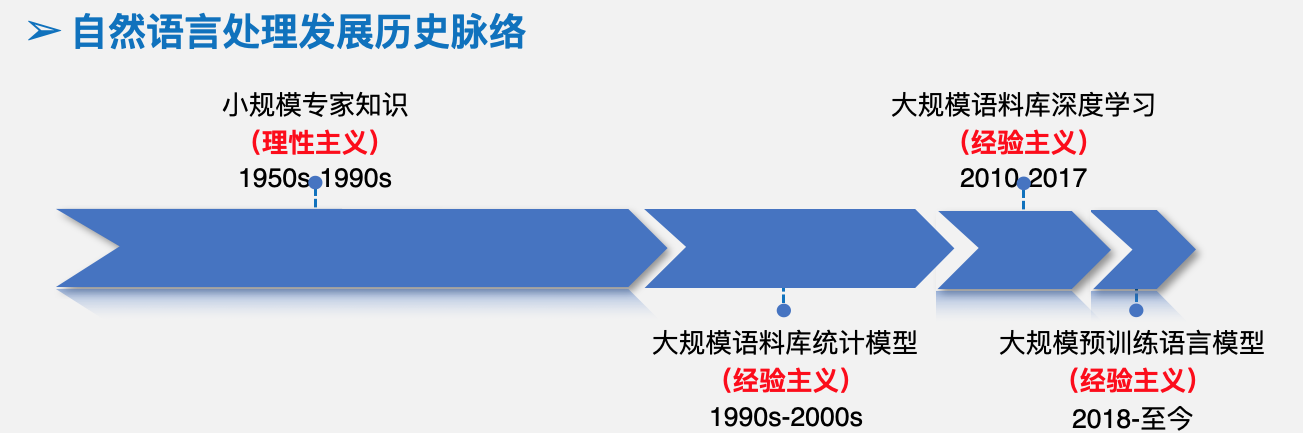
清华大学孙茂松教授在引导报告《自然语言处理面临的三大真实挑战》中阐述了对于自然语言处理发展前景的看法。指出自然语言处理在历史上有两大范式——理性主义、经验主义,经验主义从九十年代到现在分为多个方向,2018年到现在,是大规模预训练语言模型。
”但大规模预训练模型并不能真正理解更有深度的问题“,孙茂松教授说:”因此并不能一味追求大规模的趋势,而是应该多轨共同发展。”孙教授提出了当前亟待攻破的挑战,分别是:
形式化知识系统存在明显构成缺失。例如现有的知识图谱大而不强,虽然规模大,但是实体间关系浅,缺少关于动作的三元组,及事件间的逻辑关系。称之为知识图谱“三缺其二”。
深层结构化语义分析存在明显性能不足。解决知识图“三缺其二”问题依赖于对语言进行深层次语义分析。近年来对语义的分析取得了长足的进步,但是对深层结构化语义分析“欲行却止”。
跨模态语言理解存在明显融通局限。目前对跨模态语言理解的研究方兴未艾,是新的重要研究前沿,但是跨模态关系因缺乏深层结构化语义分析和世界知识导致推理能力较弱,存在“形合意迷”的问题。
针对这三大挑战,孙茂松教授提出了与其对应的三个目标愿景:知识图谱从“三缺其二”到“三分归一”;深层结构化语义分析从“欲行却止”到“且行且进”;跨模态语言理解从“形合意迷”到“形合意合”。以跨模态、大数据、富知识“三足”,通过经验主义加理性主义的研究方法,迎接挑战。
论坛的讨论由此展开,嘉宾学者纷纷对孙茂松教授的观点发表了看法和理解。
论坛讨论:富知识

来自中科院的研究员张家俊老师非常认可大数据、富知识以及多模态对于实现自然语言处理的终极目的重要性。
张老师长期从事数据和知识的结合以及以文本为核心的多模态信息处理研究,对于数据和知识之间的关系,张家俊老师阐述了两个观点。
第一,现有的知识图谱仍然比较简陋。从某一个领域突破,构建一个大而全的知识图谱是一个比较可行的方案。
第二,我们需要探索新的方法来表示知识。张老师说:
"从机器翻译的三个方向发展可以看出,一开始是基于规则或者基于知识的模型,后来发展到统计方法,统计方法出现之后,知识就开始结合在统计翻译模型里。但到深度学习或者神经机器翻译时代之后,知识的离散符号表示和连续向量表示就没法结合了。这是因为知识是从大规模数据中总结出的结构化规律,而深度神经网络善于从数据中学习高频出现,不善于融入结构化信息,因此我们需要探索新的方法,将常理知识转换为高频出现的数据,从而让深度神经网络模型更好地学习,提升系统性能。”
张老师近期关于词典知识在神经机器翻译中应用的工作发现这一方法确实可以提高性能,工作目前仍在推进中。
北京大学万小军教授同样认可了知识和数据结合对学习的重要性:
 “可以从文字自身学习来看。小时候学习时,只看一堆文章,没有任何注释,也没有老师教我们体系,但也能自己估摸出这个词是什么意思,能够推理出来,但还是比较慢,如果有别人或者书本把知识体系教给你,那么理解文章就能更快更透彻。但是现在的知识图谱中的知识很浅,大数据驱动的方法学到的知识也是浅层的,这种“大力出奇迹”的方法更多的是记忆而不是智能,希望未来能将语言学的知识融入模型中得到更好的性能。”
