
梦晨 发自 凹非寺
量子位 | 公众号 QbitAI
谷歌推出Gemini原生图像生成,测试版瞬间引爆网络。
如果你迟到了,但没有好的借口,甚至还没有出家门——只需要一张自拍,然后让AI把你P到地铁故障现场。

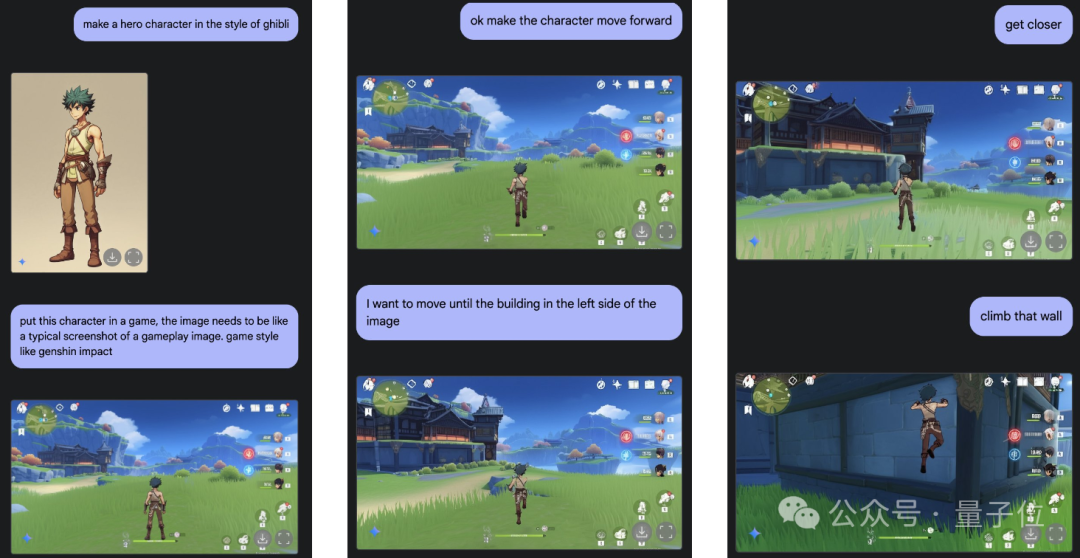
也可以凭空生成一个人物形象,把它放到原神游戏画面中(不用上传游戏截图),让角色往前走两步,再把视角往左移,走近一个建筑,开始爬墙。
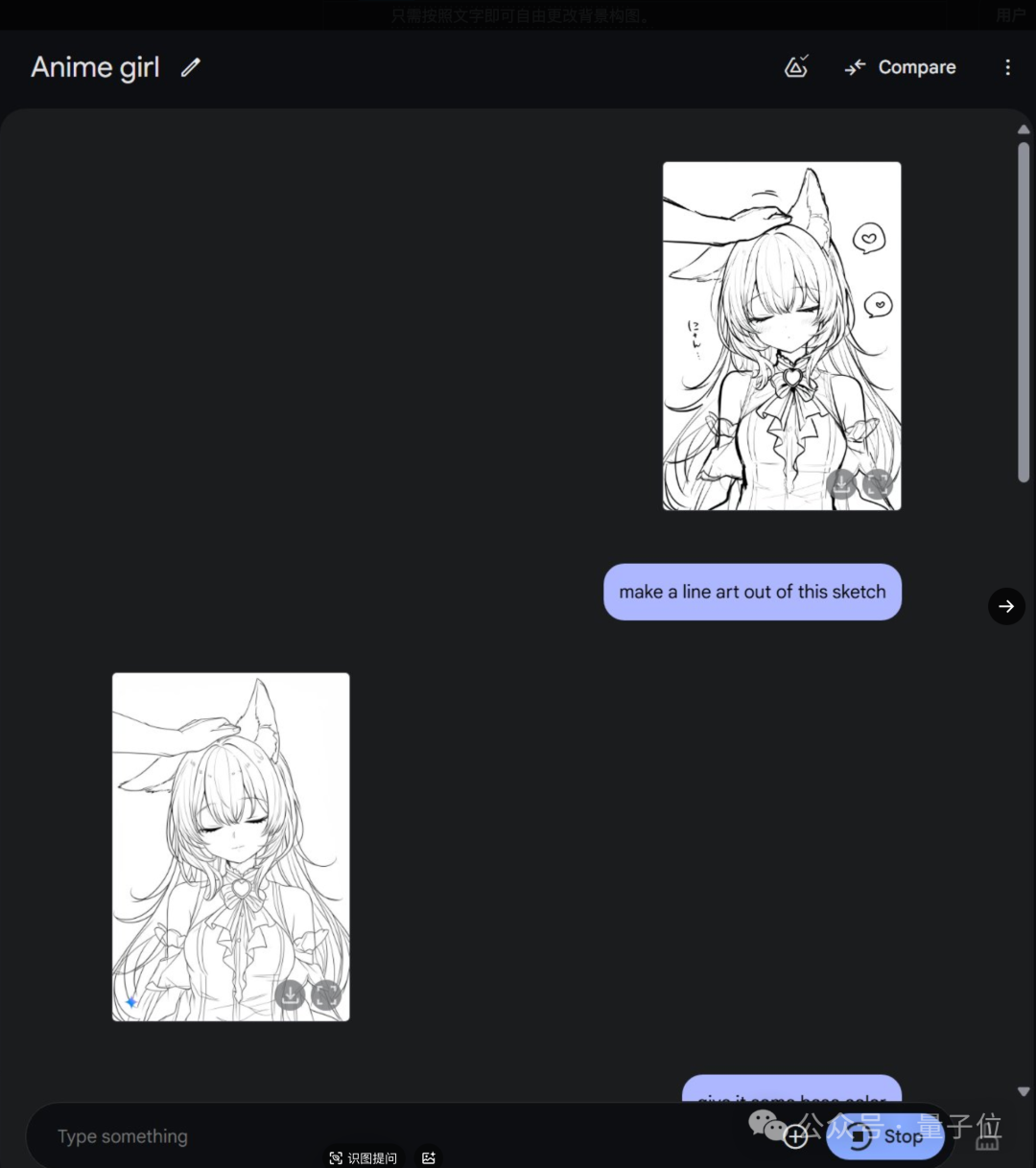
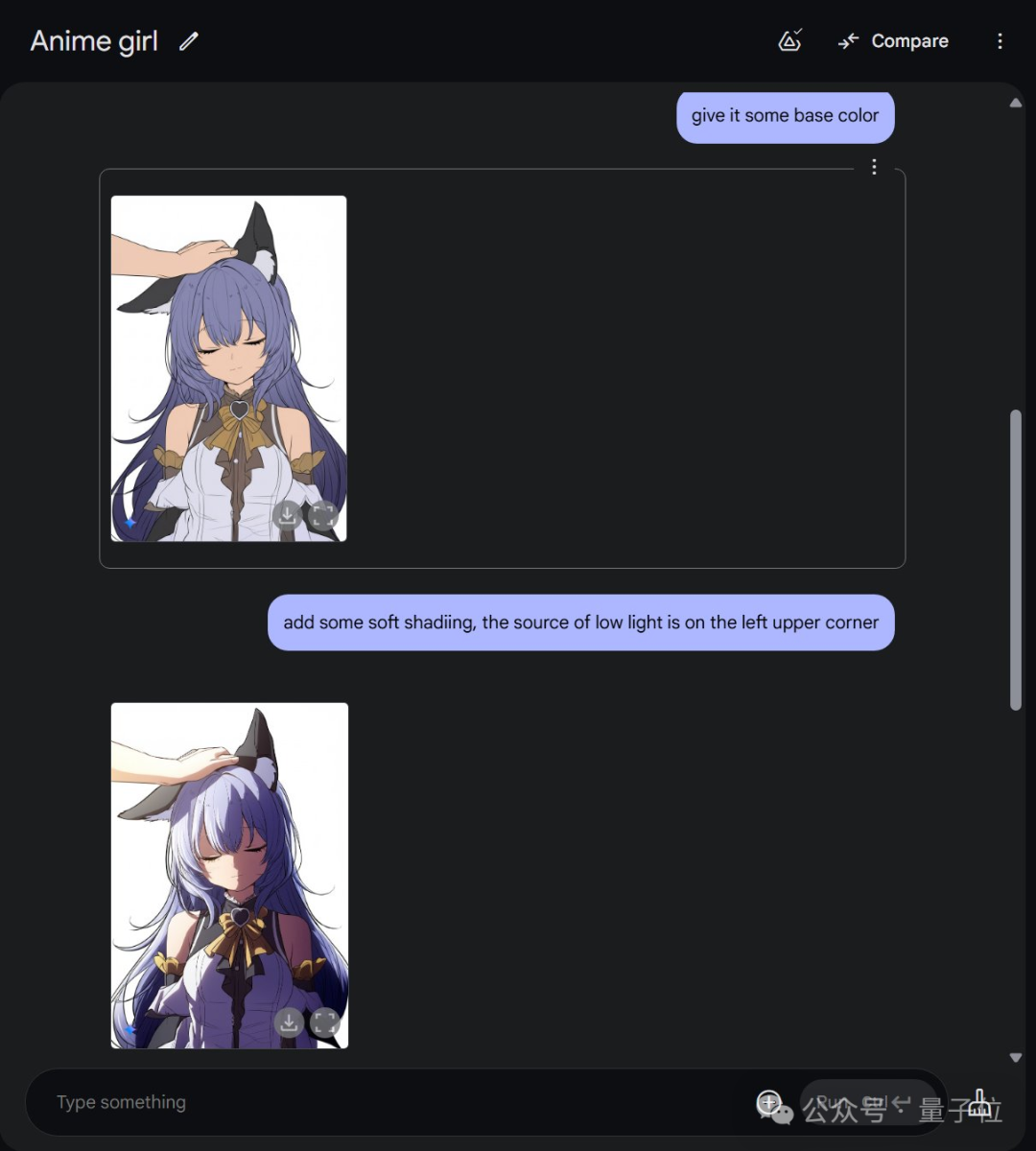
