

R1 发布之后,行业内对于推理模型的讨论多了起来。
有些人认为推理类模型代表着新的 scaling law 范式(inference-time scaling,scale test time compute)。
有人则认为现阶段 R1 还没办法很好地接入 Agent 框架中,做出固定路径的长链路任务,只能回答一些谜题、高级数学和编码挑战这种「问题短,需要的长下文短,处理的不同步骤少」问题。
文章的主要观点摘要:
“推理”定义为回答需要复杂、多步骤生成并包含中间步骤的问题的过程。因此推理模型在这上面做了不同于传统模型“推理能力”的优化,比如思考input的真正意图和指令,并一步步给出答案,COT(思维链本身就是回复给用户的回复)
推理模型旨在擅长解决复杂任务,如解谜、高级数学问题和具有挑战性的编码任务。然而,对于摘要、翻译或基于知识的问答等简单任务,它们并非必需。推理模型通常使用成本更高,更冗长,有时由于“过度思考”而更容易出错。
DeepSeek 没有发布单个 R1 推理模型,而是引入了三个不同的变体:DeepSeek-R1-Zero、DeepSeek-R1 和 DeepSeek-R1-Distill。他们的继承关系和适用。
推理时间scaling不需要额外的训练,但会增加推理成本,随着用户数量或查询量的增加,大规模部署变得更加昂贵。纯粹的强化学习对研究目的来说很有趣,因为它提供了对推理作为涌现行为的见解。然而,在实际模型开发中,RL + SFT 是首选方法,因为它导致更强的推理模型。R1是一个良好范本。 蒸馏是一种有吸引力的方法,尤其是在创建更小、更高效的模型方面。然而,其局限性在于蒸馏并不能推动创新或产生下一代推理模型。
将 RL + SFT 与推理时 scaling 相结合。这很可能是 OpenAI o1 所做的事情,但它可能基于比 DeepSeek-R1 更弱的基模型,这解释了为什么 DeepSeek-R1 在推理时表现良好同时相对便宜。同时一个专注于纯强化学习(TinyZero),另一个专注于纯SFT(Sky-T1)新模型都带来很多这条道路上的启发。
有待思考的问题:什么场景是适合推理模型企业级试水的呢?推理模型放在我们过往的Agent框架里面效果如何?似乎联网搜索+深度思考是一个更迫近日常生活用途的搜索方式。但搜索场景里:机器思维链代替人的思维链这个过程还需要时间去验证。(同时r1级别的模型更容易产生人类无法甄别的幻觉信息,这会让学会“say no”之前的机器思维链更不可信)
2024 年,LLM领域出现了越来越多的“专业化”。除了预训练和微调之外,我们还见证了从 RAG 到代码助手的专用应用兴起。我预计这一趋势将在 2025 年加速,对领域和应用特定优化的重视程度将更高(即“专业化”)。
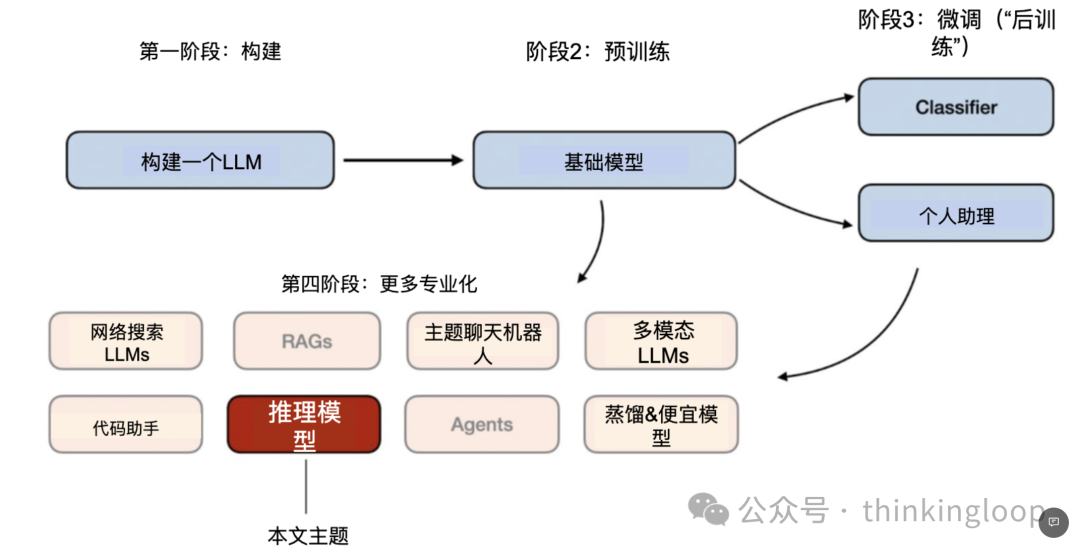
阶段 1-3 是开发 LLMs 的常见步骤。阶段 4 专门针对特定用例进行 LLMs的落地
推理模型的开发是这些专业化之一。这意味着我们改进LLMs以擅长通过中间步骤解决的最佳复杂任务,例如谜题、高级数学和编码挑战。然而,这种专业化并不取代其他LLM应用。因为将LLM转化为推理模型也引入了某些缺点,我将在稍后讨论。
01
我们如何定义“推理模型”?
