

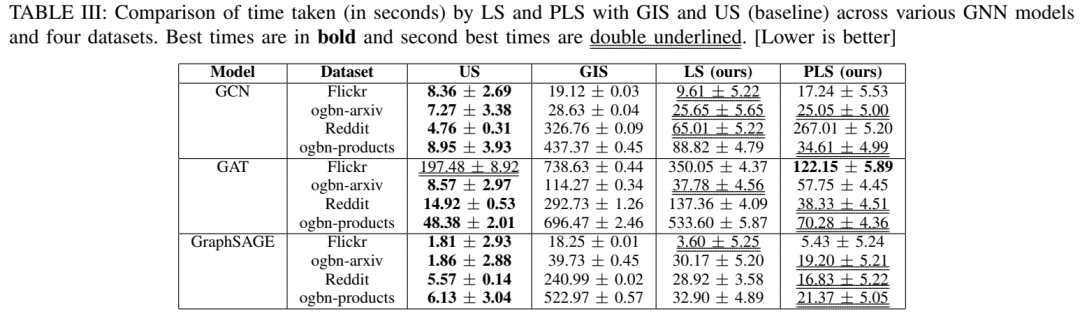
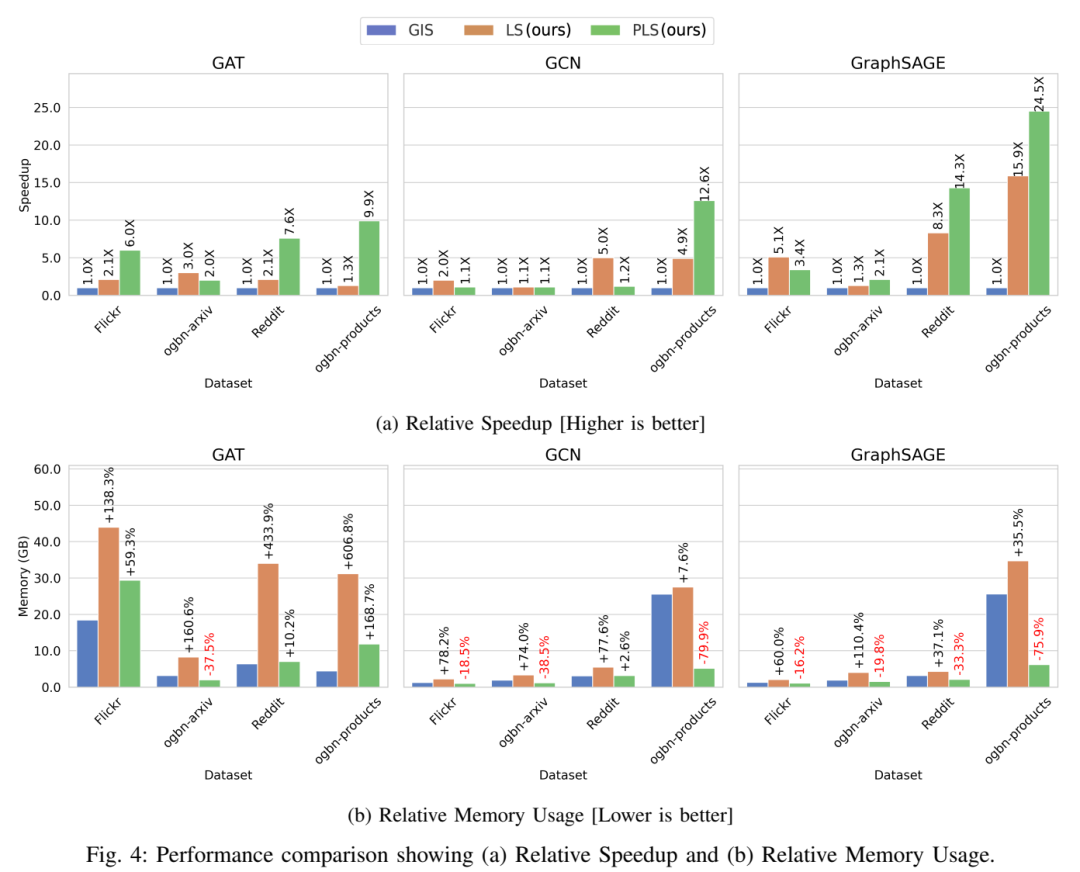
图形神经网络 (GNN) 已在众多科学和高性能计算 (HPC) 应用中展示了最先进的性能。最近的研究表明,将单独训练的 GNN “补充”(组合)到单个模型中可以提高性能,而不会增加推理过程中的计算和内存成本。但是,现有的 souping 算法通常速度缓慢且占用大量内存,这限制了它们的可伸缩性。我们介绍了 GNN 的 Learned Souping,这是一种基于梯度下降的 Souping 策略,与现有方法相比,它大大减少了时间和内存开销。我们的方法在多个开放图形基准测试 (OGB) 数据集和 GNN 架构中进行了评估,准确率提高了 1.2%,速度提高了 2.1 倍。此外,我们还提出了 Partition Learned Souping,这是一种基于分区的新型 learned souping 变体,可显着减少内存使用。在使用 GraphSAGE 的 ogbn-products 数据集上,分区学习的 souping 在不影响准确性的情况下实现了 24.5 倍的加速和 76% 的内存减少。

Enhanced Soups for Graph Neural Networks
https://arxiv.org/abs/2503.11612
1. 研究背景
图神经网络(GNN)的挑战:GNN在处理大规模图数据时面临计算和内存需求的挑战,尤其是在深度增加时会出现“邻域爆炸”问题。此外,传统的模型聚合方法在提高性能的同时会显著增加计算和内存成本。
模型汤(Model Soups):模型汤通过将多个独立训练的模型参数混合成一个单一模型,在不增加推理成本的情况下提高性能。然而,现有的模型汤算法(如贪婪插值汤GIS)在处理大规模图数据时速度慢且内存占用高。
2. 试图解决以下两个问题:
如何提高图神经网络(GNN)的性能,同时避免在推理过程中增加计算和内存成本:
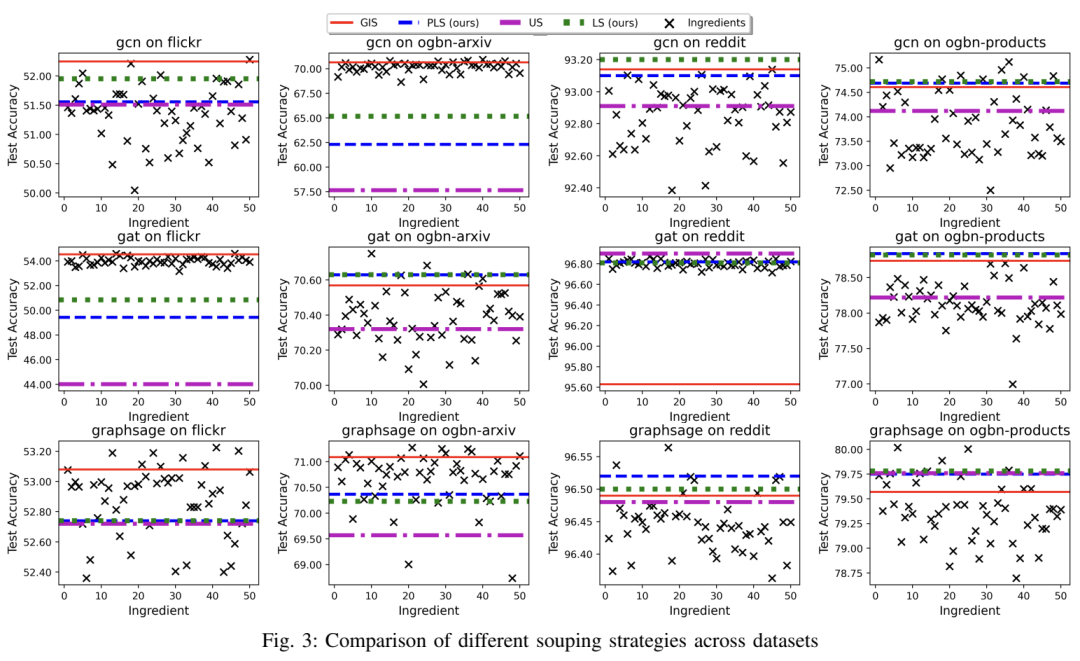
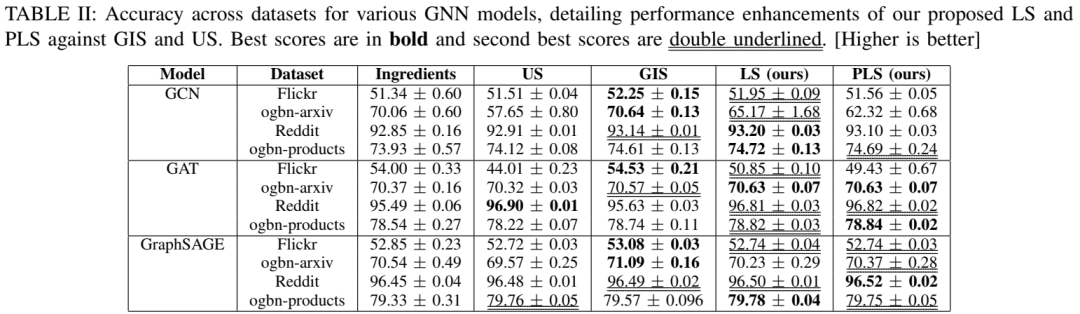
传统的模型聚合方法(如模型集成)在提高性能的同时,往往会显著增加计算和内存需求,这在实际应用中可能不可行。而“模型汤”(Model Soups)方法通过将多个独立训练的模型参数混合成一个单一模型,避免了推理阶段的额外成本。然而,现有的“模型汤”算法(如贪婪插值汤GIS)在处理大规模图数据时存在速度慢和内存占用高的问题,限制了其可扩展性。因此,论文提出了一种基于梯度下降的“模型汤”策略——Learned Souping for GNNs(LS),以显著减少时间和内存开销。
