

新智元报道
【新智元导读】LLM自身有望在无限长token下检索信息!无需训练,在检索任务「大海捞针」(Needle-in-a-Haystack)测试中,新方法InfiniRetri让有效上下文token长度从32K扩展至1000+K,让7B模型比肩72B模型。


创新性提出「注意力分配与检索增强对齐」概念,并成功利用这一特性提升LLM处理长文本的能力。 无需额外训练,InfiniRetri可直接应用于任何基于Transformer的LLM,使其具备处理无限长上下文的能力。 不同于RAG依赖外部嵌入模型,提出了「注意力中的检索」这一新颖视角,充分利用LLM内在能力增强长文本处理能力。 显著降低推理延迟和计算开销,在大规模数据集上的检索与问答任务中表现优异,展现出在极长文本处理场景中的实际应用价值。 不仅仅是扩展上下文窗口,证明了可以通过多种方式提升LLM处理长文本能力。未来的改进可通过在较小上下文窗口内增强模型内部能力,从而获得更优的长文本处理效果。
这是第一个问题,答案是不能,有3大原因:
增加计算成本,产生明显的延迟。 输入长度具有长尾效应,简单地扩展上下文窗口带来的提升注定会带来越来越低。 持续和阶段性训练成本极高,绝大多数研究人员无法承受。
接下来,进一步考虑第二个问题:要打破处理长上下文时不同窗口之间的信息壁垒,是否存在一种低成本的方法?
事实上,业界已经通过检索增强生成(Retrieval-Augmented Generation,RAG)提供了答案。
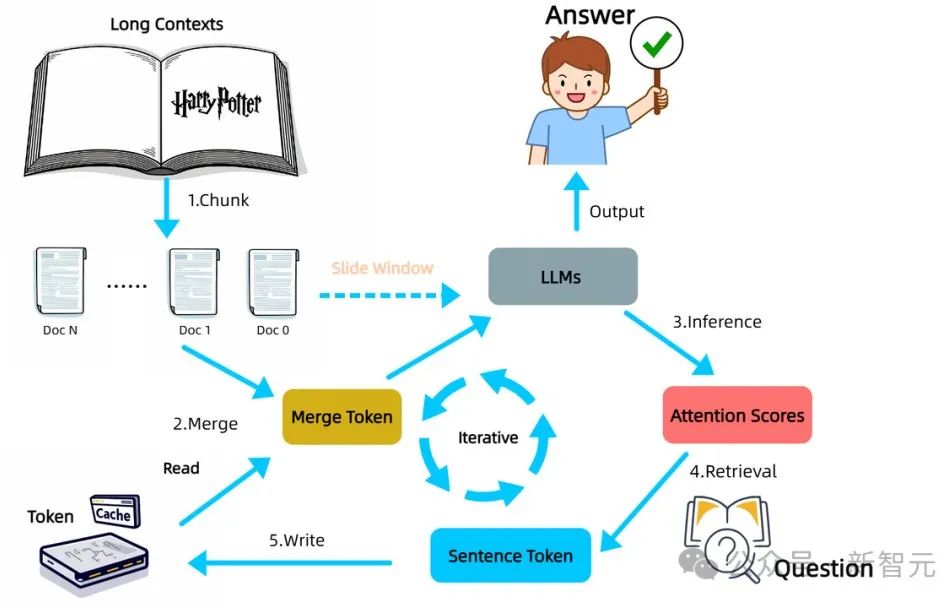
步骤1(切分,Chunk)、步骤2(合并,Merge)和步骤3(推理,Inference)。 步骤4(检索,Retrieval)是方法的核心部分。 步骤5(缓存,Cache)。
