


AI Generations: From AI 1.0 to AI 4.0
https://arxiv.org/abs/2502.11312
1 引言
人类的创造力和创新力推动了科学和医学基础研究的进步。然而,研究人员,特别是在生物医学领域,面临着广度与深度的双重难题。生物医学主题的复杂性要求越来越深入和专业的主题知识,而洞察力的飞跃可能仍然源于跨越学科的广泛知识。随着科学出版物迅速增长以及许多专门高通量检测技术的可用性,掌握学科深度和跨学科洞察力可能具有挑战性。
尽管存在这些挑战,许多现代突破都源自跨学科努力。埃玛纽埃勒·沙尔庞捷和詹妮弗·杜德纳因其在CRISPR方面的工作而荣获2020年诺贝尔化学奖,该研究结合了从微生物学到遗传学再到分子生物学的一系列技术和策略。协同效应的益处也体现在实验性生物医学之外的众多科学领域。值得注意的是,杰弗里·辛顿和约翰·霍普菲尔德将物理学和神经科学的想法结合起来[2,3],开发了人工智能(AI)系统,该系统荣获了2024年诺贝尔物理学奖。
在人工智能方面,技术进展迅速,朝着普遍智能和协作系统发展。

这可能会赋予科学家创造性地跨越学科领域并进行专业推理的能力。这样的系统具备高级推理[4-6]、多模态理解[6]以及代理行为[7],例如使用工具解决长期时间跨度的复杂任务的能力。此外,关于蒸馏[8]和推理时间计算成本[6, 9]的趋势表明,这种智能且通用的AI系统正迅速变得更加经济实惠和易于获取。受到现代科学和医学发现过程中未满足需求的启发,并基于前沿AI的进步[10],我们开发并引入了一个AI合作科学家系统。
该合作科学家旨在作为科学家们的有益助手和合作者,帮助加速科学发现过程。该系统是基于Gemini 2.0构建的一个复合多代理AI系统[11],旨在反映支撑科学方法的推理过程[12]。给定一个用自然语言指定的研究目标,系统可以搜索并推理相关文献,总结和综合先前的工作,并在此基础上提出新颖、原创的研究假设和实验方案,以供下游验证(图1a)。合作科学家通过引用相关文献和解释其建议背后的推理,为其建议提供依据。
该工作并非旨在用人工智能完全自动化科学过程。相反,合作科学家是专门为“人在回路中”的协作模式而构建的,以帮助领域专家增强他们的假设生成过程,并指导随后的探索。科学家可以用简单的自然语言指定他们的研究目标,包括告知系统它应创建假设或研究提案的理想属性以及合成输出应满足的限制条件。他们还可以通过多种方式进行协作和提供反馈,包括直接提供自己的想法和假设、完善系统生成的那些想法、或者使用自然语言聊天来引导系统,确保与他们的专业知识保持一致。
合作科学家通过显著扩展测试时计算范式[13-15],在收集更多知识和理解的同时,迭代地推理、进化和改进输出。系统的支撑在于思考和推理步骤——特别是基于自我对弈的科学辩论步骤,用于生成新的研究假设;通过寻找胜负模式的过程比较和排名假设的比赛,以及改进它们质量的假设进化过程。最终,该系统的代理特性使其能够递归地自我批判其输出,并使用网络搜索等工具来获取反馈,以迭代地完善其假设和研究提案。
虽然合作科学家系统是通用的,适用于多个科学领域,但在本研究中,我们将该系统的开发和验证集中在生物医学上。我们验证了合作科学家在生物医学三个具有不同复杂性的重要领域的能力:(1) 药物再利用,(2) 发现新的治疗靶点,以及 (3) 对抗菌耐药性的新机制解释(图1b)。
药物开发是一个日益耗时且昂贵的过程[16],其中新疗法需要针对每个适应症或疾病重新开始许多发现和开发流程的方面(大约70%的药物批准用于新药)。相比之下,药物再利用——识别超出原始预期用途的药物的新治疗适应症——已成为应对这些挑战的一个引人注目的策略[17]。成功的再利用例子包括Humira(阿达木单抗)和Keytruda(帕博利珠单抗),这两者都已成为历史上最成功的药物之一[17]。该过程通常涉及分析分子特征、信号通路、药物相互作用、临床试验结果、不良事件报告以及其他基于文献的信息[18],以及标签外使用数据和某些情况下的患者体验。然而,药物再利用受限于几个因素:(1) 需要跨生物医学、分子生物学和生化系统的广泛专业知识;(2) 哺乳动物生物系统的固有复杂性;以及(3) 所需传统计算生物学分析的时间密集性。我们利用合作科学家来生成大规模药物再利用的预测,并使用计算生物学、专家临床医生反馈和体外湿实验室验证方法组合来验证生成的预测。值得注意的是,我们的系统提出了用于急性髓性白血病(AML)的新再利用候选物,这些候选物在体外多个AML细胞系中,以临床相关浓度抑制肿瘤活力。
与药物再利用不同,后者是通过一个庞大但受限的药物和疾病组合进行搜索问题,为疾病识别新的治疗靶点呈现出更大的挑战,传统上需要广泛的文献回顾、深入的生物学理解、复杂的假设生成以及复杂的实验验证策略。识别新治疗靶点的不确定性显著大于药物再利用,因为它不仅涉及再利用现有化合物,还涉及揭示生物系统内完全新的成分和机制。这一靶点发现过程可能效率低下,可能导致体外和体内实验选择次优假设并优先考虑。鉴于实验验证的高成本和耗时,我们需要一种更有效的方法。我们探究合作科学家的能力,让其针对目标发现提出、排序和提供新的研究假设的实验方案。为了展示这种能力,我们关注一种普遍且严重的疾病——肝纤维化,展示合作科学家发现适合实验验证的新治疗目标的潜力。特别是,合作科学家建议了一些新型表观遗传靶点,在人类肝类器官中显示出显著的抗纤维化活性。
作为我们系统能力的第三次验证,我们专注于生成假设来解释与细菌基因转移进化相关的机制,这些机制与微生物为规避用于抗击感染的药物应用而开发的抗微生物耐药性(AMR)机制有关。这可以说是一个比药物再利用和目标发现更为复杂的挑战,涉及到的不仅是基因转移(共轭、转导和转化)的分子机制,还有推动AMR基因传播的生态学和进化压力:这是一个涉及许多相互作用的变量的系统级问题。这也是一个重要的医疗保健挑战,因为全球感染率和死亡率都在上升[19]。在这次验证中,研究人员指导AI合作科学家探索一个已经被他们独立研究小组发现新现象的主题。值得注意的是,在指导人工智能合作科学家的系统时,研究人员的新颖实验见解尚未在公共领域发表或披露。该系统被指令假设衣壳形成性噬菌体诱导的染色体岛(cf-PICIs)如何在多种细菌物种中存在。该系统独立提出cf-PICIs与多样的噬菌体尾部相互作用以扩展它们的宿主范围。这一计算机模拟的发现反映了专家研究人员已经进行的新颖且经过实验验证的结果,正如同步发表的报告[20, 21]中详细说明的那样。
总体而言,我们的主要贡献总结如下:
引入人工智能合作科学家。我们开发并引入了一种超越文献总结和“深度研究”工具的人工智能合作科学家,以协助科学家发现新知识、生成新颖假设以及规划实验。
科学推理测试时间计算范式的显著扩展。合作科学家基于Gemini 2.0多代理架构构建,采用异步任务执行框架。该框架允许系统灵活地为科学推理分配计算资源,反映了科学方法的关键方面。具体来说,系统采用自我对弈策略,包括科学辩论和基于比赛的进化过程,以迭代精炼假设和研究提案,形成一个自我改进的循环。通过在15个复杂且由专家策划的开放科学目标上使用自动化评估,我们展示了扩展测试时计算范式的优势,其中人工智能合作科学家在生成复杂问题的优质假设方面超越了其他最先进的代理和推理模型。
专家参与的科学工作流程。我们的系统设计用于与科学家合作。系统可以灵活地纳入来自科学家的自然语言对话反馈,并共同开发、进化和完善输出。
对生物医学重要主题中合作科学家的端到端验证。我们通过在三个不同且日益复杂的生物医学领域的新颖实证发现,展示了新颖人工智能生成假设的端到端验证:药物再利用、新靶点发现和抗药性。人工智能合作科学家预测了急性髓性白血病的新再利用药物,识别了基于肝纤维化临床前证据的新表观遗传治疗靶点,并提出了细菌进化和抗药性中基因传递的新机制。这些由人工智能合作科学家的发现已在实验室环境中得到验证,并在同时发表的技术报告中详细说明。
2 相关工作
2.1 推理模型和测试时计算扩展
现代基础AI模型[22]和大型语言模型(LLMs)的革命主要是由预训练技术的进步[23, 24]所驱动,这导致了像GPT和Gemini系列[25, 26]这样的模型的突破。这些在日益庞大、互联网规模的多模态数据集上训练的模型,在语言理解和生成方面展现了令人印象深刻的能力,从而在各种基准测试中取得了突破性的表现[27, 28]。然而,当前发展的一个关键领域是增强它们的推理能力。这导致了“推理模型”的出现,它们不仅仅是预测下一个单词,而是试图模仿人类的思维过程[29]。在这一追求中,一个有前途的方向是测试时计算范式。这种方法超越了仅依赖预训练期间获得的知识,并在推理过程中分配额外的计算资源,以实现系统2式的慢节奏、深思熟虑的推理,以减少不确定性,并朝着目标最优地前进[30]。这个概念随着早期的成功而出现,如使用蒙特卡洛树搜索(MCTS)探索游戏状态并策略性选择走法的AlphaGo[15],以及采用类似技术在扑克中实现超人类表现的Libratus[14]。这一范式现在已应用于大型语言模型(LLMs),其中测试时增加的计算得以更彻底地探索可能的响应,从而提高了推理和准确性[11, 13, 29, 31-34]。最近的进展,如Deepseek-R1模型[4],通过利用强化学习来精炼模型的“思维链”并在更长的时间范围内增强复杂推理能力,进一步展示了测试时计算的潜力。在本项工作中,我们提出了一种重要的测试时计算范式的扩展,使用源自科学方法的归纳偏见来设计一个多智能体框架,用于科学推理和假设生成,而无需任何额外的学习技术。
