

论文题目:KnowAgent: Knowledge-Augmented Planning for LLM-Based Agents
本文作者:朱雨琦(浙江大学)、乔硕斐(浙江大学)、欧翌昕(浙江大学)、邓淑敏(新加坡国立大学)、吕世伟(蚂蚁集团)、申月(蚂蚁集团)、梁磊(蚂蚁集团)、顾进捷(蚂蚁集团)、 陈华钧(浙江大学)、张宁豫(浙江大学)
发表会议:NAACL 2025 Findings
论文链接:https://arxiv.org/abs/2403.03101
代码链接:https://github.com/zjunlp/KnowAgent
欢迎转载,转载请注明出处

一、引言
大型语言模型(LLMs)在复杂推理任务中展现了极大的潜力,但在处理更复杂的挑战时,尤其是在通过生成可执行动作与环境进行交互时,仍显不足。这主要是因为智能体缺乏内置的动作知识,导致它们在任务解决过程中无法有效地指导规划轨迹,从而引发规划幻觉。
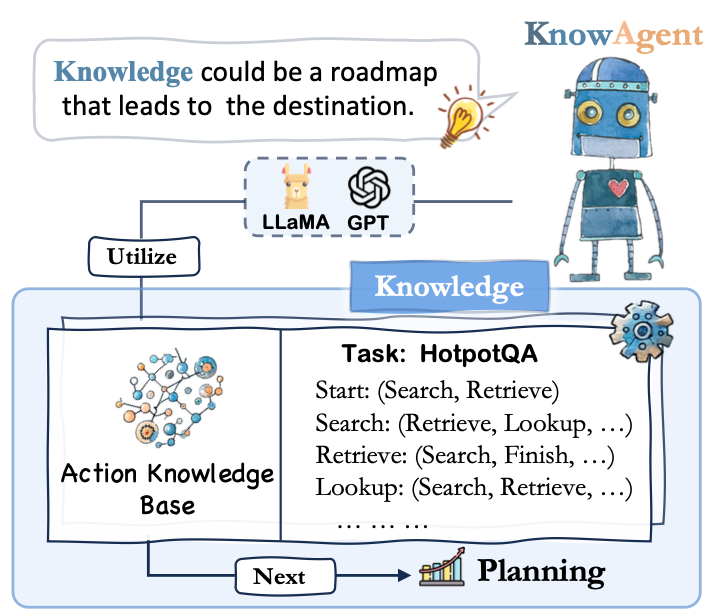
为了解决这一问题,我们提出了KnowAgent,旨在通过利用外部动作知识来增强轨迹合成,缓解其中出现的规划幻觉问题。我们的方法包括几个关键步骤。首先,我们提出了动作知识库,其中整合了与特定任务相关的动作规划知识。该数据库可以作为信息的外部储备,指导模型的动作生成过程。然后,通过将动作知识转化为文本,我们使模型能够深入理解这些知识,并进行轨迹合成。最后,通过一个知识型自我学习阶段,模型在迭代中不断优化其对动作知识的理解和应用。