我们可以把“推理”定义为回答需要复杂、多步骤生成并包含中间步骤的问题的过程。例如,“法国的首都是什么?”这样的事实性问题不涉及推理。相反,像“如果一列火车以每小时 60 英里的速度行驶 3 小时,它会行驶多远?”这样的问题则需要一些简单的推理。例如,它需要识别距离、速度和时间之间的关系,才能得出答案。
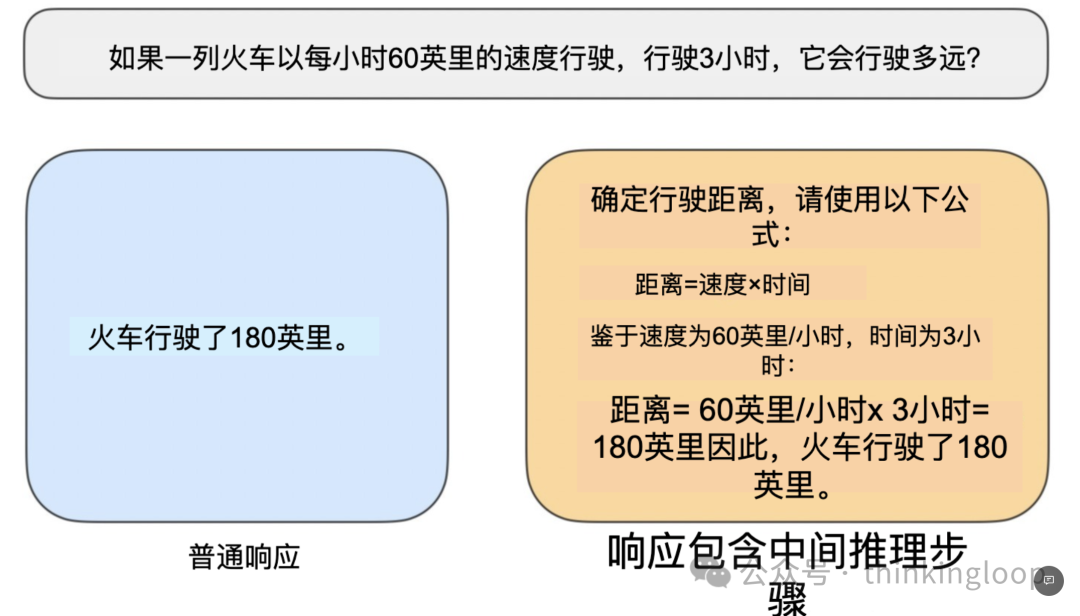
一个常规的LLM可能只能提供简短的答案(如左图所示),而推理模型通常包括中间步骤,揭示部分思考过程(如右图所示)。(注意,许多未专门为推理任务开发的LLMs也能在他们的答案中提供中间推理步骤。)
“如果一列火车以每小时 60 英里的速度行驶 3 小时,它会行驶多远?”这样的问题。因此,今天当我们提到推理模型时,我们通常指的是LLMs,它们擅长更复杂的推理任务,如解决谜题、谜语和数学证明。
现在号称是“推理模型”的LLMs都包括一个“思考”或“思维”过程作为其响应的一部分。那么LLM是否真正“思考”以及如何思考呢?
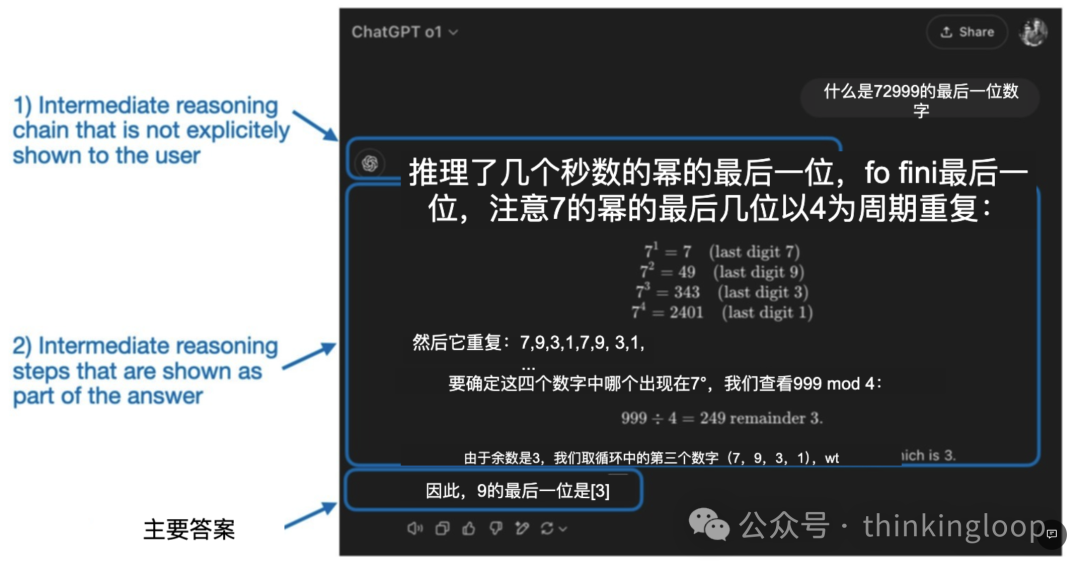
推理在两个不同层面上使用:1)通过多个中间步骤处理输入并生成;2)作为对用户响应的一部分提供某种推理。
简单来讲,思考体现在:
思考input的真正意图和指令(比如我们在问deepseek问题的时候模型总会先对大家进行一下意图判断,所以如果你用其他由头试图越狱,是能被模型察觉的)。
一步步给出答案,COT(思维链本身就是回复给用户的答案)
02
我们应该何时使用推理模型?
