

01
简介
我们希望研究不同类型任务跨语言传递率为什么存在较大的差异。在这项工作中,我们将推理任务的过程分解为两个独立的部分:知识检索和无知识推理,并分析了它们的跨语言可迁移性。通过改编现有的和新构建的无知识推理数据集,我们发现尽管无知识推理能力在某些特定目标语言中会受到资源的次要影响,但它几乎可以在不同的源-目标语言方向上完美地转移,而跨语言知识检索则明显阻碍了这种转移。此外,通过分析推理任务中的隐藏状态和前馈网络神经元激活,我们发现隐藏表征的相似性更高,激活神经元的重叠性更大,这可以解释无知识推理比知识检索具有更好的跨语言迁移能力。因此我们假设,无知识推理包含某种在语言间共享的机制,而知识则在不同的语言间是分别储存的。
根据这些发现,我们建议在未来的训练语料中优先考虑纳入多语言数据以增强知识方面的表现。在推理能力方面,应更注重推理数据的质量,而非语言的数量。此外,针对未来的多语言分析,我们建议对知识检索和无知识推理这两个部分进行分别研究,以获取更加针对性和详细的洞察
论文:https://arxiv.org/pdf/2406.16655
数据和代码:https://github.com/NJUNLP/Knowledge-Free-Reasoning
02
研究背景
当前LLM表现出了强大的多语言能力,在低资源语言中也表现出一定的能力。已有研究表明,这些多语言LLM具有一定的多语言迁移能力[1, 2, 3],即通过一种语言学到的技能或知识可以自动迁移到另一种语言,而无需额外的训练。然而,这种跨语言迁移的效果在不同任务中有所不同。在某些任务中,尤其是知识检索任务中,当前的LLM表现出不理想的跨语言迁移能力[1, 2];而在某些推理任务中,则可以观察到更为有效的迁移[3]。然而,之前的研究并未对这些任务间的差异进行深入分析,也未进一步探讨影响迁移效果的具体因素。
在本研究中,我们将一般推理任务分为两个独立的部分:知识检索和无知识推理。前者指从预训练数据中回忆特定信息,而后者指在上下文中组织给定的知识以进行推理并得出最终答案。图1对这两个部分进行了更清晰的说明,并展示了本文中探讨的跨语言迁移问题。