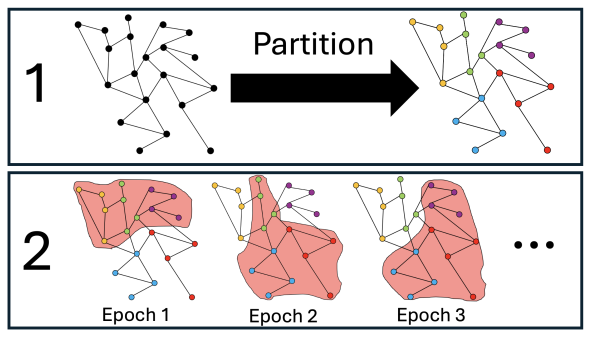
论文还提出了Partition Learned Souping(PLS),这是一种基于分区的Learned Souping变体,能够显著减少内存使用,进一步提高大规模图数据的可扩展性。
如何缓解大规模图数据带来的强烈内存和计算需求:
随着图数据规模的增大,GNN的训练和推理面临着巨大的内存和计算挑战。例如,在大规模图数据上进行分布式训练时,通信开销和模型性能之间存在权衡。论文通过提出Partition Learned Souping(PLS)方法,利用图分区采样来优化内存使用和计算效率,同时保持模型性能,从而有效管理内存约束,为大规模图数据的GNN模型汤提供了一种可扩展的解决方案。
3.相关研究:
3.1分布式GNNs
GraphSAGE:提出了归纳式学习方法,通过在聚合过程中采样固定大小的邻居子集,从而降低计算和内存需求,以应对GNN在深度增加时面临的“邻域爆炸”问题。
Layer-neighbor sampling:提出了一种新的采样方法,通过在每一层对邻居进行采样,有效缓解了GNN中的“邻域爆炸”问题,提高了训练效率。
Layer-dependent importance sampling:提出了一种基于层重要性的采样方法,通过为不同层分配不同的采样率,进一步优化了GNN的训练过程,提高了模型性能。
Learn locally, correct globally:提出了一种分布式GNN训练算法,通过在局部进行学习并在全局进行校正,实现了高效的分布式训练,降低了通信开销。
BatchGNN:提出了一种基于CPU的分布式GNN训练方法,通过批处理技术提高了训练效率,适用于大规模图数据。
Accelerating training and inference of GNNs:提出了一种通过快速采样和流水线化加速GNN训练和推理的方法,有效提高了训练和推理速度。
3.2模型聚合
Stacked generalization:提出了堆叠泛化的概念,通过将多个模型的输出进行组合,形成更强大的预测模型。
Bagging predictors:提出了Bagging方法,通过在不同数据子集上训练多个模型,并将它们组合起来以提高模型的泛化能力。
Boosting:提出了一种通过训练一系列模型,每个模型都专注于纠正前一个模型错误的方法,从而提高模型性能。