上一篇o1 不能用来 code 和 chat,那可以做什么详细讲了这一部分,也欢迎回去看一下
何时需要推理模型?
推理模型旨在擅长解决复杂任务,如解谜、高级数学问题和具有挑战性的编码任务。
然而,对于摘要、翻译或基于知识的问答等简单任务,它们并非必需。
实际上,将推理模型用于一切可能会低效且昂贵。例如,推理模型通常使用成本更高,更冗长,有时由于“过度思考”而更容易出错。此外,这里也适用简单规则:为任务使用正确的工具(或类型)。

推理模型的要点优势和劣势
03
简要讲讲DeepSeek 训练流程,
和大家部署的版本
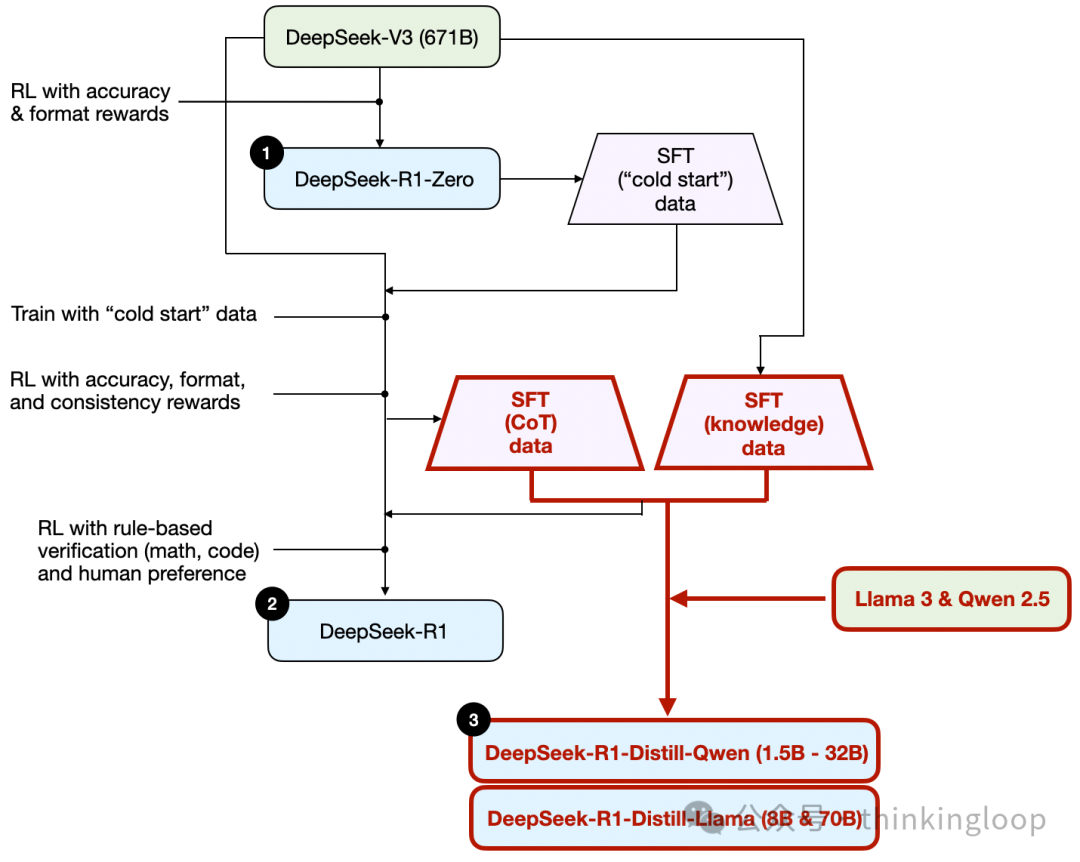
DeepSeek 没有发布单个 R1 推理模型,而是引入了三个不同的变体:DeepSeek-R1-Zero、DeepSeek-R1 和 DeepSeek-R1-Distill。
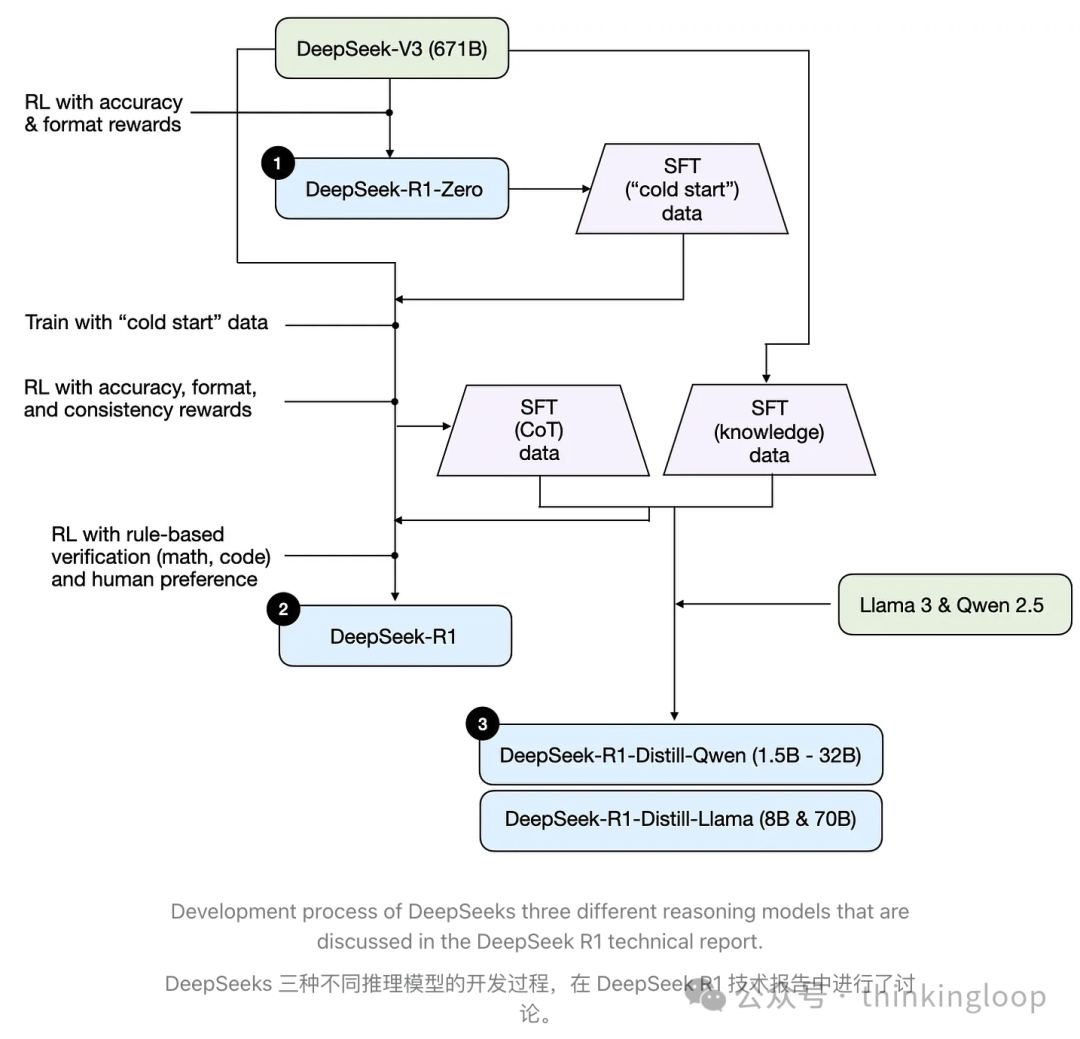
DeepSeek-R1-Zero:该模型基于 2024 年 12 月发布的 671B 预训练 DeepSeek-V3 基础模型。研究团队使用两种类型的奖励,通过强化学习(RL)对其进行训练。这种方法被称为“冷启动”训练,因为它不包括监督微调(SFT)步骤,而监督微调通常是包含人类反馈的强化学习(RLHF)的一部分。
DeepSeek-R1:这是 DeepSeek 的旗舰推理模型,基于 DeepSeek-R1-Zero 构建。团队通过额外的 SFT 阶段和进一步的 RL 训练进一步优化了它,改进了“冷启动”的 R1-Zero 模型。
DeepSeek-R1-Distill*:使用前一步骤生成的 SFT 数据,DeepSeek 团队微调了 Qwen 和 Llama 模型以增强其推理能力。虽然不是传统意义上的蒸馏,但这个过程涉及在更大的 DeepSeek-R1 671B 模型输出上训练较小的模型(Llama 8B 和 70B,以及 Qwen 1.5B–30B)。
