


关键词:人类感知 动作生成

导 读
本文是对发表在机器学习领域顶级会议 ICLR 2025 的论文 Aligning Human Motion Generation with Human Perceptions 的解读。该论文由北京大学王亦洲课题组与北京大学艺术学院、华为合作完成。
该工作提出一种数据驱动的方法,将人体动作生成与人类感知对齐。该工作首先收集了大规模的人类感知评估数据集——MotionPercept,并基于此训练了人类动作评价模型——MotionCritic,用以捕捉人类的运动感知偏好。该模型为动作质量评估提供了更为准确的度量标准,可以轻松集成到动作生成模型中。实验表明该方法在评估和提升生成运动的质量方面表现出显著的效果,能够有效与人类的感知对齐。
论文链接:
https://arxiv.org/pdf/2407.02272
项目主页:
https://motioncritic.github.io/
开源代码:
https://github.com/ou524u/MotionCritic
01
研究背景
人体动作生成(Human Motion Generation)是计算机视觉和图形学领域的一个重要任务,广泛应用于虚拟现实(VR/AR)、人机交互、数字虚拟人等多个领域。高质量的动作生成不仅要求生成动作自然、流畅且符合生物力学原理,还需要具备高度的合理性和真实感。符合人类感知的人体动作生成是一个具有挑战性的任务。动作生成模型的表现“不如人意”,很大程度上与评估方法的缺失紧密相关。传统的评估方法主要依赖与真实动作的误差比较、简单的启发式规则,或是与真实动作分布间的距离度量(例如 Fréchet Inception Distance,FID)。然而正如此前工作指出[1],上述方法难以全面地反应人类对动作质量的主观评价,这种评估方法的缺陷严重制约了动作生成模型的进一步发展和优化。
为了应对这一挑战,我们主张发展与人类感知对齐的自动化评估方法。原因主要有以下两点:
1. 人类是动作生成的主要受众与交互对象。人体动作生成的最终目标是为人类服务,无论是在虚拟环境中与人类互动,还是作为数字人直接面向用户,人类的感知都是衡量动作生成质量的关键。
2. 人类对生物动作的感知极为敏感。研究表明,人类大脑中存在专门处理生物动作的神经机制,即便是细微的不自然动作,也会被人类觉察到。因此,简单的客观评估指标难以替代人类主观感知对动作质量的判断。
为了解决上述问题,本文提出了一种全新的数据驱动方法,通过学习人类对动作的感知偏好,弥合生成模型与人类主观感知之间的鸿沟。具体来说,本文构建了一个大规模的人类感知评估数据集——MotionPercept,以及一个基于该数据集训练的动作质量评估模型——MotionCritic。
该方法的主要优点包括:
1. 感知驱动的评估:通过数据驱动的方式,直接从人类对动作的评价中学习一个与人类感知对齐的评估模型。相比于传统的客观指标,这种方法能够更准确地反映人类对动作质量的主观感知。
2. 即插即用的优化能力:MotionCritic 模型不仅可以作为评估工具,还能够集成到现有的人体动作生成模型中,对生成质量进行优化。其“即插即用”的特性使得现有动作生成模型能够快速对齐人类的感知偏好,提升生成效果。
02
方法简介
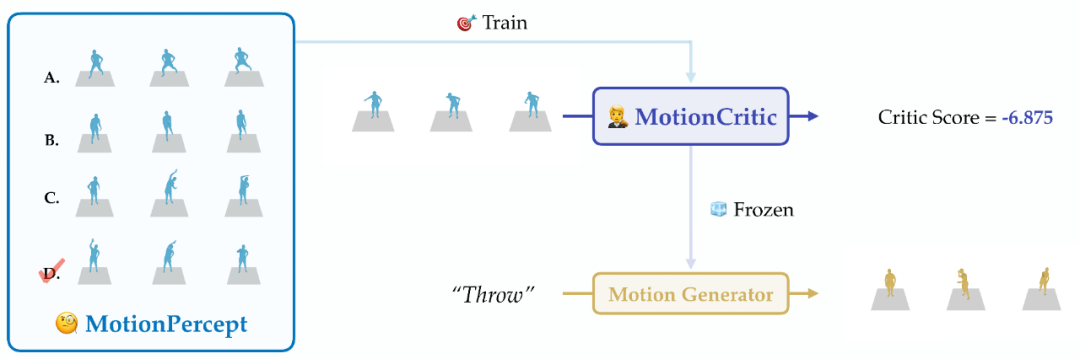
图1. 框架概览
首先,我们创建了 MotionPercept,一个大规模的人工标注数据集,用于人体动作的感知评估。在数据收集过程中,我们生成了两万多条互为对比的动作序列,并邀请标注者选择出质量最佳的动作。标注者根据动作的自然性、视觉美感以及是否存在瑕疵等标准,进行单选评判,从而对于每个选择题建立起三组优-劣动作对。经过培训、试标、标注和筛选,我们最终发布的 MotionPercept 数据集中包含 52590 组动作对。