03
知识检索需求对推理跨语言传递的影响
我们首先验证了知识检索需求对推理跨语言传递的影响。其使用StrategyQA,QASC等常识推理数据集,这一类数据集在提供问题与回答的同时,还标注的了回答问题所需的事实信息。如下例子所示。
Fact1:Miami is a city in the state of Florida.
Fact2:Florida is the southernmost state on the American East Coast.
Question:Is Miami a city on the American West Coast?
我们使用了以下4种形式对数据集进行组织,对模型进行Lora训练和各种测试。这样可以控制模型回答问题过程中,对于知识检索的需求。
NF:仅提供题目,不提供事实信息
WF-1:提供题目,以及附带的第一条事实信息
WF-2:提供题目,以及前两条事实信息
WF-all:提供题目,以及所有附带的事实信息
跨语言传递率的测试指标如公式1所示。简单来说,在源语言做对的题目上,目标语言有多大比例做对了,并按照随机正确率归一化。
我们在十种语言上进行了测试,并确保了所有模型在所有数据集和语言对上,训练前的准确率均显著弱于训练后的准确率。
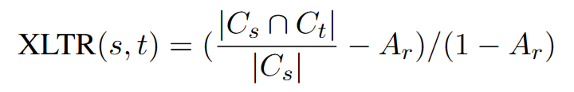
公式1:C_s和C_t分别表示在源语言和目标语言测试集上做对的题目的集合,A_r表示在该测试集上随机选择的正确率(比如4选1选择题的A_r为0.25)。
实验结果如图2和图3所示,在英语上训练,测试其他语言。其中图2中的实线是WF-all(带所有知识),而虚线是NF(不带知识)。可以发现所有模型,WF-all的跨语言传递率均显著大于NF,说明知识检索需求会显著影响推理任务的跨语言传递率。而在图3中,我们对llama2进行了更细致的分析,发现知识检索需求越大,推理任务的跨语言传递率就越低。
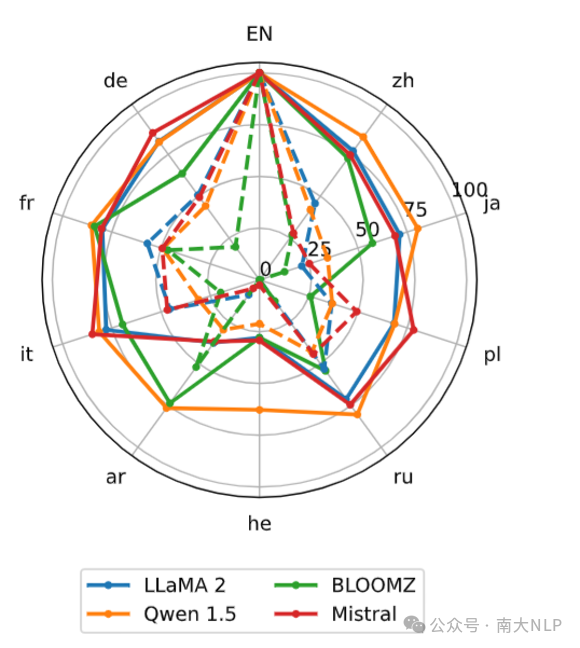
