

https: //letsdatascience.com/affinity-propagation-clustering/
假设您有一个数据集,其中各个样本之间存在关系,并且您的目标是识别数据集内的相关样本组。聚类(Clustering)是无监督机器学习算法的一部分,可能是可行的方法。但是,当您不知道簇的数量时,应该应用哪种聚类算法呢?
进入亲和传播(Affinity Propagation),这是一种八卦式算法,它通过模仿社会群体形成来推导簇的数量,通过传递有关单个样本受欢迎程度的消息来判断它们是否属于某个群体,甚至是否是某个群体的领导者。这种算法可以估算数据集本身中的簇/组的数量。
首先,我们将从理论上了解亲和力传播。它是什么?群体形成类比是如何运作的?从数学角度看,它是如何运作的?它会发送什么样的消息?这些受欢迎程度指标是如何确定的?算法是如何收敛的?我们首先来看一下这些问题。
接下来,我们将使用 Scikit-learn 和 Python 提供亲和力传播的示例实现。我们将逐步解释我们的模型代码,以便您可以逐步了解正在发生的事情。对于那些已经有一些经验并希望立即开始使用的人,也可以使用完整的模型代码。
什么是亲和传播(Affinity Propagation)?
你还记得高中时,学生们组成了不同的团体,而只有团体的领导者认为你很酷,你才能成为该团体的成员吗?
虽然这个类比可能有点牵强,但我认为这可以用通俗易懂的语言来解释聚类的亲和力传播。对于一组数据点,开始一个“群体形成(group formation)”过程,每个样本与其他样本竞争以获得群体成员资格。拥有最多群体资本的样本被称为群体领导者(exemplars)。
这种机器学习技术的有趣之处在于,与K 均值聚类不同,您不必提前配置聚类数量。主要缺点是复杂性:就所需的计算资源而言,它不是最便宜的机器学习算法之一。因此,它仅适用于“小型到中型数据集” 。
现在我们已经从高层次上理解了亲和传播,现在是时候进行更详细的了解了。我们将研究以下几件事:
从高层次来看,该算法是如何工作的;
传播什么样的信息;
这些消息中的分数是如何计算的。
每次迭代之后消息分数如何更新,从而如何形成真正的聚类。
首先,与任何聚类算法一样,亲和传播是迭代的。这意味着它将完成多次迭代直到完成。与 K 均值聚类相反,其中收敛由某个阈值确定,而使用亲和传播,您可以配置要完成的迭代次数。之后,该算法假设收敛并返回聚类结果。
传播两种类型的消息
在每次迭代过程中,每个样本都会向其他样本广播两种类型的消息。第一种称为责任(responsibility)r (i,k) — 即“样本 k 应成为样本 i 的典范的证据”。我总是记得它如下:k 的预期群体领导力越强,对群体的责任就越大。这就是你知道从 i 的角度来看的责任总是会告诉你一些关于 k 对群体的重要性的信息。
发送的另一种消息是可用性(availability)。这与责任相反:i 有多确定应该选择 k 作为样本,即加入特定组的可用性有多高。在高中的案例中,假设你想加入一个半酷的小组(有一定的可用性),而你更愿意加入非常酷的小组。对于非常酷的小组,你的可用性要高得多。责任告诉你一些关于你需要谁的接受才能加入小组的信息,即最有可能的小组领导者或样本。
计算责任感和可用性的分数
现在让我们更深入地了解责任和可用性的概念。既然我们知道它们在高层次上代表什么,现在是时候详细地研究它们了——也就是从数学上。
责任(Responsibility)
以下是责任公式:
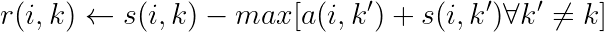
现在让我们用通俗易懂的英语来解释这个公式。我们从左边开始。这里,r(i,k) 再次表示样本k 是样本 i 的样本。但是什么决定了它?两个组成部分:s(i, k) 和 max[ a(i, k') + s(i, k')∀ k'≠ k]。
第一个是样本 i 和 k 之间的相似性。如果它们高度相似,那么 k 成为 i 的样本的可能性就非常高。然而,这并不是故事的全部,因为我们不能只看相似性——因为其他样本也会试图说服自己,它们是更适合 i 的样本。因此,相似性是相对的,这就是为什么我们需要减去那个大的最大值。它看起来很复杂,但它可以归结为“所有其他样本 k' 的最大可用性和相似性,其中 k' 永远不是 k”。我们只需减去相似性和k 的“最大竞争对手”的意愿,以显示其作为样本的相对实力。
可用性(Availability)
责任看起来很复杂,但实际上相对容易。可用性的公式也是如此:
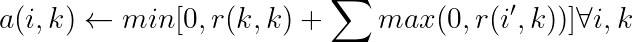
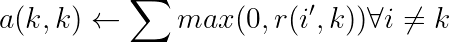
我们可以看到,可用性由 0 和 k 对 k 的责任(即它认为自己作为样本或组长的重要性)与所有其他样本 i' 至 k 的责任之和(其中 i' 既不是 i 也不是 k)之间的最小值决定。因此,在组形成方面,如果样本本身认为自己非常重要并且周围的其他样本也是如此,那么它将对潜在样本变得更加可用。
更新分数:集群是如何形成的
