


论文题目:Commonsense Knowledge Representation, Reasoning and Application
作者:Ying Su
类型:2024年博士论文
学校:Hong Kong University of Science and Technology(香港科技大学)
下载链接:
链接: https://pan.baidu.com/s/190hB6MQC-e9TsuBpEp0weQ?pwd=i5ty
硕博论文汇总:
链接: https://pan.baidu.com/s/1Gv3R58pgUfHPu4PYFhCSJw?pwd=svp5
1.1 动机
人类层面的知识理解是人工智能的基础。常识知识包括各种组成部分,包括有关事件及其影响的基本事实,以及对知识获取方式的洞察,以及信念和愿望 [3]。近年来,旨在使机器理解常识知识的研究越来越受欢迎,并已成为人工智能领域的一项关键挑战。
多年来,研究人员已经建立了知识图谱来存储和表示结构化的人类知识[4, 5]。随着21世纪互联网的快速发展,大量的网络内容不断积累,其中包含大量人类知识[6]。各种知识图谱应运而生,它们以手工制作的资源和从网络内容中自动构建的本体[7, 8]为基础,例如词汇知识图谱[4, 9, 10]、事实知识图谱[11, 12, 13]和常识知识图谱[14, 15]。知识图谱的演进从词级迁移到短语级或句子级,语义越来越复杂。