Adaptive Boosting (AdaBoost):提出了一种自适应增强算法,通过赋予不同模型不同的权重,进一步提高了模型的泛化能力。
Leveraging relational graph neural network for transductive model ensemble:提出了一种利用关系图神经网络进行模型集成的方法,通过在图结构数据上进行集成学习,提高了模型性能。
Mage: Automatic diagnosis of autism spectrum disorders using multi-atlas graph convolutional networks and ensemble learning:提出了一种基于多图卷积网络和集成学习的自闭症诊断方法,通过集成多个模型提高了诊断准确性。
Robust graph neural networks via ensemble learning:提出了一种通过集成学习提高图神经网络鲁棒性的方法,通过组合多个模型提高了模型的抗干扰能力。
Efficient ensembles of graph neural networks:提出了一种高效的图神经网络集成方法,通过优化集成过程提高了模型性能和效率。
Gnn-ensemble: Towards random decision graph neural networks:提出了一种基于随机决策的图神经网络集成方法,通过引入随机性提高了模型的泛化能力。
3.3模型汤(Model Soups)
Model soups: averaging weights of multiple fine-tuned models improves accuracy without increasing inference time:首次提出了模型汤的概念,通过将多个微调模型的权重进行平均,提高了模型性能,而无需增加推理时间。
Graph ladling: Shockingly simple parallel gnn training without intermediate communication:将模型汤的概念扩展到图神经网络,提出了一种无需中间通信的并行GNN训练方法,通过贪婪插值汤(GIS)算法提高了模型性能。
Personalized soups: Personalized large language model alignment via post-hoc parameter merging:提出了一种通过模型汤进行个性化语言模型对齐的方法,通过参数合并提高了模型的个性化性能。