基于这一数据集,我们训练了 MotionCritic,一个自动评估动作质量的模型。该模型采用 DSTFormer[5]结构,基于 MotionPercept 训练而来,能够根据人类的感知偏好给生成的动作打分,从而为动作生成提供更精准的量化人类感知。我们观察到 MotionCritic 能够有效地对生成的动作进行评分,并具备与人类感知相似的良好性质。此外,MotionCritic 能够作为生成过程中的监督信号,通过简单的微调即可显著提升模型的输出质量。我们将 MotionCritic 嵌入到动作生成训练流程中,通过与生成模型的对接,仅需少量的调整即可实现与人类感知的高效对齐。
03
实验结论
MotionCritic 作为动作质量评估指标
MotionCritic 能够准确反映生成动作的质量,且与人类的感知偏好高度一致。从动作-分数映射的角度考察 MotionCritic,我们的模型在动作评估中展现出了鲁棒性,同时对动作扰动高度敏感,符合人类的认知特征。
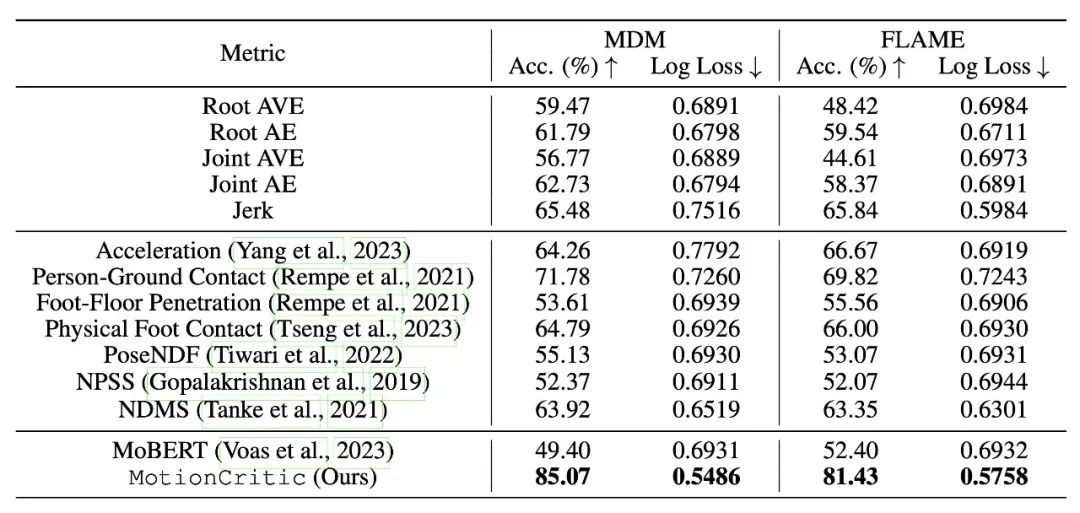
表1. 在 MotionPercept 的 MDM[2]和 FLAME[3]测试集上,针对动作评估指标的定量比较。我们的方法取得了最佳表现。
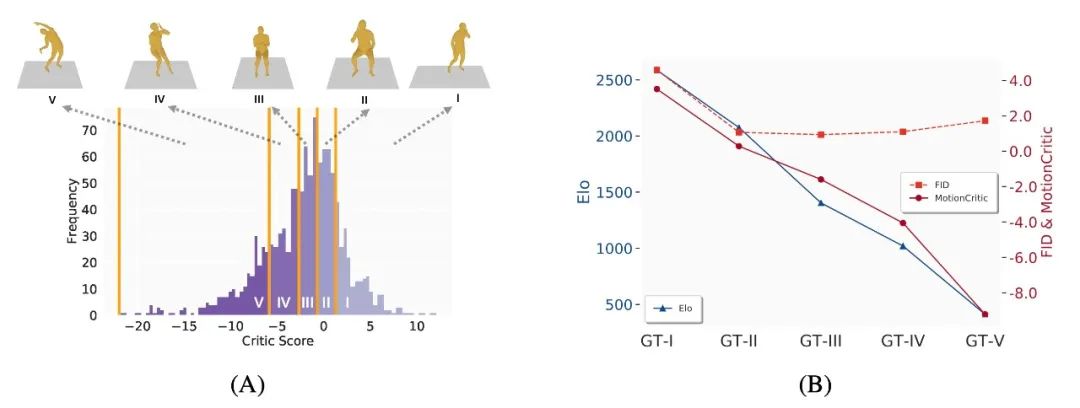
图2. 我们将 HumanAct12[4]测试集划分为 5 个子集,并比较它们的质量。(A):根据 MotionCritic 评分将不同子集从高到低进行划分。(B):不同子集的 Elo 评分、FID 和平均 MotionCritic 评分。MotionCritic 与人类 User Study 的结果高度对齐。
进一步地,我们应用 MotionCritic 完成数据集诊断。我们发现评分较高的动作质量普遍更好,对齐人类感知;同时评分较低的动作往往是数据集中的“残次品”,存在质量问题。这一发现展示了 MotionCritic 在揭示数据问题和提高评估精度方面的潜力,进一步增强了其作为动作质量指标的实用性。
MotionCritic 作为监督信号
在训练阶段,我们将 MotionCritic 作为监督信号进行微调,实验结果表明,这一方法显著提高了生成动作的质量。通过与生成模型结合,微调后的 MotionCritic 能够有效提升生成的动作质量,并且只需数百次的迭代即可达到较高的评分。相比传统的训练方法,微调的效率和效果表现出了明显的优势。
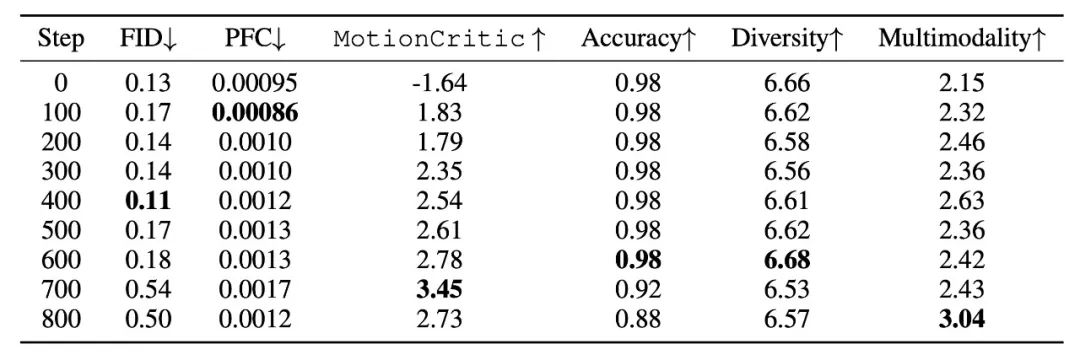
表2. 不同微调步数下生成动作的对应指标
这一过程不仅优化了生成模型的性能,还确保了生成动作与人类的感知标准更为一致,解决了现有生成方法中缺乏有效监督信号的问题。通过这种方式,我们能够在短时间内显著提升动作生成模型的表现,确保其生成结果符合人类对动作质量的主观评价。
04
总 结
综上所述,我们提出的 MotionCritic 作为一种基于人类感知的动作质量评估指标,在评估和优化生成动作的质量方面表现出了卓越的效果。其在动作质量评估和数据集诊断中的应用,以及作为训练监督信号在生成模型中的有效性,都表明了这一方法的巨大潜力。通过与人类感知对齐,MotionCritic 不仅提升了动作生成的质量,还为未来生成模型的优化提供了新的方向。
项目视频:
参考文献:
[1] Jordan Voas, Yili Wang, Qixing Huang, and Raymond Mooney. What is the best automated metric for text to motion generation? SIGGRAPH Asia 2023.