2.2 人工智能驱动的科学发现
人工智能驱动的科学发现代表了在各个科学领域进行研究方式的一种范式转变。最近的进展,特别是大型深度学习和生成模型的发展,巩固了人工智能在科学发现中的作用。这在AlphaFold 2在蛋白质结构预测的重大挑战中取得的显著进步中得到了最佳体现,这彻底改变了结构生物学,并为药物发现和材料科学开辟了新的途径[35]。其他值得注意的例子包括利用人工智能开发新型抗生素、蛋白质结合剂设计和材料发现[36-38]。
在这些成功的基础上,通过专门定制的AI模型,最近的研究探索了更为雄心勃勃的目标,即将人工智能(尤其是基于现代大型语言模型的系统)完全整合到完整的研究工作流程中,从最初的假设生成一直到稿件撰写。这种端到端的整合代表了一个重大转变,随着该领域从专门的AI工具向实现人工智能作为积极合作者甚至一些人所设想的“AI科学家”的潜力迈进,既带来了前所未有的机遇,也带来了重大的挑战[39]。
作为这种转变的一个例子,梁等人。[40] 直接评估了大型语言模型(LLMs)在提供研究稿件反馈方面的效用。通过回顾性分析现有的同行评审和前瞻性用户研究,他们证明了LLM生成的反馈与人类审稿人的反馈之间存在显著的一致性。他们的研究使用了GPT-4[41],发现大多数研究人员认为LLM生成的反馈有帮助,在某些情况下甚至比来自人类同事的反馈更有益。然而,尽管很有价值,但他们的研究仅关注科学过程的反馈阶段,留下了关于如何将LLMs整合到完整的研究周期中的问题,从假设形成到实验验证以及稿件撰写。
体现这一转变的另一个努力是PaperQA2[42],一种用于科学文献搜索和总结的AI代理。作者声称在多项文献研究任务上超越了博士和博士后研究人员,这些任务的衡量标准既包括客观基准测试的表现,也包括人类评估。虽然该系统对于综合信息很有用,但它并不参与针对新假设生成的科学推理。
周等人提出的HypoGeniC系统[43],通过使用大型语言模型和多臂老虎机启发式方法迭代精炼假设来解决假设生成问题。该过程从一个小型示例集开始,从中生成初始假设。然后通过探索和利用迭代更新这些假设,以基于训练准确率的奖励函数为指导。这套精细的假设随后被用来构建一个可解释的分类器。然而,该方法依赖于回顾性数据进行评估,这意味着系统能够生成真正新颖假设的程度仍是一个悬而未决的问题。此外,系统缺乏超出主观人类评估的端到端验证。
伊法甘等人(Ifargan et al.)提出了一个名为“数据到论文”的平台,该平台系统地指导多个大型语言模型和基于规则的代理生成研究论文,并配备自动反馈机制和用于验证的信息追踪。然而,这些评估仅限于复现现有的同行评审出版物,且不清楚该系统是否能生成真正新颖、但基于事实的假设和研究提案。
虚拟实验室(Virtual Lab)是另一项密切相关的工作。在这里,作者提出了一个由“首席调查员”大型语言模型指导的专业大型语言模型代理团队来解决科学问题的方案。大型语言模型团队接受高级人类监督。作者通过利用虚拟实验室设计针对SARS-CoV-2最近变种的纳米抗体结合剂,并通过实验验证展示了他们工作的实用性。虽然精神类似,但在设计上与我们的方法存在显著差异,系统的普遍性仍然不明确。
最后,陆等人(Lu et al.)提出了“AI科学家”,这是一个完全自动化的系统,旨在使用多个协作的大型语言模型代理进行研究。这些代理人负责研究过程的所有阶段,从定义研究问题和进行文献综述到设计并执行实验,甚至撰写结果。该设计与我们的工作有相似之处——主要区别在于我们专注于扩展测试时间计算范式,以生成高质量的假设和研究提案。其次,他们提出的系统自动化评估有限;相比之下,我们的工作结合了自动化、人类专家和端到端的湿实验室验证。最后,我们的目标不是自动化科学发现,而是构建一个对科学家有帮助的人工智能合作者。
2.3 人工智能在生物医学领域的应用
更广泛地说,大型人工智能模型在生物医学科学中日益显示出其潜力。通用型(GPT-4、Gemini)和专用的大型语言模型(Med-PaLM、Med-Gemini、Galactica、Tx-LLM)在生物医学推理和问答基准测试上表现出色[25, 26, 46-49]。不仅在基准测试上,Med-PaLM 2还被成功应用于识别导致小鼠糖尿病、白内障和听力损失等特征的因果遗传因素[50]——这是假设生成和LLM辅助发现的早期例子。我们还看到了在DNA、RNA和蛋白质序列上训练的专用基础模型和大型语言模型的令人兴奋的发展,这些模型具有多种应用[51-54]。尽管生物学和医学中的人工智能经常需要专业化,但前沿AI模型的快速发展模糊了这一界限。随着这些模型在规模、数据多样性和复杂性方面的增长,它们继续在曾被认为需要特定领域人工智能的领域实现突破。我们的合作科学家系统采用模块化多智能体架构,设计灵活,能够基于这些通用前沿人工智能模型的进展进行构建,并利用专门的AI模型作为工具来增强能力。
药物再利用是此项工作中的一个重要验证实验领域。传统方法要求结合计算和实验方法以及对疾病-药物相互作用的全面了解[17, 55]。虽然像知识图谱与图卷积网络这样的方法已显示出潜力[56, 57],但其适用性受限于初始知识图谱的范围。TxGNN[58]是一个采用基于图的方法的专门生物医学基础模型的例子,它解决了针对新疾病的“零样本”再利用问题,但仍依赖于底层知识图谱的质量,并且缺乏足够的可扩展性和可解释性。此外,该研究中没有报告对模型预测的端到端验证。相比之下,我们的工作利用最先进的LLM在合作科学家设置中,更具可扩展性。我们结合专家评估和实验室实验来验证系统预测。
3 介绍AI合作科学家
本节描述了构成合作科学家系统的技术细节、智能体和框架。合作科学家采用基于Gemini 2的多智能体架构。0,集成在异步任务执行框架内。该框架允许灵活地扩展测试时计算资源,促进高级科学推理。
根据自然语言领域专家科学家指定的研究目标,合作科学家生成符合以下默认标准的假设和研究提案:
与所提供的研究目标一致。生成的输出必须精确符合科学家定义的研究目标、偏好和限制。
合理性。系统输出应无明显的缺陷。任何与先前文献或既定知识可能存在的矛盾都必须明确陈述并加以解释。
新颖性。合作科学家系统的关键目标是生成基于先前文献的新颖假设、猜想和研究计划,而不仅仅是综合现有信息(这一能力已被现有的“深度研究”工具[59]所涵盖)。
可测试性。系统输出应在科学家指定的限制条件下,能够进行实证验证。
安全性。系统输出将受到控制,以防止启用不安全、不道德或有害的研究。
除了这些默认标准外,合作科学家可以根据需要配置额外的标准、偏好和限制。例如,它可以被配置为按照研究者偏好的格式生成输出,以提高可解释性和可读性。
在本节中,我们使用一个重复出现的例子:生成假设以探究肌萎缩侧索硬化症(ALS)的生物机制,以此来阐述合作科学家系统的各个组成部分。虽然这个例子已经由领域专家审阅过,但它仍然是说明性的,并可能包含错误。重要的是,这个例子并不旨在提出ALS的潜在治疗途径,应当极其谨慎地解读。所有例子都列在附录A.1节中。
3.1 人工智能合作科学家系统概述
在高层次上,合作科学家系统包括四个关键组成部分:
自然语言界面。科学家主要通过自然语言与系统互动和监督。这使他们不仅能够定义最初的研究目标,而且随时可以对其进行完善,对生成的假设(包括他们自己的解决方案)提供反馈,并总体上指导系统的进展。
异步任务框架。合作科学家使用一个多代理系统,其中专门的代理作为工作进程在一个异步的、持续的、可配置的任务执行框架内运行。一个专用的监督代理管理工作任务队列,分配专门代理给这些进程,并分配资源。这种设计使系统能够灵活有效地利用计算资源,并迭代提升其科学推理能力。
专门代理。根据科学方法得出的归纳偏见和科学先验,科学推理和假设生成的过程被分解成子任务。每个个体、专门的代理都配备了定制的指令提示,被设计来执行这些子任务。这些代理作为由监督代理协调的工人进行操作。
上下文记忆。为了使迭代计算和长期时间范围的科学推理成为可能,合作科学家使用持久的上下文记忆来存储和检索计算过程中代理和系统的状态。
双子座2.0模型是支撑合作科学家系统中所有代理的基础大型语言模型。特定的合作科学家设计是通过迭代开发得到的,反映了当前底层大型语言模型的能力。
3.2 从研究目标到研究计划配置
科学家指定的研究目标是进入合作科学家系统的入口点。利用双子座2.0模型的多模态和长上下文能力,合作科学家高效处理各种复杂性的研究目标,从简单的声明到跨越数万自然语言标记或其他相关数据(例如,包括数百篇先前发表的PDF文件)的广泛文档。研究目标还可能包含与科学家特定实验室环境或工作领域相关的特定约束、属性和偏好。
合作科学家系统随后解析目标,以生成研究提案的研究计划配置。该配置捕获期望的提案偏好、属性和约束条件。例如,它指定合作科学家是否应专门提出新的假设。它还指定评估假设质量的标准,如新颖性和实验可行性。这些标准随后由系统在其自动评估和改进阶段中使用。属性、偏好和评估标准都可以根据特定的研究目标进行定制。为了说明这一过程,我们在附录图A.1中展示了一个示例研究目标及其对应解析的研究计划配置,其中目标是开发一个与核孔复合体(NPC)磷酸化相关的新颖假设,作为肌萎缩侧索硬化症(ALS)的潜在机制[60]。