现在我们知道了责任和可用性的公式,让我们看一下每次迭代之后分数是如何更新的:
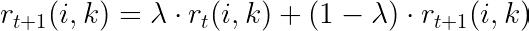
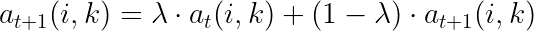
简而言之:每次更新时,我们都会取旧值的 λ 并将其与新值的 (1-λ) 合并。这个 lambda 也称为“阻尼值”,是一个平滑因子,可确保平稳过渡;它可以避免优化过程中出现较大的振荡。
总而言之,亲和传播是一种算法,它:
估计聚类本身的数量。
考虑到计算成本,它对于中小型数据集很有用。
通过“闲聊”的方式进行工作,就好像它试图组建高中学生团体一样。
通过随时间推移(即每次迭代之后)对单个样本的“吸引力”进行小幅、平滑的更新来更新自身。
对于样本,吸引力是通过回答“这能成为我想要加入的群体的领导者吗?”以及样本本身(“有什么证据表明我是群体领导者?”)来判断的。
使用 Python 和 Scikit-learn 实现亲和传播
这些聚类在我们关于K 均值聚类的博客中也曾出现过,尽管今天的样本较少:
还记得我们是如何生成它们的吗?打开一个 Python 文件并将其命名为“affinity.py”,添加导入(即 Scikit-learn、Numpy 和 Matplotlib)。
import matplotlib.pyplot as plt
import numpy as np
from sklearn.datasets import make_blobs
from sklearn.cluster import AffinityPropagation然后,我们添加一些配置选项:我们生成的样本总数、聚类中心以及我们将为其生成样本的类数。这些都将在 中使用make_blobs,它会生成聚类并分别将它们分配给 X 和目标。
我们用 Numpy 保存它们,然后加载它们并再次将它们分配给 X。这两行代码对于您的模型运行来说不是必需的,但如果您想跨设置进行比较,您可能不想每次都随机生成样本。通过保存它们一次,然后注释掉save和make_blobs,您将一次又一次地从文件中加载它们 :)
# Configuration options
num_samples_total = 50
cluster_centers = [(20,20), (4,4)]
num_classes = len(cluster_centers)
# Generate data
X, targets = make_blobs(n_samples = num_samples_total, centers = cluster_centers, n_features = num_classes, center_box=(0, 1), cluster_std = 1)
np.save('./clusters.npy', X)
X = np.load('./clusters.npy')然后,我们将数据加载到亲和传播算法中,这只需要两行代码。在另外两行中,我们导出了诸如样本之类的特征,以及簇的数量:
# Fit AFfinity Propagation with Scikit
afprop = AffinityPropagation(max_iter=250)
afprop.fit(X)
cluster_centers_indices = afprop.cluster_centers_indices_
n_clusters_ = len(cluster_centers_indices)最后,通过使用我们拟合的算法,我们可以预测所有样本属于哪个聚类:
# Predict the cluster for all the samplesP = afprop.predict(X)
最后将结果可视化:
# Generate scatter plot for training data
colors = list(map(lambda x: '#3b4cc0' if x == 1 else '#b40426', P))
plt.scatter(X[:,0], X[:,1], c=colors, marker="o", picker=True)
plt.title(f'Estimated number of clusters = {n_clusters_}')
plt.xlabel('Temperature yesterday')
plt.ylabel('Temperature today')plt.show()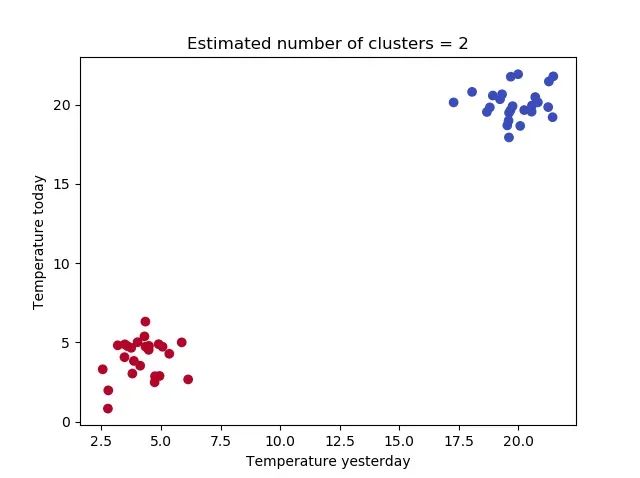
完整代码
如果您希望立即获得完整的模型代码,以便可以立即开始使用它 — 那就来吧!它也在我的Github 存储库中提供https://github.com/Francesco601/machine-learning-stuff/blob/main/affinity_prop.py。
import matplotlib.pyplot as plt
import numpy as np