[2] Guy Tevet, Sigal Raab, Brian Gordon, Yoni Shafir, Daniel Cohen-or, and Amit Haim Bermano. Human motion diffusion model. ICLR 2023.
[3] Jihoon Kim, Jiseob Kim, and Sungjoon Choi. Flame: Free-form language-based motion synthesis & editing. AAAI 2023.
[4] Chuan Guo, Xinxin Zuo, Sen Wang, Shihao Zou, Qingyao Sun, Annan Deng, Minglun Gong, and Li Cheng. Action2motion: Conditioned generation of 3d human motions. ACM Multimedia 2020.
[5] Wentao Zhu, Xiaoxuan Ma, Zhaoyang Liu, Libin Liu, Wayne Wu, and Yizhou Wang. Learning human motion representations: A unified perspective. ICCV 2023.

图文 | 王浩如
Computer Vision and Digital Art (CVDA)
About CVDA
The Computer Vision and Digital Art (CVDA) research group was founded in 2007 within the National Engineering Research Center of Visual Technology at Peking University led be Prof. Yizhou Wang. The group focuses on developing computational theories and models to solve challenging computer vision problems in light of biologically plausible evidences of visual perception and cognition. The primary goal of CVDA is to establish a mathematical foundation of understanding the computational aspect of the robust and efficient mechanisms of human visual perception, cognition, learning and even more. We also believe that the marriage of science and art will stimulate exciting inspirations on producing creative expressions of visual patterns.
CVDA近期科研动态


— 版权声明 —
本微信公众号所有内容,由北京大学前沿计算研究中心微信自身创作、收集的文字、图片和音视频资料,版权属北京大学前沿计算研究中心微信所有;从公开渠道收集、整理及授权转载的文字、图片和音视频资料,版权属原作者。本公众号内容原作者如不愿意在本号刊登内容,请及时通知本号,予以删除。

点击“阅读原文”转论文链接
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