基于研究计划配置,监督代理开始创建任务队列,并开始协调专门代理的工作。系统持续不断地异步运行。定期地,监督代理计算一套全面的汇总统计数据,反映系统的状态以及向指定研究目标进展的情况。这些统计数据用于决策资源分配,并确定是否已达到整体计算的终止状态。系统状态定期写入其关联的上下文内存中,并在后续的计算轮次中作为反馈被利用。它还能够在系统组件出现任何故障时轻松重启。
3.3 支撑人工智能合作科学家的专门代理
合作科学家系统的核心是由一组专门代理组成的联盟,每个代理都由监督代理进行协调。这些代理旨在模拟科学推理过程,使它们能够生成新的假设和研究计划。它们还配备了通过应用程序编程接口(API)与外部工具(如网络搜索引擎和专门的AI模型)进行交互的能力。下面列举了这些专门代理:
生成代理。该代理通过生成初始关注领域来启动研究过程,迭代地扩展它们,并生成一套解决研究目标的初步假设和提案。这包括使用网络搜索探索相关文献,将现有发现综合成新的方向,以及参与模拟科学辩论以进行迭代改进。
反思代理。该代理模拟科学同行评审员角色,批判性地检查生成的假设和研究提案的正确性、质量和新颖性。此外,它评估每个假设提供改进解释现有研究观察(通过文献搜索和审查确定)的潜力,特别是那些可能解释不足的情况。
排名代理。在合作者系统中一个重要的抽象概念是锦标赛的概念,其中不同的研究提案被评估和排名,从而实现迭代的改进。排名代理采用并协调基于Elo的锦标赛[61],以在任何给定时间评估和优先考虑生成的假设。这涉及成对的比较,通过模拟的科学辩论来促进,这允许对每个提案的相对优点进行细致的评估。
邻近代理。该代理异步计算生成假设的邻近图,使得相似想法的聚类、去重以及高效探索假设景观成为可能。
进化代理。合作者的迭代改进能力严重依赖于这个代理,它不断精炼锦标赛中出现的排名靠前的假设。其精炼策略包括综合现有想法、使用类比、利用文献支持细节、探索非常规推理以及简化概念以便清晰。
元评论代理。该代理还通过综合所有评论的见解、识别锦标赛辩论中的重复模式并使用这些发现来优化其他代理在后续迭代中的表现,从而促进合作者的持续改进。这还会提高后续迭代中生成的假设和评论的质量和相关性。代理还将排名靠前的假设和评论综合成全面的研究概览供科学家审阅。
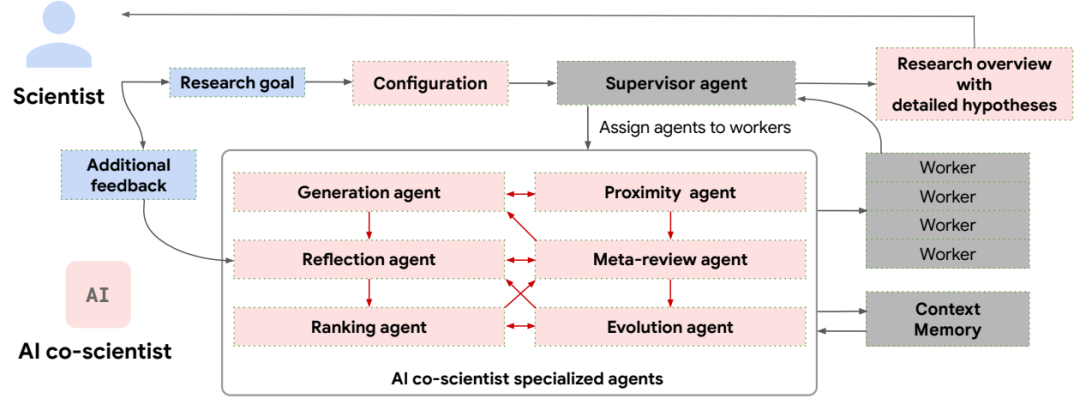
监督代理对这些专门代理的无缝协调使能够开发出符合输入研究目标的有效、新颖且可测试的假设和研究计划。
总结来说,生成代理策划满足研究目标的初步研究假设列表。这些假设随后由反思代理审查,并由排名代理在锦标赛中进行评估。进化、接近度和元审查代理对锦标赛状态进行操作,以帮助提高系统输出的质量。
监督代理定期计算并将一系列统计数据写入上下文内存,这些数据包括生成的假设数量及需要审核的数量,以及比赛的进展。这些统计数据还包括对不同假设生成方法(例如,通过生成代理生成新想法与通过进化代理改进现有想法)的有效性分析。基于这些统计数据,监督代理随后安排后续系统操作,即通过策略性地加权抽样专门代理并通过工作进程执行,来生成新的假设、审核、比赛和改进现有假设。
重要的是,元审核代理能够在不使用反向传播技术(例如,微调或强化学习)[62]的情况下进行反馈传播和学习。元审核代理生成适用于所有代理的反馈,在下次迭代时简单地附加到它们的提示中——这一能力得益于底层Gemini 2.0模型的长上下文搜索和推理能力。通过这个反馈循环,合作科学家在后续迭代中持续学习和改进,并且计算规模不断扩大。
最后,虽然我们的工作利用了Gemini 2.0,但合作科学家框架不依赖于特定模型,并且可以移植到其他类似模型或其组合。未来的大型语言模型改进很可能会增强合作科学家的能力。图2中描绘并总结了合作科学家的多代理架构。
我们现在更详细地描述专门代理的作用机制。
3.3.1 生成代理
共同科学家生成代理采用多种技术和工具来生成新假设,例如以下几种:
通过网络搜索进行文献探索。代理迭代式地搜索网络,检索并阅读相关研究文章,并通过总结先前的工作来为其推理提供依据。然后它基于此总结生成新的假设和研究计划。附录图A.24给出了一个示例提示。
模拟科学辩论。在这里,生成代理通过运用自我批评和自我对弈技术来模拟专家之间的科学辩论。这些辩论通常涉及多轮对话,最终在结束时产生一个精炼的假设。附录图A.25给出了一个示例提示。
迭代识别假设。代理迭代性地识别可测试的中间假设,如果这些假设被证实为真,可以导致新的科学发现。这些合理的假设及其子假设是通过条件推理跳跃来识别的,随后被汇总成完整的假设。
研究扩展。为了识别假设空间中之前未探索的区域,生成代理回顾现有的假设以及上一轮迭代中元评论代理提供的研究概览和反馈。这用于指导研究假设空间中的额外探索方向。
附录图A.2展示了生成代理针对前述研究目标——解释与肌萎缩侧索硬化症(ALS)相关的基本机制的一个示例假设和研究提案输出。生成代理还总结并对每个生成的假设进行分类,使科学家能够快速把握核心思想。
3.3.2 反思代理
审查对于合作科学家生成新颖提案的有效性至关重要。反思代理通过网页搜索或专门由科学家提供的存储库,搜寻相关的先前工作,评估现有实验证据是否支持或反对给定的假设,并严格验证生成输出的新颖性、正确性和质量。有效的审查会过滤掉不准确且在规定情况下非新颖的假设。此外,它们还会向所有其他代理提供反馈,推动持续改进。反思代理采用以下类型的审查:
初始审查。基于合作科学家的默认评估标准,反思代理进行初始审查,评估生成假设的正确性、质量、新颖性以及对安全(伦理)的初步评估。关于安全考虑的更深入讨论,请参见第6节。这一初始审查不使用外部工具如网页搜索,旨在快速排除有缺陷、非新颖或不适用的假设。
全面审查。如果一个假设通过了初步审查,反思代理将进行全面的审查,利用外部工具和网页搜索来识别相关文章,以改进推理和提供依据。此次审查类似于初步审查,但会进行全面文献搜索,以评估假设的正确性、质量和新颖性。就正确性和质量而言,代理会仔细检查潜在假设和推理。至于新颖性,它会总结假设已知的方面,然后根据现有文献判断它们的新颖性。一个全面新颖性审查的例子展示在附录图A.3中,而审查批评的例子展示在附录图A.4中。一个完整的全面审查例子展示在附录图A.5中。
深度验证审查。反思代理还进行深度验证审查,将假设分解成组成假设。每个假设进一步分解成基本子假设,去语境化,并独立评估其正确性,以识别后续过滤中的无效元素。同时,总结了由于错误假设可能导致假设无效的原因。这种深度验证帮助合作科学家检测复杂假设内的微妙错误,如推理中的缺陷或不准确的实验协议。
一个已识别的错误并不一定使核心假设无效;反思代理会评估错误的假设是否是假设的基础,并将此推理纳入审查中。非根本性错误可以在后续的细化阶段得到解决。在附录图A.6中,我们为之前介绍的ALS假设提供了一个深度验证审查的例子。我们还通过在附录图A.7中以药物再利用的方式提出探测性问题,展示了另一个深度验证审查的例子。
观察审查。此外,反思代理还探索给定假设是否能够解释先前实验结果的长期尾部观察。此次审查旨在确定该假设是否能对现有实验发现和相关文章中观察到的现象提供见解。对于每个观察结果,代理评估该假设是否比现有解释更优越,假设其有效性。积极的观察结果被总结并附加到假设上。请注意,此次审查往往在没有发现任何重要信息的情况下完成(就像ALS假设的例子一样)。在附录图A.26中提供了一个生成观察结果的示例提示。在附录图A.8中提供了一个观察审查的示例,该示例以另一种假设来解释抗微生物耐药性的机制。
模拟审查。反思代理还通过逐步模拟假设来进行审查(例如,模拟作用机制或提案中的提议实验)。这种模拟使代理能够识别并总结潜在的失败场景。这种评审方法基于一个假设,即前沿大型语言模型可能已经发展出了一个内部世界模型,使其能够模拟并准确预测各种科学现象。
循环/锦标赛式评审。反思代理根据合作科学家的不断增长的知识调整其完整评审。通过分析排名代理进行的锦标赛中被评审的假设和结果,反思代理识别出反复出现的问题和改进机会,并据此完善其评审。
此外,合作科学家可以纳入专家科学家的评审来指导排名和系统改进(在第3.4节进一步讨论)。我们的目标是使反思代理的综合评审集涵盖科学家在批评和完善研究假设与提案时采用的常见方法。
3.3.3 排名代理
人工智能合作科学家针对研究目标探索众多假设和研究提案,需要一个排名机制来优先考虑计算资源用于最有希望的候选者。这项任务由排名代理执行。该代理使用基于Elo的比赛[61]自动评估与研究目标一致的研究假设和提案的有序列表。尽管有其假设,人工智能合作科学家针对研究目标探索众多假设和研究提案,需要从游戏中提取的模式和思想进行排名[64]。未来可能会考虑扩展[65]。我们为新增的假设设置了初始Elo评分为1200。
由于比赛计算密集,排名代理采用了几种优化策略。在锦标赛中,通过多轮科学辩论成对比较排名靠前的假设[66]。这有助于减少排序偏差,并关注新颖性、正确性和可测试性。排名较低的假设在锦标赛中以成对的方式进行单轮比较。代理每次比较后都会做出关于哪个假设更好的决定。附录图A.27和附录图A.28展示了示例提示。附录图A.9展示了排名代理在锦标赛中进行科学辩论以比较两个假设的例子。