值得注意的是:Distill版本既没有大家说的那么强——部署后发现满血和蒸馏版效果差异较大;也没有大家讲的那么弱,比如有一些版本:30B表现出在coding领域的某些任务很强高于满血版的效果。
04
构建 DeepSeek-R1、
OpenAI 的 o1 和 o3 涉及的技术
4.1 Inference-time scaling 推理时间scaling
具体指的是在推理过程中增加计算资源以提高输出质量。人类在思考复杂问题时,如果给予更多时间,往往能产生更好的回应。同样,我们可以应用一些技术,鼓励LLM在生成答案时“思考”更多。(尽管,LLMs是否真的“思考”是另一个话题。)
一种简单直观的推理时间Scaling方法是巧妙的提示工程。一个经典的例子是思维链(CoT)提示,其中在输入提示中包含诸如“逐步思考”之类的短语。这鼓励模型生成中间推理步骤,而不是直接跳到最终答案,这在更复杂的问题上往往能导致更准确的结果,但也不一定总是成功。(对于像“法国的首都是什么”这样的简单基于知识的问题,采用这种策略是没有意义的,这又是一个很好的经验法则,用来判断推理模型是否适用于你的给定输入查询。)
回答最一开始的问题:Inference-time scaling、scale test time compute目前来讲都是在讲一件事

上述 CoT 方法可以看作是推理时间缩放,因为它通过生成更多输出标记使推理更加昂贵。
另一种推理时间缩放的方法是使用投票和搜索策略。一个简单的例子是多数投票,我们生成多个答案,并通过多数投票选择正确答案。同样,我们可以使用束搜索和其他搜索算法来生成更好的响应。
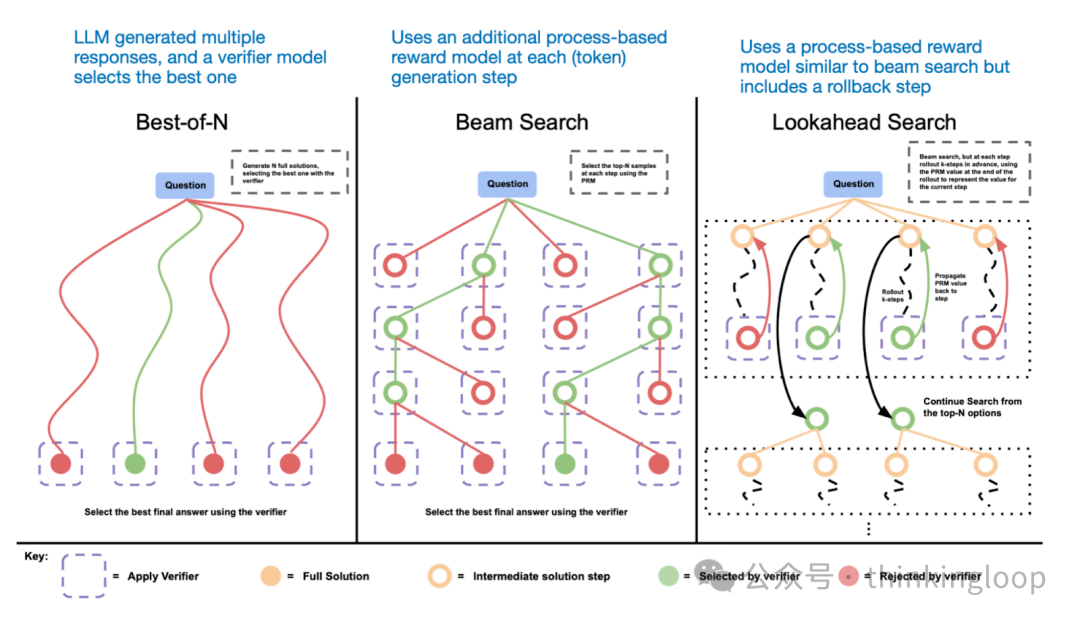
不同的基于搜索的方法依赖于基于过程-奖励的模型来选择最佳答案。来自LLM 测试时计算论文的注释图,https://arxiv.org/abs/2408.03314
