
一、引领大模型技术新纪元
OpenSeek是由北京智源人工智能研究院(BAAI)发起的开源共创项目,旨在联合全球开源社区,推动算法、数据和系统的协同创新,开发出超越DeepSeek的下一代模型。该项目从Bigscience和OPT等大模型共创模式中汲取灵感,致力于构建一个开源自主的算法创新体系。
自DeepSeek模型开源以来,学术界和工业界涌现出众多算法改进和突破,但这些创新往往面临以下挑战:缺乏完整的代码实现、必要的计算资源以及高质量的数据支持。OpenSeek项目期望通过联合开源社区的力量,探索高质量数据集的构建机制,推动大模型训练全流程的开源开放,并构建创新的训练和推理代码以支持多种AI芯片,从而促进自主技术创新和应用发展。
OpenSeek项目的核心目标包括:
-
创新数据合成技术:解决高质量数据获取的挑战,打破数据壁垒,为模型训练提供更丰富、更高质量的数据资源。 -
支持多AI芯片:减少对特定芯片的依赖,提升模型的通用性和适应性,使其能够在多种AI芯片上高效运行,降低硬件成本,提高应用的灵活性。 -
构建开源自主的算法创新体系:通过开源合作,促进算法的自主创新和技术共享,激发全球开发者和研究者的创造力,推动AI技术的快速发展。
-
高质量数据开源开放 -
开源大规模高质量中英文数据集(>4TB),涵盖丰富多样的数据类型和场景,并通过OpenSeek模型训练进行充分验证。 -
开源高质量数据集构建方案,支持基于人工数据进行多样性高质量数据合成,助力开发者在数据层面实现创新。 -
多AI芯片分布式训练框架 -
支持Triton算子,支持多元芯片训练,兼容多种硬件架构,确保不同设备的高效利用。 -
实现更高效计算、通信与访存联合协同的混合并行方案,提供集群实训日志和性能数据,助力开发者优化大规模训练任务。 -
模型结构优化改进 -
探索OpenSeek-small和OpenSeek-Mid等两个不同尺寸的模型结构优化,以满足不同应用场景的需求。 -
提供小尺寸模型的训练经验与优化方案,帮助开发者在资源受限的环境中实现高性能开发部署。
-
英文Common Crawl -
https://data.commoncrawl.org/contrib/Nemotron/Nemotron-CC/index.html -
https://huggingface.co/datasets/HuggingFaceFW/fineweb-edu -
中文Common Crawl -
https://huggingface.co/datasets/BAAI/CCI3-HQ -
https://huggingface.co/datasets/opencsg/Fineweb-Edu-Chinese-V2.1 -
其他Domain -
Wiki & Books & Arixv -
英文:https://huggingface.co/datasets/allenai/dolma -
中文:自建的中文百科、图书和文献数据 -
Math -
https://huggingface.co/datasets/OpenCoder-LLM/opc-fineweb-math-corpus -
https://huggingface.co/datasets/EleutherAI/proof-pile-2 -
https://huggingface.co/datasets/HuggingFaceTB/finemath -
Code -
https://huggingface.co/datasets/OpenCoder-LLM/opc-fineweb-code-corpus -