图2:StrategyQA上不同模型的XLTR。实线:WF-all;虚线:NF(不带知识)。训练语言(en)的标签大写。
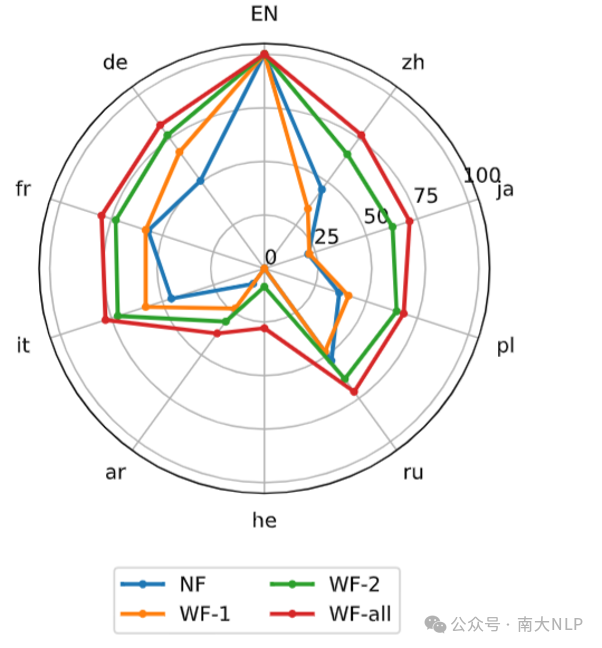
图3:不同设置下StrategyQA上LLaMA-2-7B-Chat的XLTR
04
知识无关推理的传递情况
上述的实验发现,strategyQA在给全部知识的情况下,模型在一些语言已经达到80+%的跨语言传递率。但我们发现,strategyQA对于某些样例并没有给出推理所需的所有知识。我们希望进一步的分析纯粹的、不含知识检索的推理能力。而现有的推理数据集或多或少都会包含知识检索的部分,因此我们新构造了一个纯粹不含知识检索的数据集KFRD(Knowledge-Free Reasoning Dataset)进行分析研究。还也选择了一些现存的推理数据集作为补充和验证。
我们主要考虑算术推理(如四则运算)、符号推理(如增删替换)和逻辑推理(如逻辑命题)这三种具有代表性的基本推理任务类型。并认为其他更复杂的推理可以由这三种组合而成。我们使用GPT4生成了不同语言的模板和实体,再使用代码生成数据,这确保了完成任务无需额外的知识和问题在不同语言之间是平行的。所使用的模板和样例如下所示。

图4:KFRD数据集的模板示例
表1:KFRD数据集中不同任务的示例

实验结果如下图所示,在KFRD数据集上,模型在不同语言上表现出了几乎完全的跨语言传递能力。而对于那些传递能力较差的语言,我们发现都是对应模型的低资源语言,并在后续进行了更详细的分析。
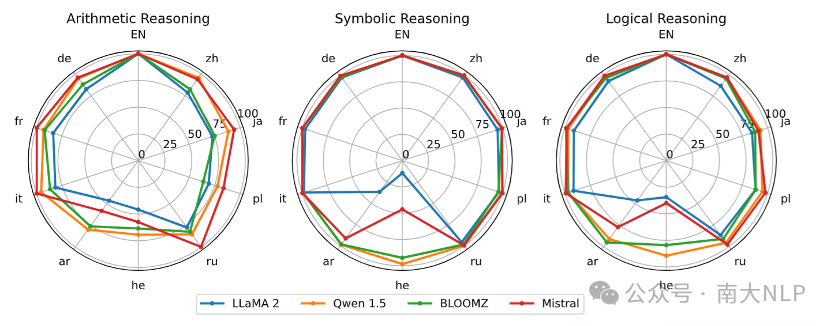
图5:关于KFRD不同部分的XLTR
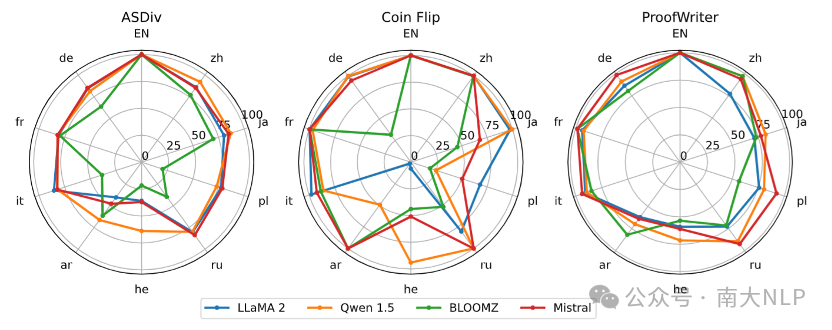
图6:现存伪无知识推理数据集XLTR
05
语言能力对知识无关推理跨语言传递的影响
我们认为训练语言的语言能力可能会影响准确率,在低资源语言上训练的准确率可能相对较弱(图7)。但是不会影响跨语言传递率(图8)。

