

新智元报道
新智元报道
【新智元导读】DeepSeek公开推理系统架构,成本利润率可达545%!明天还有更大惊喜吗?
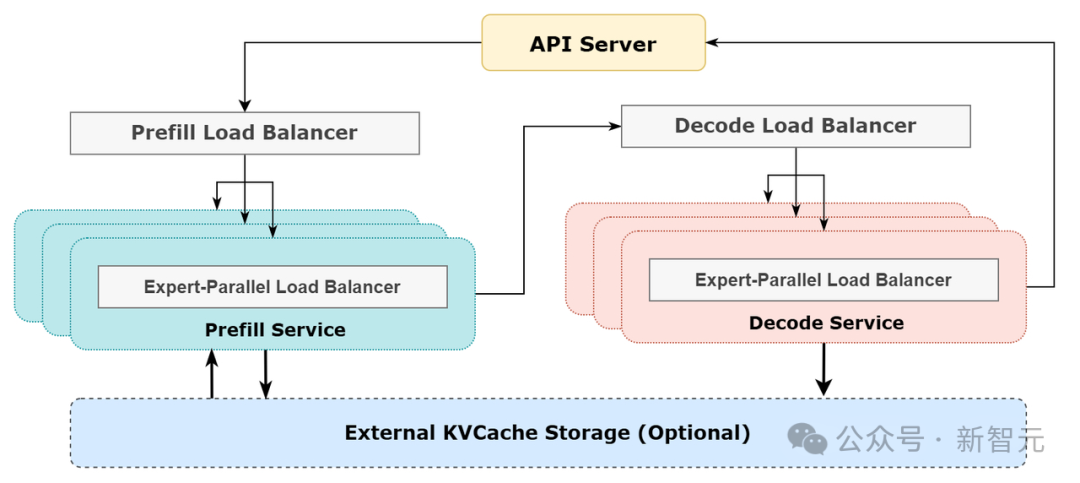
跨节点高效并行(EP)驱动的批处理扩展
计算与通信并行处理
智能负载均衡
每个H800节点每秒处理73,700/14,800输入/输出token 成本利润率高达545%
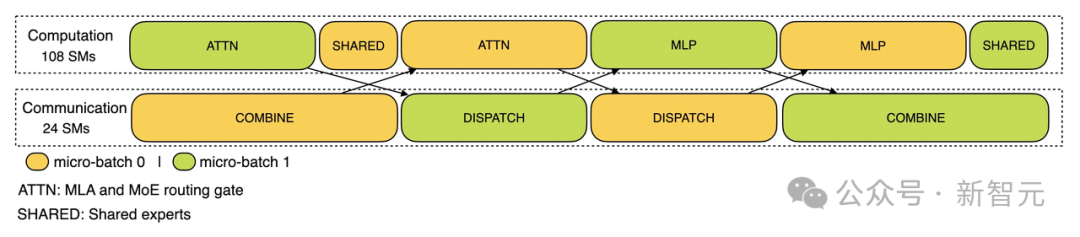
系统设计原则
EP引入了跨节点通信。为了优化吞吐量,需要设计合理的计算工作流,使通信过程与计算过程能够并行进行。
EP涉及多个节点,因此必然需要数据并行(Data Parallelism,DP),并要求在不同DP实例之间进行负载均衡。
利用EP技术扩展批处理规模 将通信延迟与计算过程重叠处理 实现有效的负载均衡
大规模跨节点专家并行(EP)
预填充阶段「路由专家EP32,MLA/共享专家DP32」:每个部署单元跨越4个节点,配置32个冗余路由专家,每个GPU负责处理9个路由专家和1个共享专家。
解码阶段「路由专家EP144,MLA/共享专家DP144」:每个部署单元跨越18个节点,配置32个冗余路由专家,每个GPU管理2个路由专家和1个共享专家。
计算-通信重叠处理
在预填充阶段,两个microbatch交替执行,一个microbatch的通信开销被另一个microbatch的计算过程所掩盖。
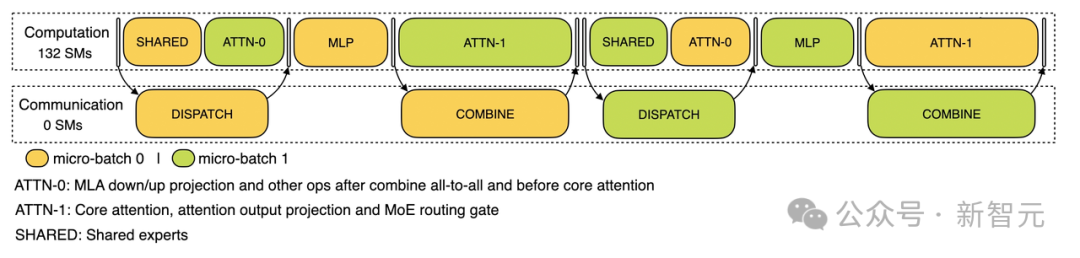
实现最优负载均衡
关键问题:不同数据并行实例之间的请求数量和序列长度差异导致核心注意力计算和分发发送负载不平衡。
优化目标: 平衡各GPU之间的核心注意力计算(核心注意力计算负载均衡); 均衡每个GPU处理的输入token数量(分发发送负载均衡),避免特定GPU出现处理延迟。