文本分割
新方法受到人类阅读书籍过程的启发,专门针对LLM在处理超出上下文窗口的文本时所面临的挑战。 尽管人类的视野有限,一次只能看到一页内容,但仍然可以逐页阅读并理解整本书。在这个过程中,大脑就像一个缓存(cache),通过记忆保留并整合每一页的信息,从而掌握整本书的内容。 类似地,InfiniRetri将整篇文本拆分为连续的文本块(chunk)。 这种切分方式虽然与RAG相似,但不同之处在于,InfiniRetri不是并行处理每个文本块,而是按照顺序逐块迭代地处理每个文档。 这种方法能够保留文本的顺序信息,更符合人类的阅读习惯。 具体而言,如图4所示,在步骤1(切分,Chunk)中,研究团队根据句子边界将整个长文本划分为长度大致相等的文档块,其长度由方法参数ChunkSize³决定。 然后,这些文档块依次与缓存(Cache)中保留的token进行合并,形成完整的输入序列,称为MergeToken,并将其输入LLM进行处理。 InfiniRetri采用了类似滑动窗口注意力(Slide Window Attention,SWA)的迭代方式,按顺序处理每个文本片段。 然而,InfiniRetri对缓存的处理方式与传统方法有本质区别。 传统缓存通常在每一层存储过去的键值(Key-Value)状态,而新方法则重新定义了缓存概念,改为存储过去的token ID。 如图4,步骤2(合并,Merge)所示,新方法在输入LLM之前,将缓存的token ID与当前文本片段的token进行合并,从而取代了推理过程中对历史键值状态的合并需求。 因此,在步骤3(推理,Inference)阶段,LLM仍然使用标准注意力机制,而非SWA。对于第h层的注意力得分,其计算公式如下:
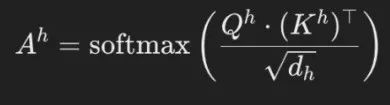
其中,A^h∈R^{n×m}表示查询(query)和键(key)组成的注意力矩阵,n是查询的数量,m是键的数量。
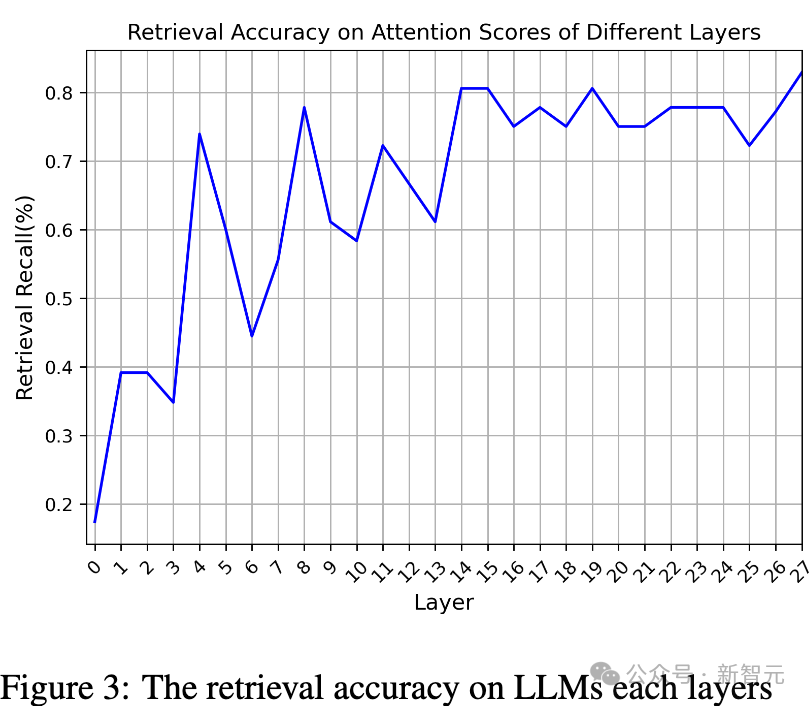
在注意力中检索(Retrieval In Attention)
在单个上下文窗口内,根据问题token准确定位相关的上下文token,注意力分配模式能够帮助LLM找到正确答案。 如果在滑动窗口框架内的每次推理过程中持续应用这一模式,理论上,LLM就可以在保持查询不变的情况下,对整个长文本进行推理。 这一过程与人类的阅读方式高度相似,类似于公认的「带着问题阅读」学习策略,即通过问题作为锚点,在LLM可处理的范围内逐步整合相关信息。 因此,LLM能否精准检索与问题最相关的文本,是本方法有效性的核心。 关键在于设计基于注意力得分分布的token检索策略和算法,以确保模型能够在长文本中高效提取关键信息。 借鉴实验结果,研究团队选取了多头注意力(Multi-Head Attention)的最后一层,并对所有注意力头的得分进行求和聚合(如公式2所示),探索了一种能够准确判断模型关注重点的方法。 通过可视化注意力得分,研究团队观察到:与答案相关的信息通常由连续的token组成。 也就是说,它们以短语级别的粒度存在。 这一发现与在图2c的实验结果一致,进一步确认了LLM在token级别上具备较高的注意力精度。 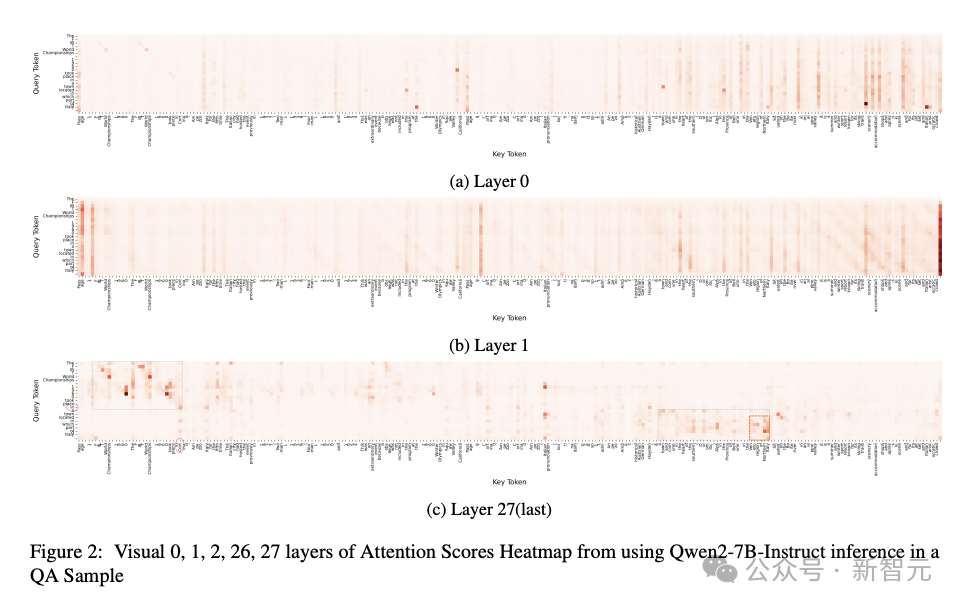