https://huggingface.co/datasets/HuggingFaceTB/smollm-corpus -
https://huggingface.co/datasets/bigcode/the-stack-v2
-
通用知识标签体系构建:参考论文Key-Point-Driven Data Synthesis with its Enhancement on Mathematical Reasoning。基于大模型,分析数学、代码、常识问答等领域开源数据涉及的常见知识点,构建通用知识标签体系。 -
原始语料标注、筛选:结合知识标签体系,应用大模型对语料进行打标。根据文章知识点类型采样、区分适合合成简单QA的语料与适合合成长CoT QA的语料。 -
预训练QA数据合成: -
简单QA合成:基于开源模型,从原始语料中抽取Question-Answer对。 -
Long-CoT-Backward数据合成:对原始文档进行分段摘要、组织CoT过程、总结Query。以 {Query, CoT过程, 原始文档} 作为一条训练样本。 -
Long-CoT-Forward数据合成:在Backward数据合成基础上,调用开源强推理模型,优化、精炼Backward数据中的CoT过程,重新给出Query对应的高质量CoT解答。以 {Query, 优化后的CoT过程, 模型回答} 作为一条训练样本。 -
Long-CoT-RAG数据合成:参考论文Search-o1: Agentic Search-Enhanced Large Reasoning Models。搜集开源指令,采用推理+RAG的方式给出指令的高质量回复。 -
RL数据:基于通用知识标签体系,从合成数据中进一步采样高质量的推理类型数据(数学、代码、较难常识等)及非推理数据(写作、翻译等)。 -
质量过滤:结合奖励模型、规则验证等对数据的质量进行打分及过滤。
-
基于MiniHash的全局模糊去重 -
https://github.com/huggingface/datatrove/blob/main/examples/minhash_deduplication.py -
Exact substring deduplication -
https://github.com/google-research/deduplicate-text-datasets
-
基于data-juicer工具https://github.com/modelscope/data-juicer 进行二次开发,主要规则包括以下 -
文档字符长度 -
文档平局句子字符长度 -
繁体中文转简体中文 -
敏感词和安全词过滤
-
中文基于教育水平的质量分类器进行预估 -
英文综合多个教育水平的质量分类器进行综合预估
-
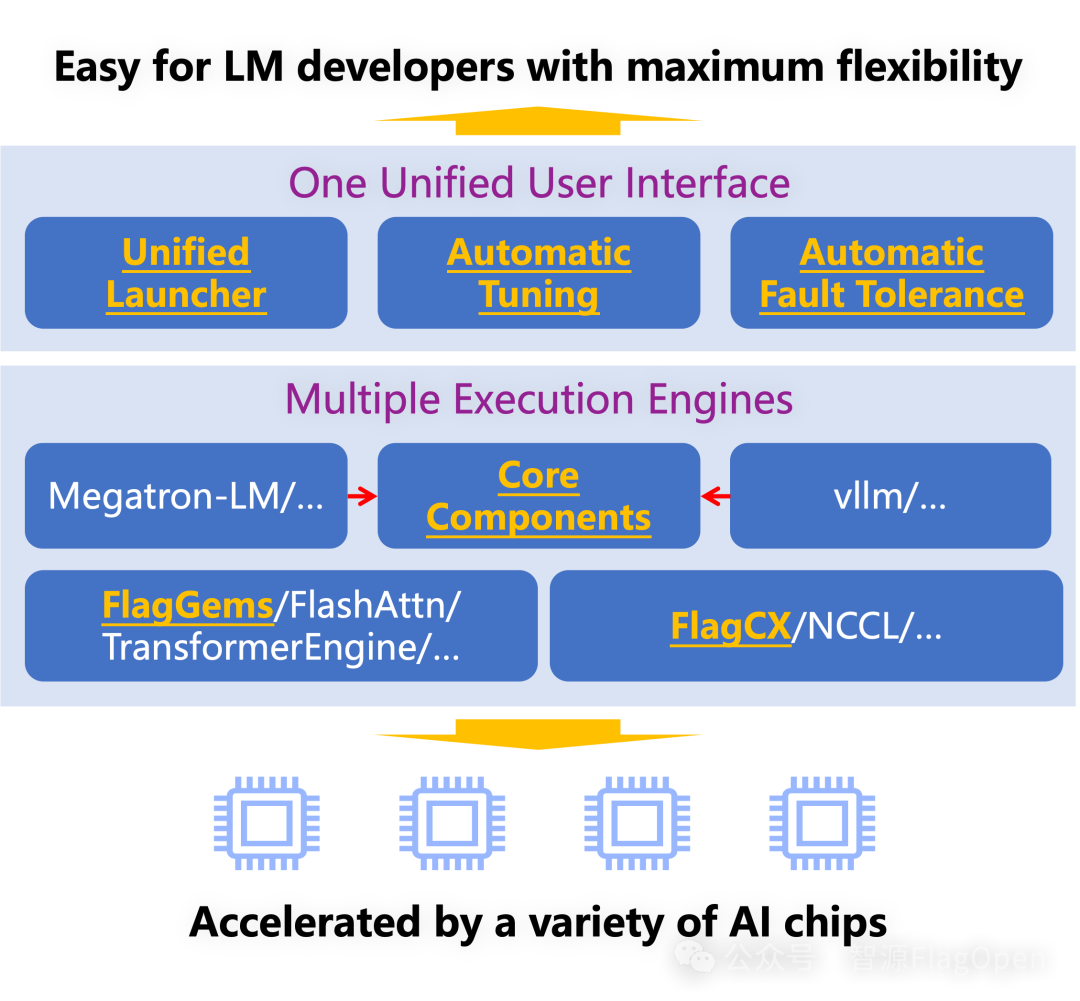
前端(Frontend) 提供统一的用户界面和自动化工具,如统一启动器和自动调优,为用户良好使用体验。 -
中间件(Middleware) 包括自研和开源的多个高性能执行引擎,涵盖训练、压缩、推理和服务等各个阶段,增强系统的灵活性和扩展性。 -
后端(Backend) 包含底层算子库和通信库,确保高效可靠的性能,尤其是基于Triton的FlagGems算子库(https://github.com/FlagOpen/FlagGems)和异构统一通信库(https://github.com/FlagOpen/FlagCX),能够实现不同芯片上的计算与通信。
-
模型结构改进:进一步改进 MLA、MTP、MoE 等,以优化模型性能和训练效率。 -