关键问题:数据并行实例之间请求数量和序列长度不均导致核心注意力计算(与KV缓存使用相关)和分发发送负载的差异。
优化目标: 平衡各GPU之间的KV缓存(KVCache)使用(核心注意力计算负载均衡); 均衡每个GPU的请求处理数量(分发发送负载均衡)。
关键问题:在混合专家模型(Mixture of Experts,MoE)中,存在天然的高负载专家,导致不同GPU上的专家计算工作负载不平衡。
优化目标: 平衡每个GPU上的专家计算工作量(即最小化所有GPU中的最大分发接收负载)。
DeepSeek在线推理系统图示
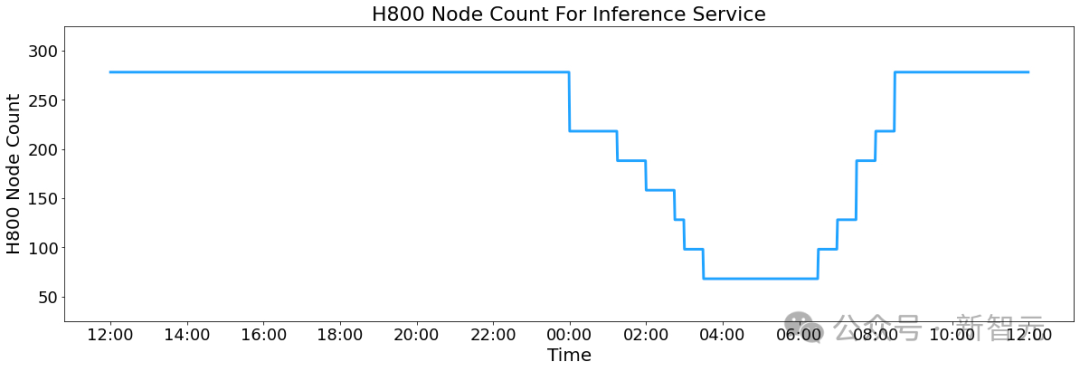
DeepSeek在线服务统计数据
在白天高峰时段,所有节点都部署推理服务; 在夜间低负载时段,减少推理节点并将资源分配给研究和训练。
总输入token:6080亿,其中3420亿token(56.3%)命中磁盘上的KV缓存。 总输出token:1680亿。平均输出速度为每秒20-22个token,每个输出token的平均KV缓存长度为4,989个token。 每个H800节点在预填充阶段提供平均约7.37万token/秒的输入吞吐量(包括缓存命中),或在解码阶段提供约1.48万token/秒的输出吞吐量。
R1定价:输入token(缓存命中)每百万0.14美元,输入token(缓存未命中)每百万0.55美元,输出token每百万2.19美元。
DeepSeek-V3的定价显著低于R1 只有部分服务实现了商业化(网页和APP访问仍然免费) 在非高峰时段自动应用夜间折扣



内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