二次元选手最喜欢的玩法,是草稿一句话变线稿,再上色,再上阴影等操作,注意每一步执行后人物形象都是保持一致的。
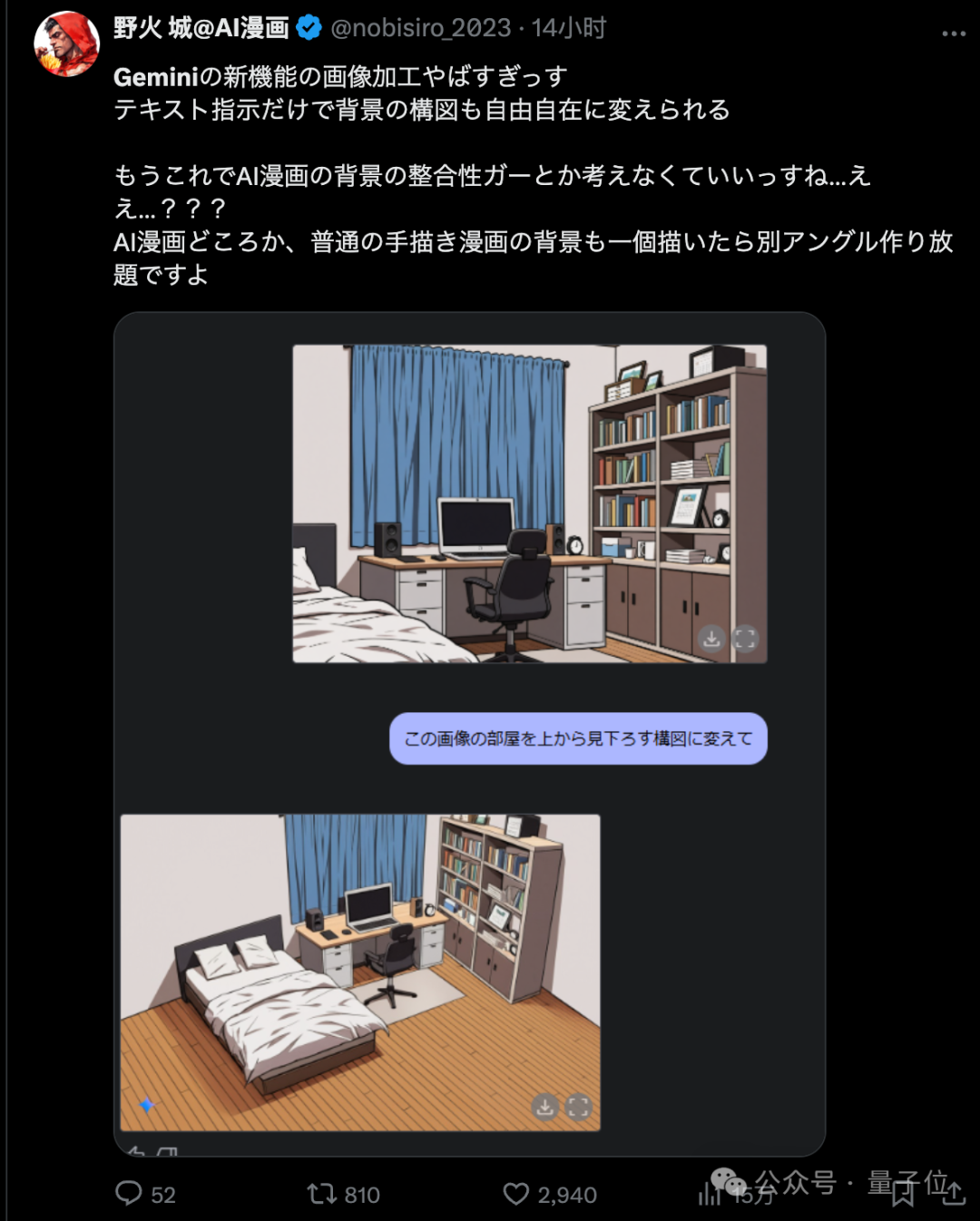
有漫画创作者用它来改变构图视角,同时保持画面内容的一致性。
游戏开发者则可以用一些素材组件自动拼成关卡场景。
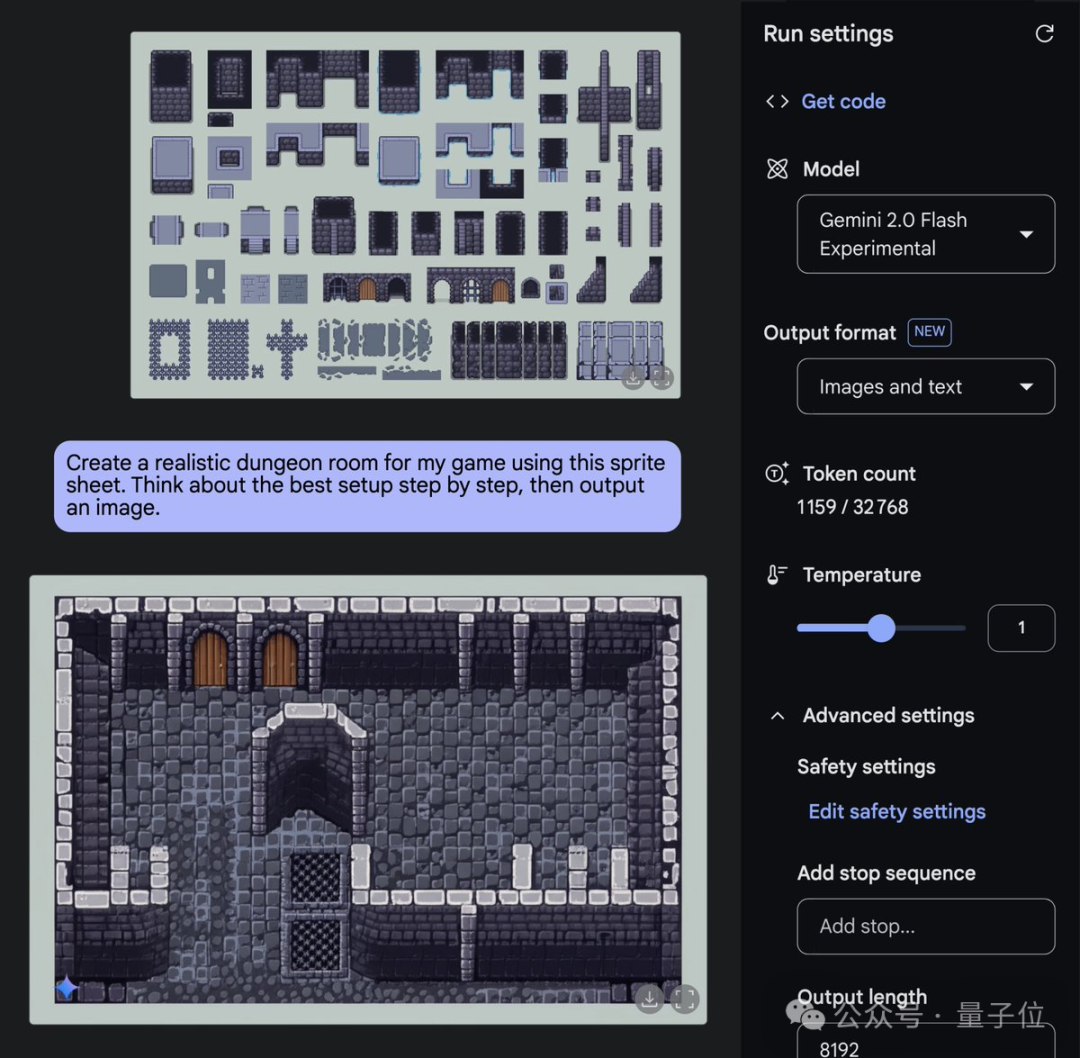
除了精准遵循指令一键P图之外,还支持图文混排输出。
谷歌官方演示了生成菜谱,每个操作步骤都配上写实的图像,学起来更直观。
现在,这些功能都可以在Google AI Studio免费试玩。
模型命名很乱,请认准Gemini 2.0 Flash Experimental。