因此,希望设计的操作是:计算每个token及其相邻token在2D注意力得分矩阵中的累积注意力得分。 计算结果将作为新的特征,在后续的检索过程中用于排序。经过深入分析,发现此操作等效于使用一个填充了1的卷积核(kernel)进1D卷积。 对于查询i和键j,其特征重要性计算如下: 1. 聚合所有注意力头的得分(公式2): 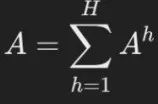
2. 基于1D卷积计算每个token及其相邻token的重要性(公式3): 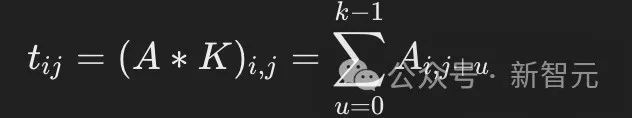
其中,k是1D卷积核的大小,对应于方法中的参数Phrase Token Num。 3. 沿矩阵的列方向求和,计算每个上下文token的总重要性分数(公式4): 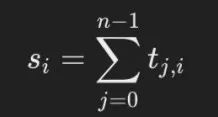
其中,s_i代表第i个上下文token的综合重要性分数。 4. 最后,选取重要性分数最高的前K个上下文token,并将其所在句子的所有token写入缓存(cache)。这个过程可表示为: 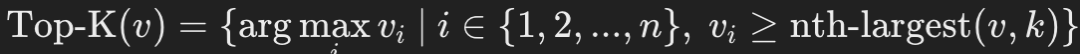
即,从所有token的重要性分数v中,选择排名前K的token,并将它们所在的完整句子存入缓存,以便后续推理时使用。
缓存句子Token(Cache Sentence Token)
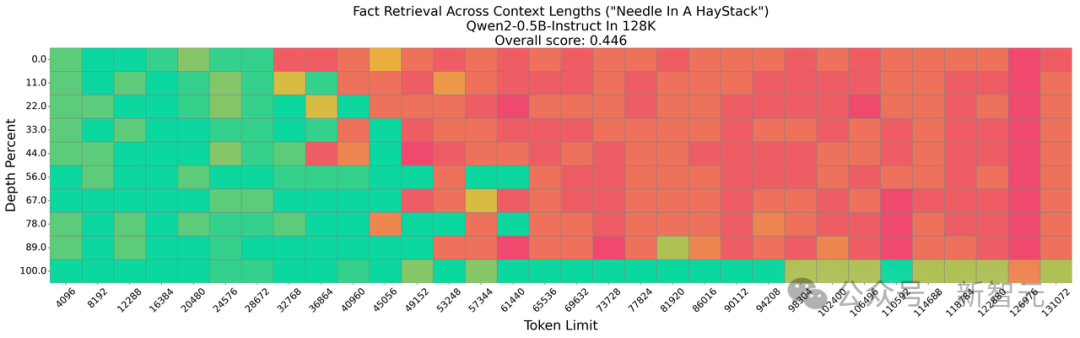
