


关键词:铰链物体操作 适应性机制 仿真模拟

导 读
本文是对发表于计算机人工智能领域顶级会议 ICLR 2025 的论文 AdaManip: Adaptive Articulated Object Manipulation Environments and Policy Learning 的解读。该论文由北京大学董豪课题组完成,共同第一作者为北京大学计算机学院博士生王远非、北京邮电大学硕士生张小杰和北京大学计算机学院博士生吴睿海。
本文首次提出了一个支持模拟适应性操作机制的铰链物体仿真环境 AdaManip,并为其配备了 9 类物体数据资产。基于该环境和数据集,本文进一步提出了适应性示范轨迹收集和基于 3D 视觉扩散模型策略的模仿学习管道,用于训练适应性操作策略。仿真和现实世界的实验验证了仿真环境和训练方法的有效性。AdaManip 对适应性机制模拟的支持,将推动铰链物体仿真向更加复杂和真实的场景发展,为研究人员提供一个更为强大的训练与测试平台。
论文链接:
https://arxiv.org/abs/2502.11124
项目主页:
https://adamanip.github.io/
01
研究动机
铰链物体是由多个通过关节连接的刚性部件构成的物体,部件之间复杂的相对运动使得铰链物体具备多种功能性机制。铰链物体在日常生活中非常常见,如橱柜、门和微波炉等,且其部件通常较为复杂,具有丰富多样的几何形状、语义、铰接方式和功能。因此,铰链物体的操作对于机器人在现实生活场景中的部署至关重要。
尽管已有一些研究(如 PartNet-Mobility[1])对铰链物体操作的仿真环境和策略学习进行了探索,这些工作主要集中在简单操作机制上,其中完整的操作过程可以通过物体的外观推断得出。例如,在之前的仿真环境中,保险柜不具备锁机制,柜门可以通过直接拉动把手打开。然而,在现实世界中,保险柜的门只有在锁被解锁时才能打开,而锁的状态或关节角度的约束无法通过视觉直接察觉。因此,成功操作这些物体需要依赖试错进行适应性调整,而不是单纯依赖一次性的视觉信息。UnidoorManip[2]拓展了门物体的复杂真实机制,但不涉及门以外的部件和机制。因此为了研究真实场景下的铰链物体操作,我们有必要构建一个支持模拟更多真实适应性机制的仿真环境。
针对铰链物体的这种适应性机制,机器人的操作策略必须具备两项核心能力:(1)多峰策略分布;(2)基于历史的适应性调整。首先,对于观察到的物体,操作策略可能包括多种模式和不同的操作轨迹。例如,当观察到门闭合的保险柜时(图1左下方),为了实现开门的目标,策略可能是直接拉门(当门已解锁时),或者先转动钥匙再拉门(当门已上锁时)。此外,为了从多峰策略分布中选择正确的动作,有必要根据历史操作结果调整策略。例如,当拉门没有任何反应时,适应性策略应该从多峰策略分布(拉门或转动钥匙)调整为单峰策略(转动钥匙)(图1右下方)。
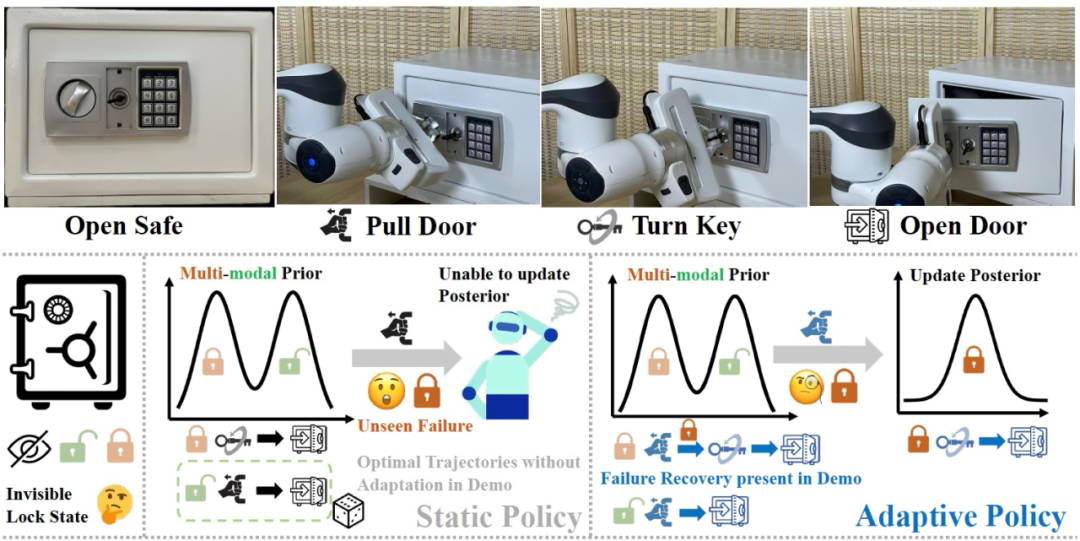
图1. 保险柜的例子。由于锁状态无法从外观获知,机器人初始的策略为多峰分布,对应两种不同的操作轨迹。由于静态策略的训练数据中不存在错误调整示例,其在失败尝试后无法恢复。相反,适应性策略训练数据包括错误调整,因此可以根据环境反馈将初始多峰先验分布调整为单峰后验分布。
为研究更为真实的适应性铰链物体机制及其策略训练,我们构建了一个能够模拟上述复杂机制的铰链物体操作环境,并为其配备了 9 类不同的物体,涵盖5种适应性机制。同时,我们还提出了适应性示范轨迹收集方法,并结合基于 3D 视觉的扩散模型策略,提出了一种模仿学习管道,用于训练适应性操作策略。
02
适应性操作机制仿真模拟
大多数现有的铰链物体环境主要关注不同类别物体之间的几何多样性。虽然这些物体可能包含多个部件,但操作其中一个部件通常不会影响其他部件的状态或关节限制,从而导致过度简化的操作机制。在这些环境中,常见的操作包括推动或拉动某个部件,比如打开抽屉或按下按钮,这些操作通常可以通过视觉观察直接推断。然而,现实中的操作往往依赖于内部关节状态,而这些状态是外部不可见的,因此需要基于反馈的适应性操作策略。为了更好地模拟现实世界中的铰链物体操作及其相应的机制,我们确定了 5 种增强环境真实性的适应性机制,以及对应的 9 种物体:瓶子、笔、咖啡机、窗、高压锅、台灯、门、保险柜、微波炉。
锁机制:在日常物品中,例如门或保险箱,锁机制要求执行解锁动作,如转动钥匙、旋钮,或按下按钮以解锁物体,然后才能打开。此机制跟踪关键部件的关节状态,并相应地更新锁的状态。如果锁状态变为“解锁”,则门的关节限制解除,允许打开;否则,门仍然保持锁定状态。由于锁的状态无法通过视觉推断,机器人必须与物体交互,以确定锁的状态并调整策略。
随机旋转方向:当旋转旋钮、盖子或把手时,旋转方向(即顺时针或逆时针)由内部转动关节限制决定。我们的环境在初始化时随机分配旋转方向,防止通过视觉直接推断旋转方向。机器人必须尝试一个方向,如果不成功,则需要切换到另一个方向。
旋转与滑动机制:该机制要求部件在被提升或拉出之前,先旋转到特定角度,例如打开高压锅的盖子。由于所需的旋转角度无法通过视觉识别,机器人需要逐步旋转部件并尝试滑动,以确定是否已达到正确的角度。我们随机化转动关节的限制,并将滑动关节的初始限制设为零,一旦达到正确的角度,就解除限制。
推动/旋转机制:由于按钮和旋钮的外观相似,无法明确判断某个部件应该被推动还是旋转。例如,某些情况下,按下按钮可能会打开灯,而另一些情况下,旋转旋钮则会打开灯。我们的环境为同一部件的 URDF 文件中包含了转动关节和滑动关节,并随机决定部件应该是推动还是旋转,根据需要调整关节限制。
操作点切换机制:基于锁机制,这要求机器人操作不同的关键部件,如把手和旋钮。例如,在一个保险箱中,由于锁状态的模糊性,机器人必须在操作过程中切换部件,这使得机器人无法一开始就确定接触点的顺序。
图2 和图3 中可视化展现了我们基于 Isaac Gym 构建的仿真环境和 9 类物体。从表1 的对比中可知,本文提出的 AdaManip 环境相比以往工作提出的仿真环境具备更为真实复杂的适应性机制。