图7:LLaMA-2-7B-Chat在KFRD数据集 三个部分的准确性。不同的线条表示不同的训练语言。
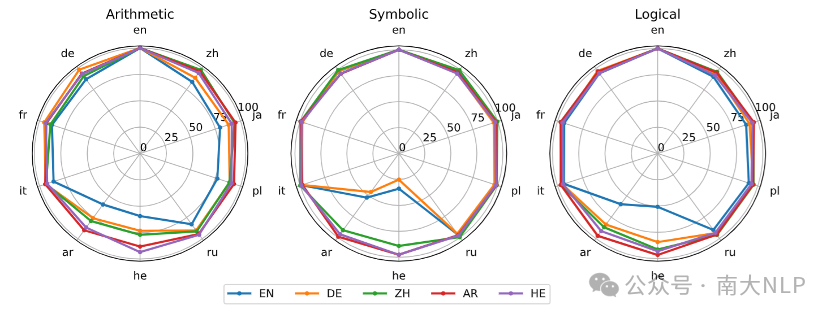
图8:LLaMA-2-7B-Chat在KFRD三个部分上的XLTR。不同的线条表示不同的训练语言。
我们之前假设目标语言语言能力弱可能会影响知识无关推理跨语言(如llama2的阿拉伯语(AR)和希伯来语(HE))。我们选取了对应模型在AR和HE两种低资源语言上,进行继续预训练、有监督微调之后的模型,并与基座进行对比。发现原先传递率较低的低资源语言在增强语言能力后,传递率显著提升了。说明目标(测试)语言语言能力较弱会显著影响知识无关推理的跨语言传递。
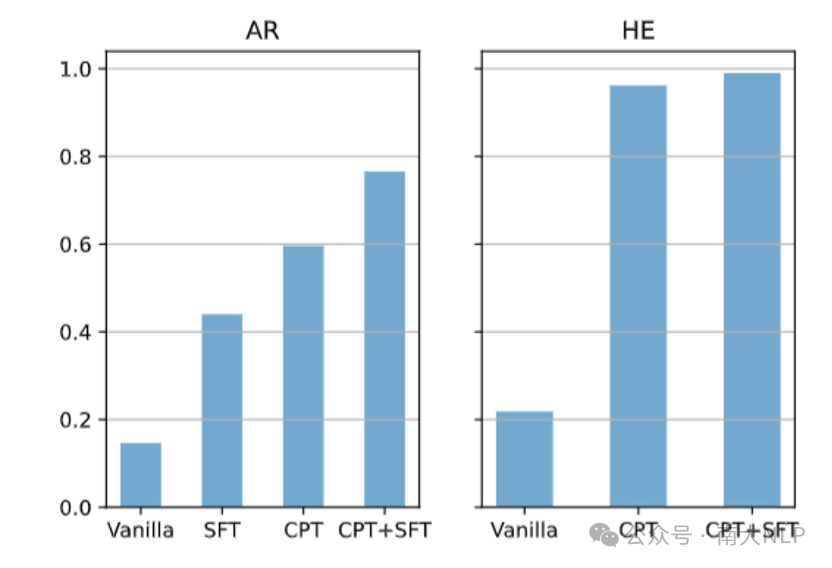
图9:在KFRD数据集的三个部分中,以阿拉伯语/希伯来语训练的不同阶段模型从英语到阿拉伯语/希伯来语的平均XLTR。
06
可解释性研究-知识无关推理和知识检索的传递率差异的原因
结合先前的研究[2]以及本文的实验,我们发现知识检索和知识无关推理在跨语言传递率上存在显著的差异。我们希望进一步的分析为什么会存在这样的差异。我们从神经元以及隐层表示的角度,对以上差异的原因进行分析。简单来说,隐层表示的余弦相似性(CS)就是计算同一层不同语言之间的cos相似度,NAO就是计算不同语言之间激活神经元的重叠程度,所有语言均激活神经元数量/各语言激活均值(设定一个阈值为激活)。
我们选取了KFRD作为知识检索的数据集代表,选取了一些知识QA任务作为知识检索数据集的代表(MKQA,BoolQ,AmbigQA)。
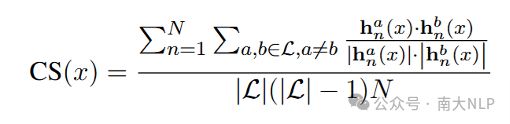
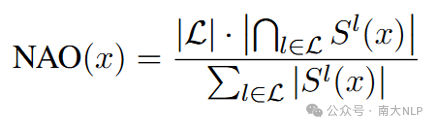