Seasoning model soups for robustness to adversarial and natural distribution shifts:提出了一种通过模型汤提高模型对对抗性和自然分布偏移的鲁棒性的方法,通过调整模型汤的成分提高了模型的鲁棒性。
Adversarial example soups: averaging multiple adversarial examples improves transferability without increasing additional generation time:提出了一种通过平均多个对抗样本来提高对抗样本的可转移性的方法,无需增加额外的生成时间。
Fedsoup: Improving generalization and personalization in federated learning via selective model interpolation:提出了一种在联邦学习中通过选择性模型插值提高泛化和个性化性能的方法,通过模型汤提高了模型的性能。
Sparse model soups: A recipe for improved pruning via model averaging:提出了一种通过模型平均提高剪枝性能的稀疏模型汤方法,通过模型汤提高了模型的稀疏性和性能。
Instant soup: Cheap pruning ensembles in a single pass can draw lottery tickets from large models:提出了一种通过单次传递中的廉价剪枝集成绘制大模型中的彩票票的方法,通过模型汤提高了模型的性能和效率。
4. 提出两种新的“模型汤”(Model Soups)策略
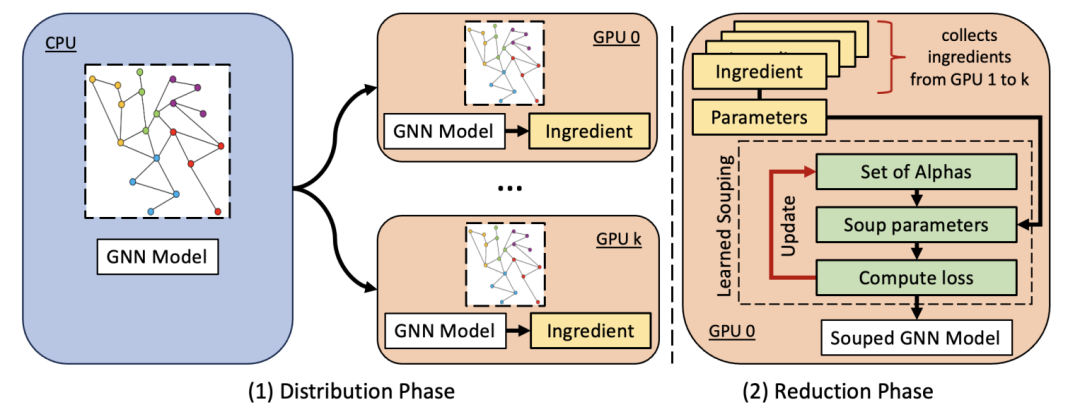
我们提出的 GNN 模型混合工作流程是,阶段 (1) 将初始化的模型和图形分发给独立的工作者,他们独立训练,成为成分;阶段 (2) 通过将成分混合成单一模型来减少成分。
4.1 Learned Souping for GNNs (LS)
核心思想:LS是一种基于梯度下降的模型汤策略,它通过优化模型参数的插值比例来构建一个性能更优的单一模型。与传统的贪婪插值汤(GIS)相比,LS能够更高效地找到最优的插值比例,从而在减少时间和内存开销的同时提高模型性能。
具体方法:
插值参数的引入:LS为每个模型的每一层引入了一组插值参数





内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