分子设计Molecular design,利用数据驱动的生成模型,已经成为一种很有前景的技术,影响着药物发现和功能材料开发等各个领域。
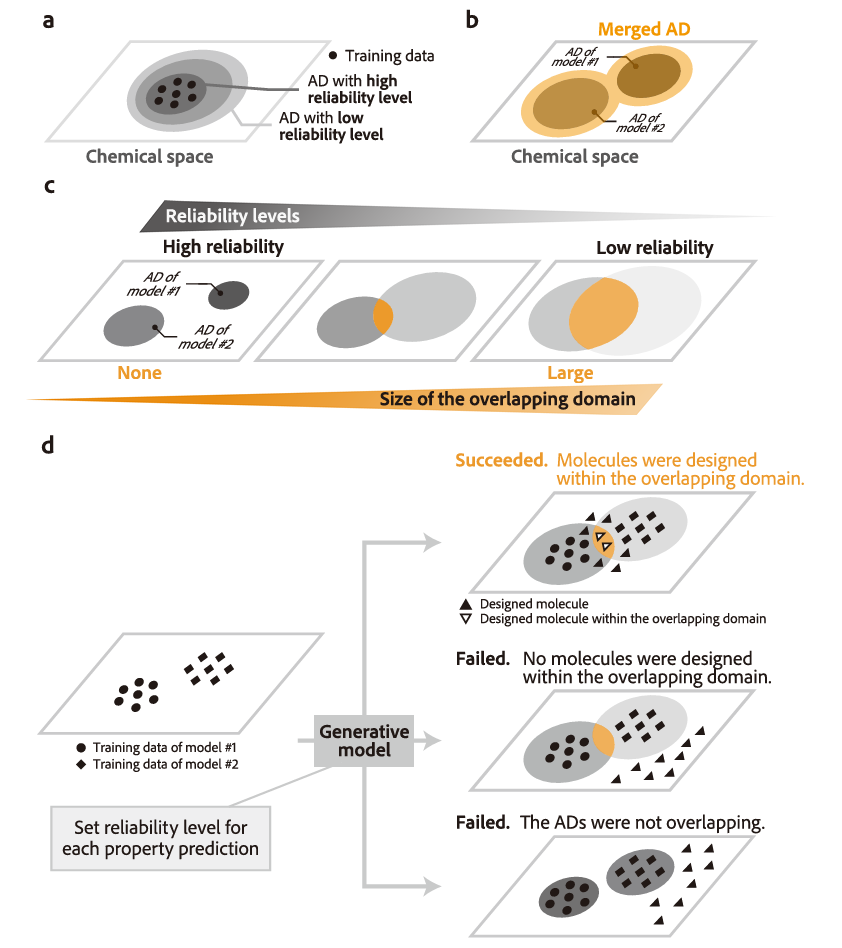
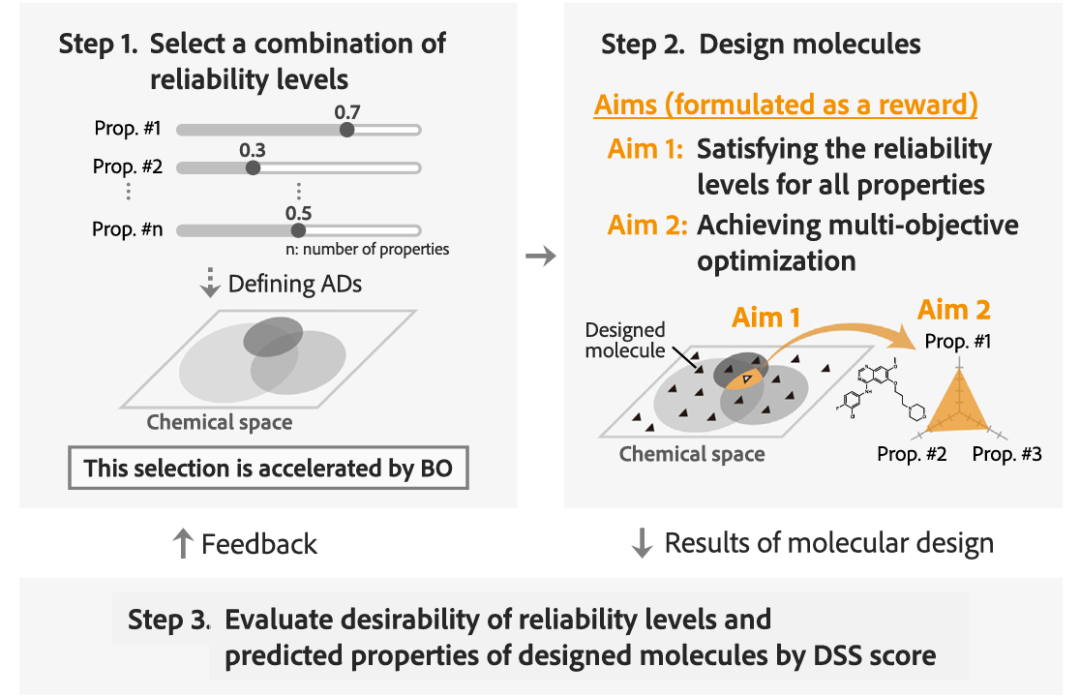
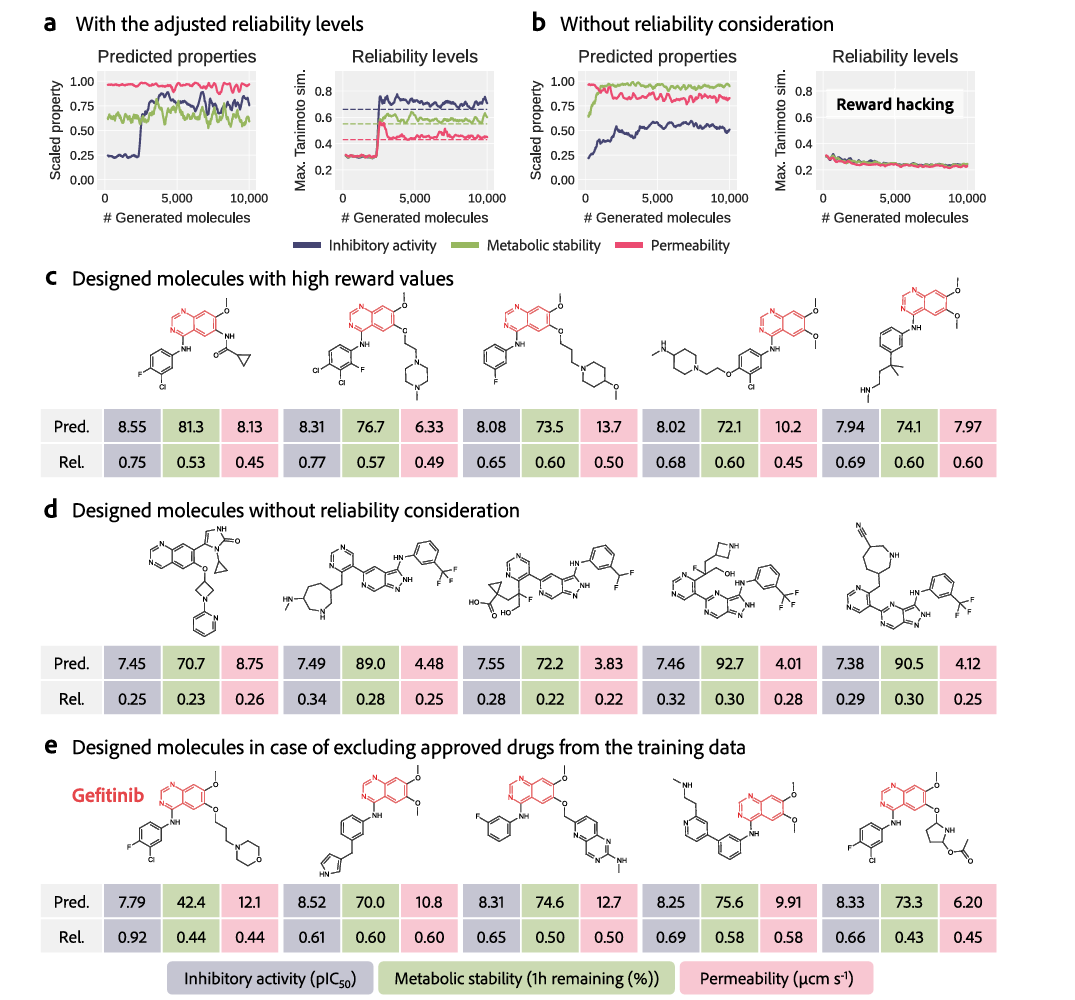
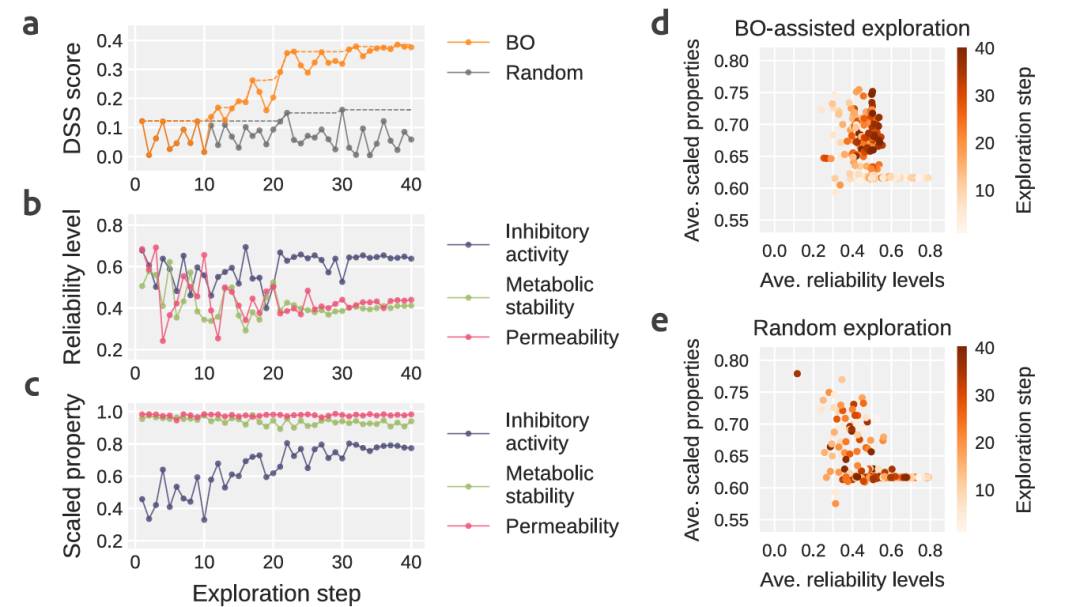
然而,分子设计方法,通常由于奖励欺骗reward hacking(是指强化学习智能体,通过利用奖励函数中的漏洞或模糊性,获得高奖励,但没有真正学习或完成预期任务的现象),从而易受优化不利的影响,其中预测模型不能外推,即不能准确地预测显著偏离训练数据的设计分子的性质。虽然用于估计预测可靠性的方法,例如适用域Applicability Domain, AD(基于化学空间相似性估计不确定性,方法简单但对复杂数据分布敏感),已被用于减轻奖励欺骗,但多目标优化,仍具有挑战性。这些困难主要是因为,需要预先确定具有某些可靠性水平的多个适用域AD,是否在化学空间中重叠,并且需要适当地调整每个性质预测的可靠性水平。今日,日本横滨市立大学(Yokohama City University)Tatsuya Yoshizawa, Kei Terayama等,在Nature Communications上发文,提出了一种可靠的设计框架,以生成模型执行多目标优化,同时防止奖励欺骗。为了证明框架的有效性,设计了抗癌药物的候选者作为多目标优化的典型例子。成功地设计了具有高预测值和可靠性的分子,包括一种已获批准的药物。可以根据用户指定的属性优先级,自动调整可靠性级别,而无需任何详细设置。A data-driven generative strategy to avoid reward hacking in multi-objective molecular design.