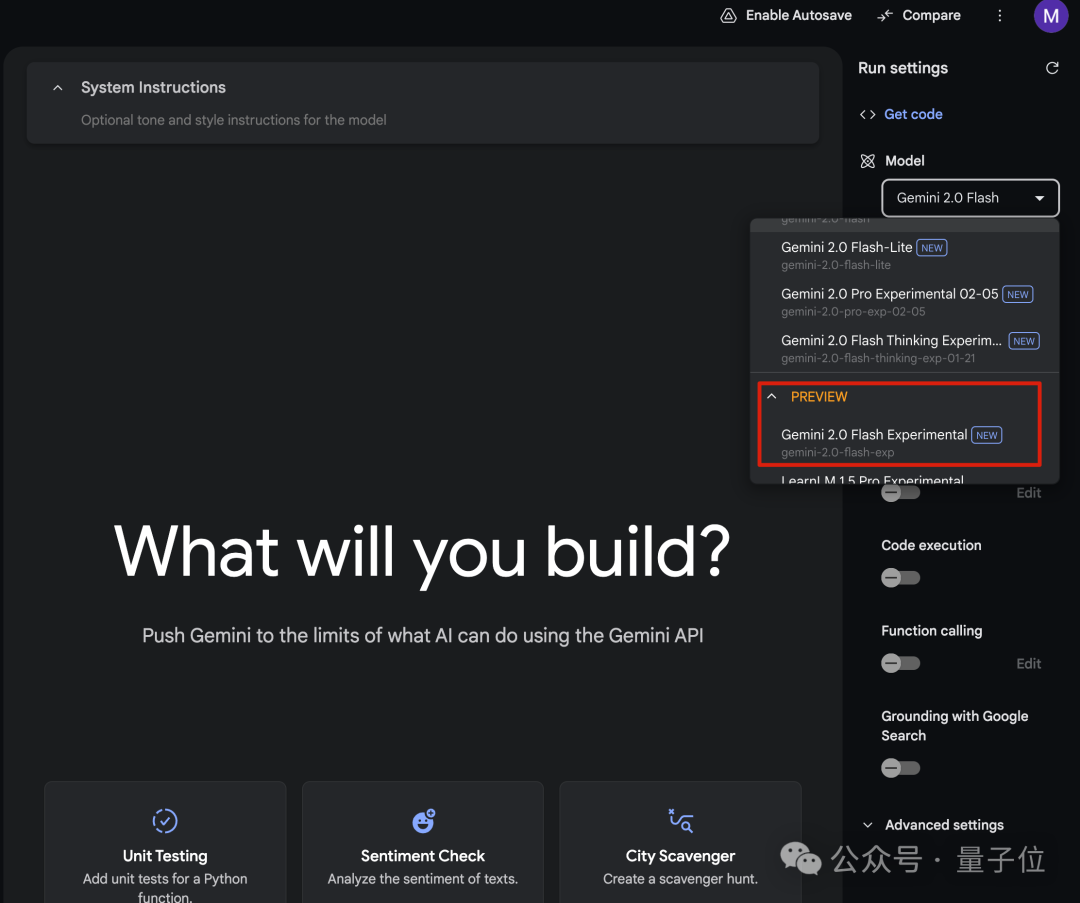
原生图像输出首次开放
目前Gemini 2.0 Flash原生图像输出能力还没有公开技术细节,简短的介绍中只讲了“结合多模态输入、增强推理和自然语言理解”。
而其他AI产品语言大多是语言模型把图像生成模型当做工具去调用,如ChatGPT调用Dall·E 3,Grok调用flux.1。
新范式下,Gemini 2.0 Flash的主要优势包括:
图文故事模式:始终保持人物和场景的一致性。也可以中途提意见,让AI重新讲述故事或改变绘画风格。
对话式图像编辑:支持多轮编辑,可以一句话p图,反复完善图像,实现实时协作和创意探索。