在推理过程中对缓存(cache)的使用方式,InfiniRetri与传统方法存在本质性区别。 相比于直接使用缓存,InfiniRetri将其用于存储过去的上下文信息。 具体而言,主要有以下两点不同: 1 新方法在模型外部缓存token ID,而不是每层的历史键值(Key-Value)状态。具体来说,在推理过程中不使用传统的Key-Value缓存,而是在每次推理前,将过去的上下文信息与当前输入合并后再进行推理。 2 新方法基于短语级特征进行检索,并在缓存中存储包含Top-K token的句子级token。也就是说,存储的是完整的句子,而不是单独的token,从而确保检索到的信息更具上下文完整性。 事实上,正是这两项创新性改进,使得新方法在无需微调的情况下,就能比传统的KV缓存方法更有效地提升LLM处理长文本的能力。 新方法并不试图压缩缓存中的token,而是保留句子级别的相关上下文信息。这是因为,句子是最小的完整语义单元,相比于单个token,更能确保LLM对上下文的理解。 在LLM逐步推理每个文本片段的过程中,缓存中保留的中间结果是动态变化的,它们由先前存储的token和当前输入片段的组合决定。因此,在整个过程中,这些中间结果会相对调整和更新,以适应模型的理解需求。 AI界的「大海捞针」 大海捞针(Needle-in-a-Haystack,NIH)任务要求模型在一篇「超长文档」(「大海捞针」之海)中,精准检索出一个特定的目标句子(「针」),该句子可以被随机插入到文档的任意位置。 通过调整「针」的放置位置(文档深度)和上下文长度,反复测试以衡量模型的表现。 为了直观分析模型的检索能力,采用了热力图(heatmap)可视化实验: 绿色代表完美检索(准确找到目标句), 其他颜色表示检索错误。
这种可视化方法可以直观展示LLM处理长文本的能力上限,因此被广泛用于评估。
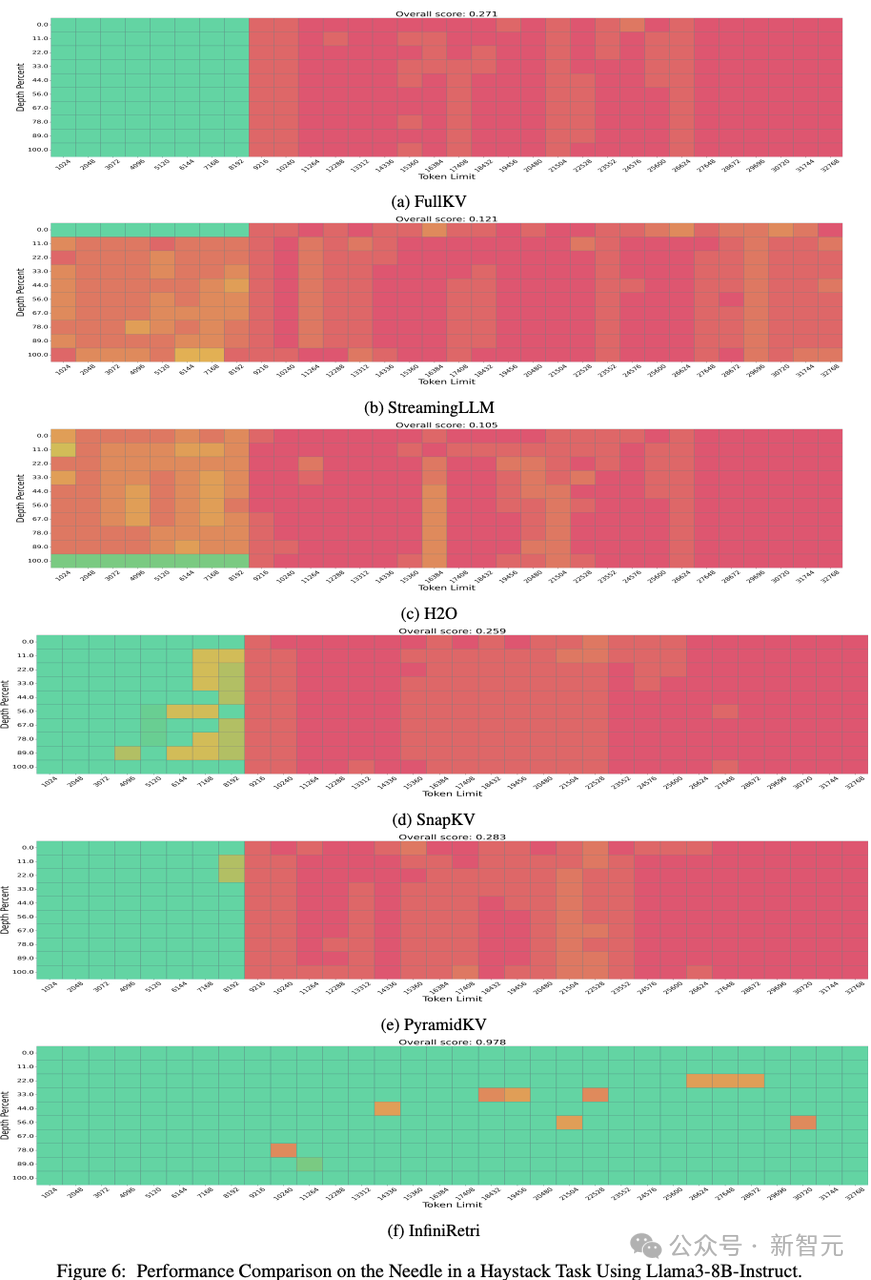