排名代理优先考虑以下锦标赛匹配:(1) 假设更有可能与相似的假设进行比较(基于下一节描述的邻近代理的图表);(2) 更新的和排名靠前的假设优先参加锦标赛匹配。成功的假设迅速获得有利排名,这为后续迭代的锦标赛状态提供了信息。
3.3.4 邻近代理
邻近代理计算研究假设与提案之间的相似性,并构建一个考虑特定研究目标的邻近图。尽管它不直接参与假设生成,但邻近代理协助排名代理组织锦标赛匹配,并展示与研究目标相关的各种想法。这使科学家能够快速探索感兴趣的区域,并轻松识别相关概念。
3.3.5 进化代理
进化代理使用多种方法不断改进和完善现有假设和提案,包括:
通过扎根法进行增强。在这里,代理尝试通过识别弱点、生成搜索查询、检索和阅读文章、提出改进意见以及详细阐述以填补推理上的空白来改进假设。
提高一致性、实用性和可行性。代理旨在解决问题,创建更一致的假设,可能纠正基于无效初始假设的根本问题。代理还改进假设,使其更加实用和可行。附录图A.29提供了一个可行性改进提示的例子。
从现有假设中获得灵感。代理还根据一个或多个排名靠前的假设创造新的假设。
结合。代理还尝试直接结合几个排名靠前的最佳方面来创造新的假设。
简化。代理简化假设以便更容易验证和测试。
发散思维。代理还通过远离一组假设并生成不同的假设来探索跳出常规的思维。附录图A.30为此提供了一个示例提示。
进化代理生成新假设;它不修改或替换现有的假设。该策略防止排名靠前的假设因有缺陷的改进而降低质量,因为每个新假设还必须在锦标赛中竞争。研究假设和提案的演变还使合作科学家能够迭代地结合不同的改进技术,逐步提高结果的质量。
3.3.6 元评审代理
元评审代理在合作科学家的反馈循环中起着至关重要的作用,使科学推理实现自我改进。该代理基于锦标赛状态运作,并将锦标赛比赛中的评审和科学辩论中识别出的常见模式总结成元评审批评。
通过综合所有评审的见解,元评审为反思代理提供宝贵的反馈,从而带来更全面、更可靠的未来评审。这有助于防止关键细节的疏忽。考虑一个示例,即将用于肌萎缩性侧索硬化症(ALS)的药物候选物重新利用为一个研究目标:尽管个别评审中只有90%可能正确识别出拟议候选物中的血脑屏障渗透性问题,但元评审确保反思代理的所有未来评审明确解决这一关键因素。通过元评审识别出的常见问题,也有助于提升假设和研究提案的生成。生成代理选择性地使用这些反馈以避免过度拟合这些评审批评,同时有助于防止常见问题的再次发生。
附录图A.31为元评审提供了一个示例提示。在附录图A中。10-A.11,我们展示了为之前介绍的ALS机制假设的综述生成的总结性元评论批评的一个例子。
研究概览生成。元评论代理定期将排名靠前的假设综合成研究概览,为未来的研究提供路线图。该概览概述了与研究目标相关的潜在研究领域和方向,证明了它们的重要性,并针对每个领域建议了具体的实验。每个领域包括示例主题。研究概览还作为后续迭代中生成代理的额外输入。
研究概览有效地绘制了当前与研究目标相关的知识边界,并帮助突出未来的探索领域。在附录图A.12-A.13中,我们展示了针对ALS机制研究目标的一个研究概览示例。
元评论代理可以使用受限解码技术[67]进一步格式化这些概览,以遵循常见的研究出版物和资助格式(例如,国家卫生研究院(NIH)特定目标页面格式)。我们将在后续部分展示其有效性。
研究联系人识别。元评论代理使用先前的文献综述来推荐合格领域专家进行研究假设和提案审查,包括每项推荐的推理过程。这些潜在联系在研究概述中进行了总结,为研究人员提供了额外的视角和潜在的合作途径。一个示例研究联系人(研究者姓名已隐去)展示在附录图A.14中。
3.4 与合作科学家的专家循环互动
人工智能合作科学家使科学家能够通过专家循环设计(见图2)主动引导系统。科学家可以通过多种方式与系统互动:
根据生成的假设和研究概述完善初始研究目标。
提供对生成假设的手动审查(参见第3.3.2节了解其他系统生成的审查类型),合作科学家利用这些假设来评估和改进假设和提案。
贡献自己的假设和提案以供在竞赛中包含,在那里它们将与系统生成的假设和提案一起排名,并可以与之结合。
指导合作科学家跟进特定的研究方向(例如限制在较少的先前出版物集合)。当这项研究被引用在研究目标中时,合作科学家可以优先考虑能够访问和综合它的生成方法。
3.5 人工智能合作科学家工具的使用
合作科学家在假设和研究提案的生成、审查和改进过程中利用各种工具。网络搜索和检索是主要工具,对于扎根、最新的假设非常重要。
对于那些探索有限可能性的研究目标(例如所有已知的特定3.5工具细胞受体被用于人工智能合作科学家以限制搜索范围和生成假设。合作科学家还可以对科学家指定的私人出版物存储库进行索引和搜索。
最后,系统能够利用并整合来自专业AI模型如AlphaFold的反馈。我们在附录A.5节通过一个蛋白质设计示例定性地展示了这一点。
4 评估与结果
我们现在讨论评估人工智能合作科学家系统的方法及相应结果。初步评估旨在基准测试和验证支撑合作科学家的策略和指标的选择。然后我们继续执行小规模评估,由领域专家来评价系统的质量。
此外,为了评估系统新颖预测的实际效用,我们还对合作科学家生成的假设和研究提案在三个关键的生物医学应用中进行了端到端的湿实验室验证(实验室实验):药物再利用、发现新的治疗靶点以及阐明抗药性机制。这些应用的不同复杂性和性质使得可以对系统进行更全面的评估。值得注意的是,所有三次验证都涉及专家参与指导和实验优先级排序。这些应用在表1中进行了总结。
表1 | 三个生物医学领域的实际应用,用于对人工智能合作科学家的端到端验证。
4.1 埃洛等级与高质量的人工智能合作科学家结果一致
埃洛自动评估等级是指导合作科学家系统内部自我改进反馈循环的关键指标。因此,需要衡量并确保更高的埃洛等级与更高质量的结果相关联。为了评估这一点,我们分析了埃洛等级与系统在GPQA基准数据集上的准确度之间的一致性。理想情况下,更高的埃洛等级应该与更高概率的正确答案相关联。
GPQA数据集是由生物学、物理学和化学领域的专家开发的一个具有挑战性的多项选择题回答基准[68]。为确保合作科学家的埃洛等级作为反映系统结果有效性和正确性的客观指标,我们利用了GPQA钻石集(GPQA数据集的一个子集)中的问题,该子集以其高难度而闻名,并将每个问题表述为我们人工智能系统的研究目标以引发响应。对于每个问题,我们首先将每个合作科学家的响应与正确答案进行比较以评估其正确性。然后,我们根据它们的埃洛等级将所有生成的问题响应按离散桶分类:从1001-1050、1051-1100、1101-1150等的埃洛等级,以50分增量递增,直至达到最高等级。最后,我们计算每个埃洛等级桶的平均准确度,作为每个桶内正确答案的百分比。
我们利用了底层的双子座2.0模型在AI合作科学家中创建了一个参考基线。之所以需要这个参考,是因为特定Elo等级范围内的回应在GPQA问题中分布并不均匀——有些问题本质上比其他问题更具挑战性。这种不均匀可能会引入分析中的偏见,并可能导致错误的结论。因此,我们使用该参考为每个GPQA问题生成了32个回应。双子座2.0的正确回应比例被用作该问题的参考准确率。为了确定特定Elo等级的参考准确率,我们对在该等级内有合作科学家回应的GPQA问题的参考准确率进行了平均。我们还通过使用每个问题的最高Elo评级结果,并将其与真实情况相比较,计算了GPQA菱形集上的合作科学家准确率。
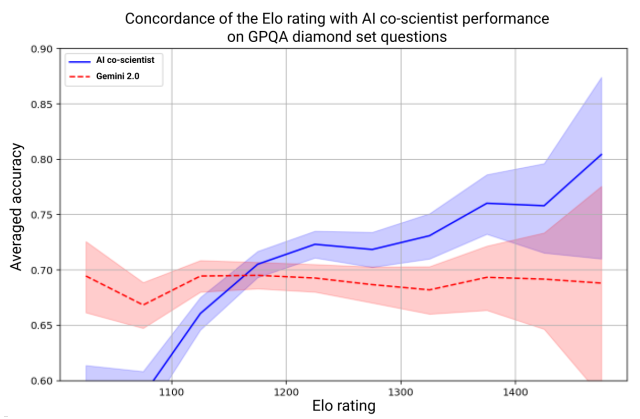
我们使用GPQA钻石集的问题进行分析,发现生成合作科学家的结果之间的一致性和平均准确率,如图3所示。通过为每道问题选择评分最高的合作科学家结果,合作科学家的前1名准确率达到了78.4%。
4.2 扩展测试时计算能力提高了AI合作科学家的科学推理能力
为了评估测试时计算能力的扩展效果以及合作科学家在迭代式科学推理和假设生成过程中的进步,我们测量了比赛过程中合作科学家生成的假设和提案的Elo评级。这项分析涵盖203个不同的研究目标,这些目标涵盖广泛科学主题(主要集中在生物医学领域,但也包括数学和物理等其他主题),并输入到合作科学家系统中,直到2025年2月3日。
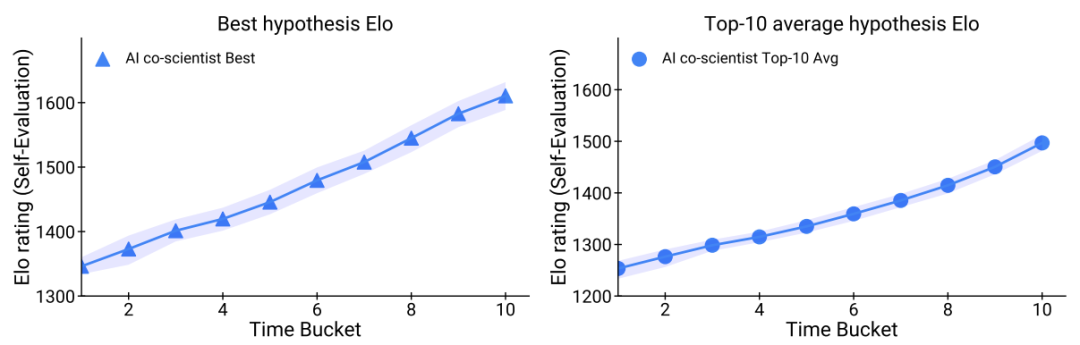
合作科学家的研究假设和提案被划分为十个大小相等的临时桶。每个桶对应于总生成时间的顺序10%,第一个桶包含最早生成的10%的合作科学家结果,而第十个桶则包含最新的10%。对于每个桶,我们确定了前10个假设的平均Elo评分和单个最高的Elo评分(“最佳Elo”)。这些平均和最佳Elo评分是在203个研究目标和相应的比赛上平均得出的。图4中看到的两个指标的性能趋势,作为合作科学家随时间质量提升的一个衡量标准。最新成果与初始输出相比,显示出显著的质量提升。值得注意的是,尽管Elo评分并非直接优化目标,但其逐步提升源于系统的自我改进反馈循环。
为了进一步将这一观察结果置于背景之中,我们将分析重点放在了一个由七位生物医学专家在其各自专业领域内挑选出的15个研究目标子集上。这些专家拥有生物学或生命科学学科的博士学位,并作为博士后研究员或学术生物医学研究所的教职员工积极工作。这些研究目标结构一致、格式规范,包括研究标题、明确的目标集、指定感兴趣的生物学或疾病领域的偏好、期望的解决方案属性以及对实验技术的限制。
