
DRUGAI
近年来,人工智能(AI)领域的突破性进展越来越依赖于由多个大语言模型(LLMs)及其他专业工具(如搜索引擎和模拟器)协同驱动的系统。然而,目前这些系统主要依赖领域专家手工设计,并通过启发式方法进行调整,而非自动优化,这在加速AI进步方面构成了重大挑战。人工神经网络的发展曾面临类似的困境,直到反向传播和自动微分的引入,使优化流程变得高效便捷。
DRUGAI
近年来,人工智能(AI)领域的突破性进展越来越依赖于由多个大语言模型(LLMs)及其他专业工具(如搜索引擎和模拟器)协同驱动的系统。然而,目前这些系统主要依赖领域专家手工设计,并通过启发式方法进行调整,而非自动优化,这在加速AI进步方面构成了重大挑战。人工神经网络的发展曾面临类似的困境,直到反向传播和自动微分的引入,使优化流程变得高效便捷。
类比于此,研究人员在本文中提出了一种通用优化框架 TextGrad,该框架通过反向传播LLM生成的反馈来改进AI系统。TextGrad利用自然语言反馈来批判性分析并建议优化系统的各个部分——从提示词(prompts)到输出结果(如分子结构或治疗方案),从而实现对生成式AI系统的自动优化,适用于多种任务。研究人员通过一系列实验验证了TextGrad的通用性和有效性,包括解决博士级科学问题、优化放射治疗方案、设计具有特定性质的分子、代码生成以及优化自主智能体系统。TextGrad的引入,使研究人员能够更加便捷地开发高效且具影响力的生成式AI系统。

大型语言模型(LLMs)正在重塑突破性人工智能(AI)系统的构建方式。新一代AI应用越来越多地以复合系统的形式运行,协同调度多个复杂组件——从基于LLM的智能体,到如模拟器和网页搜索引擎等专业工具。例如,一个由多个LLM与符号求解器协作的系统可以解决奥林匹克级别的数学问题;另一个系统则通过调用搜索引擎与代码解释工具,达到了人类竞争程序员的水平,并能处理现实中的GitHub问题。
尽管取得了诸多进展,但当前许多突破仍依赖于领域专家手工打造的系统。因此,开发自动化优化算法,成为构建LLM驱动的复合AI系统并推动未来突破的关键挑战之一。
在过去十五年中,AI的许多进展都依赖于神经网络与可微优化方法。神经网络中的各组件(如两个人工神经元)通过可微函数(如矩阵乘法)进行通信,因此,利用反向传播传递数值梯度、据此调整参数,已成为训练AI模型的自然方式。
然而,这种基于数值梯度的优化方式很难应用于新一代生成式AI系统,因为此类系统往往涉及自然语言交互、黑盒LLM模型或外部工具,使得传统的数值梯度回传变得不可行。
为应对这一挑战,研究人员提出了 TextGrad——一种通过文本实现“自动微分”的框架。传统神经网络以数值为媒介进行通信,而现代AI系统则依赖于文本、代码、图像等非结构化信息。在TextGrad中,AI系统被建模为一个计算图,其中各组件通过复杂(不一定可微)的函数交换这些丰富的非结构化变量。