另一个知识来源是在大型语料库上预先训练的生成语言模型。语言模型大致分为两类,自动编码模型[16,17,18,19,20]和自回归模型[21,22,23,24,25]。生成模型能够处理各种形式的推理问题,包括算术、逻辑和常识。它们是否完全或准确地覆盖了常识知识值得探索。最近的大型语言模型已经发展到十亿参数大小[26,27,28,29]。这些模型在常识相关任务上表现出色,例如即使在零样本或少量样本设置下也能回答问题。除了自然语言处理,大型语言模型在视觉方面也取得了巨大的进步。近年来,视觉语言模型的发展经历了巨大的进步[30,31]。
知识图谱提供了实体及其关系的结构化表示,通常来自可靠的人工策划来源。实体之间丰富的语义联系使复杂的查询能力成为可能 [32、33、1、34、35] 并支持逻辑推理 [36、37、38、39、40、41、42、43]。相比之下,语言模型在大型语料库上进行训练后,擅长理解和生成自然语言文本。预训练的语言模型可以通过微调轻松适应各种任务 [44、45]。将知识图谱中的知识集成到语言模型中[46、47、48、49、50],或采用结合两者的检索推理框架[51、52、53、54、55、56、57、58、59],已变得越来越流行,用于探索对显性和隐性知识源进行复杂推理的能力。