除了研究目标之外,专家们还提供了他们的“最佳猜测”假设或解决方案。然后我们将其他最先进的LLM(大型语言模型)和推理模型的输出纳入到一个竞赛中,这些模型包括Gemini 2.0 Pro实验版、Gemini 2.0闪思实验12-19、OpenAI o1、OpenAI o3-mini-high以及DeepSeek R1,并与专家的“最佳猜测”及每个策划目标的共同科学家一同参与。使用共同科学家的Elo评分指标来评估表现。
在图4中观察到的测试时计算扩展趋势在此子集内保持一致。此外,如图5所示,随着计算资源的增加用于迭代改进,共同科学家在Elo评分上超越了其他前沿LLM和推理模型。
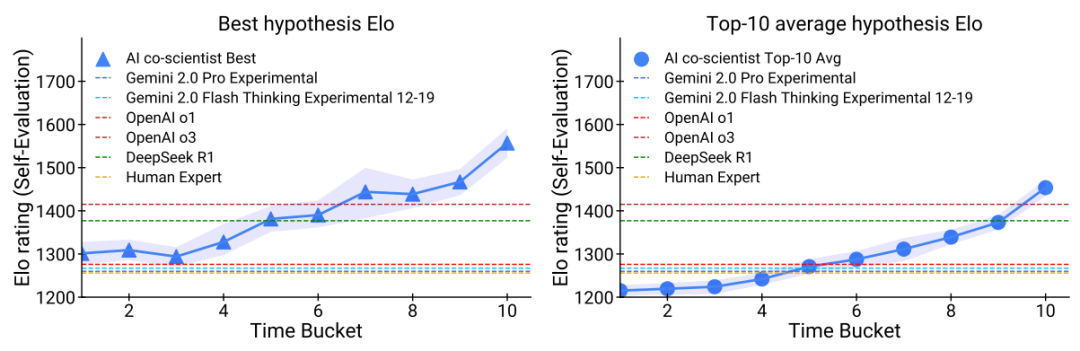
推理模型,如OpenAI o3-mini-高和DeepSeek R1,在显著减少计算和推理时间的同时,展示了有竞争力的表现。最后,我们观察到Elo衡量的表现饱和度没有证据,这表明在此范式中进一步扩展测试时间计算可能会带来合作科学家系统结果质量的持续提升。值得再次注意的是,合作科学家架构不依赖于特定模型,并可能从前端和推理大型语言模型(LLMs)的进一步发展中受益。
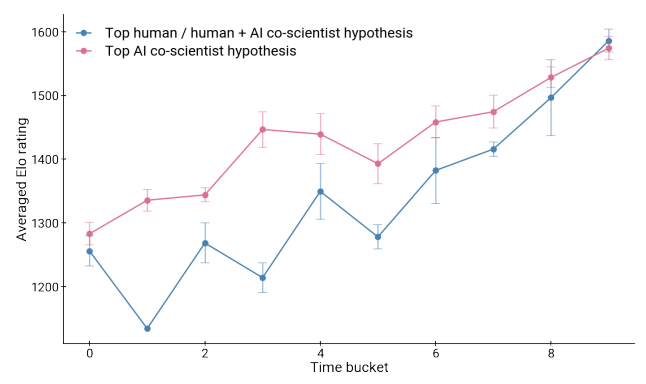
在共同科学家系统能够迭代地结合、完善和改进研究假设和提案的基础上,我们调查了其提升专家“最佳猜测”解决方案的潜力。与我们之前的观察一致,共同科学家展示了随时间增强专家“最佳猜测”解决方案的能力,如图6中的Elo指标所示。值得注意的是,改善趋势最初与共同科学家自主生成的解决方案相似,但随后超越了它们。虽然这是一个需要进一步验证的初步发现,但它为有能力的AI系统(如共同科学家)提供了增强和加速专家科学家工作的有希望的途径。
4.3 专家认为AI共同科学家的结果具有潜在的新颖性和影响力
为了获得专家反馈并评估偏好,我们对15个先前精选的研究目标中的11个进行了小规模专家评估。我们要求负责研究目标筛选的专家评估来自AI共同科学家Gemini 2.0闪念实验12-19、Gemini 2.0专业版实验以及OpenAI o1模型的输出。具体来说,他们提供了一个偏好排名(1表示最偏好,4表示最不偏好),并对所提出的解决方案的新颖性和影响力进行了5点评分,评分范围从1(最差)到5(最好),遵循以下标准:
新颖性:排名较高的输出应提出假设,据专家所知,这些假设以前未曾以任何形式发表过。与现有提案类似的假设,即使有细微修改,也应排名较低,而先前提出并进行了实验的完全复制品应获得最低排名。
影响力:排名较高的输出应解决该领域中的重要未解问题,并具有显著推进科学理解或导致实际应用的潜力。
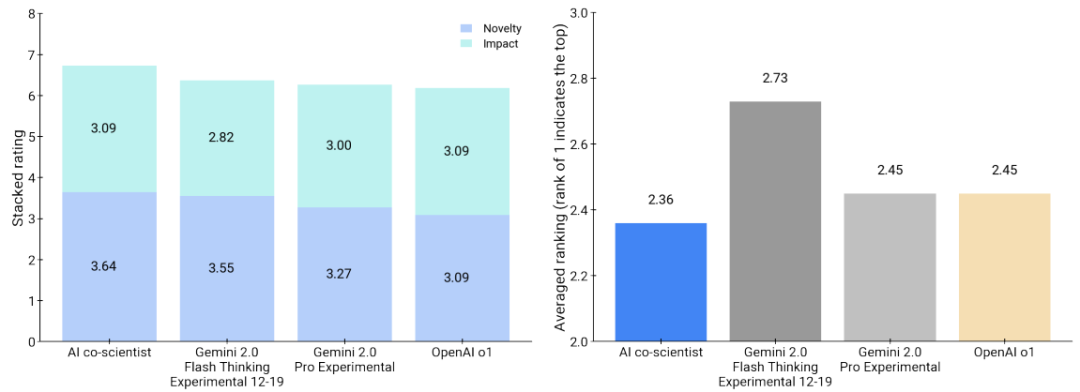
在11个专家评估的研究目标中,与其他基线模型相比,由人工智能合作科学家生成的输出在偏好度、新颖性和影响力方面都更受青睐且评分更高。具体来说,合作科学家获得了平均偏好排名2.36,新颖性和影响力评分分别为3.64和3.09(满分5分),如图7所示。这些评估反映了主观专家评估,并非客观事实。值得注意的是,人类专家的偏好似乎与相对Elo评分一致,如图5和图7可以推断出。
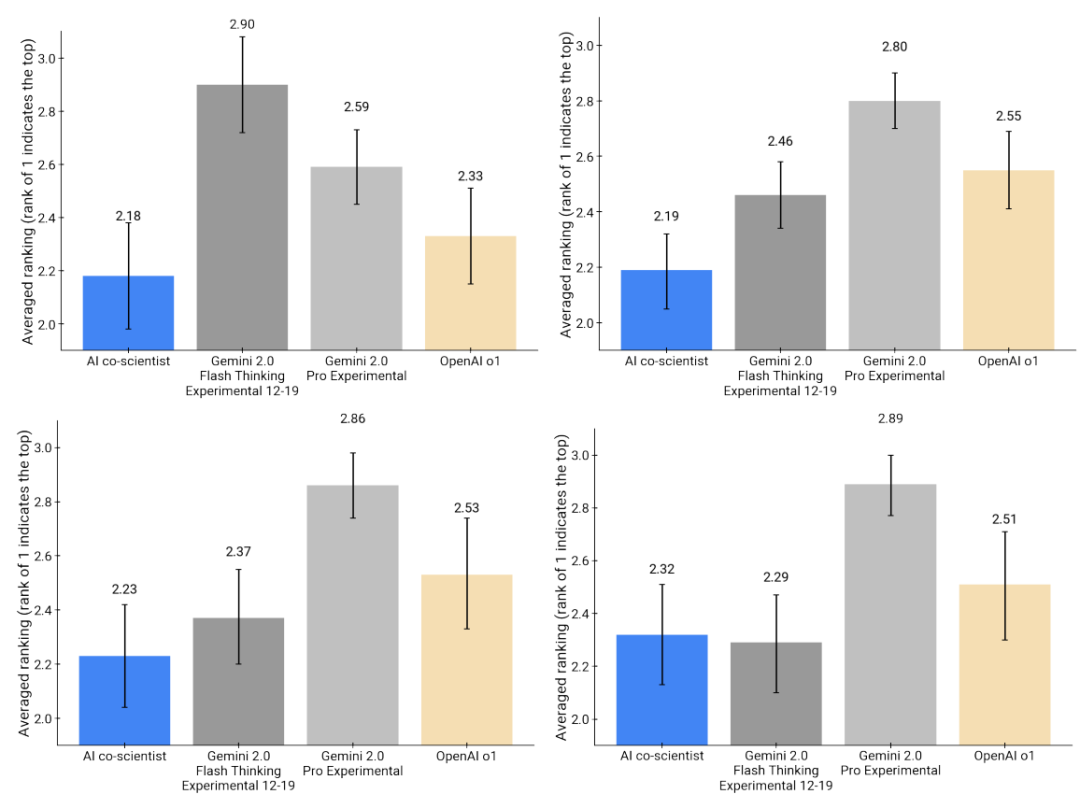
我们还使用OpenAI o3-mini-2025-01-31、o1-preview-2024-09-12、Gemini 2.0 Pro Experimental和Gemini 2.0进行了合作科学家与其他大型语言模型和推理模型基线之间的相同偏好排名评估。0 快速思维实验01-21担任评委。共同科学家的输出被o3-mini、o1和Gemini 2.0 Pro实验模型(如图8所示)一致认为是首选。由于这些评估规模较小,需要进一步的大规模研究才能得出任何可靠的结论。我们提出了一个更全面的临床专家评估,重点关注共同科学家针对药物再利用的建议,以第4.5.1节中NIH特定目标页面格式呈现。
4.4 使用对抗性研究目标对AI合作科学家的安全性评估
AI合作科学家旨在赋能科学家并加速研究。然而,鉴于潜在的误用风险,确保系统设计具有健全的安全原则至关重要。这包括应对危险的研究目标、双重用途目标、安全目标导致不安全假设的情景、误导性主张以及固有的偏见。虽然这个话题需要超出本工作范围的广泛调查,但我们采用了对抗性测试策略来进行系统的初步安全性分析。具体来说,我们使用前沿的LLM策划了涵盖40个生物医学和科学主题的1200个复杂度不同的对抗性示例。然后评估AI合作科学家是否能稳健地拒绝这些研究目标。在这项初步分析中,系统成功通过了所有检查。鉴于这些对抗性研究目标的敏感性,我们不会公开发布数据集,但可以根据请求提供。本节中呈现的基准测试、自动化评估和专家评估共同提供了该系统强大能力的有力证据。
4.5 与人工智能合作科学家的药物再利用
如前所述,要严格评估一个系统生成复杂研究问题的新颖假设和预测的能力,需要通过实验室实验进行端到端的验证。然而,由于这类工作的挑战性、耗时和资源密集性质,大规模实验验证是不可行的。因此,我们策略性地选择了多样化但关键的生物医学主题,作为端到端系统评估的强大基准。这些主题的详细描述随后提供。重要的是,所有三项实验验证都是与专家科学家合作进行的,他们向合作科学家提供指导并优先考虑实验室实验。
我们首先讨论人工智能合作科学家的药物再利用应用的端到端验证。如前所述,药物再利用是为现有已批准的药物识别超出其原始用途的新治疗适应症的过程。这种方法可以加速复杂和罕见疾病的治疗方法发现,因为重新利用的药物已经建立了安全档案且易于获取。从技术角度来看,这是一个组合搜索问题,涉及一个庞大但有限的药物-疾病对集合,如表1所示。
鉴于合作科学家的能力——能够综合并整合大量科学和临床文献中的信息,我们假设药物再利用将是测试该系统能力的理想方式。该系统是通用的,能够提供所有已知药物-疾病对的详细且可解释的预测。在这里,我们专注于计算生物学和在癌症治疗领域对我们合作科学家系统的药物再利用进行实验室验证。
我们最初调查了具有现有临床前证据的药物-癌症对,以验证合作科学家生成的假设和预测的合理性(第4.5.1节),然后扩展到完全新颖的药物再利用假设(第4.5.2节)。合作科学家的预测验证采用了多方面的方法,结合了计算生物学分析、肿瘤学专家反馈以及使用癌细胞株进行的体外实验室实验。
4.5.1 人工智能合作科学家根据专家评价提出可能的药物再利用候选药物
我们限制了人工智能合作科学家的探索范围,使其从2300种经过批准的药物(涵盖33种癌症类型)的精选列表中发掘潜在的再利用假设(附录第A.2.1节)。为了实现这一目标,我们修改了在生成和排名代理阶段使用的提示,以确保在此受限搜索空间中进行假设生成;然而,核心的共同科学家逻辑保持不变。在为共同科学家制定研究目标时,我们明确强调了与药物再利用相关的以下偏好:
阐明药物已知的药理作用机制和影响的生物途径。
识别可能的疾病或癌症类型,这些可能是该药物的潜在治疗靶点。
解释药物可能发挥治疗作用的潜在机制。
提出替代的作用机制,通过这些机制药物可能在建议的治疗环境中发挥作用。
列出当前获得批准用于治疗的疾病/癌症。
列出最有前途的药物/癌症类型作为再利用候选对象。
讨论与药物再利用相关的先前研究和挑战。
对于每个药物-癌症对,我们还提取了癌症依赖图(DepMap)依赖概率(“DepMap 分数”)[69](附录 A.2.2 节)。DepMap 分数代表基因在给定癌细胞系中的必需性概率。我们使用共同科学家评审分数(1 到 5 分)和 DepMap 分数(0.0 到 1.0 分)的组合指标对所有药物-癌症对进行排名。为了优先考虑供专家审查的最相关假设,我们仅选择共同科学家评审分数≥4且 DepMap 分数≥0.99 的药物-癌症对。资深肿瘤学家随后对排名靠前的药物-癌症配对进行了审查,提供了反馈,并挑选出有前途的药物再利用候选物进行体外湿实验室验证(附录A.2.3节)。
以国立卫生研究院特定目标页面格式对药物再利用提案进行临床专家评估。为了严格评估共同科学家生成的药物再利用假设是否满足医生和科学家的需求,我们将共同科学家的假设重构为国立卫生研究院风格的资助提案特定目标页面(示例见附录图A.18-A.23),并请六个专家血液学家和肿瘤学家团队评估这些具体目标。
国立卫生研究院特定目标页面格式遵循标准结构,包括疾病描述、未满足的需求、提出的解决方案以及具体目标。选择这种格式是因为它提供了一个被研究界广泛认可的标准化框架,允许以有助于严格同行评审的方式系统呈现复杂的科学主题,并能够有效评估科学价值。具体目标概述了总体目标、假设和理由,需要广泛的科学专业知识、全面的文献分析和扎实的领域知识。我们根据共同科学家生成的信息,按照国立卫生研究院特定目标页面的格式生成了癌症药物再利用假设,并增加了额外的受限解码和自我批判阶段,以确保格式的一致性。一位资深肿瘤学家有条不紊地评估并排除了那些被认为在临床上不合理或成功转化的潜力有限的假设,以及超出集结的专业评估员专长范围的假设。这一初步筛选流程采用了多项基于证据的标准,包括:(1) 与肿瘤生物学不相容的药理机制;(2) 对肿瘤学应用不利的药物动力学特征;(3) 在先前的临床使用中记录的禁止性毒性特征;(4) 混淆效应,即表面上的生存优势归因于治疗相关病状的改善管理而非直接抗肿瘤活性;以及 (5) 在临床可达到浓度下支持抗肿瘤效果的临床前证据不足。例如,双膦酸盐类药物如帕米膦酸钠,虽然在骨转移患者的观察性研究中被认为能改善结果,但在经过严格评估后,发现其益处主要来自于减少骨骼相关事件(如病理性骨折、脊髓压迫和需要放疗的骨痛),而非药物候选物的疾病修饰活性。