“可以从文字自身学习来看。小时候学习时,只看一堆文章,没有任何注释,也没有老师教我们体系,但也能自己估摸出这个词是什么意思,能够推理出来,但还是比较慢,如果有别人或者书本把知识体系教给你,那么理解文章就能更快更透彻。但是现在的知识图谱中的知识很浅,大数据驱动的方法学到的知识也是浅层的,这种“大力出奇迹”的方法更多的是记忆而不是智能,希望未来能将语言学的知识融入模型中得到更好的性能。”
中国人民大学赵鑫副教授非常看好知识和数据的融合这个方向,但认为亟需对于知识的一个清晰定义。
在NLP领域更多是通过关系抽取去构建目前最常用的三元组的知识,但是这种表示的知识是非常浅层有限的。另外,大规模的预训练语言模型中学到的东西是否能够看作知识库,例如GPT3这种预训练模型,它的确可以给出一些不错的预测,但是也有可能出现常识性的错。也许模型的确可以回答“中国的首都是北京”,但是这是否是知识,仍待探究。
论坛讨论:多模态
京东集团技术副总裁何晓东博士:多模态是通往通用人工智能的重要方向
何晓东博士认为有效利用多模态信息是走向通用人工智能的一个非常重要的方向:“因为人的信息肯定是从多个模态来的,很多信息光读文本很难判断。举个简单例子,光看文本不能区别出颜色的意义,红色、绿色对文本来说是个符号。所以从这个角度来说,多模态肯定是通往AI智能之路的重要方向。但另一方面,利用多模态信息也非常困难。比如“看图说话”这件事情以前一直做不不了,是因为图片本身的模型算法和语言算法完全不一样,到了深度学习提出概念以后做Embedding以后,才看到一些有意思的一些新希望。近年有研究将不同模态的数据表示投影到统一的连续空间,在这个空间中做转换运算,将原始的输入转换为抽象的表达,从这些抽象的表达中生成文本或图像。在这类研究中,如何学习一个通用的共有的语义空间,使得不同模态的信号能之间进行比较或者进行计算转换,以及在不同模态之间如何做映射,都是值得研究的问题,也是最近逐渐兴起的研究方向。”
何晓东博士用在京东的工作举例,说明现有很多生成模型可以应用多模态的方法,实现更好的应用价值。例如广告词生成,给定商品规格、商品图片,就可以生成一段关于描述这个商品的广告词。反过来也一样,例如画一幅画,描述画一只鸟,是蓝色的背、红色肚皮,模型就可以创作出来,可以做更多创作性应用。
另外,何晓东博士指出,孙老师提出的三个挑战对应的愿景是很好的技术路线,是否能定义一个评价标准,或者是一个具体的任务,来作为向这些愿景前进的量化评判方法。例如知识图谱从“三缺其二”到“三分归一”中,对于三元组的知识现有的评价任务是QA,而“三缺其二”中的“其二”可能需要更具现实意义的大规模任务来判定,这个任务是什么。其他两个愿景也是如此,应该利用什么任务进行评判。
依图科技CTO颜水成博士:女儿给我了启发
在观察自己女儿的学习过程,颜博士发现女儿明显通过图片、文字,声音等多模态形式的输入积累,知识才慢慢增长。与此同时,认识的文字,物品越来越多。经验告诉他,多模态相互作用,才能学得更好。既然人的学习是多模态共同的结果,机器学习应该也是一样的道理;另外,刘嘉老师的讨论得出,人的人脑的一些研究表明,当人闭上眼睛只听声音时,视觉中枢神经元也会被激活;也就是说人脑中多模态在某些程度已经共享了一些东西了,这进一步证实了多模态学习的合理性。图神经网络的实践的结果也同样显示,用图表示的形式处理文本、图像或音频都有一些不错的效果,图网络的形式跟人脑神经的连接形式是非常类似的,图无序的节点用某种机制去做一个操作之后产生下一层,这种机制在图像、语音和语义领域似乎是共享的,说明在文本、图像或音频数据中的知识时有一些可以共享的,这点值得深入探索。