实验1:Llama3-8B-Instruct的对比
如图6所示,在Llama3-8B-Instruct模型上测试NIH任务,并与以下方法进行了对比:Full KV(完整KV缓存) StreamingLLM、H2O、SnapKV、PyramidKV以及InfiniRetri(新方法)。 在最长32K token的输入文本上进行实验,结果表明: 传统KV缓存压缩方法虽有所改进,但没有超越Full KV的性能。 InfiniRetri方法的表现优于FullKV,显著增强了Llama3-8B-Instruct处理NIH任务的能力,甚至突破了原始8K token上下文窗口的限制。
实验2:Mistral-7B-Instruct的对比
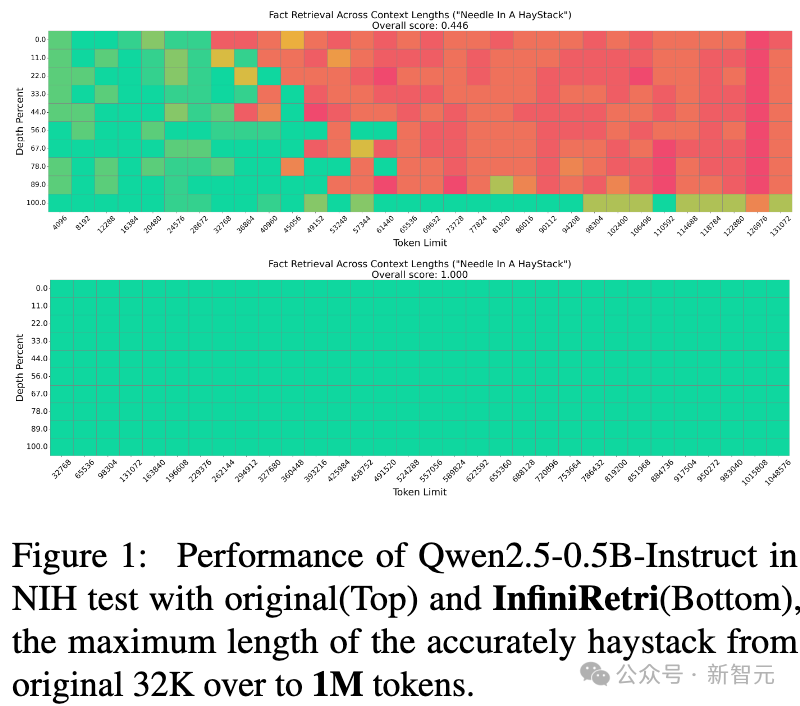
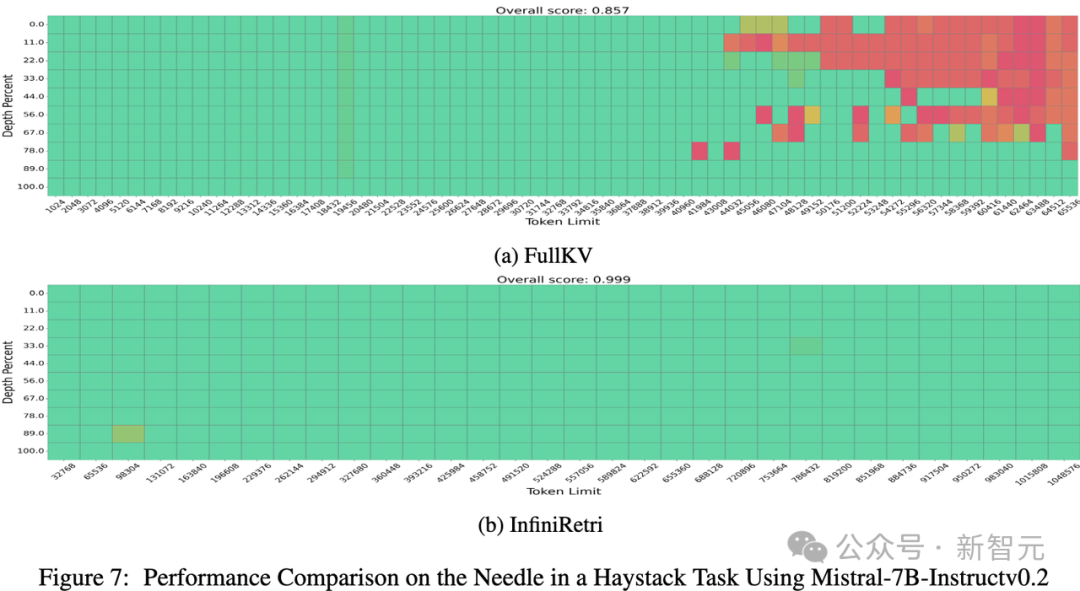
为了进一步验证InfiniRetri的有效性,在Mistral-7B-Instruct上扩展了输入长度。 Mistral-7B-Instruct官方支持的上下文窗口为32K token,对比了FullKV和InfiniRetri的表现,如图7所示: Mistral-7B-Instruct+FullKV(图7a):最多可在43K token长度范围内正确完成NIH任务。 Mistral-7B-Instruct+InfiniRetri(图7b):在相同的参数设置下,新方法不仅超越了Llama3-8B-Instruct,而且在NIH任务上达到了100%的检索准确率,并将可处理的输入长度扩展至1M token,且没有损失准确率。
关键发现与额外实验