《DeepSeek R1 技术报告》指出,其模型不使用推理时缩放。然而,这项技术通常在LLM的应用层实现,因此 DeepSeek 可能在他们的应用中应用了这项技术。我怀疑 OpenAI 的 o1 和 o3 模型使用了推理时scaling,这可以解释为什么它们相对于 GPT-4o 等模型来说相对昂贵。除了推理时scaling之外,o1 和 o3 可能还使用了类似于 DeepSeek R1 的 RL 管道进行训练。下两节将详细介绍强化学习。
4.2 纯强化学习(RL)
如前所述,DeepSeek 开发了三种类型的 R1 模型。第一种,DeepSeek-R1-Zero,建立在 DeepSeek-V3 基础模型之上,这是他们在 2024 年 12 月发布的标准预训练LLM。与典型的 RL 流水线不同,其中在 RL 之前应用了监督微调(SFT),DeepSeek-R1-Zero 完全使用强化学习进行训练,没有初始 SFT 阶段,如图下所示。
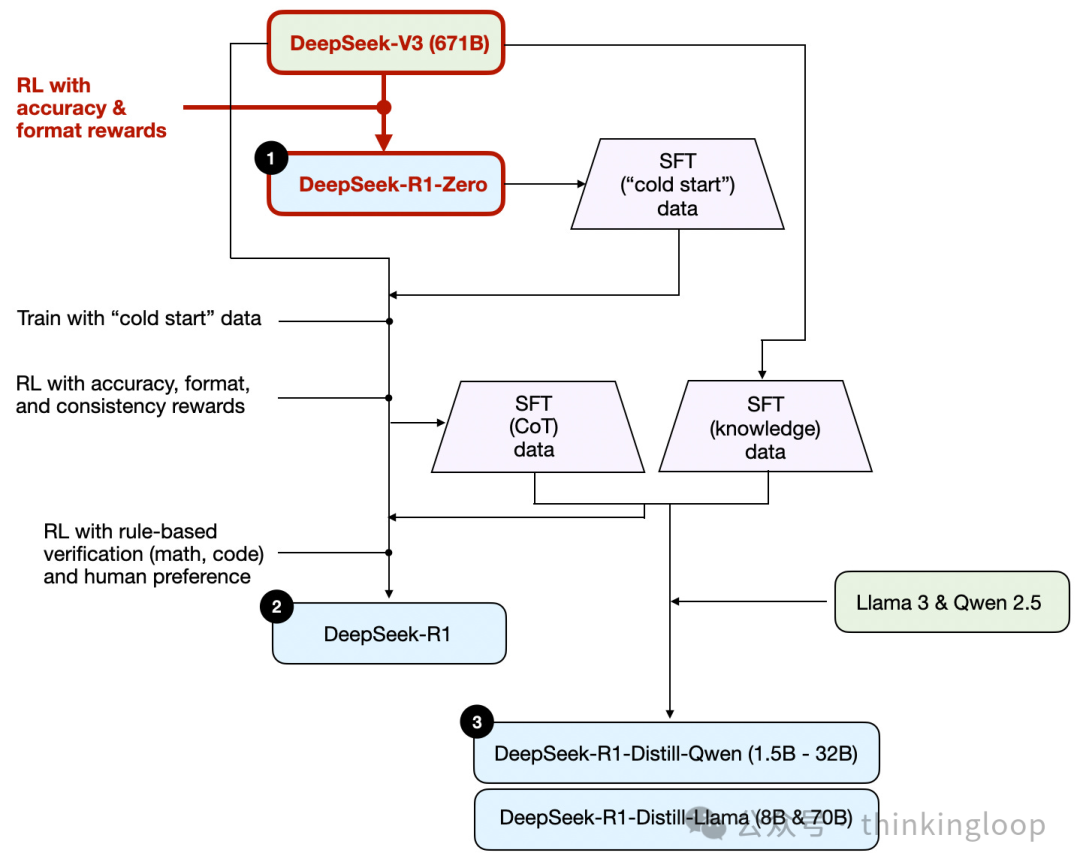
尽管如此,这个强化学习(RL)过程与常用的强化学习与人类反馈(RLHF)方法相似,通常应用于偏好调整LLMs。。但如上所述,DeepSeek-R1-Zero 的关键区别在于它们跳过了指令微调(SFT)阶段。这就是为什么他们称之为“纯”RL。尽管在LLMs的背景下,RL 与传统 RL 有显著差异。
为了奖励,他们没有使用基于人类偏好的奖励模型,而是采用了两种类型的奖励:准确度奖励(accuracy reward)和格式奖励(format reward)。
准确性奖励使用 LeetCode 编译器验证编码答案,并使用确定性系统评估数学回答。
格式奖励依赖于一个LLM评委来确保响应遵循预期格式,例如将推理步骤放在标签内。
DeepSeek研究人员在这样的推理路径上发现的“Aha moment”

该模型在解数学题的过程中学会了用拟人的语气重新思考——RL的力量