这一过程不仅增强了智能体的规划能力,也提升了其在复杂情境中的应用潜力。在HotpotQA和ALFWorld数据集的实验中,KnowAgent具有不错的性能表现。此外,我们也分析证明了该方法在减少规划幻觉方面的有效性,并展示了从大型语言模型中提取精炼动作知识的可行性,从而减少人工并为后续应用拓展提供新的方向。
二、方法
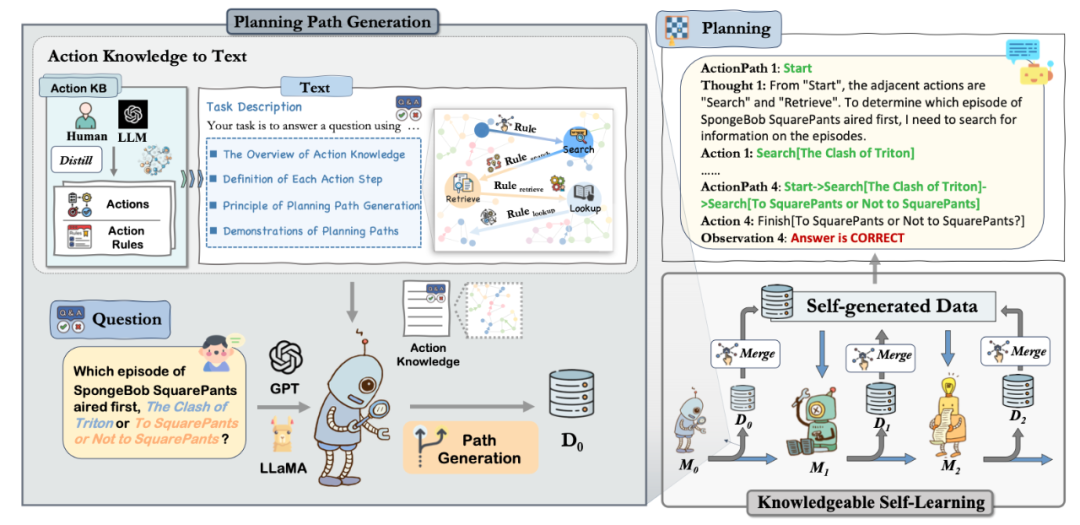
如图所示,我们的方法首先定义了动作知识这一概念。接着,我们让模型利用这些知识生成规划路径,并通过知识型自我学习机制不断优化这些路径,从而迭代地增强模型能力。
动作知识由定义的动作集合和控制动作转换的规则组成。这些规则基于动作之间的关系或特定任务的需求,描述了动作转换的逻辑和顺序。不同任务的动作知识被整合成一个动作知识库(Action KB),在动作生成和决策制定中起到关键作用,有助于减少规划幻觉。由于任务中涉及的动作知识非常多样,完全依靠人力手动构建既耗时又费力。为此,我们引入了GPT-4,让人类和模型协作提高构建效率。
图中展示了从动作知识到文本的转换过程。首先,我们通过识别任务特定需求的动作,利用先前的数据集分析和LLMs的内在知识,建立动作知识库。然后将这些信息转化为文本格式,以便后续操作。例,引用HotpotQA中的一条动作规则 - Search: (Search, Retrieve, Lookup, Finish)。这条规则指出,搜索可以通往多种路径:继续作为搜索、更改为检索或查找,或进展到结束。利用动作知识,模型使用这些见解来简化任务的规划过程。为了促进轨迹的合成,我们设计了特有的prompt,以补充基本任务描述,提供给大模型更多规划信息。
