
点击蓝字
关注我们

Part1
Part2
3.1 评测指标的科学性与局限性
3.2 数据集的“暗箱”
3.3 超参数优化和过拟合陷阱
Part3
3.1 科研方向的扭曲
3.2 政策资源的虹吸效应
Part4
Part5
Part6
3月18日,superCLUE发布了《中文大模型基准测评2025年3月报告》。报告显示,o3-mini(high)总分76.01分稳居榜首,国产模型表现亮眼,DeepSeek-R1等与国际领先模型差距缩小。在这场大模型的“战国争霸”中,这着实是一个好消息。
然而,在搜索引擎上以“国产大模型”“排行”“榜单”等关键词进行检索时,则会出现大量在知乎、CSDN博客等平台上发布的、以各家榜单为基础的帖子。综合来看,当前国内大模型评测体系呈现“多足鼎立”格局,以superCLUE、CMMLU、AgentEval为代表的榜单各立山头。
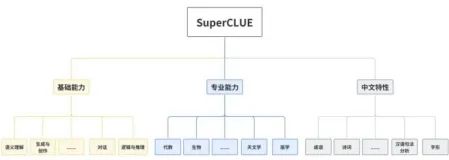
而在superCLUE、CMMLU、AgentEval三家国内主流大模型排行榜中,其衡量大模型的指标也存在极为割裂的现象。例如,由清华大学、智谱AI开发的superCLUE,其强调中文特性能力,从基础能力、专业能力、中文特性三大维度构建评测体系;
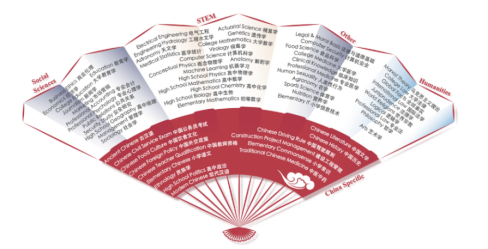
由MBZUAI,上海交通大学,微软亚洲研究院合作完成的CMMLU,其包含了包括自然科学、人文和社会科学在内的诸多领域学科,此外也包含许多具有中国特色的内容,全面地评估大模型在中文知识储备与语言理解上的能力;
而由Microsoft Research推出的AgentEval则另辟蹊径,其以任务完成度为标准,评估模型实用价值。但其评测成本较高,针对每个大模型可能都存在特定的评估过程。
这些榜单的差异性映射出技术路线之争;superCLUE 试图证明“中文大模型不逊于国际巨头”,而 AgentEval 则指向产品化验证。依照不同的标准存在不同的榜单与排名无可指摘,然而厂商选择性地参与特定榜单,本质却是争夺技术话语权:部分大模型在特定的赛道取得的成绩,是否会成为厂商的公关推广?而公关推广是否会夸大其所获得的成就?
因此,作为公众眼中的高科技,在为大模型“哪家强”争辩的同时,也应当为公众拂去大模型榜单及其各项指标表面的迷雾。
这些榜单的指标(评测基准)是否科学?以 superCLUE 为例,其“中文特性能力”包含成语填空、诗歌创作等任务,但这些设计是否真正反映语言理解深度?模型通过可以模板化学习在诗歌生成任务中取得高分,却未必具备文化意境解读能力。
数据集的“暗箱”
2024年3月,《新华每日电讯》的一则评论《刷榜跑分?AI评测不应走偏路线》揭开了大模型榜单的“遮羞布”。评论认为,在榜单排名存在第三方“考官”出题库考察大模型能力的前提下,部分厂商会提前拿题库、背答案、考高分,以此来投机取巧,炒作包装。而在这种情况下,部分名不见经传的国产大模型以高分压过chatGPT等知名大模型,其训练数据是否包含评测题库的相似内容?这种“数据泄露”风险使得榜单的公信力存疑,最终使榜单成为技术资本化的工具。
而在知乎等平台搜索关于大模型榜单的评价,相关帖子同样认可这个观点。依旧以superCLUE为例,不少知乎答主认为superCLUE为部分大模型“量身定做题目”,测试高分的大模型在实践中出现大量“事实性逻辑性错误”,衡量的大模型榜单并没有推动科技向前发展,最终却成了某些大模型公关推广的场地。
微调是指调整大型语言模型(LLM)的参数以适应特定任务的过程。这是通过在与任务相关的数据集上训练模型来完成的。所需的微调量取决于任务的复杂性和数据集的大小。
模型厂商通过调整模型结构(如 MoE 架构)和训练策略(如动态学习率)提升榜单表现。例如,阶跃星辰的 step-2 模型通过“从头训练 MoE 架构”实现参数利用率优化,在 LiveBench 的指令跟随测试中夺冠,但这种架构是否在其他场景(如长文本生成)中表现均衡?这种针对性优化可能导致模型在榜单任务中过拟合,牺牲泛化能力。
科研方向的扭曲
“机器之心”曾经提到,部分厂商为提升榜单排名,倾向于选择利用优秀的数据集,即“真题”进行训练大模型。基准泄露会让大模型取得夸张的成绩,但利用“真题”刷分的大模型,其性能并不会因为训练数据更优秀而编的更好。这种“榜单导向”的科研模式,可能会延缓中国在人工智能方向的探索。