实验结果如图10和图11所示,我们发现在训练前,LLM知识无关推理相比知识检索任务具有更高的CS和NAO。这说明在进行知识无关推理任务时模型的内部表示相比知识检索更加对齐,神经元的激活模式也更加相似。而在知识无关推理数据上进行微调也会进一步提高CS和NAO,而在知识检索任务上进行微调,CS和NAO不会明显上升,甚至会带来下降。这说明模型在适应知识无关推理任务时产生了更加对齐的内部表示和更加相似的激活模式
这说明模型在进行知识无关推理时更加倾向于使用某种不同语言间共享的机制。
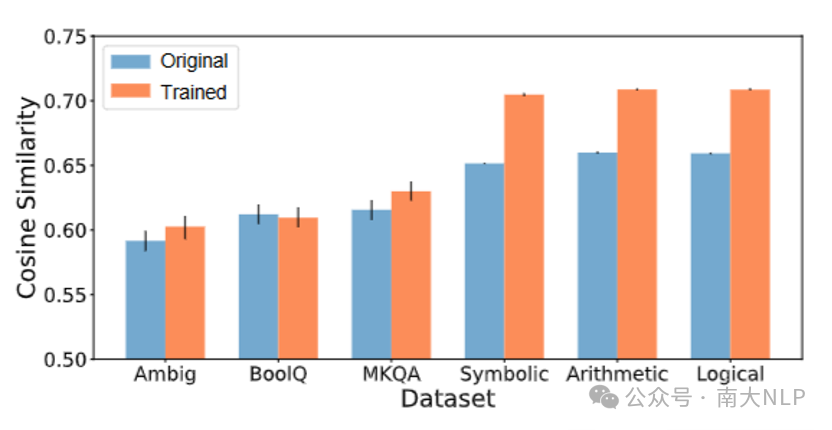
图10:LLaMA-2-7B-Chat模型中不同数据集的CS。每个条形图上的黑线表示通过bootstrap采样估计的99%置信区间。
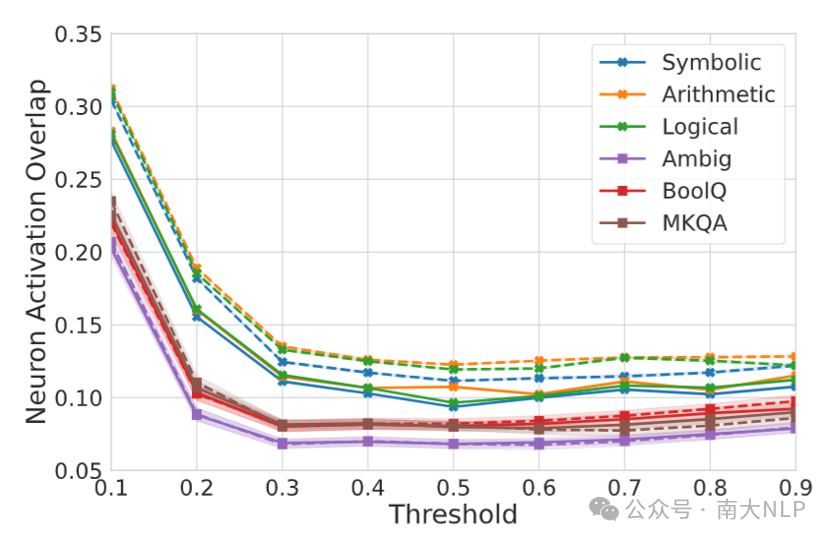
图11:在LLaMA-2-7B-Chat模型中,对于不同数据集,NAO在激活阈值从0.1到0.9范围内的表现。阴影区域:通过bootstrap采样估计的99%置信区间;实线:原始模型的结果;虚线:LoRA调优模型的结果。图12和图13中阴影区域和虚线的含义与此处描述的相同。
之前的研究发现[4, 5],模型可以分成三个阶段,低层负责处理输入,中间层负责进行推理,高层用于处理输出。我们参考了这种理论,对上述实验进行了更细致的分析。实验结果如图12和图13所示。实验结果表明,在模型低层,两种任务没有太大差距。而在模型中间层两种任务之间的差异较为明显,这说明两种任务的主要差异在于推理。
而在模型的高层,训练前两种任务的结果较为一致,但在训练后知识无关推理的CS和NAO明显提升了。这可能由于在知识无关推理任务上微调提高了模型在该任务上的准确率,使得不同语言间的一致性提升了。
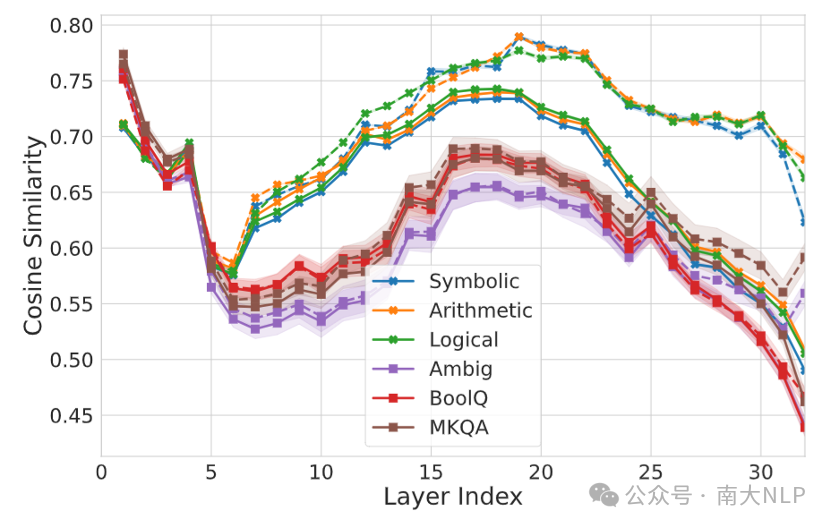
图12:LLaMA-2-7B-Chat不同层的CS
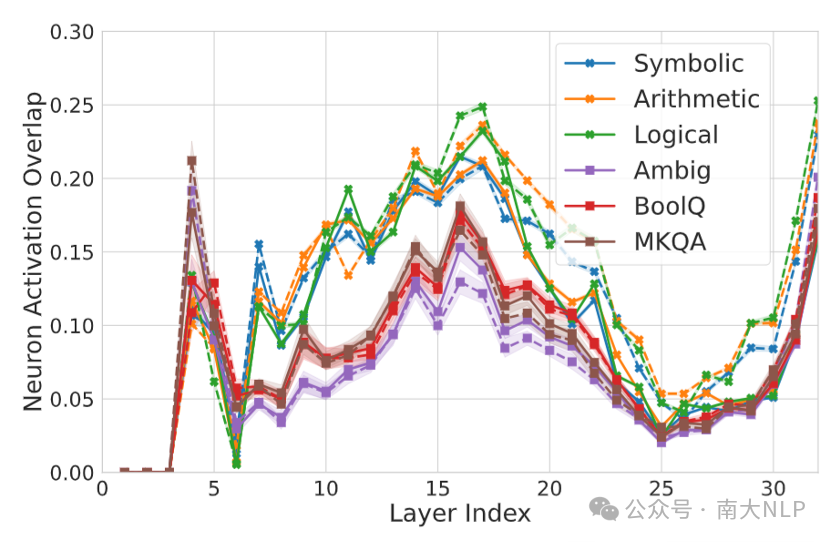
图13:LLaMA-2-7B-Chat不同层的NAO激活阈值为0.4时的NAO
参考文献
[1] Qi J, Fernández R, Bisazza A. Cross-Lingual Consistency of Factual Knowledge in Multilingual Language Models[C]//Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing. 2023: 10650-10666.
[2] Gao C, Hu H, Hu P, et al. Multilingual Pretraining and Instruction Tuning Improve Cross-Lingual Knowledge Alignment, But Only Shallowly[C]//Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers). 2024: 6101-6117.
[3] Ye J, Tao X, Kong L. Language versatilists vs. specialists: An empirical revisiting on multilingual transfer ability[J]. arXiv preprint arXiv:2306.06688, 2023.
[4] Zhao Y, Zhang W, Chen G, et al. How do Large Language Models Handle Multilingualism?[J]. arXiv preprint arXiv:2402.18815, 2024.
[5] Wendler C, Veselovsky V, Monea G, et al. Do llamas work in english? on the latent language of multilingual transformers[J]. arXiv preprint arXiv:2402.10588, 2024.
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