在该框架中,研究人员将“微分”作为一种隐喻:LLMs提供的反馈被称为“文本梯度”(textual gradients),以自然语言形式给出清晰且具有可解释性的批评与建议,指明各变量应如何修改以优化整体系统。文本梯度可以通过任意函数进行传播,例如LLM的API调用、模拟器或外部数值求解器。值得注意的是,这种文本反馈并不直接作用于底层神经网络的参数,因此与黑盒API兼容。
研究人员在多个领域展示了TextGrad的强大能力,从问答基准测试,到放射治疗方案优化,再到分子生成,均可通过该统一框架无缝适配,无需为不同任务单独设计。LLMs能够为这些不同任务中的变量提供丰富、清晰、具有可操作性的自然语言反馈,比如修改分子结构、优化其他LLM的提示词、或者改进代码片段。
该框架基于一个关键假设:当前最先进的LLMs具备对系统中的组件和子任务进行合理推理的能力。实验结果表明,TextGrad具备自动改进生成式AI系统及其输出的巨大潜力。
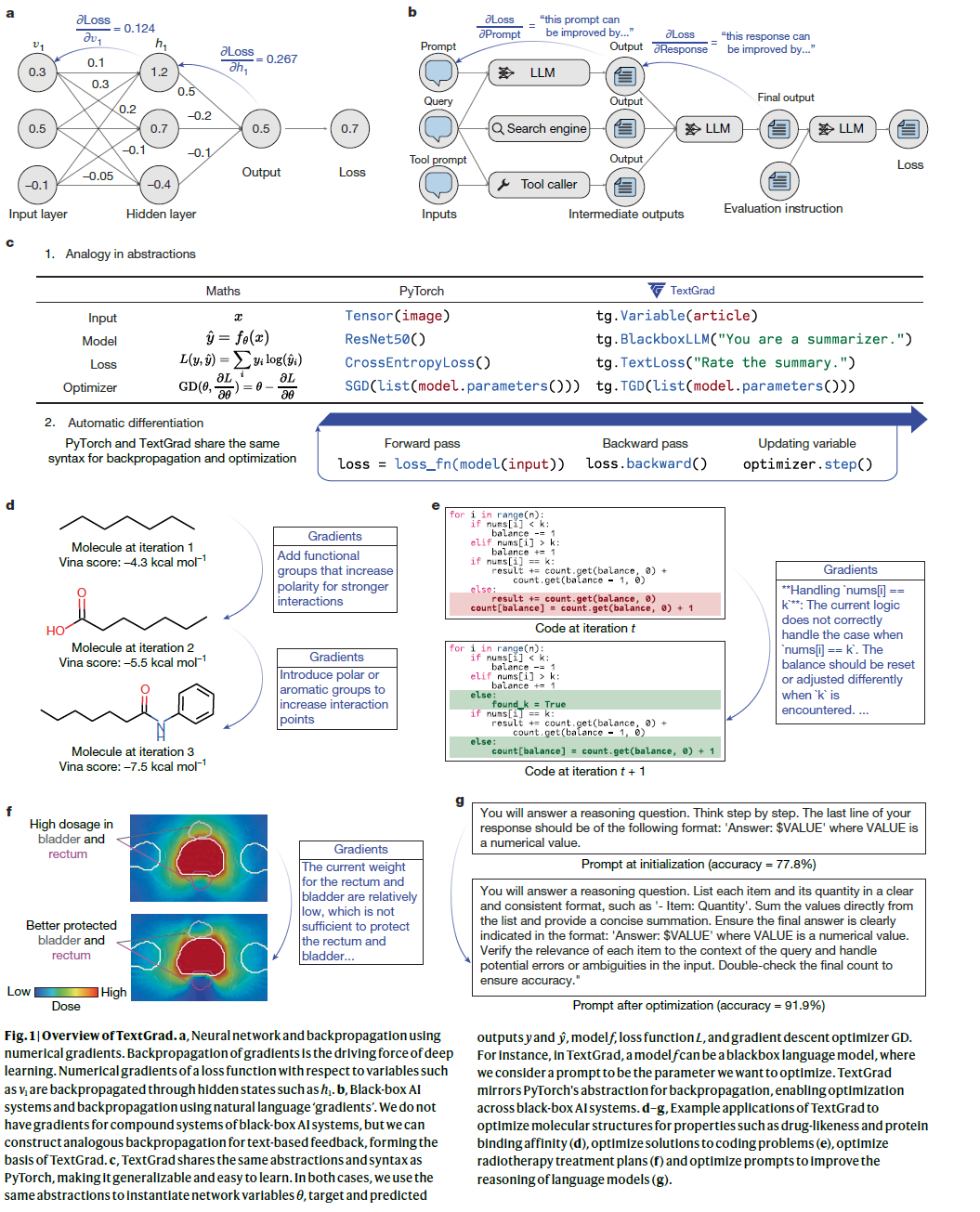
TextGrad:利用语言模型反馈进行反向传播优化
研究人员首先介绍了 TextGrad 在包含两个LLM调用的系统中的应用示例,并在后续部分给出其更一般的形式。在许多任务中,例如 LLM 作为评估者,语言模型不仅用于生成答案,还用于评价输出的质量。传统自动微分方法通过链式法则计算数值梯度,以优化系统变量,而 TextGrad 通过文本反馈提供优化建议,以改进非结构化变量,如提示词、输出内容或最终预测。
为了优化AI系统,研究人员提出了一种类似于反向传播的算法,其中 文本梯度(Textual Gradient) 作为优化信号。例如,当优化提示词时,TextGrad 先评估最终预测结果,再基于反馈信息,调整初始提示词,从而逐步优化整个流程。类似于数值梯度下降,文本梯度下降(TGD) 采用语言模型生成的优化建议,动态调整系统变量以提升性能。
与传统优化方法不同,TextGrad 可适用于 非可微分或黑盒目标函数,例如 LLM 生成的评价、单元测试结果或分子模拟引擎输出。这使得该框架更具通用性与灵活性。研究人员展示了 TextGrad 在多种任务中的适用性。

代码优化
在代码优化任务中,目标是修改代码以提高其正确性或优化运行时间。通常,我们构建一个计算图,在有限的单元测试监督下,通过测试指令自评估代码,并提供优化建议。
例如,在 “给定一个包含 1 到 n 的不同整数的数组 nums 和一个正整数 k,返回中位数等于 k 的非空子数组数量” 这一问题中,GPT-4o 生成的初始解答未能通过测试。TextGrad 识别出边界情况的问题,并提供改进建议,使优化后的代码成功通过所有测试。
研究人员在 LeetCode Hard 数据集上评估 TextGrad 的代码优化能力。GPT-4o 在零样本(zero-shot)设定下的通过率为 26%,而 Reflexion 方法达到 31%。TextGrad 进一步提升至 36%,且未使用示例提示,优于依赖上下文示例的 Reflexion,展现出强大的代码优化能力。