榜单高分模型在实际应用中可能“水土不服”。实验室任务多为封闭问题,而现实交互需处理模糊性和多轮对话。此外,部分大模型当前展现出的能力尚不能支持专业应用。因此,大模型需要完成从“刷榜”到“用榜”的转型。
针对不同需求,以不同指标构建出不同的榜单本身合理。但相对于目前大模型榜单存在的包括数据泄露、“高分低能”等问题,其急需构建更全面的评估体系。
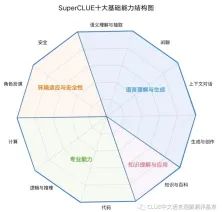
1.动态化评测。大模型评测体系中应引入对抗性测试,采用诱导大模型输出不安全内容的对抗输入。相对于通过特定领域学科知识的考察,对抗性测试更能验证大模型在现实环境中的实践应对能力。这里同样以superCLUE为例,superCLUE同样考察大模型的安全能力,防止生成可能引起困扰或伤害的内容。这涉及到识别和避免可能包含敏感或不适当内容的请求,以及遵守用户的隐私和安全政策。
2.场景化权重。大模型榜单应当根据不同的应用场景设计不同的指标权重,例如,医疗领域应该侧重推理准确性,教育领域更应关注交互友好度,避免“一刀切”排名。
3.算法伦理维度。算法歧视现象构成了个人数字化生存的伦理挑战。黄阳坤与俞雅芸研究发现,算法工程师“求真”“求准”的价值与业务目标挤压着趋向善良与正义的算法“向善”,在其认知中,技术系统应当反映现实而不超越现实,应当反映歧视而不扩大歧视[。而未来,人与大模型在伦理观念上如何相互介入相互构建,仍有待后来者的研究。
榜单既是技术进步的催化剂,也可能成为创新者的枷锁。当厂商沉迷于“数字竞速”,当政策资源被指标绑架,大模型的发展或将陷入“内卷化”陷阱。唯有打破指标崇拜,建立“技术-场景-伦理”三位一体的评估范式,国产大模型才能真正走出泡沫,迈向可持续的创新之路。
审核丨梁正 鲁俊群
[1]superCLUE,《中文大模型基准测评2025年3月报告》,2025.3
[2]superCLUE,2025年3月总排行榜,SuperCLUE,2025.3
[3]CSDN博客,SuperCLUE中文大模型排行榜(2023年7月)_2023年7月中文语言大模型榜单-CSDN博客,2023.7
[4]CSDN博客,SuperCLUE中文大模型最新排行榜(2023年11月) ChatGPT引领智能竞赛_superclue中文大模型排行榜-CSDN博客,2023.11
[5]Haonanli,CMMLU:Measuring massive multitask language understanding in Chinese,2024.1
[6]AgentEval: A Framework for Evaluating LLM Applications,2025.1
[7]周琳,董雪.刷榜跑分?AI评测不应走偏路线[N].新华每日电讯,2024-03-22(007).
[8]知乎,(9 封私信) 如何看待 SuperClue 的排名结果?- 知乎,2023.5
[9]机器之心,大模型走捷径「刷榜」?数据污染问题值得重视-36氪,2023.11
[10]通信世界,工信部:2025年要实施“人工智能+制造”行动,挖掘行业大模型场景应用,2024.12
[11]工信微报,国产大模型发展按下提速键_腾讯新闻,2025.2
[12]superCLUE,cluebenchmarks.com/static/superclue.html
[13]黄阳坤,俞雅芸.镜像与花园之辩:算法歧视争议下的价值目标与伦理实践——基于工程师的访谈[J].国际新闻界,2023,45(10):91-111
清华大学人工智能国际治理研究院(Institute for AI International Governance, Tsinghua University,THU I-AIIG)是2020年4月由清华大学成立的校级科研机构。依托清华大学在人工智能与国际治理方面的已有积累和跨学科优势,研究院面向人工智能国际治理重大理论问题及政策需求开展研究,致力于提升清华在该领域的全球学术影响力和政策引领作用,为中国积极参与人工智能国际治理提供智力支撑。
新浪微博:@清华大学人工智能国际治理研究院
微信视频号:THU-AIIG
Bilibili:清华大学AIIG
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