清华大学宋森研究员从脑科学的角度给出了关于多模态的解释。
NLP的脑科学研究中,通过深度神经网络中的节点参数与人脑神经元做对应的研究发现,语言不是人脑思考过程中最终的媒介。对于解码语言与理解语言的信息,大脑中是对应于不同层次的,理解信息是在更高的层次。因此,比如像BERT这样的模型可以对应我们语言感知的层,它能够模拟我们解码语言的层次,但并不能理解。更高一点的层次在研究中发现是具有多模态特征的。第二点是结合人脑对于记忆的操控,在NLP领域对信息进行处理时引入时间维度。在大脑中的时间是用嵌套的震荡的模式来实现的,也有比较长的,也有比较短的。引入时间可以考虑到人的思维特点。第三点是设计多模态的任务时能否结合大脑神经元的工作方式去考虑。另外也非常同意孙老师关于知识层面表示的观点,在人脑中确实关于表征动词和名词的震荡很不一样,甚至是在不同的区域。
清华大学刘知远副教授认为大规模预训练模型还是存在很大的缺陷,例如生成的语言没有逻辑性,前后没有照应关系;预训练参数空间学到的是浅层的语义表示,而没有学到深层的语义知识;另外语言模型无法学到知识的层次性,不能抽象出高层的语义,因此模型不知道自己哪些知识是不知道的,这是预训练语言模型亟待解决的问题。
到了自由讨论环节,各位老师专家讨论热烈,孙茂松老师首先肯定了颜水成博士观察女儿成长学习过程的这种研究方法,并建议各位青年学者把握机会,趁孩子还小有机会去进行观察,从中去找到研究的灵感。场下听众中一位来自北师大研究心理学的学者建议大家关注认知心理学、发展心理学方面的研究,其中有很多关于人类成长过程中一些学习表现的研究,值得大家借鉴。
自由讨论
自由讨论环节,学者们针对先前的问题,诸如学科交叉、知识表达等,进行了更为深入的探讨。
颜水成博士表示,无论是用类似神经网络的形式建立知识体系,还是说像先贤们那样说用一个形式化的系统,用一个符号化的系统来把这些知识表现出来,无论怎么样都得需要以一种能力,把人类对世界认知的方式显式地,在模型内部或外部表示出来。另外,水成博士抛出了三个问题。第一,关于NLP知识的表示,例如三元组,是否跟人的大脑中知识的表示有关系?第二,有很多人是文盲不识字,但是一样可以做推理,仍然具备语言能力,这个在脑科学中如何解释?第三不同语言在大脑中是否有不同分区?场下学者指出,不同语言的分区是不一样的,例如英语和汉语在大脑中是不一样的。何晓东博士又提问,如何能将知识、记忆、推理统一起来?之后,学者们的讨论聚焦在知识本身的定义问题。例如其与语言的关系,不同与语言是否对应不同的知识、知识与记忆的区别、意识的分层。一时众说纷纭,讨论十分激烈,在场的学者纷纷发表看法,并从多学科的视角进行讨论。
由于时间有限,各位学者都意犹未尽。孙茂松教授建议智源研究院组织一个封闭的短期学术交流,找一个封闭小岛,将各个学科(包括计算机、脑科学、心理学等等)的研究人员组织到一起讨论三五天,将各个学科基本的理论和前沿的研究讲清楚,以便各位学者能全面快速了解交叉学科,从而帮助本学科的研究。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