
整理者:杨二茶 (清华大学)
为了方便大家对因果科学社区丰富多彩的学术探讨有个快速了解的窗口,我们推出《因果科学社区热点 Q&A》系列,精选因果科学社区近期的精彩问答,以抛砖引玉,并期待更多的朋友参与到我们的社区活动和学术交流中。作为问答系列的第2期,我们筛选了因果科学与Casual AI读书会第九期——因果推理和迁移学习中,宫明明、郭家贤、丁晨炜与社区会员们互动中的交流问答,此外因果社区的龚鹤扬博士等也对部分问题作了补充。对于交流的问题,大家如果有进一步的疑问或者补充,请直接在下面回帖评论,我们将邀请社区内相关专家、老师们给你回馈。
主讲人介绍:
宫明明,墨尔本大学讲师,研究方向为因果推断,基于因果的机器学习,迁移学习,计算机视觉。
郭家贤, 悉尼大学在读博士,研究方向为深度迁移学习,强化学习。
丁晨炜,悉尼大学在读博士,研究方向为因果发现,计算机视觉。
演讲内容简介:
大数据的出现使得许多学科在学习和预测方面取得了革命性的成功。但是,当前的机器学习模型的一个主要缺点是缺乏对新领域的适应性和泛化能力。也就是说,标准的监督学习模型在数据分布发生变化时预测性能会显著下降。在本次读书会,我们将重点讲述如果利用因果模型理解和建模不同领域的分布变化。因为因果系统的独立模块性质,我们可以将复杂的分布分解成小的模块,发掘分布在不同领域的不变性和变化性,从而开发出具有领域自适应能力的高效迁移学习算法。以下是本次读书会的大纲:
参考资料下载:本期读书会演讲中分享的PDF,部分问答中会涉及到。下载PDF
1. 宫明明互动问答
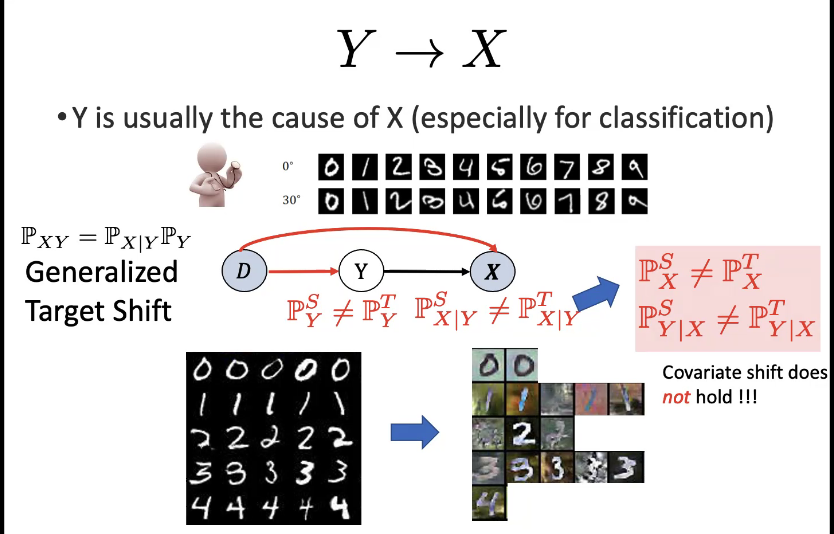
Q:p15 P(X|Y)他们的函数是一个密度函数,说他们独立到底是什么意思? 宫明明:每个domain都有一个分布,假设我把这个分布参数化,从贝叶斯角度可以看成一个随机变量。从private distribution从每一个domain去产生数据。
Q:p15 变化用一个参数θ表示,对应的概率空间是什么?如果把参数看成随机变量的话,随机变量是指的特定空间中的随机变量,参数看成随机变量的话,随机变量属于哪个概率空间呢?假设是确定性函数的变化和P(Y)的变化是独立的? 宫明明:不是这样理解的。把每个function看成一个随机变量,因为我最后考虑的是multiple domain
Q:p15 如果是两个domain就没办法区分了? 宫明明:是的,一定要多个domain才可以。
Q:p15 confounder的时候,因果机制还是会独立变化吗? 宫明明:不会独立的。因为你没有观测到。
Q:p15 因果图下面的式子和右边方框的式子是同时成立的吗?潜在因果图是否唯一的?