在这一阶段,我们引入了知识驱动的自我学习。目标是通过迭代微调,帮助模型更深入地理解行动知识。这个过程从初始训练集和未训练模型开始生成初始轨迹,经过过滤后用于进一步训练形成新模型。新模型在初始数据集上再评估,生成新的轨迹,这些轨迹与初始轨迹一起经过过滤和合并后用于进一步微调模型。从而在迭代过程中使模型能力得到进一步提升。
三、实验分析
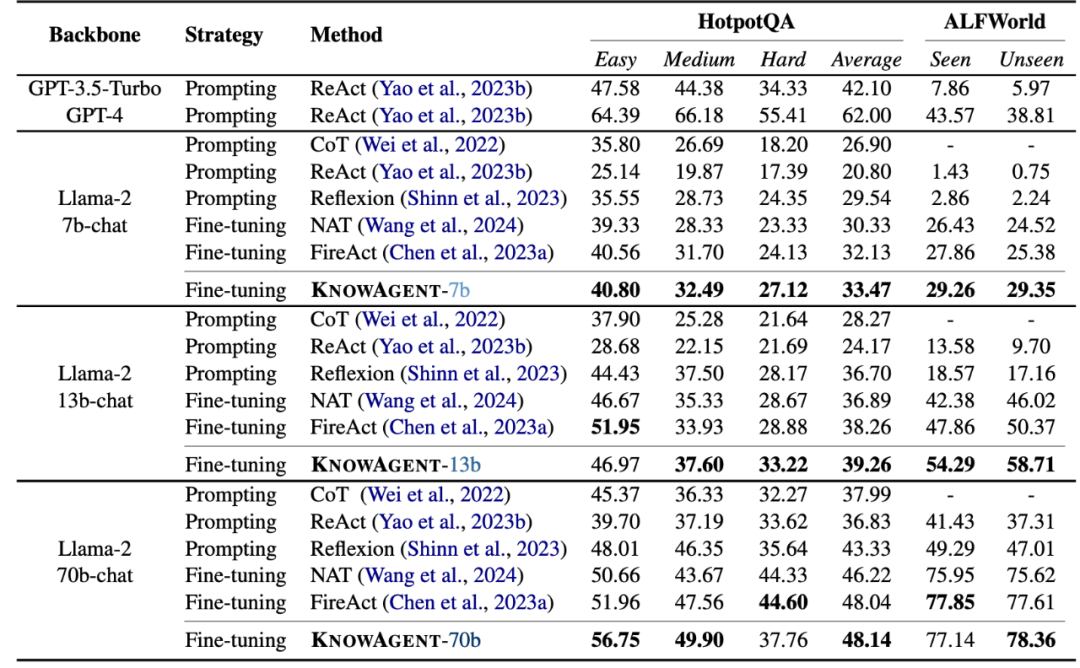
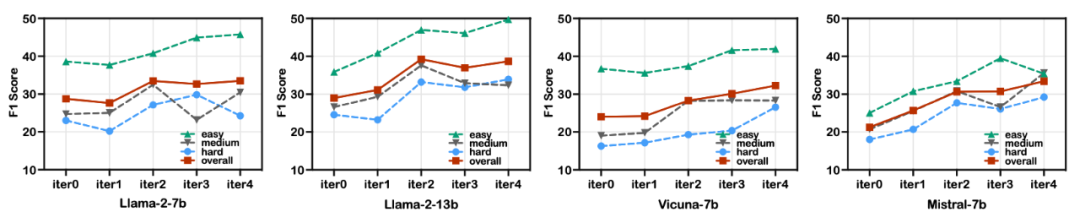
KnowAgent在不同的规模模型和数据集中有着较好的表现。同时,我们也在ALFWorld上进行了额外实验,将未经过微调的KnowAgent*与ReAct进行比较。结果也验证了动作知识本身的有效性。
对于实验结果,我们进行了以下分析:
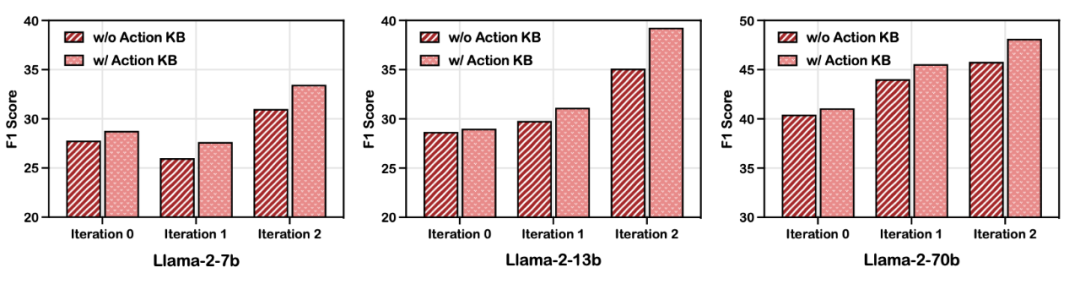

四、总结
在这项研究中,我们介绍了KnowAgent,这一框架旨在通过将外部动作知识纳入合成轨迹来减轻规划幻觉。我们的方法利用这些知识来引导模型的动作生成,并通过知识型自我学习阶段实现持续改进。通过对各种模型的实验,结果表明KnowAgent超越或与其他基准方法持平,展示了整合外部动作知识以简化规划过程和提高性能的优势。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