图2. 基于 Isaac Gym 的仿真环境,包含 9 类物体
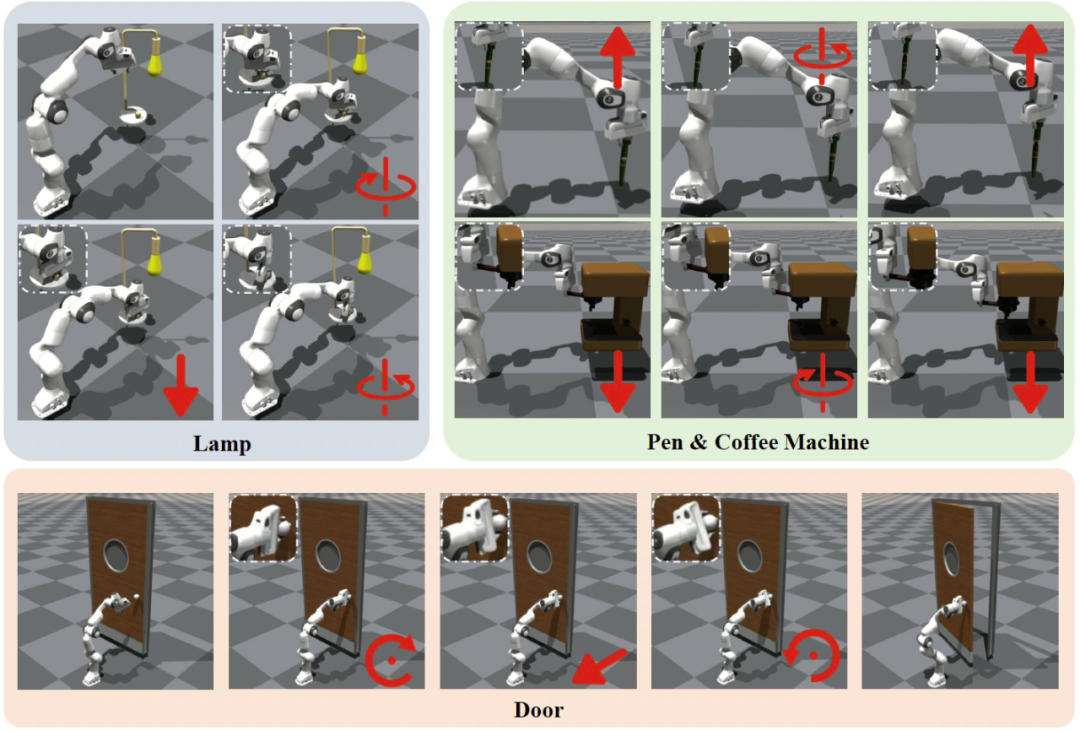
图3. 仿真环境中物体的适应性机制

