上周五,DeepSeek 发推说本周将是开源周(OpenSourceWeek),并将连续开源五个软件库。就在刚刚,DeepSeek 第三天的开源项目 DeepGEMM 正式发布。DeepGEMM,一款支持密集型和专家混合(MoE)GEMM 的 FP8 GEMM 库,为 V3/R1 的训练和推理提供了支持。仅用 300 行代码,DeepGEMM 开源库就能在 Hopper GPU 上可以达到 1350+ FP8 TFLOPS 的计算性能,超越专家精心调优的矩阵计算内核,为 AI 训练和推理带来很大的性能提升。
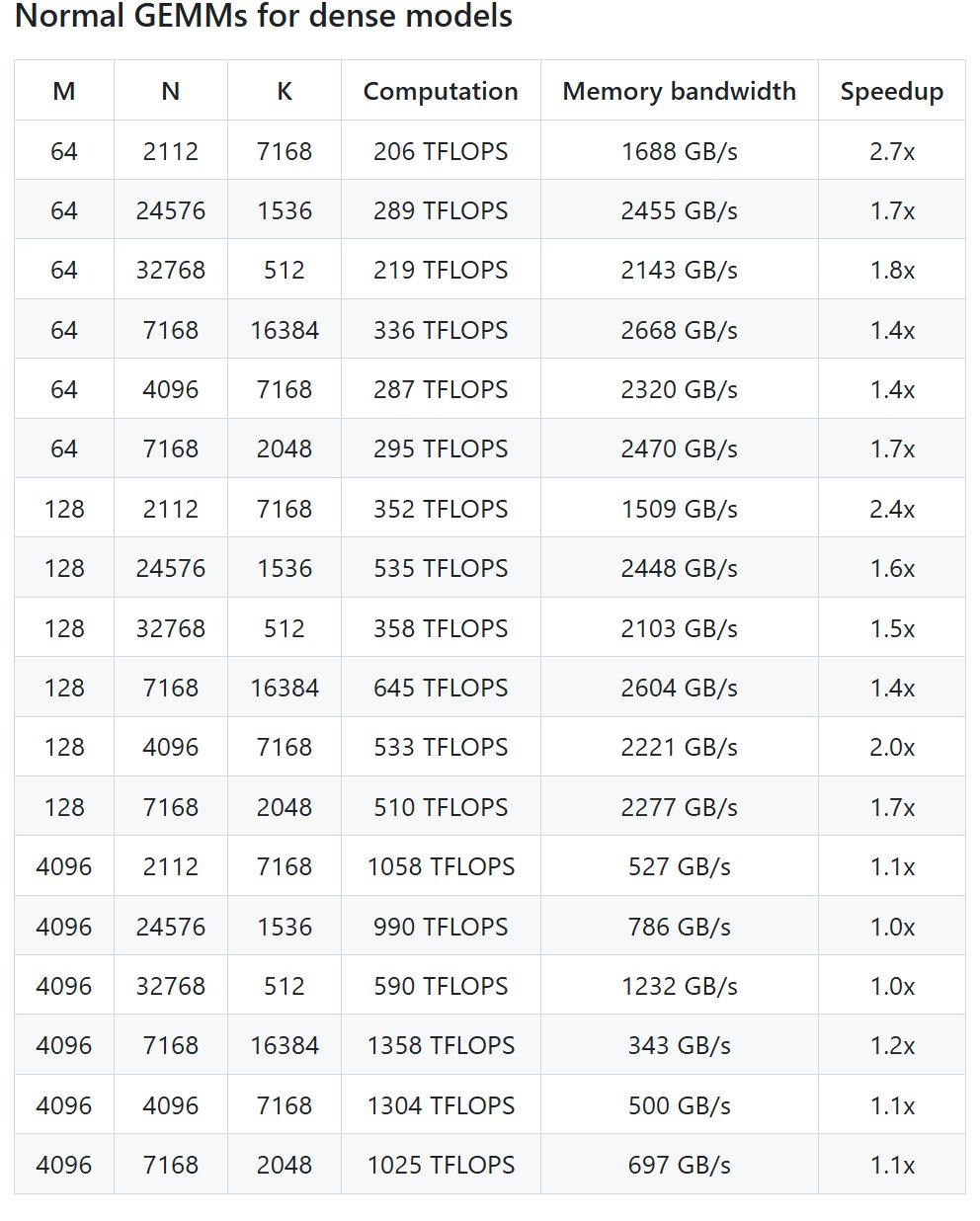
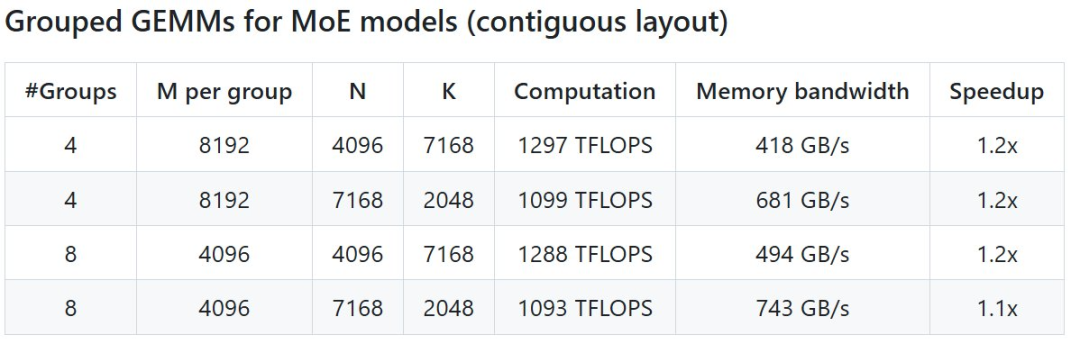
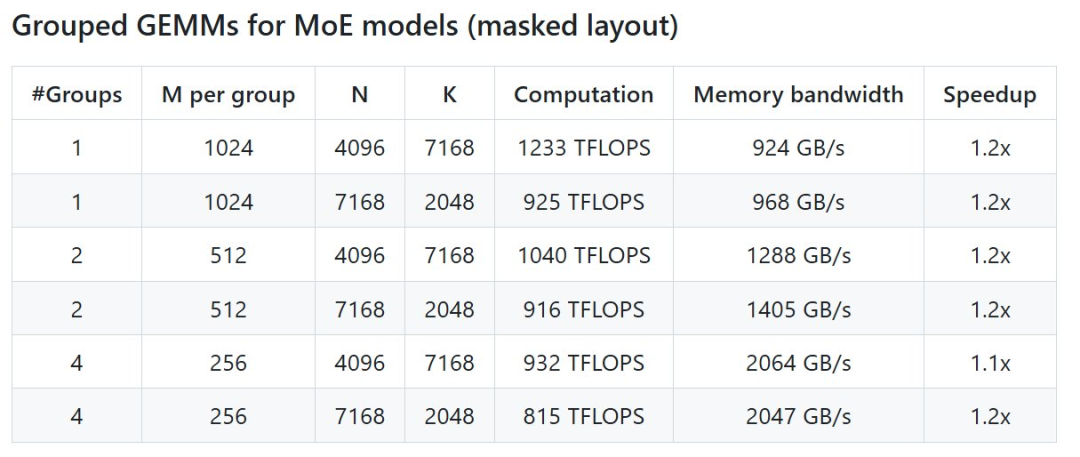
具体来说,DeepGEMM 是一个旨在实现简洁高效的 FP8 通用矩阵乘法(GEMM)的库,它采用了 DeepSeek-V3 中提出的细粒度 scaling 技术。该库支持普通 GEMM 以及专家混合(MoE)分组 GEMM。该库采用 CUDA 编写,在安装过程中无需编译,而是通过一个轻量级的 Just-In-Time(JIT)模块在运行时编译所有内核。目前,DeepGEMM 仅支持英伟达 Hopper 张量核心。为了解决 FP8 张量核心累加不精确的问题,它采用了 CUDA 核心的两级累加(提升)机制。尽管 DeepGEMM 借鉴了 CUTLASS 和 CuTe 的一些概念,但避免了过度依赖它们的模板或代数系统。相反,该库的设计注重简洁性,仅包含一个核心内核函数,代码量仅为 300 行。这使其成为学习 Hopper FP8 矩阵乘法和优化技术的理想入门资源。尽管采用轻量级设计,DeepGEMM在处理各种矩阵形状时的性能都能够达到甚至超越经专家调优的库。开源地址:https://github.com/deepseek-ai/DeepGEMMDeepSeek 在 H800 上使用 NVCC 12.8 测试了 DeepSeek-V3/R1 推理中可能使用的所有形状(包括预填充和解码,但不包括张量并行),最高可以实现 2.7 倍加速。所有加速指标均基于内部精心优化的 CUTLASS 3.6 实现。但根据项目介绍,DeepGEMM 在某些形状上表现不佳。- Hopper 架构的 GPU,必须支持 sm_90a;