进一步观察到:只要LLM在有限上下文窗口内具备足够的检索能力,新方法就可以赋能模型处理超长文本的检索任务,理论上可支持无限长输入。 基于这一发现,在更小的开源模型上的额外实验,结果符合预期: 新方法将该模型的有效上下文token长度从32K扩展至1M+,从而使其在NIH任务上具备了近乎无限的长文本处理能力(如图1所示)。
LongBench实验
LLaMA3-8B-Instruct:相对提升4.9%(32.92→34.56) Qwen2-7B-Instruct:相对提升70.5%(25.11→42.82) Mistral-7B-Instruct-v0.3:相对提升55.8%(24.17→37.68)
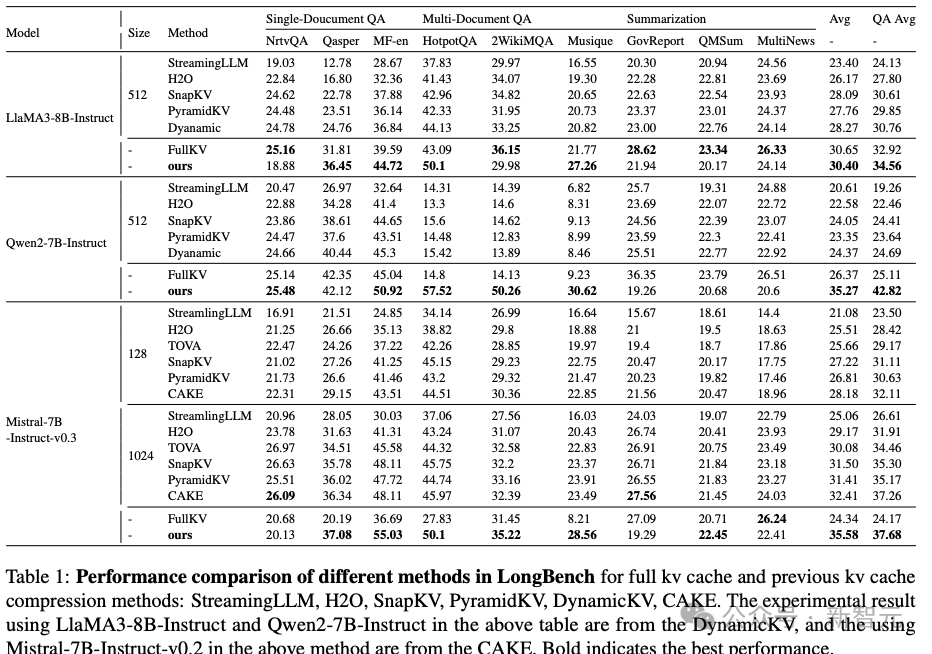
关键发现
值得注意的是,Qwen2-7B-Instruct在HotpotQA任务上的得分,超越了其他同等参数规模的模型,表明其在短文本推理方面的优势。这进一步说明,Qwen2-7B-Instruct通过新方法,能够有效提升其长文本推理能力。 类似地,Mistral-7B-Instruct v0.2作为擅长短文本推理的模型,在长文本任务中的表现也得到了显著提升。
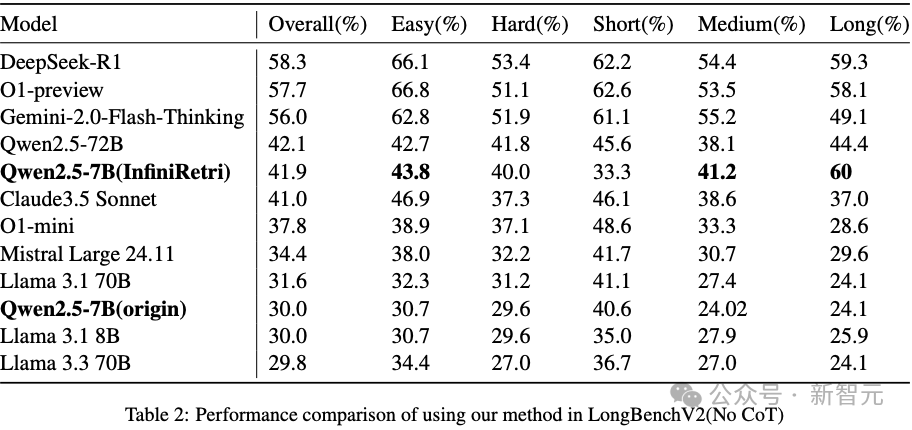
降低延迟与计算开销
如前所述,新方法采用分段滑动窗口机制+迭代处理,在确保LLM推理长度保持在方法参数范围内的同时,仅在缓存中保留最相关的token。 这种机制使得LLM仅需处理长文本中的少部分关键信息,从而显著降低长文本处理时的推理延迟和计算开销。 正如表4所示,即使未对方法参数进行精细调整,新方法仍能在LongBench文档问答(QA)任务中,大幅降低推理成本,适用于Llama3-8B-Instruct、Mistral-7B-InstructV0.2和Qwen2-7B-Instruct等模型。 