
【论文标题】Understanding the Difficulty of Training Transformers
【作者团队】Liyuan Liu, Xiaodong Liu, Jianfeng Gao, Weizhu Chen and Jiawei Han
【发表时间】EMNLP 2020
【论文链接】https://www.aclweb.org/anthology/2020.emnlp-main.463/
【推荐理由】本文着重于解决Transformer的难以训练的问题,分析了其中的原因,同时提出一种新的优化方来提高Transformer的训练效率。
Transformer在许多NLP任务中被证明是有效的。然而,训练Transformer的过程往往需要精心的参数设计(例如,传统的SGD无法有效地培训Transformer,必须采用Warmup的策略)。
本论文从经验和理论的角度来理解变压器培训的复杂性。文中的分析表明,不平衡的梯度不是训练不稳定的根本原因。相反,文中确定了多层Transformer模型的每一层存在一种影响训练效果的放大效应。因为这种效应放大了小参数扰动(例如,参数更新),使得对其残余分支的严重依赖使得训练不稳定,并导致模型输出中的显著干扰。并且,论文中指出,轻微的依赖性限制了模型的潜力,并导致低质量的训练模型。
同时,论文中提出Admin(自适应模型初始化)来稳定早期训练,并在后期充分发挥其潜力。大量的实验表明,管理更稳定,收敛更快,并导致更好的性能。 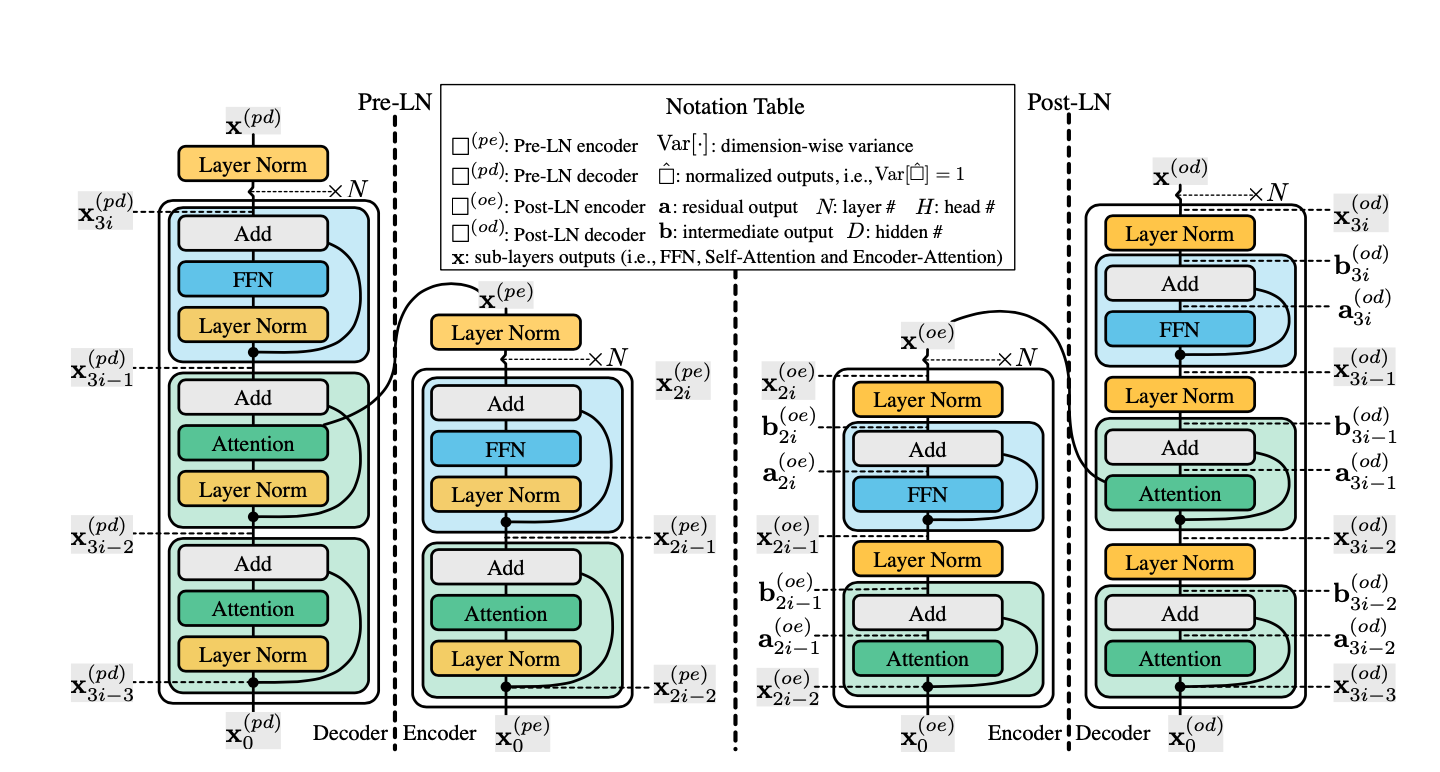
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