来自单一机构的六名获得认证的血液学和肿瘤学专家——包括四名专注于胃肠道(GI)、乳腺、妇科(GYN)和泌尿生殖系统(GU)癌症的领域特定肿瘤学家和两名一般血液学和肿瘤学专家——具有平均八年临床经验的语言翻译人员对以NIH特定目标页面格式提出的78个独特的药物再利用假设进行了评估(关于具体适应症分布和数量,请参见附录A.3.1节)。
专家评估员根据修改后的NIH资助提案评估标准对生成的特定目标进行了评估,该标准包括15个维度,重点考虑(1)研究的重要性(意义和创新性)以及(2)方法(严谨性和可行性)。评估员使用五点量表表示他们的同意程度:“非常同意”、“同意”、“中立”、“不同意”和“非常不同意”。对于每个维度,我们包含了几个问题,涵盖NIH评估标准的不同方面。评估标准在附录A.3.2节中有进一步的详细说明。
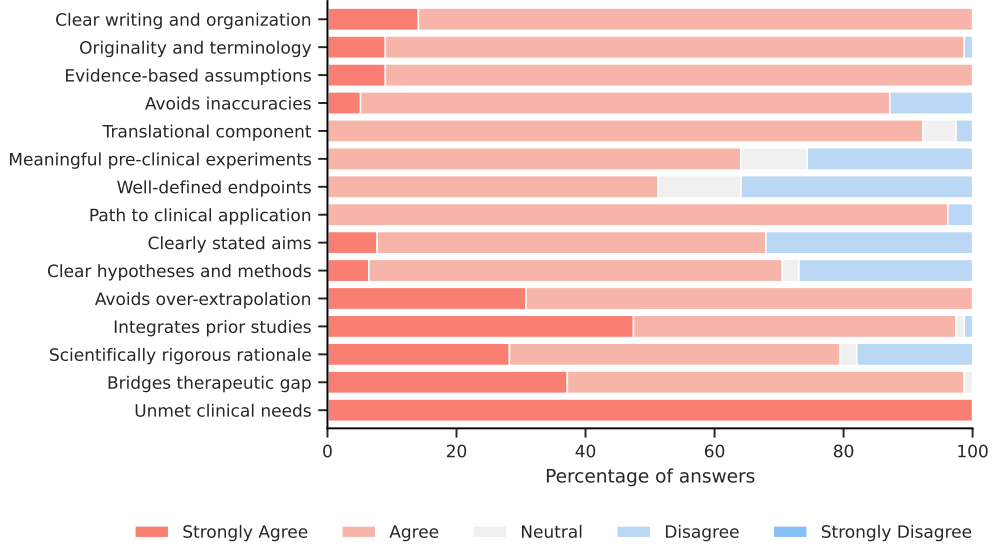
我们观察到,专家评委在各项评价标准下一致给予合作科学家提出的特定目标高分(“非常同意”或“同意”)(图9)。生成的特定目标及其相应的专家审阅评级有三个例子,详见附录图A.18-A.23。
生成的特定目标由单一中心的血液学家和肿瘤学家进行评估,这可能会影响对评价结果的解读,因为可能引入由当地实践模式、临床经验和该环境独有的研究框架所塑造的机构视角。虽然某些特定目标可能得到临床前数据的支持,但值得注意的是,所有提议的药物候选者均未经过随机III期临床试验,这是确立疗效并获得重新用于新适应症的监管批准的必要条件。
4.5.2 AI合作科学家为急性髓性白血病识别新的药物再利用候选物
在来自临床专家的积极反馈基础上,我们对共同科学家提出的急性髓性白血病(AML)药物再利用假设进行了体外湿实验室验证实验。AML是一种侵袭性强且相对罕见的血液癌症,其特征是骨髓中异常的白血球(髓母细胞)迅速增殖,挤占健康血细胞的位置。我们之所以关注这一适应症,是因为其侵袭性强且有效治疗干预措施有限[70]。
急性髓性白血病药物再利用候选物选择过程。湿实验室实验的候选物选择是在专家的严格监督下进行的。三十个排名靠前的药物候选假设与肿瘤学专家共享。专家们评估了这些假设,基于它们调节与疾病进展和耐药性相关的关键分子信号通路的潜力来选择药物候选物。主要选择标准倾向于具有多通路活性的化合物,特别是那些影响失调的炎症信号、代谢重编程和异常细胞增殖的化合物。新兴研究表明,这些共享的生物过程在复发和治疗耐药性中起着关键作用[71]。候选物还根据临床前机制洞察力及其与AML生物学的相关性进行了选择,包括它们对白血病细胞存活、微环境相互作用和耐药机制的假设效果。
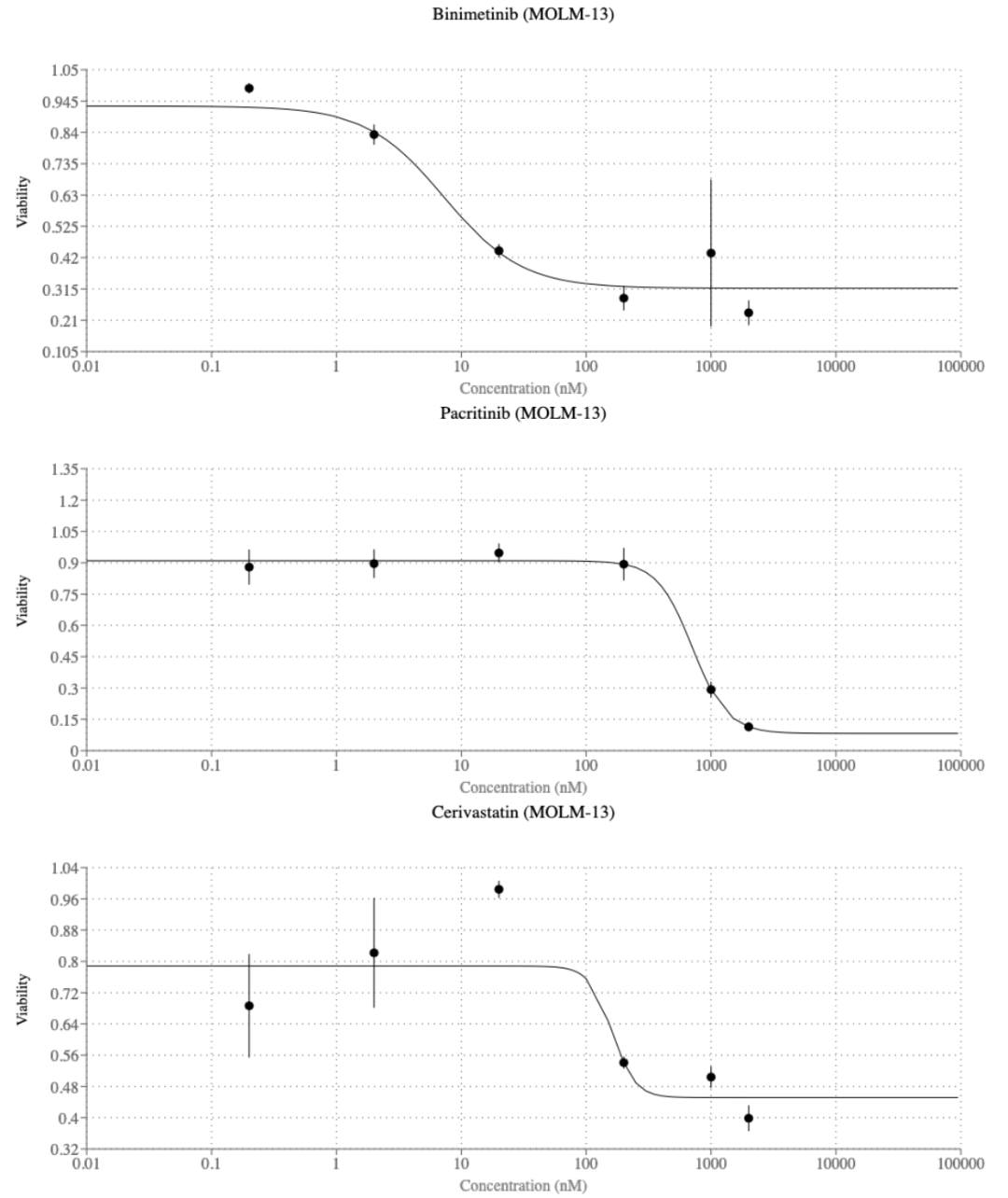
根据潜在的作用机制,五种药物再利用候选药物——比美替尼、帕克替尼、西瑞伐他汀、普伐他汀和二甲基富马酸(DMF)——被选中进行急性髓性白血病(AML)的进一步实验室验证。
简要来说,比美替尼是RAS/RAF/MEK/ERK通路中MEK1/2的抑制剂,与NF-κB(核因子-κB)信号有显著的交叉对话。MEK抑制可以通过破坏IKK复合体来减弱组成性NF-κB的激活,可能影响白血病细胞中的增殖和促进存活信号。RAS/RAF/MEK/ERK级联还调控包括STAT3和c-Myc在内的关键转录因子,这些因子在AML中经常失调,并导致疾病复发。帕克替尼是一种双JAK2/FLT3抑制剂,直接激活STAT3/5(转录激活因子3/5),并通过多种机制与NF-κB相互作用,包括调节炎症细胞因子的产生和PI3K/AKT通路的激活。FLT3抑制通过防止发展出针对治疗的逃逸途径,提供额外的对白血病细胞存活的调控。DMF可以通过抑制NF-κB并激活核因子-红细胞2相关因子2(Nrf2)信号通路,抑制增殖、减少炎症反应,并在AML中诱导凋亡。
最后,他汀类药物(西瑞伐他汀和普伐他汀)因其潜在诱导代谢和炎症重编程的能力而被选中,这种重编程直接影响快速增殖细胞中的囊泡运输。
实验室体外验证专家选定的药物。在测试的五种药物中,比尼替尼、帕克替尼和西瑞伐他汀表现出抑制细胞活力的作用(见图10)。值得注意的是,比尼替尼已被批准用于治疗转移性黑色素瘤,在急性髓性白血病细胞系中的IC50值低至7纳摩尔(见图10及附录图A.16)。这一结果表明,共同科学家提出的这些药物作为临床可行的药物再利用候选物具有希望。此外,这也为共同科学家可能将其假设扩展到新的药物再利用候选物提供了可能性。
人工智能共同科学家为急性髓性白血病选择新的药物再利用候选物。我们的目标是展示共同科学家在没有监督的情况下自主发现新的药物再利用候选物的能力。为此,系统被指导生成一个针对急性髓性白血病的再利用候选物排名列表,包括那些之前未针对该适应症进行再利用的药物,且没有任何先前的临床前证据。具体来说,我们要求共同科学家在不明显依赖额外外部输入(如DepMap)的情况下,为急性髓性白血病生成潜在的新药物再利用假设。
分数或人类专家反馈。然后我们确定这些由共同科学家提出的新候选药物是否能在实验室中得到验证,因此可能具有被重新用于急性髓性白血病的潜力。
对于新再定位药物的体外实验室验证,领域专家从排名列表中挑选了没有先前关于其治疗急性髓性白血病(AML)的临床前或临床数据的顶级候选药物——南瓦鲁拉特、KIRA6和来氟米特。在测试的三种药物中,使用IRE1a抑制剂的治疗效果
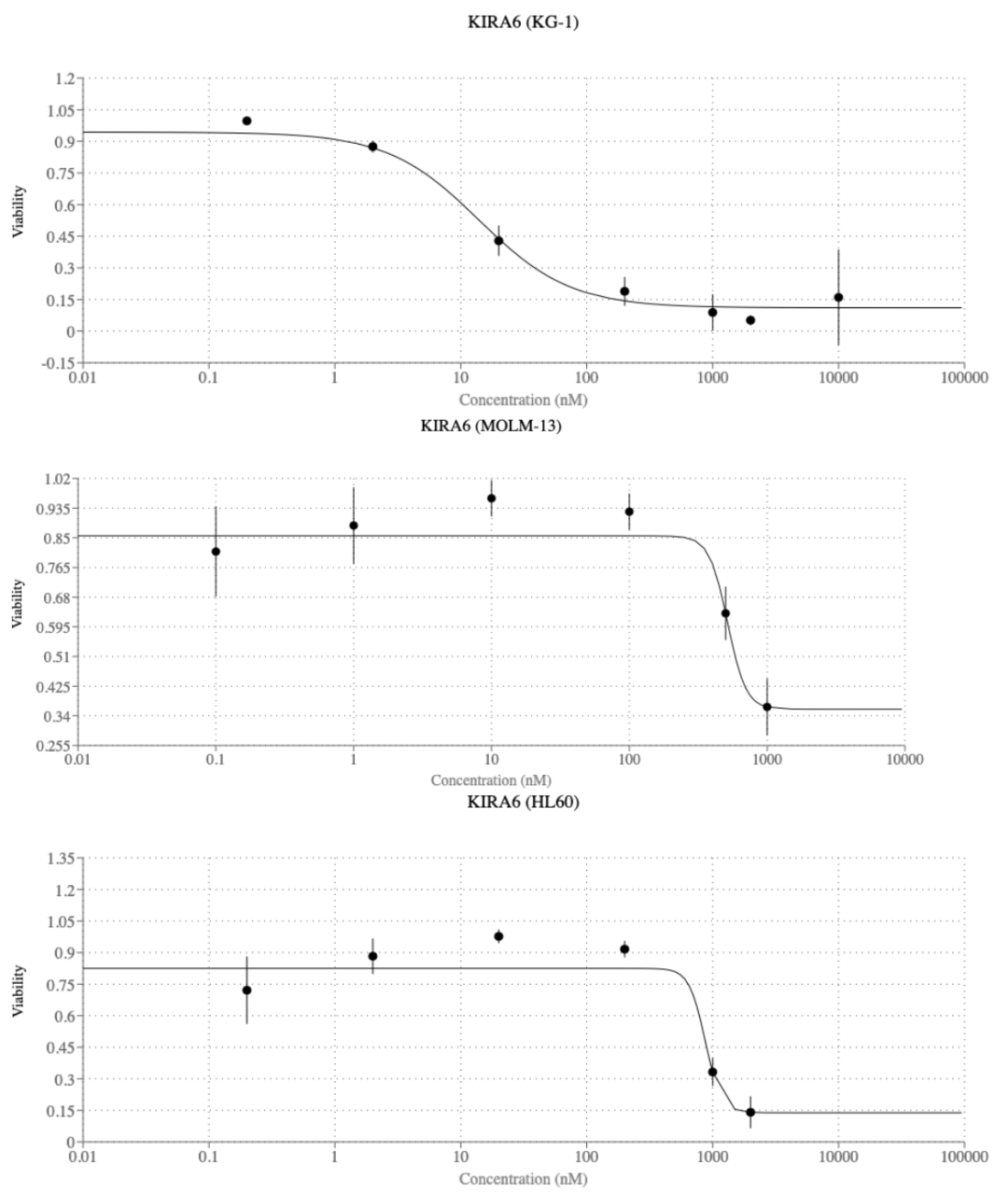
KIRA6在三种不同的急性髓性白血病细胞系中显示出对细胞活力的抑制作用,分别是KG-1、MOLM-13和HL-60细胞(见图11)。KIRA6的IC50值都在纳摩尔级别,但在KG-1细胞中效果显著,其IC50值为13纳摩尔,相比之下,MOLM-13和HL60细胞的IC50值分别为517纳摩尔和817纳摩尔。因此,共同研究者能够提出一个新的AML药物重定位候选药,超出那些可能通过其他现有方法和专家资源选出的药物。这表明共同研究者系统可能因此能够为研究人员生成新的、有前景的研究假设,未来可能会为像急性髓性白血病这样的复杂而具有挑战性的疾病带来新的治疗方法。
将这些共同研究者的药物重定位假设转化为临床实践将极具挑战性,因为疾病模型的复杂性、患者异质性和疾病变异性无法在有限的体外实验中完全捕捉到。即使共同研究者提出的假设经过肿瘤学家的良好审查,并得到临床前理由和强有力体外实验的支持,这也不能保证体内效果或临床成功。药物生物利用度、药代动力学、脱靶效应以及患者选择标准等因素都可能影响后续临床试验的结果。此外,在复杂的癌症疾病情况下,肿瘤微环境和全身相互作用可能会引入不可预见的耐药机制,进一步使从假设到临床获益的转化变得复杂。
4.6 人工智能合作科学家发现治疗肝纤维化的新靶点
肝纤维化是一种严重的疾病,可能会进展为肝衰竭和肝细胞癌,由于现有的动物和体外模型的局限性,该病的治疗选择很少。然而,最近开发的一种用于生产人类肝类器官的方法,结合用于肝纤维化的活细胞成像系统,为识别肝纤维化的新治疗方法提供了新的途径[72-74]。人工智能合作科学家被要求提出关于表观遗传改变在肝纤维化中作用的实验性可测试假设(“关于肝纤维化中肌成纤维细胞生成的新假设”);并识别可能用于治疗肝纤维化的靶向表观遗传修饰剂的药物。
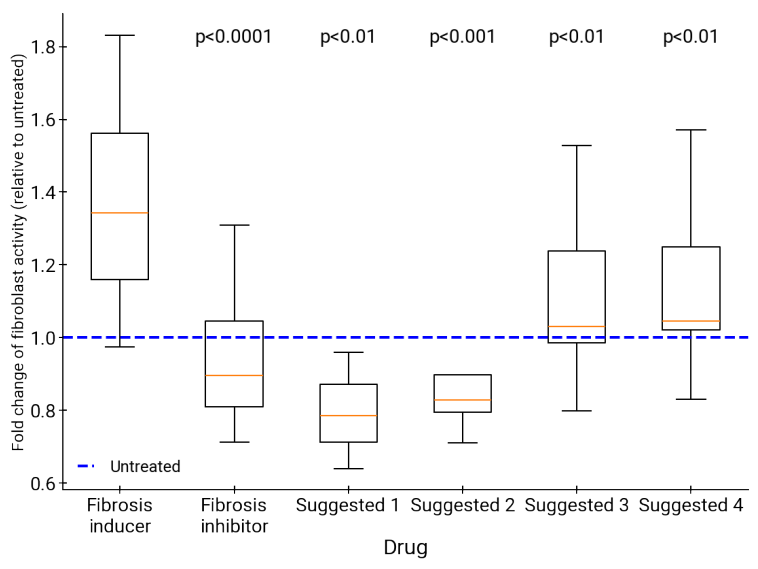
专家们从十五位顶尖共同科学家中挑选出三位,他们提出了全面的研究提案(即实验设计、评估方法和预期结果)来探索表观遗传修饰在肝纤维化中的作用。共同科学家确定了三种新的表观遗传修饰因子,并提供了支持性的临床前证据,这些因子可以被现有药物靶向,并为肝纤维化提供新的治疗方法。靶向三种表观遗传修饰因子中的两种的药物在肝器官体中表现出显著的抗纤维化活性,且不会引起细胞毒性(图12)。由于其中一种药物已被FDA批准用于其他适应症,这为重新利用该药物治疗肝纤维化创造了机会。这些结果将在即将发布的技术报告中详细说明。
4.7 人工智能合作科学家重现了抗菌素耐药性的突破
理解抗生素耐药性的机制对于研究人员开发有效的传染病治疗至关重要。我们专注于形成衣壳的噬菌体诱导染色体岛(cf-PICIs),它们在抗生素耐药性中起着关键作用。这些移动遗传元素与典型的噬菌体和其他PICIs不同,具有显著的在不同细菌种类间转移的能力,并携带毒力和抗生素耐药基因。我们寻求了解cf-PICIs在多种细菌物种中存在的进化理由,以制定对抗抗菌素耐药性的解决方案。
主要目标是利用人工智能合作科学家生成一个研究提案,旨在阐明导致cf-PICIs广泛宿主范围的细菌进化的分子机制,并制定策略来遏制抗生素耐药性的传播。我们特别关注观察到相同的cf-PICIs,如PICIEc1和PICIKp1,一种在临床相关的细菌物种中重新发现,包括世界卫生组织优先病原体如大肠杆菌和肺炎克雷伯菌。