例如,在NtvQA任务中,仅保留4.5%的原始输入文本(18409->834);在HotpotQA任务中,Qwen2-7B-Instruct仅需处理8.7%的原始文本(9152->795),但推理性能提升高达288%。 这些实验结果进一步证明,新方法能够通过优化LLM在较小上下文窗口内的能力,有效提升其长文本处理能力。 这一发现表明,提升LLM的长文本处理能力不仅可以通过扩展上下文窗口,还可以通过优化模型在小窗口内的推理能力,再结合新方法机制,实现高效处理长文本的目标。 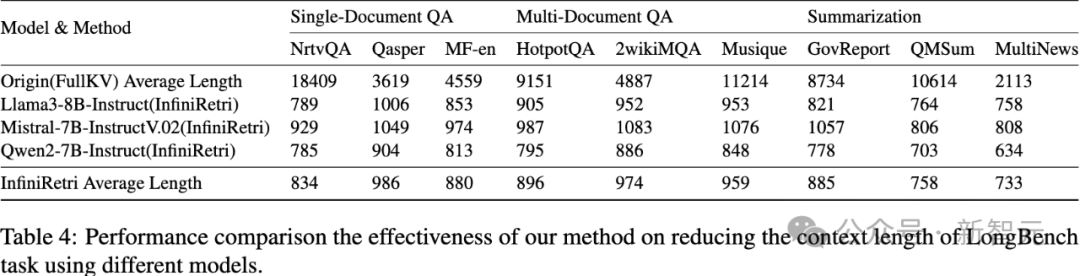
评论 这篇论文强调了一个本应显而易见的事实:预测和检索是同一枚硬币的两面。 要有效地进行预测,首先必须确定什么是相关的。令人惊讶的是,适当地利用注意力模式,拥有5亿参数的模型可以在100万个token上执行完美的检索。 这引发了一个有趣的问题:如果围绕检索能力明确设计架构会怎样?
Transformer架构是为预测而设计的,检索是作为副产品出现的。那么,专门为检索优化的架构会是什么样子呢? 许多资金已经投入到构建大规模RAG(检索增强生成)系统中。
如果这篇论文所承诺的性能改进是真实的,其影响将是巨大的。 
参考资料: https://arxiv.org/abs/2502.12962 https://github.com/gkamradt/LLMTest_NeedleInAHaystack


内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