宫明明:是的。目前还没有考虑到唯一性,现在是假设这一个因果关系。假设了Y指向X。红色的两个式子并不独立,因为他们的变化是 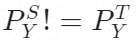 引起的。目前是假设知道方向,来探究性质。
引起的。目前是假设知道方向,来探究性质。
Q: p15 Domain是指什么?Y和X在这里代表什么? 公式里的S是什么? 听众:不同的(X, Y)分布。D还是属于confounder吧,只不过是observed。 D只是domain的index。Y是level,X是特征。S是 Source (train dataset).Domain就是一个地方得到一组数据就叫domain,也就是不同环境里得到的数据。
Q: confounder 的定义只是 common cause, 只不过在这里D是observed confounder? 龚鹤扬:不一定能理解为common cause。E(Y|do(X)) 并不等于E(Y|X)。由此导致会有偏差。整个过程是deconfounding,所以应该理解为导致他产生混淆偏差的变量。
Q:因果推理这方面,Elias在研究transferability写了一系列的文章,从13-00,你们的研究和他们的有什么样的关系?
宫明明:因果独立变化性和modularity是一样。不同的就是我考虑machine learning的问题,最终解决预测的问题。他们会考虑experimental的问题,intervention是否能迁移这样的问题。我这边不考虑这个。基于causality的machine learning太多了,我们考虑adaptation。各种各样的机器学习问题,都可以通过因果推断来学习。传统机器学习是不太需要因果的,如果得到信息不够完整,因果才会有帮助,比如强化学习这样的。
龚鹤扬:Elias考虑某个因果量是否可以迁移的问题,宫老师这边是主要用因果来帮助机器学习预测的问题。
Q:红色箭头是指的什么操作或者含义呢? 听众:表示 domain-dependent, i.e, different in different domains
2. 郭家贤互动问答
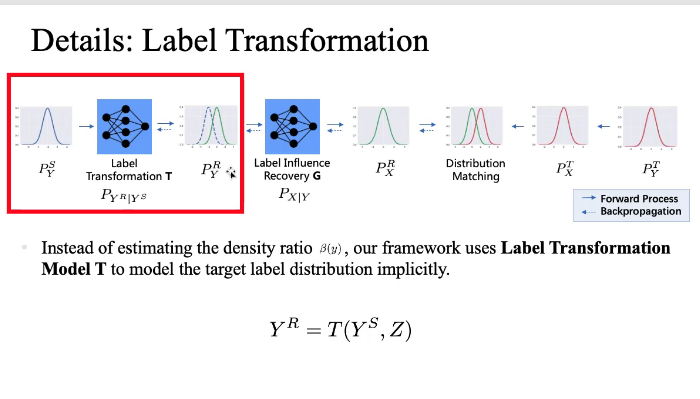
Q:Distribution matching,用的什么方法?如何衡量两个分布的距离?