解答优化
在解答优化中,目标是改进某一问题(如量子力学相关问题)的答案。研究人员将解答作为优化变量,LLM通过评估当前答案,生成文本反馈,不断优化解答。即使首次生成的答案不正确,LLM也可通过迭代性反馈持续提升答案质量。
在多个问答基准数据集上,研究人员评估了TextGrad的效果,包括GPQA(涵盖物理、生物、化学问题)、MMLU子集(机器学习与大学物理)、MathVista和ScienceQA等。在这些任务中,TextGrad均显著提升了GPT-4o的表现,例如GPQA准确率从51.0%提升至55.0%,MMLU子集提升约3%至4%,在多模态任务中也超过Reflexion方法。
推理任务中的提示词优化
虽然LLMs在推理任务中表现强大,但其性能高度依赖于提示词设计。TextGrad可用于自动优化提示词,包括说明性提示(instruction)和上下文示例(in-context examples),以提升模型在推理任务中的泛化能力。
研究人员以Big Bench Hard(如物体计数、单词排序)和GSM8k数学推理数据集为测试平台,通过GPT-4o生成反馈,优化GPT-3.5-turbo等轻量模型的提示词。在这些任务中,TextGrad优于OPRO,并与当前先进方法DSPy持平或超越。例如,在物体计数任务中,TextGrad比DSPy提升了7.0%。
此外,研究人员验证了TextGrad的可扩展性与鲁棒性:优化后的提示词可迁移至开源模型(如Qwen、Llama),仍能带来性能提升,同时展现出较高的性价比。
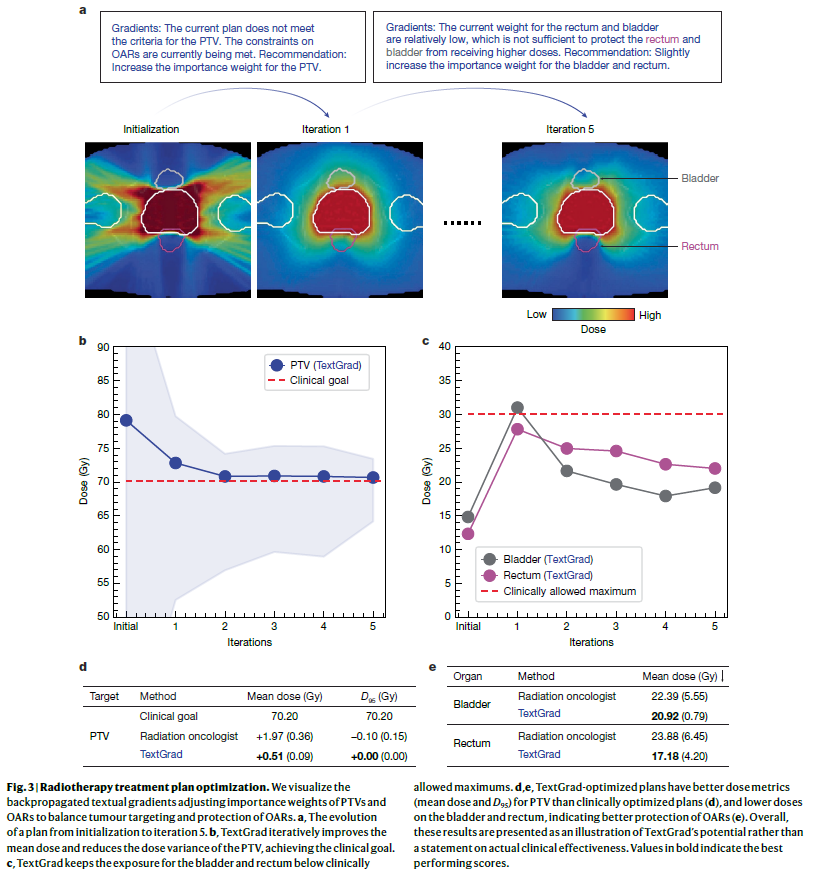
放射治疗方案优化
放射治疗需在杀伤肿瘤细胞和保护健康器官之间取得平衡,治疗计划制定过程复杂且依赖人工经验。研究人员将TextGrad应用于治疗方案的外层优化环节,通过优化器官权重配置,改进整体方案质量。
实验中,研究人员使用GPT-4o对当前治疗计划进行评估,并生成优化建议来调整权重配置。为提高LLM理解能力,还引入历史方案和权重示例作为上下文。
结果显示,TextGrad能根据剂量外溢情况生成有针对性的反馈,如增加PTV(靶区)权重、调整膀胱与直肠保护力度。在与五位前列腺癌患者的临床方案对比中,TextGrad生成的治疗计划在肿瘤区域剂量控制与健康器官保护方面均优于人工设计方案,展示了其在复杂医疗优化任务中的潜力。
优化复合AI系统
研究人员进一步探讨了 TextGrad 在优化涉及多个变量和复杂推理链的复合AI系统中的能力。
首先,研究人员应用 TextGrad 优化 Chameleon,这一高度智能的代理系统集成了多个LLM模块和多种工具,如视觉感知和知识检索。然而,Chameleon 的原始规划与执行流程是静态的,缺乏反馈机制,容易在推理过程中累积错误。