表1. AdaManip 相比其他仿真环境具备更多复杂真实的适应性机制
03
适应性操作轨迹收集与策略训练
本文提出了一个新框架,通过收集适应性示范轨迹学习不同机制的适应性操作策略,如图4 所示。我们利用数据集中的部件姿态标注,在环境中生成专家操作轨迹,同时考虑不可见的内部状态,以确保这些轨迹具有适应性。我们的目标是在部分观测的情况下生成最优的适应性示范。例如,在打开微波炉时,专家适应性策略首先拉动把手检查锁状态。如果插销被锁住,策略将按下按钮而后开门;如果插销未锁住,策略将继续拉动把手以打开门。相比之下,具有完全观察的静态策略则能提前知道锁的状态,可以直接打开门或按下按钮,而不需要先尝试拉动把手。
接下来,为了高效建模专家轨迹的多峰分布,我们采用基于 3D 视觉扩散模型的模仿学习,该方法通过学习动作评分函数的梯度来生成动作。得到的适应性策略可以根据历史信息动态调整策略分布。
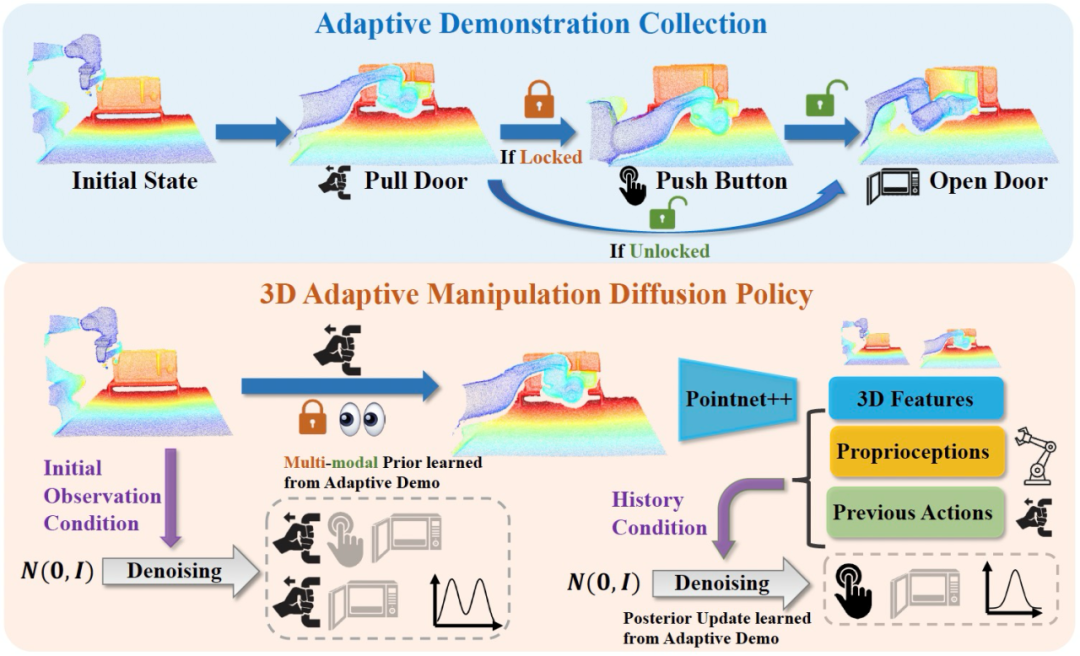
图4. 适应性操作轨迹收集与基于 3D 视觉的适应性扩散模型策略
04
实验结果
我们首先在仿真环境中对比 AdaManip 和几种先进方法。具体而言,我们选择了基于 affordance 的方法 VAT-MART[3]和其适应性版本 AdaAfford[4]、使用动作分块的模仿学习算法 ACT[5],以及基于 3D 视觉的扩散模型策略 DP3[6]。此外,我们还进行了消融实验,ours w/o adaptive 将适应性示范轨迹数据替换为在完全观察下最优的静态示范数据。实验结果表明,本文提出的框架相比基线方法和消融方法均有显著优势。
我们进一步现实场景中验证 AdaManip 的表现。我们在 4 种真实物体:高压锅、微波炉、瓶子和保险箱上进行了实验,策略的可视化结果如下。