虽然 R1-Zero 不是一个表现最出色的推理模型,但它通过生成中间的“思考”步骤来展示推理能力,如图所示。这证实了使用纯强化学习开发推理模型是可能的,DeepSeek 团队是第一个(至少是第一个公开)展示这种方法的团队。
4.3 监督微调和强化学习(SFT + RL)
让我们标红SFT过程:
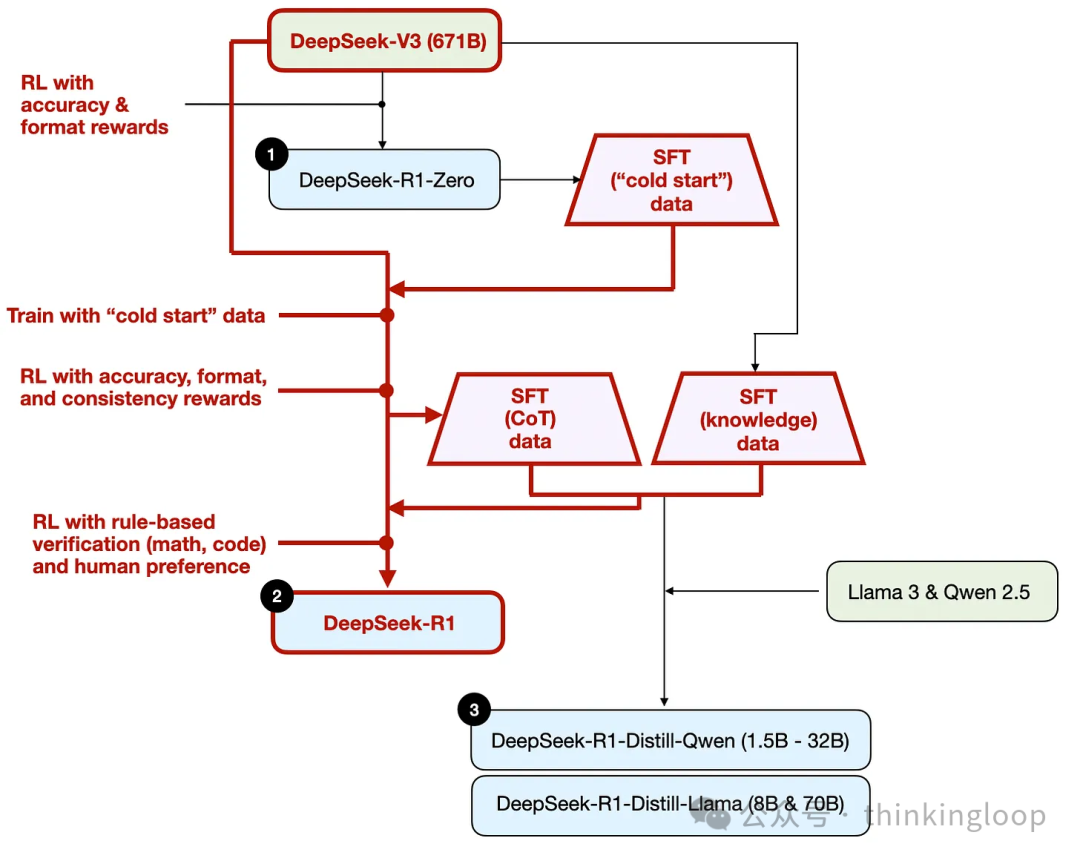
如图所示,DeepSeek 团队使用 DeepSeek-R1-Zero 生成了他们所说的“冷启动”SFT 数据。术语“冷启动”指的是这些数据是由 DeepSeek-R1-Zero 生成的,而 DeepSeek-R1-Zero 本身并未在任何监督微调(SFT)数据上进行训练。
使用此冷启动 SFT 数据,DeepSeek 随后通过指令微调训练模型,随后进入另一个强化学习(RL)阶段。此 RL 阶段保留了 DeepSeek-R1-Zero 的 RL 过程中使用的相同准确性和格式奖励。然而,他们增加了一致性奖励,以防止在模型在响应中切换多种语言时发生语言混合。
RL 阶段之后,又进行了一轮 SFT 数据收集。在这个阶段,使用了最新的模型检查点来生成 600K 思维链(CoT)SFT 示例,同时使用 DeepSeek-V3 基础模型创建了额外的 200K 基于知识的 SFT 示例。这些 60 万+20 万 SFT 样本随后用于另一轮强化学习。在这个阶段,他们再次使用基于规则的方法为数学和编码问题提供准确度奖励,而用于其他问题类型的是人类偏好标签。
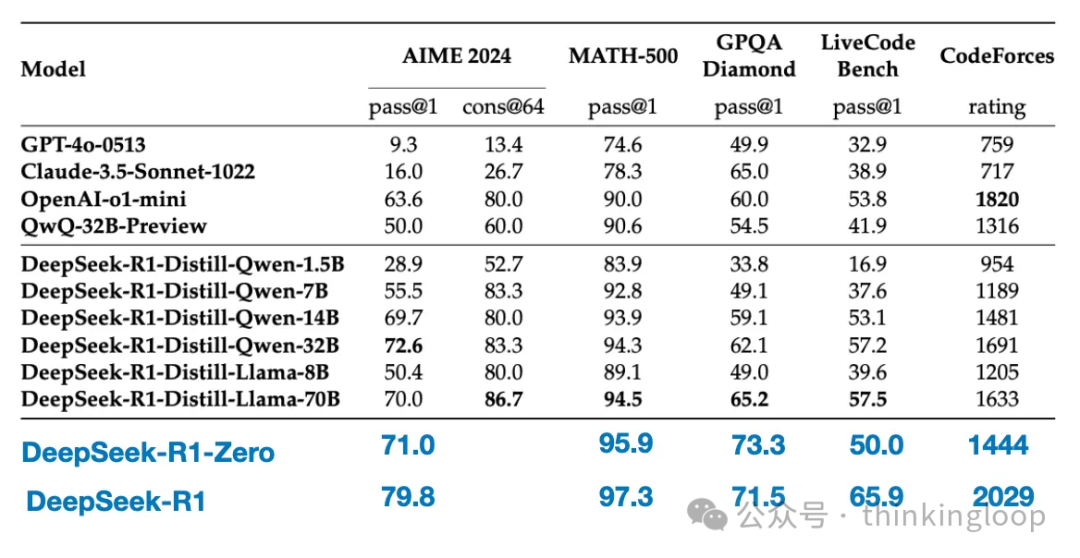
最终模型 DeepSeek-R1 相较于 DeepSeek-R1-Zero,由于增加了 SFT 和 RL 阶段,性能有显著提升,如表所示。
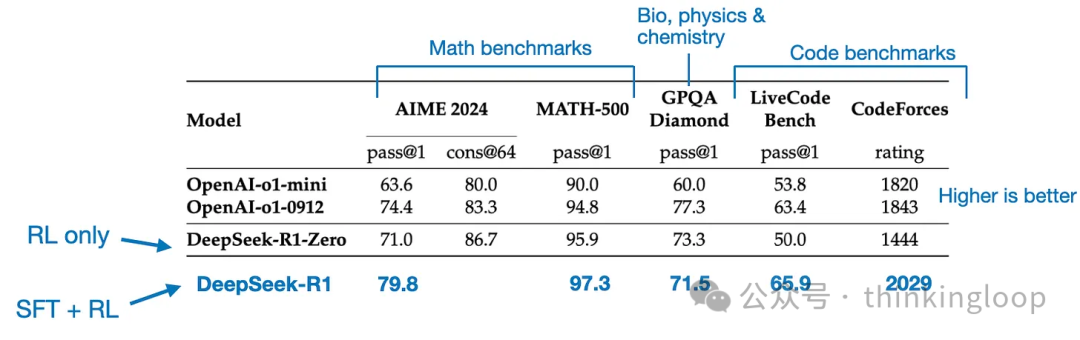
对比一下RL only 和SFT+RL在各个bench上的跑分
4.4 纯监督微调(SFT)和蒸馏