在多目标分子设计中,避免奖励欺骗的数据驱动生成策略。
图1:适用域AD概念和包含多个AD的多目标优化困难。
图2:DyRAMO(多目标优化的动态可靠性调整)的工作流程。
图3:使用DyRAMO分子设计结果。
图4:在DyRAMO(多目标优化的动态可靠性调整)中,通过贝叶斯优化(BO)和随机探索,调整可靠性水平的过程。
图5:优先级对可靠性水平调整的影响。
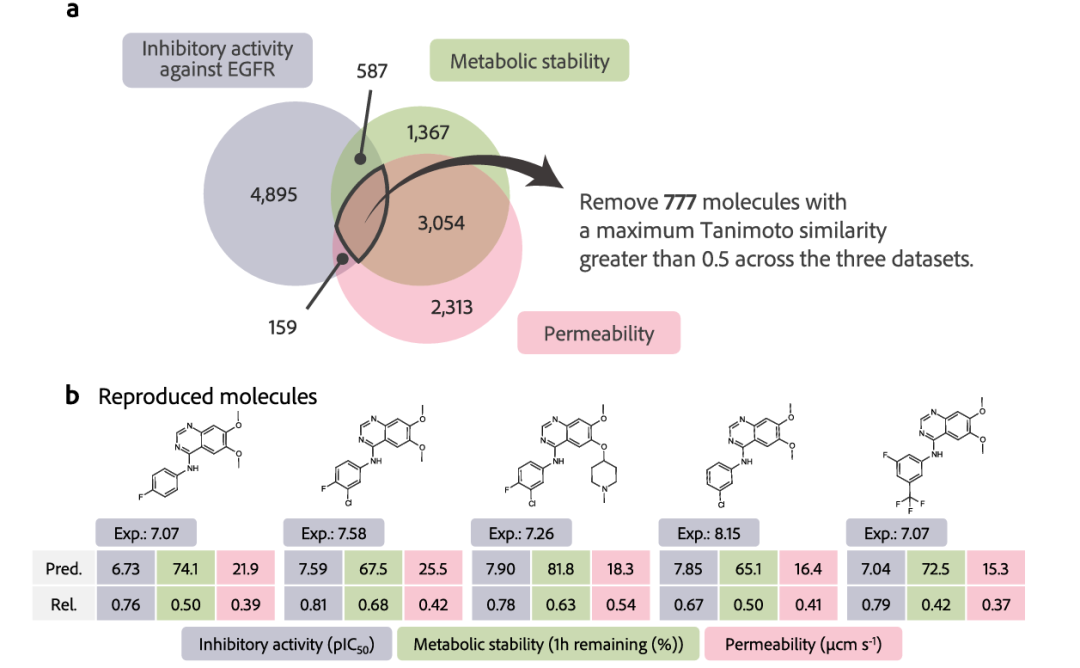
图6:跨数据集的相似分子移除以及在移除的分子中,重新发现的实例。
Yoshizawa, T., Ishida, S., Sato, T. et al. A data-driven generative strategy to avoid reward hacking in multi-objective molecular design. Nat Commun 16, 2409 (2025). https://doi.org/10.1038/s41467-025-57582-3声明:仅代表译者观点,如有不科学之处,请在下方留言指正!
内容中包含的图片若涉及版权问题,请及时与我们联系删除




评论
沙发等你来抢