TextGrad 通过引入反馈循环优化 Chameleon 的解决步骤。系统先执行标准的前向传播,随后逐步优化每个模块的输出,从第一模块开始,直至最后一个模块。每个模块的优化过程包括:使用损失函数评估最终响应、计算 TextGrad 生成的梯度,并反向传播以更新模块输出。研究人员在 ScienceQA-IMG 数据集上进行评估,实验结果表明,TextGrad 通过文本梯度的迭代优化提高了 Chameleon 的性能,优化两次后准确率提升 5.7%,优化三次后提升 7.7%,有效增强了复合AI系统的表现。
在另一项研究中,研究人员利用 TextGrad 提升多模态模型的空间推理能力。在视觉问答任务中,模型需要结合图像内容回答问题。研究人员设计了两个优化变量:答案生成的提示词(instructional prompt)和用于评估的损失提示词(loss prompt),并将它们与最终答案作为独立变量,通过 TextGrad 进行联合优化。实验在 HQH 数据集上进行,结果显示,该方法在 GPT-4o 结合思维链推理(CoT)基础上进一步提升 9%,并优于 Reflexion 方法,验证了 TextGrad 在优化多模态推理任务中的有效性。

讨论
TextGrad 的设计基于三个核心原则:(1)通用且高效,不依赖于特定领域的手工设计;(2)易于使用,借鉴了 PyTorch 的抽象结构,便于迁移已有知识;(3)完全开源,便于研究人员进一步拓展和应用。在多个任务中,TextGrad 实现了领先的性能表现,包括代码优化、博士级问答、提示词优化,并在分子设计和放射治疗等领域展示了可行性验证结果。
此前已有研究探索了利用LLM进行提示词优化和自我改进,虽在特定任务中展现了能力,但多局限于提示词层面。而TextGrad 提出了一种通用框架,首次将自然语言反馈的“反向传播”机制扩展到更广泛的目标变量上,如代码、分子结构和治疗方案,突破了现有方法的限制。
尽管TextGrad展现出良好潜力,研究人员也指出了未来发展的方向。首先,仍需进一步探索如何将其应用于科学发现与工程设计中的高效迭代流程;其次,文本反馈的反向传播本身拥有丰富的算法设计空间,有望与传统数值优化和自动微分方法形成更紧密的联系;最后,尽管TextGrad在分子设计与治疗方案中取得了体外验证的可行性结果,其最终效用仍需通过实验或临床试验来确认。
随着AI系统逐渐从单一模型训练转向多模块、多工具协同的复合系统优化,亟需新一代优化方法。TextGrad结合了LLM的强大推理能力与可分解优化流程的优势,为构建和优化下一代AI系统提供了一个通用、高效的解决方案。
整理 | WJM
参考资料
Yuksekgonul, M., Bianchi, F., Boen, J. et al. Optimizing generative AI by backpropagating language model feedback. Nature 639, 609–616 (2025).
https://doi.org/10.1038/s41586-025-08661-4
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