
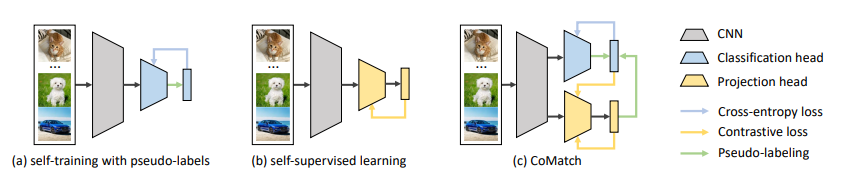
【论文标题】CoMatch: Semi-supervised Learning with Contrastive Graph Regularization 【作者团队】Junnan Li,Caiming Xiong,Steven C.H. Hoi 【发表时间】2020/11/23 【论文链接】https://arxiv.org/pdf/2011.11183.pdf
【推荐理由】 本文来自 Salesforce 研究院,作者针对目前基于自学习和自监督预训练的半监督学习方法存在的缺点,提出了一种同时利用分类概率和低维嵌入进行训练的半监督学习方法 CoMatch,有效地提升了稀疏图像数据集上的半监督分类性能。
半监督学习是一种有效利用无标签数据减少对数据标注的依赖的范式。当前主要有两个主流的半监督学习研究趋势:(1)使用分类器为每个无监督样本赋予训练所需的伪标签(2)首先进行无监督、自监督预训练,然后基于得到的表征进行有监督的调优和自学习。然而,自学习方法高度依赖于分类结果的质量,会引起确认偏差,积累预测误差。另一方面,对比学习等自监督学习方法则学习到的是针对特定分类任务的次优解。在本文中,作者提出了一种新的半监督学习方法 CoMatch,它是目前主流半监督方法的集大成者,并解决了它们的局限性。CoMatch 会同时学习训练数据的两种表征(分类概率和低维嵌入)。这两种表示相互作用,共同演进。嵌入会对分类概率施加一个平滑性约束来改进伪标签,而伪标签则通过基于图的对比学习来对嵌入的结构进行正则化。CoMatch 在多个数据集上取得了目前最先进的性能。在标签稀疏的 CIFAR-10 和 STL-10 数据集上,分类准确率提高了 20%。在包含 1% 的标签的 ImageNet 数据集上,CoMatch 的 Top-1 准确率达到了 66.0% ,比 FixMatch 方法高出 12.6%。通过自监督预训练,准确率进一步提高到 67.1%。此外,CoMatch 在下游任务上取得了更好的表征学习性能,其性能优于监督学习和自监督学习。
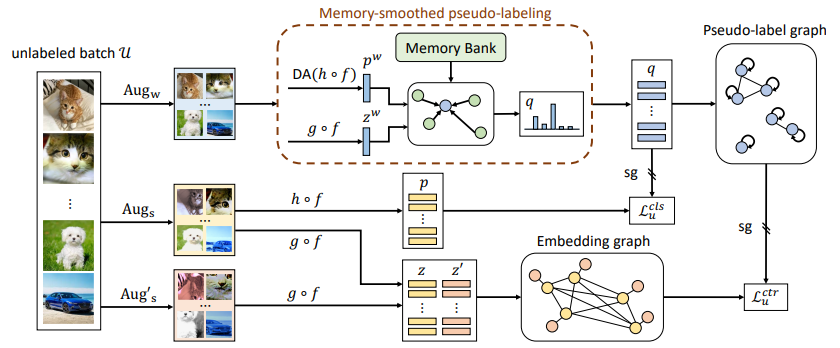
给定一批无标签图像,作者对它们进行较弱的数据增强,然后将增强后的图像用于生成记忆平滑后的伪标签。这些伪标签将被作为对应用了较强数据增强后的图像进行类别预测的目标标签。作者构建了一个带有自环的伪标签图,用来衡量样本之间的相似度,从而训练一个嵌入图,使得带有相似伪标签的图像拥有相似的嵌入。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