在一项正在进行同行评审的研究中[75],该研究在一个领域内已建立的期刊上进行,基因组学和实验研究揭示了一种新机制,解释了为何相同的cf-PICIs能够在不同细菌物种中被找到。在了解这个问题的答案(但尚未公开可用)后,我们调查了合作科学家是否能够独立发现相同或类似的研究假设。我们向合作科学家提供了一份单页文档,其中包含了一般信息,包括关于噬菌体卫星的简要背景以及两篇相关研究文章。第一篇论文描述了cf-PICIs的最初发现[76],第二篇论文介绍了一种用于识别细菌基因组中噬菌体卫星的计算技术[77]。然后我们挑战合作科学家解释为什么cf-PICIs,而不是其他类型的PICIs或卫星,能够在多样的细菌物种中容易被找到,以及这一现象背后的机制是什么。
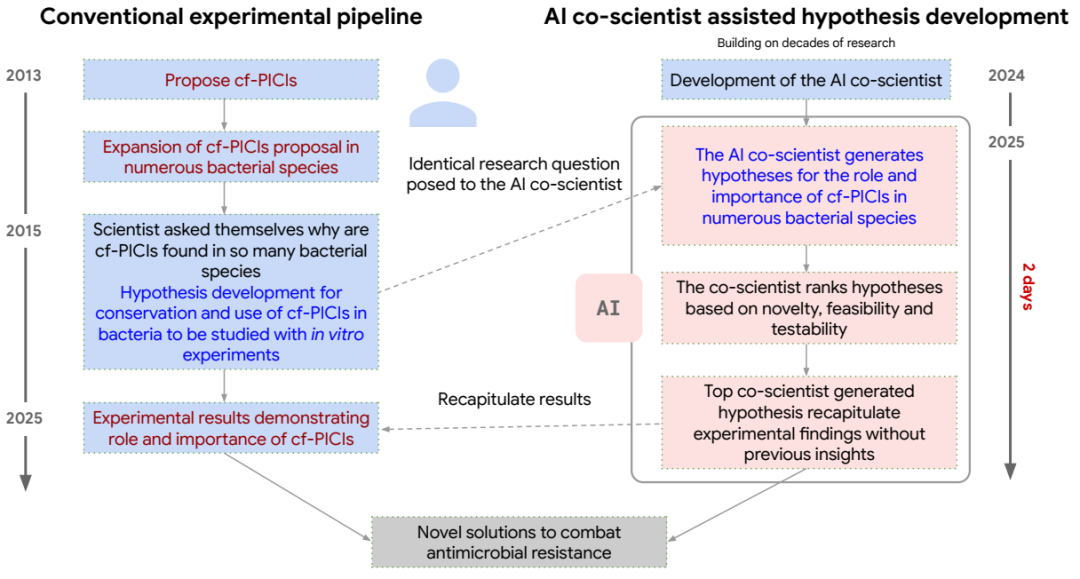
合作科学家独立且准确地提出了一个突破性的假设——cf-PICIs元素与多种噬菌体尾部相互作用以扩展其宿主范围——作为其排名第一的建议[21]。这一发现在独立的研究中得到了实验验证,而合作科学家在假设生成期间并不知道这项研究[20]。
值得注意的是,尽管合作科学家仅用两天就生成了这个假设,但它是建立在几十年的研究基础之上,并且可以获取关于此主题的所有先前开放获取文献。(图13)。具体来说,针对cf-PICIs的给定研究目标,合作科学家建议了以下研究课题:
衣壳-尾部相互作用。研究cf-PICI衣壳与各种辅助噬菌体尾部的相互作用。这一主题与被撤回手稿的主要发现完全一致:cf-PICIs与不同噬菌体的尾部相互作用以扩展其宿主范围,这一过程由cf-PICI编码的适配器和连接蛋白介导。
整合机制。检查cf-PICIs整合到各种细菌基因组中的机制。
进入机制。探索cf-PICI进入机制的替代途径,超越传统的噬菌体受体识别。
辅助噬菌体和环境因素。研究辅助噬菌体和更广泛的生态因素在cf-PICI转移中的作用。
替代转移和稳定机制。探索其他潜在的转移机制,如共轭、细胞外囊泡以及独特的稳定策略,这些可能有助于cf-PICI广泛的宿主范围。
常规方法和人工智能合作科学家的方法在同一新发现上的融合,强调了合作科学家增强、补充和加速科学事业的潜力(图13)。进一步的结果和详细内容可在伴随报告[21]中获取。
5 限制
我们对人工智能合作科学家评估的早期承诺感到鼓舞,这突显了其在增强科学研究方面的潜力。然而,该系统存在几个限制。负责任的创新需要慎重考虑这些因素以及可能对研究人员和科学研究产生的潜在影响。
文献搜索、综述和推理方面的限制。人工智能合作科学家系统进行的综述可能会因依赖开放获取文献而遗漏关键的前期工作。在展示的工作中,人工智能合作科学家由于遵守许可证或适用的访问限制,不会访问全部已发表的文献。系统还可能在错误推理某项工作不相关的情况下遗漏考虑前期工作。
缺乏获取负面结果数据的能力。人工智能合作者系统仅使用公开已发表的文献,这意味着它可能获取有限的负面实验结果或失败实验记录。众所周知,这类数据可能比正面结果更不常见,但从事该领域的经验丰富的科学家可能仍然拥有并利用这些知识来优先考虑研究[78]。克服这一现象的策略可能会进一步提高合作者作为科学发现工具的性能。
提升多模态推理和工具使用能力。科学出版物中一些最有趣的数据并非以文字形式撰写,而是可能以图形和图表的形式直观编码。然而,即使是最先进的前沿模型也可能无法以最佳推理全面利用这些数据[79],人工智能合作者系统也不太可能成为例外。需要更严格的基准测试和评估来提升这些能力。我们还没有评估我们的系统在推理和整合来自特定领域生物医学多模态数据集(如大型多组学数据集)和知识图谱的信息的能力。需要更多的工作来整合人工智能合作者系统与专门的科学工具、AI模型和数据库,并评估有效利用它们的能力。
需要更好的指标和更广泛的评估。当前的人工智能合作科学家评估包括AI自动评分、专家审查和有针对性的体外验证,但对系统性能的评估仍然是初步的。需要在不同的生物医学和科学学科中进行全面、系统的评估,以确定合作科学家的普遍适用性。此外,系统需要持续改进,以产生符合高质量出版物严格性和细节要求的输出。此外,用于帮助系统自我改进生成假设的Elo评级是一种有限的自动评估指标。继续研究其他更客观、较少内在偏好的评估指标,这些指标能更好地代表专家科学家的观点和偏好,可能会加强未来的工作。
前沿大型语言模型(LLM)的固有局限。LLM的局限性包括不完美的事实性和幻觉,这些可能会在合作科学家系统中传播。系统依赖现有的LLM和网络搜索,虽然能够立即获取广泛的知识,但也可能传播那些资源中存在的准确性错误、偏见或限制。
6 安全和伦理影响
尽管像合作科学家这样的人工智能系统提供了加速科学发现的潜力,但它也带来了重大的安全和伦理挑战,这些挑战与其对科学方法本身的影响是不同的。安全风险集中在双重用途上,以及科学突破可能被用于有害目的的可能性。相反,伦理风险涉及的研究与特定科学学科内既定的伦理规范和惯例相矛盾。我们审查这些不同的风险类别,强调进一步研究对全面理解和减轻它们至关重要。
随着伦理框架的发展,针对高级AI在科学事业中的使用,政策和法规也在不断演变。研究伦理是科学事业的一个核心方面,本身也是一个突出的研究领域[80-85]。一个关键重点是引导研究产生积极的社会影响,尽管关于潜在的双重用途知识仍有疑问[86-90]。
核心伦理原则正被新兴的法规所补充,涉及组织伦理审查的正式程序旨在评估遵守行为准则的情况,以及对研究提案目前和未来风险的评估[91-94]。
通过AI加速科学进步,特别是具有高级代理能力的AI系统,需要科学和AI伦理方面的政策和法规取得进展[95, 96]。这种适应对于应对变化的研究格局以及与不同能力和自主性的AI代理相关的独特风险至关重要。
AI系统的进步,如共同科学家,需要超越为早期、专门化的AI模型设计的有限伦理考量,这些模型的适用范围和行动空间受限[97]。已发展出一些初步框架,以理解大型语言模型(LLM)代理在科学领域的影响,特别是映射用户意图、领域和更广泛影响的风险[98]。
双重用途风险和技术保障措施。除了科学领域之外,正在开发广泛的框架,用于评估人工智能代理可能产生危险能力的情况[99-101]。这些框架评估与说服、欺骗、网络安全、自我增殖和自我推理相关的能力。随着人工智能代理的进步,科学领域的安全评估必须整合这些更广泛的评估。一个长期风险是代理系统可能会发展出影响研究方向的内在目标。人类对人工智能操纵的易感性已在其他情境中观察到[102],这突显了需要健全框架以确保遵循指令和价值一致性。
在更短的时间尺度上,需要技术保障措施来解决不道德的研究查询、恶意用户意图以及从科学人工智能系统中提取危险或双重用途知识的可能性。因为验证在计算上比生成更为“简单”,大量研究聚焦于使用先进的大型语言模型作为“评论家”或“裁判”来评估用户查询和作为可扩展监督机制的人工智能输出。这些评论家基于预定义标准进行操作,通过直接指令、示例(少样本或多样本提示)或微调提供[103-108]。它们还可以利用外部工具进行基础定位[109],并在多模态场景中显示出潜力[110]。然而,仍然存在限制;人类专家的参与至关重要,因为大型语言模型(LLMs)在专业领域可能与人类判断不一致[111]。
科学人工智能系统的对抗鲁棒性。识别和减轻对抗攻击是基础模型和高级人工智能助理发展的一个关键且持续的研究领域[75, 112-118]。虽然手动红队已经发现了漏洞,但自动化方法现在允许优化提示后缀以绕过安全措施,使用贪婪、基于梯度或进化方法等技术[119, 120]。攻击还可以利用少样本演示、上下文学习[121, 122]和多模态输入[123]。此外,大型语言模型可以用来生成和完善针对其他大型语言模型的攻击[124],并且攻击可以是迭代的,跨越多个步骤[125]。正在开发防御措施来对抗人类和自动化攻击,这在代理人工智能的未来越来越重要[126]。
基础模型训练后进步的改进可能会提高整体对抗鲁棒性。然而,对恶意使用的特定领域识别可能仍需要专门的开发和整合到科学人工智能助理中。在采用迭代推理的人工智能系统中(例如,请求解释、假设生成、内心想法、评估、用户查询),每个组件必须独立测试。这种全面的测试应考虑所有潜在的失败模式,包括对不安全情况的处理查询、假设(中间和最终)的安全性以及内部检查和过滤器的准确性。
需要全面的安全方法。科学AI助手,如同合作科学家一样,需要在他们的保护措施中集成可配置的指导方针。开发者应预见这一挑战的复杂性,并优先考虑灵活的保护措施,以快速纳入社区反馈。这些语义保护措施可能需要通过传统的软件安全措施来加强,包括可信测试员、逐步推出功能、访问控制、请求记录以及对不确定输出进行手动审查的标志。
确保这些系统的安全性,与现有的AI安全指南一致[127, 128],需要采取多方面的方法。这包括:
进行全面的威胁建模,以识别潜在的漏洞。
针对每个已识别威胁的防御机制。
广泛的团队对抗和安全测试。
快速响应程序,以便快速解决问题,包括漏洞补丁。
持续监控和性能跟踪。
这些考虑强调了负责任的开发、治理以及谨慎部署旨在推进科学的技术、适当的安全措施和道德准则,并严格遵守适用的法规。它们还进一步强调了广泛社区参与的重要性,以及围绕科学中AI的安全和伦理使用的最佳实践和建议的包容性发展。
