
1.0 引言
Graph Neural Networks (GNNs), which have changed the way we process and interpret graph-structured data through deep learning techniques to capture domain related patterns and relationships within graphs, addressing tasks that range from node classification to link prediction and beyond. Traditional neural network architectures struggle with the non-Euclidean nature of graph data, however, GNNs are designed to handle its complexity by using specialised techniques that aggregate and process information from nodes’ local neighbourhoods. This localised approach enables the model to preserve the structural information of the graph, making it possible to perform accurate predictions and analyses directly from the graph topology. Additionally, the field of graph machine learning has advanced significantly with the integration of self-supervised learning and other optimisation methods. These methods address the challenges posed by graph data’s inherent complexity and the scarcity of labelled datasets.
图神经网络(GNNs)通过深度学习技术改变了我们处理和解释图结构数据的方式,通过捕获图中的领域相关模式和关系来应对从节点分类到链接预测等任务。传统的神经网络架构难以处理图数据的非欧几里得性质,然而,GNNs 通过使用专门的聚合和处理节点局部邻域信息的技巧来设计以处理其复杂性。这种局部化的方法使得模型能够保留图的拓扑结构信息,从而能够直接从图拓扑中进行准确的预测和分析。此外,图机器学习领域随着自监督学习和其他优化方法的集成而取得了显著进展。这些方法解决了图数据固有的复杂性和标签数据集稀缺带来的挑战。
Detailed insights into GNNs and their applications in graph machine learning are discussed in the survey paper titled “Graph Machine Learning in the Era of Large Language Models (LLMs)” by Wenqi Fan et al., available at https://arxiv.org/pdf/2404.14928v1. These methods enable GNNs to learn useful representations without extensive annotated data, enhancing their applicability and effectiveness across various domains. This article reviews and summarises some of these pivotal concepts.
在调查论文《大型语言模型时代的图机器学习》(LLMs)中,Wenqi Fan 等人讨论了 GNN 的详细见解及其在图机器学习中的应用,该论文可在 https://arxiv.org/pdf/2404.14928v1 找到。这些方法使 GNN 能够在没有大量标注数据的情况下学习有用的表示,从而增强了它们在各个领域的适用性和有效性。本文回顾和总结了这些关键概念。

Primary concepts on Graph Machine Learning (Source: Graph Machine Learning in the Era of Large Language Models research paper)
图机器学习的基本概念(来源:《大型语言模型时代的图机器学习》研究论文)
2.0 架构方法
There are several approaches to the core architectures used in the modelling of graph data, which are necessary for the application of deep learning to graphs. The research paper presents two prominent paradigms which are based on the concept of neighbourhood aggregation or message passing. In these, nodes aggregate information from their neighbours through iterative processes, which allows the network to learn complex representations of the graph’s topology.
在图数据建模中,有几种用于应用深度学习到图的核心架构方法。研究论文提出了两种基于邻域聚合或消息传递概念的突出范式。在这些范式中,节点通过迭代过程从其邻居那里聚合信息,这使得网络能够学习图拓扑的复杂表示。
2.1 Neighbourhood Aggregation-based Models
2.1 基于邻域聚合的模型
Neighbourhood aggregation-based models capture local graph structures by effectively leveraging the connectivity and features of nodes within a graph. They leverage local connectivity and feature information to generate node embeddings that can be used for a variety of downstream tasks such as node classification, link prediction, and even graph classification, by enabling the capture of local structural information without the need for explicit graph-level labels. The approaches below handle the permutation invariance of graphs, meaning the model’s output does not change if the nodes are reordered, by ensuring that the aggregation functions they use are order-invariant. This is crucial for maintaining the consistency of the model’s output regardless of node order in the input graph.
基于邻域聚合的模型通过有效地利用图内节点的连接性和特征来捕捉局部图结构。它们通过利用局部连接性和特征信息来生成节点嵌入,这些嵌入可以用于各种下游任务,如节点分类、链接预测,甚至图分类,通过允许捕捉局部结构信息,而无需显式图级标签。以下方法处理图的排列不变性,即模型的输出不会因节点重新排序而改变,通过确保它们使用的聚合函数是无序不变的。这对于保持模型输出的连续性至关重要,无论输入图中的节点顺序如何。
2.1.1 Graph Convolutional Networks
2.1.1 图卷积网络
Graph Convolutional Networks (GCNs) are inspired by the traditional convolutional neural networks (CNNs) used in image processing but are adapted to handle the unique challenges of graph data. In GCNs, the convolutional operations are redefined to operate directly on graphs. The key idea is to aggregate features from a node’s neighbours using a weighted sum, where the weights are typically determined by the edges in the graph or through learnable parameters. Each node’s features are then updated by combining its own features with aggregated neighbour features, often followed by a non-linear transformation. This process, repeated over several layers, allows GCNs to capture increasingly higher-order neighbourhood information, essentially learning a representation of each node that reflects not just its own attributes but also the characteristics of its surrounding network.
图卷积网络(GCN)受到传统卷积神经网络(CNN)在图像处理中的启发,但被调整为处理图数据的独特挑战。在 GCN 中,卷积操作被重新定义,以便直接在图上操作。关键思想是使用加权求和来聚合节点的邻居特征,其中权重通常由图中的边或通过可学习的参数确定。然后通过将节点自己的特征与聚合的邻居特征相结合来更新每个节点的特征,通常随后进行非线性变换。这个过程在几层中重复进行,使得 GCN 能够捕获越来越高级的邻域信息,本质上学习每个节点的表示,不仅反映其自身的属性,还反映其周围网络的特征。
2.1.2 GraphSAGE
GraphSAGE (Graph Sample and Aggregation) extends this concept by introducing a more flexible framework that can generate node embeddings inductively. Unlike GCNs, which require the entire graph to be processed at once, GraphSAGE is designed to work with different graph samples on the fly. This is particularly useful for large graphs or dynamic graphs where the entire structure is not known in advance. In GraphSAGE, node features are updated by sampling a fixed number of neighbours and then aggregating their features using various possible functions such as mean, LSTM, and pooling operations. The aggregation functions in GraphSAGE are also learned, which allows the model to adaptively determine the most effective way to combine neighbour information.