随着 GPT-3 [24]、GPT-4 [26]、OPT [29]、BLOOM [28] 和 LLaMA [27] 等模型的出现,语言模型规模扩大的趋势加速。这些模型表明,具有更多参数的更大架构可以显著改善各种应用,包括文本生成、翻译和对话代理。提示技术的使用通过从 LLM 中引出设计好的响应来提高输出的质量和相关性。多步推理 [60]、渐进式提示 [61] 和提示聚合 [62] 等策略有效地设计了跨多个 LLM 的提示,在文本分类、数学和问答等任务中实现了显着的性能提升。此外,思路链 (CoT) 推理 [63, 64] 使 LLM 能够在解决问题时产生中间步骤,从而紧密模仿人类的推理过程。这对于需要多步推理的复杂任务(例如数学问题解决和逻辑推理)尤其有价值。除了提示和 CoT 推理之外,指令调整 [63、65、66、67、68] 是另一种技术,它涉及使用明确指令对一组不同的任务进行微调,帮助 LLM 通过学习遵循特定指令而在各种应用程序中进行推广。
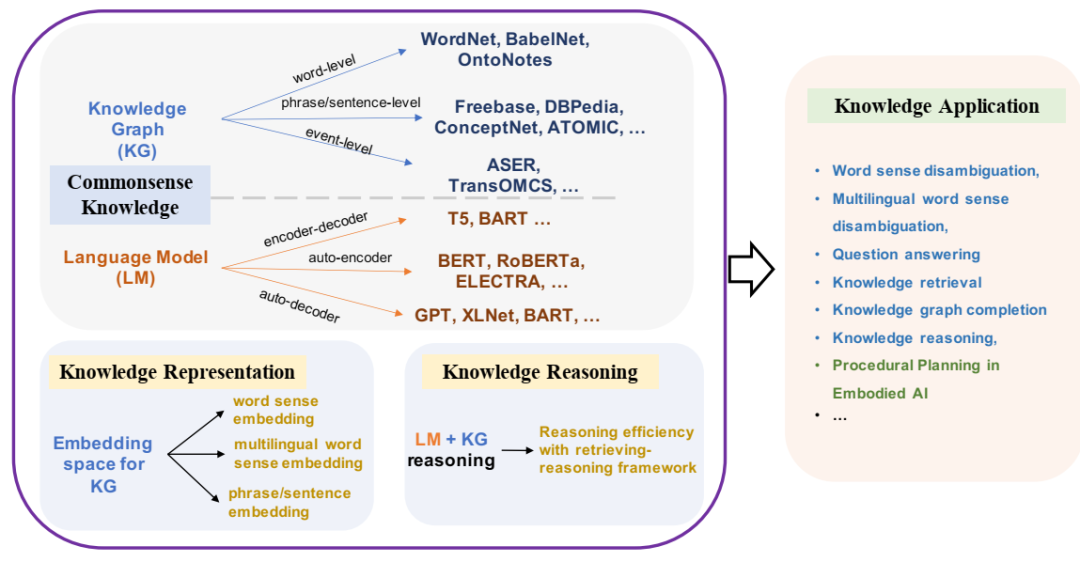
论文框架概述。
因此,从这些知识源中提取和表示常识性知识,以及基于这些知识开发下游应用程序变得越来越重要。在图 1.1 中,我们展示了论文研究的概要,其中包括以下关键方面:1)对常识性知识源的研究,包括知识图谱和语言模型;2)使用知识图谱开发知识表示;3)使用语言模型和知识图谱执行知识推理;4)常识性知识表示和推理在下游应用中的应用。