到这里只剩一个没有讲了——模型“蒸馏”。
令人惊讶的是,DeepSeek 还发布了通过他们称为蒸馏的过程训练的小型模型。然而,在 LLMs 的背景下,蒸馏并不一定遵循深度学习中使用的经典知识蒸馏方法。传统上,在知识蒸馏,一个较小的学生模型在较大的教师模型的 logits 和目标数据集上训练。
相反,这里的蒸馏指的是在由更大的LLMs生成的 SFT 数据集上对较小的LLMs进行指令微调,例如 Llama 8B 和 70B 以及 Qwen 2.5 模型(0.5B 到 32B)。具体来说,这些更大的LLMs是 DeepSeek-V3 和 DeepSeek-R1 的中间检查点(checkpoint)。实际上,用于此蒸馏过程的 SFT 数据集与上一节中描述的用于训练 DeepSeek-R1 的数据集相同。
为什么他们开发了这些蒸馏模型?在我看来,有两个关键原因:
小型模型更高效。这意味着它们运行成本更低,但它们也可以在低端硬件上运行,这使得它们对许多像我这样的研究人员和爱好者来说特别有趣。
纯 SFT 案例研究。这些提炼出的模型作为一个有趣的基准,展示了纯监督微调(SFT)在不使用强化学习的情况下可以将模型带到多远。
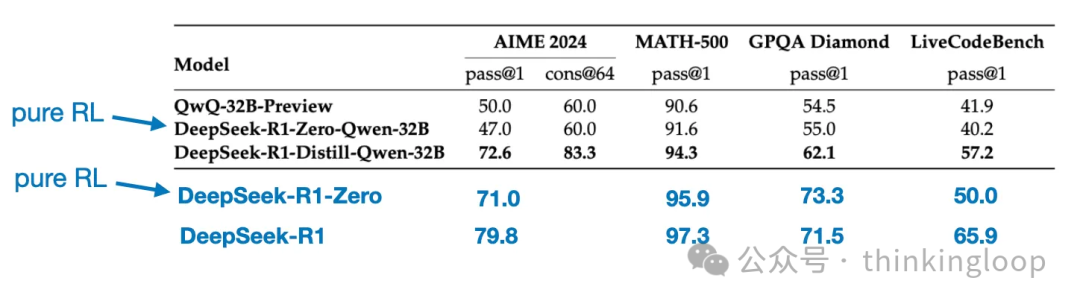
Qwen-32B 使用 SFT + RL 训练,类似于 DeepSeek-R1 的开发方式。这有助于确定当 RL 与 SFT 结合时,与纯 RL 和纯 SFT 相比,可以取得多少改进。
使用纯 SFT 训练的 DeepSeek-V3,类似于蒸馏模型创建的方式。这样就可以直接比较 RL + SFT 与纯 SFT 的有效性。
05
还有哪些启示性的工作
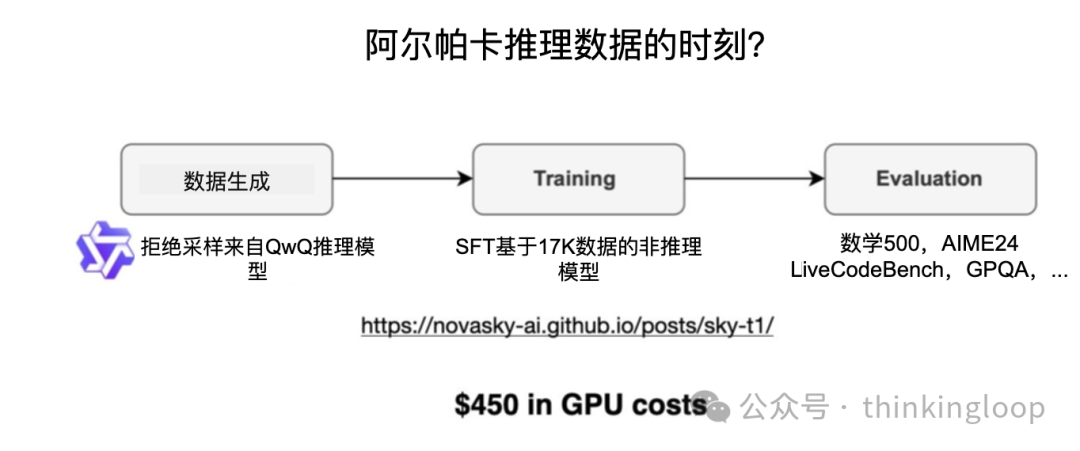
Sky-T1 :一个小团队仅使用 17K SFT 样本训练了一个开放权重 32B 模型。总成本?只需 450 美元。根据他们的基准测试,Sky-T1 的表现与 o1 大致相当,考虑到其低廉的训练成本,这很令人印象深刻。