基于世界知识的图像生成:利用大模型内置的知识和推理能力,生成与上下文更相关的图像
改进文本渲染:减少拼写错误或字符扭曲,适合生成广告、甚至邀请函。
其实早在2024年5月,OpenAI总裁Brockman就曾展示过GPT-4o的这种原生多模态能力,但后来就没了消息。
现在谷歌抢先部署这项功能,让网友不禁好奇,出于什么原因让OpenAI放弃一年以上的领先优势。

OpenAI员工也只能感叹,谷歌真的回来了。

还有隐藏玩法
除常规玩法之外,还有网友探索出了一种隐藏玩法:用文字提问,要求AI只用图片回答。
他的问题是“生命的意义是什么”,AI用一系列图片来表达,画面逐渐诡异起来,令人毛骨悚然。
他把整个过程录制成视频,下面一起来看看。
在线试玩
https://aistudio.google.com/
参考链接:
[1]https://developers.googleblog.com/en/experiment-with-gemini-20-flash-native-image-generation/
[2]https://x.com/goodside/status/1900349595718148455
[3]https://x.com/ilumine_ai/status/1900017235898622025
[4]https://x.com/nobisiro_2023/status/1900150873734733859
[5]https://x.com/linaqruf_/status/1899977818563633466
[6]https://x.com/scaling01/status/1899932304388051216
— 完 —
评选报名|2025年值得关注的AIGC企业&产品
下一个AI“国产之光”将会是谁?
本次评选结果将于4月中国AIGC产业峰会上公布,欢迎参与!

一键关注 👇 点亮星标
科技前沿进展每日见
一键三连「点赞」「转发」「小心心」
欢迎在评论区留下你的想法!
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