05
总 结
本文首次提出了一个具有复杂适应性操作机制的铰链物体仿真环境与数据集,并提出了一个新框架,通过扩散模型策略从多样的适应性示范中学习适应性操作策略。仿真与真实环境中的实验结果验证了我们所提出的环境及适应性策略学习框架的有效性。
本文是关于铰链物体适应性操作策略的初步研究。目前,我们的数据集涵盖了 9 个类别,共 277 个物体,未来我们计划引入更多类别和实例,以扩展数据集并涵盖更加复杂和现实的操作机制。未来,AdaManip 环境将逐步增加更多现实中的适应性操作任务,为相关研究人员提供更为全面的训练和测试平台。
参考文献:
[1] Kaichun Mo, Shilin Zhu, Angel X. Chang, Li Yi, Subarna Tripathi, Leonidas J. Guibas, and Hao Su. PartNet: A large-scale benchmark for fine-grained and hierarchical part-level 3D object understanding. CVPR 2019.
[2] Yu Li, Xiaojie Zhang, Ruihai Wu, Zilong Zhang, Yiran Geng, Hao Dong, and Zhaofeng He. Unidoormanip: Learning universal door manipulation policy over large-scale and diverse door manipulation environments. arXiv preprint arXiv:2403.02604, 2024b.
[3] Ruihai Wu, Yan Zhao, Kaichun Mo, Zizheng Guo, Yian Wang, Tianhao Wu, Qingnan Fan, Xuelin Chen, Leonidas Guibas, and Hao Dong. VAT-mart: Learning visual action trajectory proposals for manipulating 3d ARTiculated objects. ICLR 2022.
[4] Yian Wang, Ruihai Wu, Kaichun Mo, Jiaqi Ke, Qingnan Fan, Leonidas Guibas, and Hao Dong. Adaafford: Learning to adapt manipulation affordance for 3d articulated objects via few-shot interactions. ECCV 2022.
[5] Tony Z Zhao, Vikash Kumar, Sergey Levine, and Chelsea Finn. Learning fine-grained bimanual manipulation with low-cost hardware. RSS 2023.
[6] Yanjie Ze, Gu Zhang, Kangning Zhang, Chenyuan Hu, Muhan Wang, and Huazhe Xu. 3d diffusion policy. RSS 2024.
PKU-Agibot Lab
PKU-Agibot Lab 由北京大学前沿计算研究中心董豪助理教授领导,该科研团队专注于机器人视觉,物体操作,语义导航和具身自主决策等领域的前沿技术,致力于为工业应用和家用场景创建具有成本效益的人形机器人。
实验室 PI 简介:董豪 助理教授

扫码浏览实验室主页
https://zsdonghao.github.io/

图文 | 王远非
PKU-Agibot Lab
PKU-Agibot Lab 近期科研动态


— 版权声明 —
本微信公众号所有内容,由北京大学前沿计算研究中心微信自身创作、收集的文字、图片和音视频资料,版权属北京大学前沿计算研究中心微信所有;从公开渠道收集、整理及授权转载的文字、图片和音视频资料,版权属原作者。本公众号内容原作者如不愿意在本号刊登内容,请及时通知本号,予以删除。

点击“阅读原文”转论文链接
内容中包含的图片若涉及版权问题,请及时与我们联系删除


评论
沙发等你来抢