基于我们对知识图谱和语言模型的研究,我们从常识知识的表示开始。知识图谱嵌入一直是一个长期存在的研究课题,涵盖从单词级到短语级的各个层次 [69, 70, 71, 72]。通过对这些表示的探索,我们发现学习偏差和数据稀缺仍然是单词级表示中的重大挑战。此外,由于短语级和句子级常识知识图中的稀疏性问题和语义复杂性,以前强调密集多关系结构学习的知识图谱嵌入方法无法同时有效地捕获松散的结构和丰富的语义知识。
知识图谱是常识性知识的可靠来源,编码了复杂的结构和逻辑关系。在大型语料库上训练的语言模型具有出色的泛化能力,可以轻松适应各种应用。研究提出将这两个来源的优势结合起来,通常是通过检索推理管道 [53、55、56、57、59]。在这种方法中,首先从知识图中检索相关知识,然后根据检索到的信息和语言模型进行推理。然而,这种管道效率低下,因为从知识图中检索冗余的图节点会引入显著的噪音。
通过采用基于知识图谱和语言模型的表示和推理策略,我们可以探索各种下游任务的应用,包括词义消歧、知识检索、常识知识图谱完成、常识问答和知识推理。大型语言模型的开发已在更复杂的具象人工智能任务中显示出令人鼓舞的结果,特别是它们能够作为配备合理常识知识的高级智能代理创建可操作的计划。我们的目标是通过研究复杂现实场景中更具挑战性的应用来推进这项工作,例如多模式家庭具象人工智能环境中的程序规划。
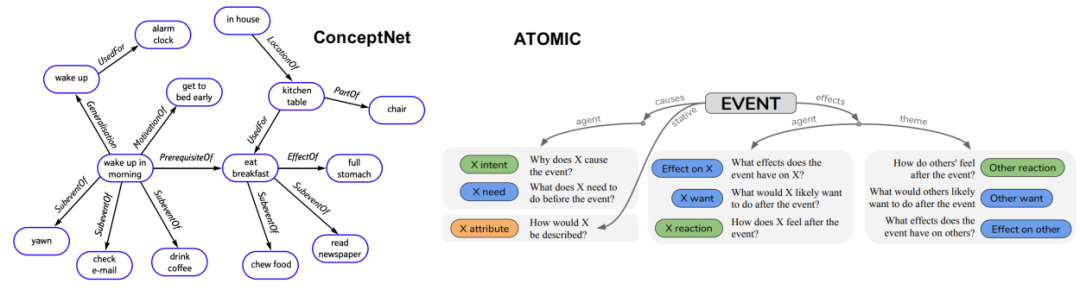