计算与通信调度优化:研发适用于更多芯片的高通用性计算与通信调度技术,提升跨硬件平台的兼容性和计算效率。 -
低精度训练优化:探索 FP8 等低精度数值格式的稳定训练方案,并开发相应的算子优化,以降低计算成本并提高训练稳定性。
-
拥有大模型训练经验的深度学习专家; -
致力于数据构建与算法创新的数据科学家; -
亦或是对开源项目充满热情的初学者;
-
代码与技术方案贡献:如果你对训练流程、代码实现或性能优化有独到见解,欢迎提交 Pull Request,与我们一起推动项目进展。 -
数据、算法与资源支持:如果你拥有高质量数据集、创新算法或其他有价值的资源,并希望以非代码形式贡献力量,请直接联系我们,共同探讨合作方式。 -
参与技术讨论与文档完善:分享你的见解、经验和建议,帮助我们不断完善项目文档和技术细节。
-
数据: -
构建数据处理和数据合成的pipeline -
构建OpenSeek-PT-1.3T-v0.1 -
基于OpenSeek-Small数据配比实验结果构建OpenSeek-data-1.3T正式版 -
训练: -
完成3B在OpenSeek-PT-1.3T-v0.1上的训练(Baseline) -
完成OpenSeek-Small实验性训练(~100B) -
系统: -
对MLA、DeepSeek MoE、MTP、Auxiliary-Loss-Free等分布式训练支持 -
DeepSeek V3参数转换并加载
-
数据: -
扩大数据规模,构建OpenSeek-PT-4T -
构建Long-CoT-Backward数据集并验证效果 -
训练: -
完成OpenSeek-Small的超参实验 -
验证OpenSeek-PT-4T效果 -
完成OpenSeek-Small在OpenSeek-PT-1.3T-v1.0的完整训练 -
系统: -
支持Node-limited Routing MoE -
FP8分布式训练支持 -
集成基于Triton的算子库FlagGems
-
数据: -
扩大数据规模,构建OpenSeek-PT-8T -
构建OpenSeek-Zero数据集 -
构建OpenSeek-RL数据集 -
构建OpenSeek-SFT数据集 -
构建Long-CoT-Forward数据集并验证效果 -
训练: -
DualPipe流水线并行支持 -
进一步计算通信重叠与显存优化 -
系统: -
完成OpenSeek-Small-Zero开发 -
完成OpenSeek-Small-SFT开发 -
完成OpenSeek-Small-RL开发 -
完成OpenSeek-Mid的超参实验 -
验证OpenSeek-PT-8T效果 -
完成OpenSeek-Mid在OpenSeek-PT-8T的完整训练 -
完成OpenSeek-Mid-Zero开发 -
完成OpenSeek-Mid-SFT开发 -
完成OpenSeek-Mid-RL开发
-
数据: -
发布正式版本OpenSeek系列数据集 -
构建Long-CoT-RAG数据集并验证效果 -
训练: -
完成OpenSeek-Mid-Zero开发 -
完成OpenSeek-Mid-SFT开发 -
完成OpenSeek-Mid-RL开发 -
系统: -
对不同芯片进行训练适配和精度对齐 -
针对特定芯片,实现定制化的并行策略和优化策略

-
社区计划于下周召开首次贡献者会议,会议将为大家介绍项目详情并解答基础疑问。 如果您对项目贡献感兴趣,欢迎通过扫描上方二维码加入群聊报名参加贡献者会议。
内容中包含的图片若涉及版权问题,请及时与我们联系删除


评论
沙发等你来抢