AI合作科学家中的当前保护措施。为了降低这些风险,人工智能合作科学家目前采用以下安全机制:
依赖公共前沿大型语言模型。系统使用已经纳入广泛安全评估和保障措施的既定公共Gemini 2.0模型。
初始研究目标安全审查。输入后,每个研究目标都会经过自动化安全评估。被认为可能不安全的目标会被拒绝。
研究假设安全审查。即使总体研究目标被认为是安全的,生成的假设也会经过安全性审查。潜在不安全的假设会被排除在竞赛之外,不再进一步发展,也不会呈现给用户。
持续监控研究方向。一个元审查代理提供研究方向的概览,使人工智能合作科学家能够持续监控潜在的安全问题,并在检测到某个研究方向可能不安全时向用户发出警报。
可解释性和透明度。所有系统组件,包括安全审查,不仅提供最终建议,还提供详细的推理轨迹,可用于证明和审计系统决策。
全面记录。所有系统活动都会被记录并存储以供未来分析和审计。
安全评估和红队演练。已经进行了初步的红队演练工作,以确保当前不安全研究目标检测的实现既健壮又准确。此评估包括在第4.4节讨论的40个不同主题领域中,面对1200个对抗性研究目标时系统行为的评估。
可信测试员计划。我们对AI合作科学家的早期前景感到兴奋,并相信在科学和生物医学的许多其他领域中更严格地了解其优势和局限性很重要;同时让更多的研究人员能够使用这个旨在支持和协助他们的系统。为了负责任且严谨地促进这一点,我们将通过可信测试员计划使科学家能够访问该系统,以收集关于系统实用性和稳健性的现实世界反馈。
至关重要的是,AI合作科学家旨在在持续的人类专家监督下运行,确保最终决策始终由行使其专业判断的科学家做出。
7 未来工作
立即改进。AI合作科学家处于早期开发阶段,有许多改进机会。立即改进的机会包括加强文献综述、与外部工具交叉核对、改进事实性检查以及提高引用召回率,以尽量减少错过相关研究。一致性检查也将通过减轻审查有缺陷假设的负担来改进系统。
扩展评估。开发更客观的评估指标,可能包括自动化基于文献的验证和模拟实验,是关键领域。减轻从基础大型语言模型继承的偏见或错误模式的方法也很重要,与此同时,分析不同代理组件的互补性和最佳组合也很重要。
一个关键需求是更大规模的评估,涉及更多具有多样化、高分辨率研究目标的主题领域专家。在每一个分辨率层面(从疾病机制到蛋白质设计,并扩展到其他科学学科)对系统进行压力测试将揭示进一步改进的领域。最后,由于实验室资源有限,改进的评估框架可以协助假设选择。
能力进步。仍有几个机会扩展合作科学家的能力。强化学习可以增强假设排名、提案生成和进化精炼。
目前,该系统评估来自开放获取出版物的文本,但不评估图像、数据集或主要公共数据库。整合这些公开可用资源将显著提升合作科学家生成和证明所提出假设的能力。
未来的工作将集中于处理更复杂的实验设计,如多步骤实验以及涉及条件逻辑的实验。将合作科学家与实验室自动化系统集成,有可能创建一个闭环验证和一个迭代的改进基础。探索更结构化的用户界面,以提供来自针对性用户研究的反馈和见解,而不仅仅是自由文本,可以提高这种范式中人机协作的效率。
8 讨论
我们的研究代表了利用代理人工智能系统加速新科学发现的初步尝试,在此,我们讨论一些更广泛的影响。共同科学家通过“生成、辩论、进化”的方法与底层的专门代理迭代地完善其生成的假设。这一设计创建了一个自我改进的研究假设生成循环,通过自动化评估指标进行衡量,并展示了测试时计算扩展对科学推理的潜在好处。
对新共同科学家假设的多重实验验证。更重要的是,这项工作通过多个实验室的实验发现验证了共同科学家的假设。在药物再利用方面,共同科学家识别出在临床相关浓度下表现出体外有效性的AML(急性髓性白血病)的新候选药物,包括超出当前临床前知识的新再利用机会。对于肝纤维化,共同科学家提出了新的表观遗传治疗靶点,随后的体外实验验证了几种建议化合物的抗纤维化活性,其中包括一种FDA批准的药物。在抗微生物耐药性领域,该合作科学家独立复现了一个关于细菌物种间cf-PICI传递机制的新颖、未发表的发现。早期对几个不同科学复杂度的查询结果显示,该合作科学家具有为各种生物医学领域的发现做出贡献的潜力。
测试时间计算扩展了科学推理先验和归纳偏见。在这里报告的实验中,合作科学家不需要专门的前期训练、后期训练或强化学习框架。它利用现有基础大型语言模型的能力,可能从这些模型的更新中受益,而无需重新训练合作科学家系统本身,这展现了计算效率和泛化性的优势。系统的架构包含了自我对弈、内部一致性检查和基于比赛的排名,这些支持迭代假设生成、评估和完善。这反映在随时间观察到的假设质量提升上。通过扩展工具使用的整合,包括数据库查询,可以进一步改善这种自我进化,使合作科学家能够将其提议建立在现有知识之上,并识别新的联系。将来,我们可能会利用合作科学家自身生成的数据和比赛排名作为反馈,使用强化学习来改进整个系统。
前沿大型语言模型进展与人工智能合作科学家。在共同科学家系统内使用的前沿大型语言模型(LLMs)已经显示出持续快速提升的能力,包括推理、逻辑以及科学文献理解的一些方面。由于我们的系统设计为模型无关的,我们假设前沿LLMs的进一步改进也将提升共同科学家的表现,并开启新的研究方向,包括工具的最优代理使用。
对药物再利用和发现的启示。这些进步对于各种生物医学和科学领域具有重大意义。例如,将共同科学家整合进药物候选选择过程代表了基于证据的药物再利用的重大进展。除了简单的文献挖掘外,共同科学家可能能够通过连接分子途径、现有的临床前证据和潜在的治疗应用来合成新颖的机制见解,形成结构化的、可检验的具体目标。这种能力特别有价值,因为它为研究人员提供了文献支持的理由,并建议了具体的实验方法用于验证。值得注意的是,共同科学家的结构化输出可以被利用来开发全面的单一患者IND(研究性新药)申请,用于同情用药案例。通过系统地呈现机制证据、相关的临床前数据和提议的监测参数,共同科学家促进了 为那些已用尽标准治疗选项且不适合参加临床试验的难治(治疗抵抗)病患制定合理的治疗方案。该申请在罕见或侵袭性疾病中特别有价值,因为传统的药物开发时间表可能与患者的紧急需求不一致。该平台能够迅速生成基于证据的治疗假设,包括安全性考量和监测参数,可以帮助临床医生和监管机构在保持科学严谨性的同时,就同情用药申请做出明智决策。
共同科学家在药物再利用方面的应用为孤儿药提供了一个非常引人注目的机会,因为这些药物在其原始罕见病适应症方面已经存在广泛的安全性和临床数据。鉴于第三阶段临床试验可能耗资数亿美元,再利用这些特征明确的治疗药物为扩展多种疾病的治疗选择提供了一条高效途径。这在孤儿药常常针对在其他疾病中也可能相关的根本生物途径时尤其相关,但通过传统研究方法可能不会立即显现出这些联系。通过系统地评估现有的临床数据、安全结果和机制见解,共同科学家可以帮助识别有前景的新治疗应用,同时利用已在药物开发和安全性验证方面的投资。这种方法不仅最大化了现有疗法的效用,还为解决更广泛患者群体中未满足的医疗需求提供了更快速的途径。
更广泛地说,共同科学家在整个药物发现领域也可能具有潜在影响力,正如早期关于共同科学家辅助肝纤维化靶点发现的工作所证实的。
自动化偏见及其对人类科学创造力的影响。要在生物医学和科学领域充分发挥人工智能的潜力,需要主动应对潜在的陷阱。过度依赖协作式人工智能系统中的AI生成建议可能会削弱批判性思维,并增加研究的同质性。关于人工智能对创造力和创意影响的研究显示结果不一;一些研究表明存在跨人群思想同质化的风险[129],而其他研究则不那么确定[130]。由于训练数据相似,大型语言模型(LLMs)的相关成功/失败模式[131]也可能人为地缩小科学探究范围。此外,必须考虑AI系统的盲点和研究领域的性能变化。因此,可扩展的事实性和验证方法,加上同行评审和对潜在偏见的仔细考虑,至关重要。仔细设计和使用共同科学家之类的系统对于减轻这些风险至关重要。
人工智能作为科学发现和公平性的催化剂。尽管存在这些风险,人工智能具有巨大的潜力,可以促进科学信息的获取并使发现加速,特别是有利于历史上被忽视和资源受限的领域[132, 133]。本质上,人工智能能够“提升科学进步之潮”,让所有船只受益,尤其是那些历史上被落下的船只。要实现这一潜力,需要进行战略性的投资,并仔细校准人工智能系统,以促进创意和创新,同时尽量减少误报。这包括关注历史上被忽视的研究主题,并解决不同科学领域中因预先存在数据量不同而产生的性能差异。虽然当前的人工智能系统可能倾向于产生增量想法和研究假设,但正在进行的开发旨在创建能够生成真正原创、非传统且具有变革性的科学理论的系统。
积极缓解这些挑战将确保人工智能成为所有科学家的强大工具,促进科学探索的更公平和创新的未来。
9 结论
人工智能合作科学家代表了朝着人工智能辅助增强科学家和促进科学发现加速的有希望的一步。它在不同的科学和生物医学领域生成新颖的可测试假设的能力,其中一些得到实验结果的支持,再加上随着计算能力的增强而进行递归自我改进的能力,展示了其意义重大的潜力加速科学家解决人类健康、医学和科学领域重大挑战的努力。这一创新开启了众多问题和机遇。将科学的经验和负责任的方法应用于人工智能合作者系统本身,从而能够安全地探索其无疑的潜力,包括协作式和人本中心的人工智能系统可能如何增强人类的创造力并加速科学发现。



内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