ConceptNet 和 ATOMIC 中的常识知识示例。
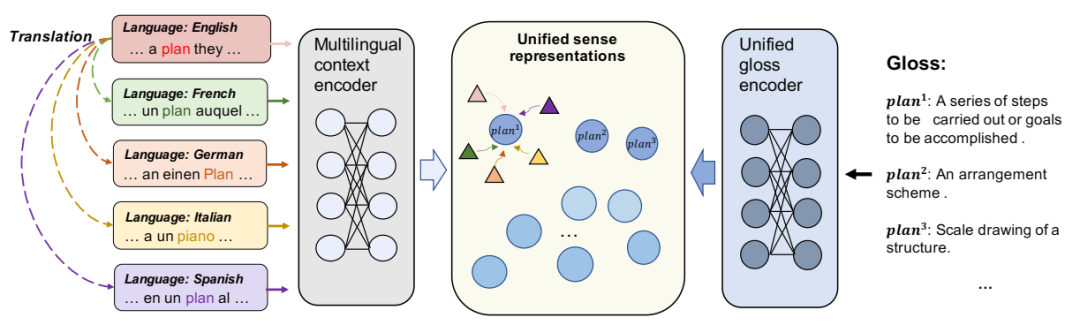
mBERT-UNI 模型的架构概述。我们将多语言 BERT 应用于编码器。上下文编码器将多语言上下文作为输入,并为目标词生成表示。注释编码器将注释作为输入,并生成统一的意义表示。针对每种语言计算目标词嵌入和候选意义表示之间的相似度得分。得分最高的意义即为模型预测的意义。
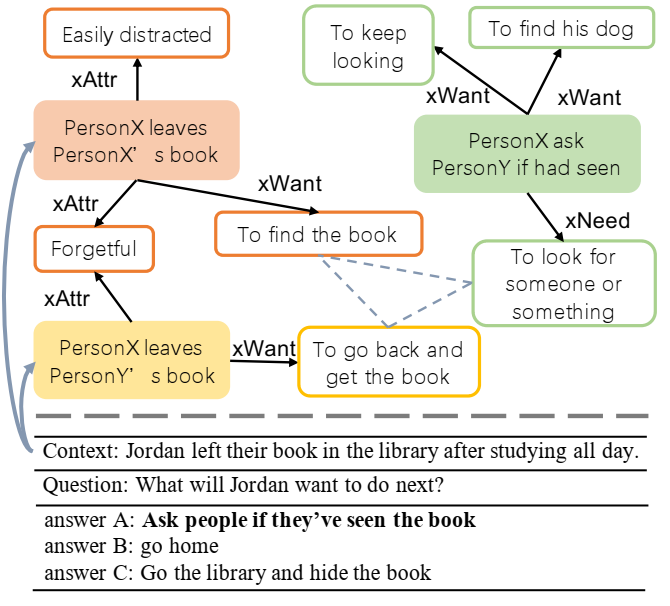
来自 CQA 任务 (SIQA [1]) 的示例以及 CKG (ATOMIC) 中的相关知识。
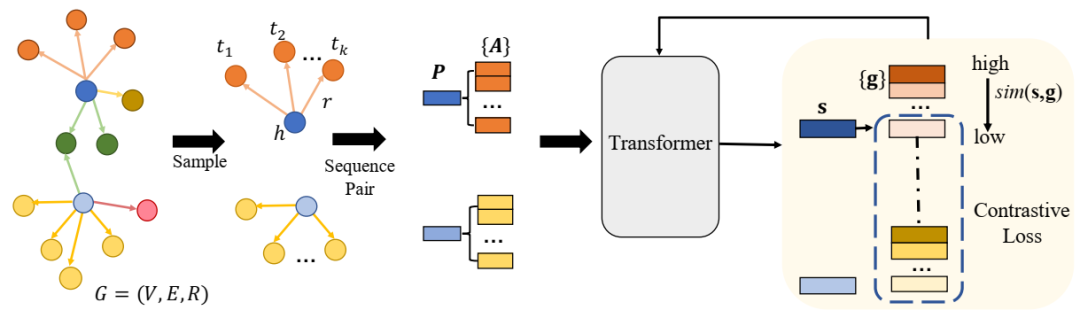
MICO 的概述框架。首先对知识三元组进行采样并将其转换为序列对。转换器块将序列对编码为知识嵌入。对比损失根据给定头序列的所选正尾序列和负尾序列之间的对比来更新转换器的参数。

将知识三元组 (h, r, t) 从 ATOMIC 转换为序列对 (P, A) 的示例。r−1 是 r 的逆关系。
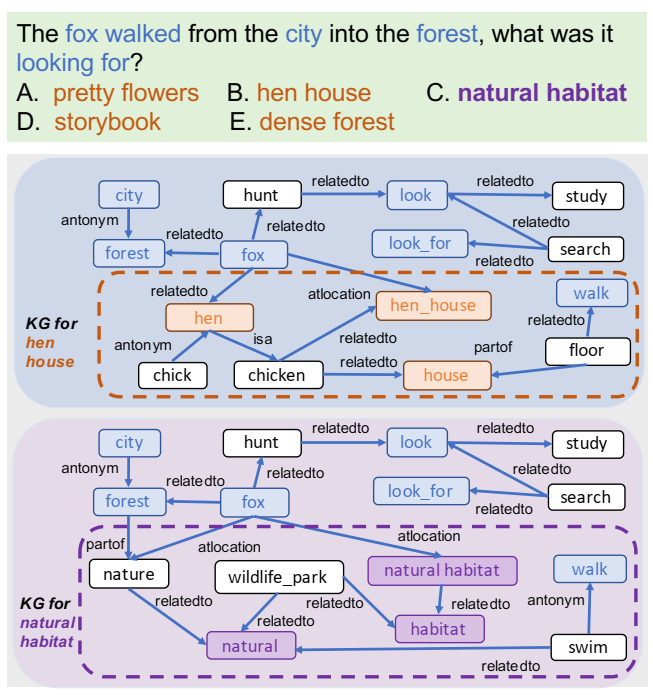
两个候选答案的查询和基础知识图谱示例。外部知识图谱节点在答案概念方面的多样性要高于问题概念方面的多样性。