- CUDA 12.3 或更高版本,但为了获得最佳性能,DeepSeek 强烈推荐使用 12.8 或更高版本;
- CUTLASS 3.6 或更高版本(可通过 Git 子模块克隆)。
# Submodule must be clonedgit clone --recursive git@github.com:deepseek-ai/DeepGEMM.git# Make symbolic links for third-party (CUTLASS and CuTe) include directoriespython setup.py develop# Test JIT compilationpython tests/test_jit.py# Test all GEMM implements (normal, contiguous-grouped and masked-grouped)python tests/test_core.py
最后在你的 Python 项目中导入 deep_gem,就可以使用了。路透社:DeepSeek R2 大模型又提前了,5 月之前发布就在 DeepSeek 紧锣密鼓地开源的同时,人们也在四处探寻该公司下一代大模型的信息。昨天晚上,路透社突然爆料说 DeepSeek 可能会在 5 月之前发布下一代 R2 模型,引发了关注。据多位知情人士透露,DeepSeek 正在加速推出 R1 强推理大模型的后续版本。其中有两人表示,DeepSeek 原本计划在 5 月初发布 R2,但现在希望尽早发布。DeepSeek 希望新模型拥有更强大的代码生成能力,并能够推理除英语以外的语言。或许下一次 DeepSeek 的发布,会是 AI 行业的又一次关键时刻。
https://x.com/deepseek_ai/status/1894553164235640933 一起“点赞”三连↓
一起“点赞”三连↓
内容中包含的图片若涉及版权问题,请及时与我们联系删除




评论
沙发等你来抢