from sklearn.datasets import make_blobs
from sklearn.cluster import AffinityPropagation
# Configuration options
num_samples_total = 50
cluster_centers = [(20,20), (4,4)]
num_classes = len(cluster_centers)
# Generate data
X, targets = make_blobs(n_samples = num_samples_total, centers = cluster_centers, n_features = num_classes, center_box=(0, 1), cluster_std = 1)
np.save('./clusters.npy', X)
X = np.load('./clusters.npy')
# Fit AFfinity Propagation with Scikit
afprop = AffinityPropagation(max_iter=250)
afprop.fit(X)
cluster_centers_indices = afprop.cluster_centers_indices_
n_clusters_ = len(cluster_centers_indices)
# Predict the cluster for all the samples
P = afprop.predict(X)
# Generate scatter plot for training data
colors = list(map(lambda x: '#3b4cc0' if x == 1 else '#b40426', P))
plt.scatter(X[:,0], X[:,1], c=colors, marker="o", picker=True)
plt.title(f'Estimated number of clusters = {n_clusters_}')
plt.xlabel('Temperature yesterday')
plt.ylabel('Temperature today')
plt.show()Summary亲和传播的一些应用
亲和传播是一种功能强大的聚类算法,已应用于各个领域。它能够自动确定聚类数量,这使其在聚类数量未知或难以确定的情况下特别有用。以下是亲和传播 (AP) 算法的一些关键应用:
图像和视频分析:亲和传播已成功应用于图像和视频分析任务,例如对象识别、图像分割和视频摘要。通过对图像或视频中的相似区域或对象进行聚类,它可以帮助识别和分类不同的对象或场景。
自然语言处理:亲和力传播已用于自然语言处理任务,例如文档聚类、主题建模和情感分析。它可以根据内容将相似的文档分组,从而更轻松地组织和分析大型文本数据集。
生物信息学:AP 算法已应用于生物信息学,用于基因表达分析、蛋白质结构预测和蛋白质-蛋白质相互作用网络聚类等任务。它有助于识别生物数据中的模式和关系,从而为基因组学和蛋白质组学领域带来见解和发现。
社交网络分析:亲和力传播已用于社交网络分析,以识别网络中的社区或群体。通过根据个人的社交联系或互动对他们进行聚类,它可以帮助理解社交网络的结构和动态。
市场细分:亲和力传播 (AP) 已用于市场细分研究,根据客户的偏好、行为或人口统计数据对其进行分组。这可以帮助企业瞄准特定的客户群体并相应地调整营销策略。
概括
在今天的博客文章中,我们研究了亲和传播算法。这种聚类算法允许机器学习工程师通过“消息传递”的方式对数据集进行聚类。类似于高中的小组组建方式,小组组长决定谁可以加入以及谁必须选择另一个人,算法也玩拉动游戏。
通过查看传播的消息、随这些消息发送的责任和可用性指标以及它如何迭代收敛,我们首先了解了亲和传播算法的理论部分。接下来是一个使用 Python 和 Scikit-learn 的实际示例,我们逐步解释了如何实现亲和传播。对于感兴趣的人,整个模型也可以在上面找到。
参考
Scikit-learn. (n.d.). 2.3. Clustering — scikit-learn 0.22.2 documentation. scikit-learn: machine learning in Python — scikit-learn 0.16.1 documentation. Retrieved April 18, 2020, from https://scikit-learn.org/stable/modules/clustering.html#affinity-propagation
Geeks for Geeks(n.d.): Affinity Propagation from https://www.geeksforgeeks.org/affinity-propagation/



内容中包含的图片若涉及版权问题,请及时与我们联系删除


评论
沙发等你来抢