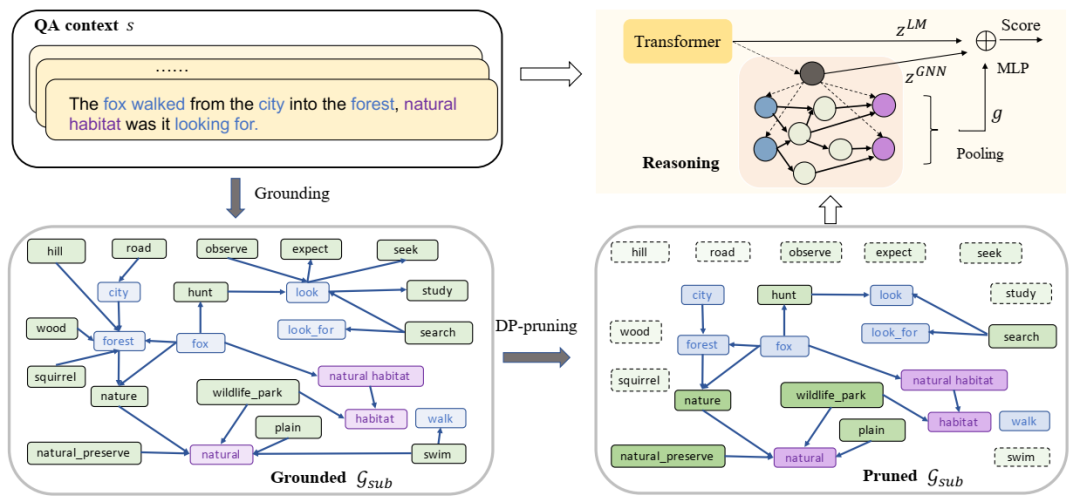
基础-剪枝-推理流水线 PipeNet 的总体框架。首先将概念节点基础化在知识图谱中,形成与问答上下文相关的子图 Gsub。在推理模块之前,剪枝模块根据节点得分剪枝噪声节点。最终答案得分基于上下文表示 zLM 和子图表示 zGNN 计算得出。
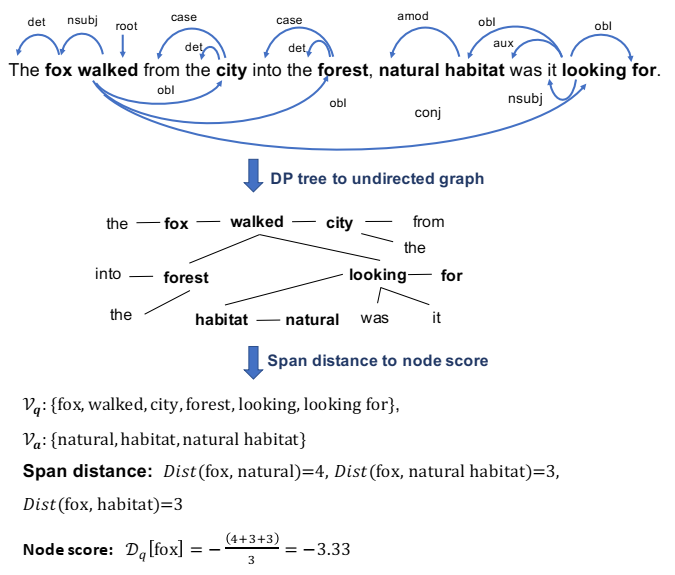
QA 上下文示例的依赖关系树。粗体字是 ConceptNet 中匹配的概念跨度。

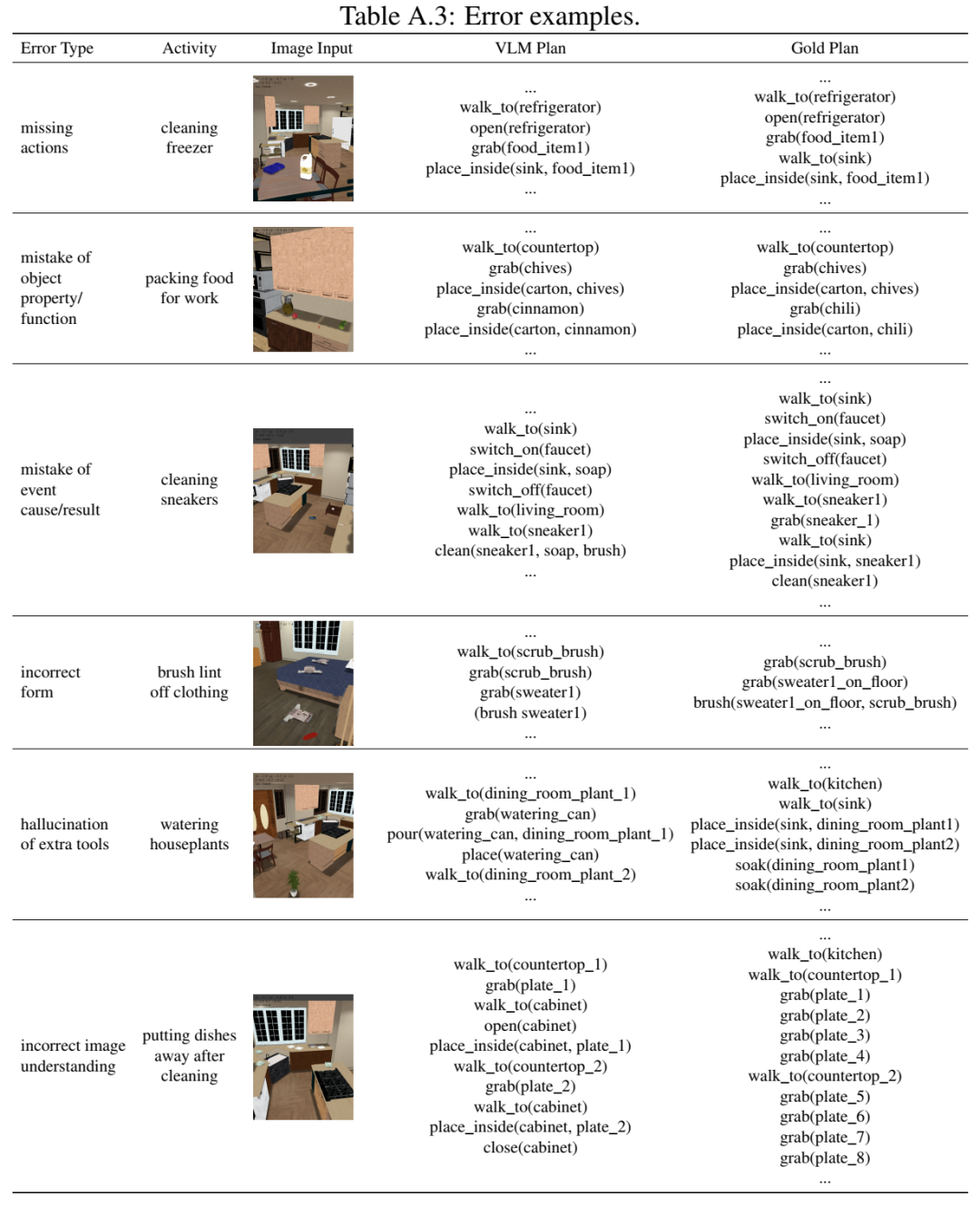
通过任务描述和环境图像的提示,使用 VLM 生成家庭活动的程序计划。
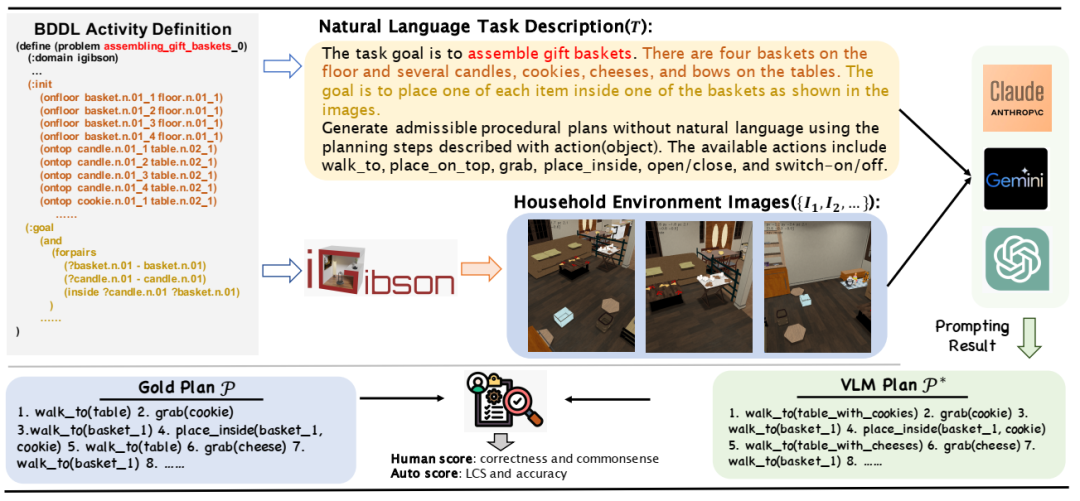
ActPlan-1K 数据集收集和评估概述。BDDL 活动定义被转换为自然语言描述。加载 BDDL 定义后,在模拟器中采样环境图像。在提示 VLM 后,VLM 计划通过人工评分和自动指标与黄金计划进行比较进行评估。

正常活动和反事实活动的示例。黄金计划因反事实情况而有所不同。
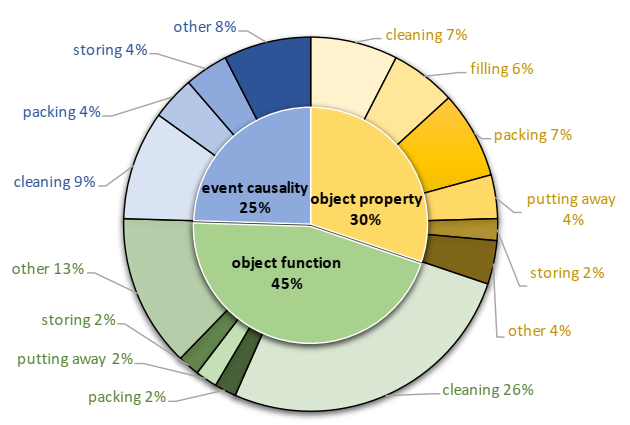
反事实活动的分布。







内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