纯 RL 的:TinyZero
虽然 Sky-T1 专注于模型蒸馏,我也在“纯强化学习”领域遇到了一些有趣的工作。一个值得注意的例子是 TinyZero,一个具有 30 亿参数的模型,它复制了 DeepSeek-R1-Zero 的方法(旁注:训练成本不到 30 美元)。令人惊讶的是,即使只有 30 亿个参数,TinyZero 也展现出一些自验证能力,这支持了通过纯强化学习推理可以从小模型中产生的观点。
上述两个项目表明,即使在有限的预算下,进行推理模型的研究也是可能的。虽然这两种方法都复制了 DeepSeek-R1 的方法,一个专注于纯强化学习(TinyZero),另一个专注于纯SFT(Sky-T1),但探索这些想法如何进一步扩展将是非常有趣的。
06
推理模型应用在哪里?
编者按:
推理模型放在我们过往的Agent框架里面效果如何(据传很多公司工程师去年搭建了一年的Agent春节期间被老板push换成deepseek—R1,这样做很容易让之前的努力全部白费,因为input/output和评价标准、路由体系都要update。
企业级客户虽然会更加谨慎选择,但什么场景是适合推理模型企业级试水的呢?(除了R1的写作能力)(毕竟解密、Leetcode解题并不是2B的刚需、在一些传统任务上大家还是在Sonnet+4o)
o3的第一个PMF或者说MMF(model marketing fit)在哪里?时延要求高的肯定不是,COT过程中出现一些问题会导致结果受影响的肯定不是。会是大家近期在讲的搜索嘛?似乎联网搜索+深度思考是一个更迫近日常生活用途的搜索方式。但机器思维链代替人的思维链这个过程还需要时间去验证(同时r1级别的模型更容易产生人类无法甄别的幻觉信息,这会让学会“say no”之前的机器思维链更不可信)。

更多阅读
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