郭家贤:对抗训练的方法。引入了一个discriminator,G产生的数据点,我们来判断discriminator,产生的数据是XR还是XT,如果数据很相似的话,discriminator不能判断是从哪个生成出来的,我们就可以判断 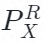 和
和 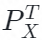 相等了。
相等了。
3. 丁晨炜互动问答
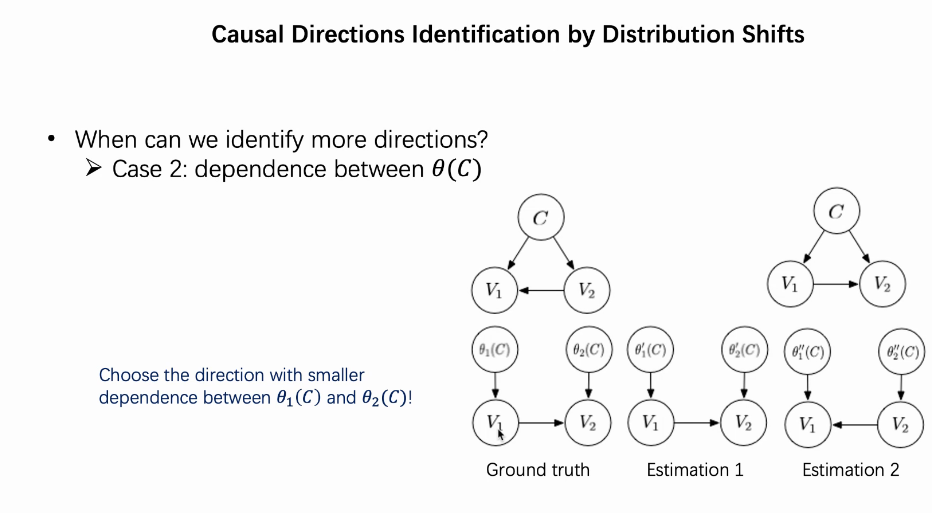
Q:θ1到V1的model是假设的吗? 丁晨炜:不是的。 假设已经知道是高旋model,再在不同的domain中,去计算θ1 和θ2,对方差进行度量。
Q: 这个算法的时间复杂度随着theta的增加变化,domain的类别增加吗? 丁晨炜:不是的。关系是非线性的时候,我们会采取其他一些度量两个independence的方法去做,维度越高,复杂度就越大。Domain变化会导致我们把θ1和2数据采样变化。另外如果domain类别增加导致数据量整体变动,计算也会变慢。
Q:有点没理解倒数第二张的PPT感觉图上的两个case里面 θ1和2都是独立的啊? 丁晨炜:V2到V1是个错误的方向。我们的数据是从ground truth的方向产生的,从V1导致V2.如果我们用V2导致V1的因果图,我们去学习causal module的参数,得到的θ1和2就不是独立的。
Q: 您好,我刚刚可能听漏了一小段。想问一下通过dependence判断direction的原因是什么呢? 丁晨炜:我想判断V1和V2之间的direction,错误估计是最右边的图,错误估计的图是Estimation1. 对于错误的direction,θ1和θ2不是独立的,所以我们可以计算这两个之间dependence判断依据。
Q:θ1和2都是由C决定的,那C是否可以为共同原因呢?从函数关系看是不一样的? 丁晨炜:一百个数据就可以看成他和θ1中不同的采样的数据点。 赵芳芳:举个例子,C是不同的公司,在每一个公司里采样,θ就是不一样的。
因果科学社区简介:它是由智源社区、集智俱乐部共同推动,面向因果科学领域的垂直型学术讨论社区,目的是促进因果科学专业人士和兴趣爱好者们的交流和合作,推进因果科学学术、产业生态的建设和落地,孕育新一代因果科学领域的学术专家和产业创新者。

因果科学社区欢迎您加入!
因果科学社区愿景:回答因果问题是各个领域迫切的需求,当前许多不同领域(例如 AI 和统计学)都在使用因果推理,但是他们所使用的语言和模型各不相同,导致这些领域科学家之间沟通交流困难。因此我们希望构建一个社区,通过组织大量学术活动,使得科研人员能够掌握统计学的核心思想,熟练使用当前 AI 各种技术(例如 Pytorch/Pyro 搭建深度概率模型),促进各个领域的研究者交流和思维碰撞,从而让各个领域的因果推理有着共同的范式,甚至是共同的工程实践标准,推动刚刚成型的因果科学快速向前发展。具备因果推理能力的人类紧密协作创造了强大的文明,我们希望在未来社会中,因果推理融入到每个学科,尤其是紧密结合和提升 AI ,期待无数具备攀登因果之梯能力的 Agents (Causal AI) 和人类一起协作,共建下一代的人类文明!
如果您有适当的数学基础和人工智能研究经验,既有科学家的好奇心也有工程师思维,希望参与到“因果革命”中,教会机器因果思维,为因果科学作出贡献,请加入我们微信群:扫描下面社区小助手二维码加入(请备注“因果科学”)?

内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