GraphSAGE(图样本与聚合)通过引入一个更灵活的框架扩展了这一概念,该框架可以归纳性地生成节点嵌入。与需要一次性处理整个图的 GCN 不同,GraphSAGE 旨在实时处理不同的图样本。这对于大型图或动态图特别有用,因为在这些图中,整个结构事先并不知道。在 GraphSAGE 中,节点特征通过采样一定数量的邻居并使用各种可能的函数(如均值、LSTM 和池化操作)聚合它们的特征来更新。GraphSAGE 中的聚合函数也是学习的,这使得模型能够自适应地确定最有效地组合邻居信息的方法。
2.2 Graph Transformer-based Models
2.2 基于图变换器的模型
Graph Transformer-based models are inspired by the success of transformers in natural language processing. These models harness the self-attention mechanism, which has proven effective for capturing dependencies in data. In the context of graphs, this mechanism allows each node to dynamically attend to other nodes across the entire graph, rather than just to immediate neighbours. This capability enables the model to learn global graph properties and relationships directly, addressing some of the limitations inherent in traditional graph neural networks that rely on localised neighbourhood information.
基于图变换器的模型受到了自然语言处理中变换器成功应用的启发。这些模型利用了自注意力机制,该机制已被证明在捕捉数据中的依赖关系方面非常有效。在图的情况下,这种机制允许每个节点动态地关注整个图中的其他节点,而不仅仅是直接邻居。这种能力使模型能够直接学习全局图属性和关系,从而解决了一些传统图神经网络固有的局限性,这些图神经网络依赖于局部邻域信息。
2.2.1 Graph-Bert
One notable adaptation of transformer technology to graph data is Graph-Bert, a model that applies the principles of the original BERT (Bidirectional Encoder Representations from Transformers) model, famous in NLP, to graph-structured data. Unlike conventional graph neural networks that operate with fixed neighbourhood sampling schemes, Graph-Bert integrates node features and topological structures without recursive neighbourhood expansion. It employs a positional encoding scheme to maintain the structural context of nodes within graphs, allowing it to process various graph sizes and topologies effectively. This approach enhances the model’s flexibility and scalability, making it suitable for tasks such as node classification and graph classification where understanding the broader context within the graph is crucial.
图机器学习在大型语言模型时代的显著应用之一是 Graph-Bert,这是一个将原始 BERT(来自 Transformer 的双向编码器表示)模型的原则应用于图结构数据的模型,BERT 在 NLP 领域广为人知。与使用固定邻域采样方案的常规图神经网络不同,Graph-Bert 在无需递归邻域扩展的情况下整合节点特征和拓扑结构。它采用位置编码方案来维护图中节点在结构上的上下文,使其能够有效地处理各种大小和拓扑的图。这种方法增强了模型的灵活性和可扩展性,使其适用于节点分类和图分类等任务,在这些任务中,理解图中的更广泛上下文至关重要。
2.2.2 GraphGPT
GraphGPT adapts the transformer architecture for generative tasks in graph domains, inspired by the success of GPT (Generative Pre-trained Transformer) in generating textual content. GraphGPT is specifically designed to generate graph structures by learning to predict node and edge formations in a sequence-to-sequence manner. This is achieved by representing the graph as a sequence of tokens, which includes both node and edge tokens, and training the model to predict parts of this sequence. The use of transformers in GraphGPT allows it to capture both local and global dependencies within the graph.
GraphGPT 将 Transformer 架构应用于图域中的生成任务,受到 GPT(生成预训练 Transformer)在生成文本内容方面成功的影响。GraphGPT 专门设计用于通过学习以序列到序列的方式预测节点和边形成来生成图结构。这是通过将图表示为包含节点和边标记的标记序列来实现的,并训练模型预测该序列的部分。GraphGPT 中 Transformer 的使用允许它捕捉图中的局部和全局依赖关系。
3.0 Optimising GNNs
With the growing complexity of graph-based tasks and the scarcity of labelled data, self-supervised learning has emerged as a powerful strategy for training GNNs. The research paper covers two main aspects on how self-supervised learning paradigms are utilised to train GNNs using unlabeled data effectively.
随着基于图的任务复杂性的增加和标记数据的稀缺,自监督学习已成为训练 GNN 的一种强大策略。该研究论文涵盖了两个主要方面,即如何利用自监督学习范式有效地使用未标记数据来训练 GNN。
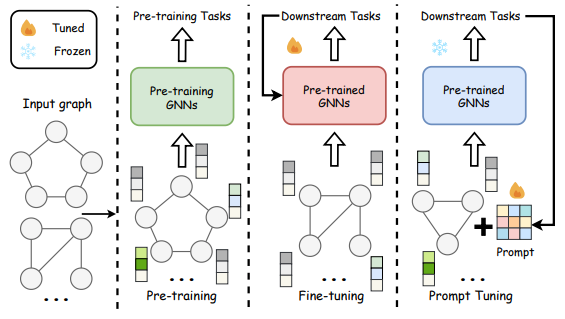
A comparison of pre-training, fine-tuning and prompt-tuning (Source: Graph Machine Learning in the Era of Large Language Models research paper)
预训练、微调和提示调整的比较(来源:《大型语言模型时代的图机器学习》研究论文)
3.1 Graph Pretext Tasks
3.1 图预训练任务
Graph Pretext Tasks enable GNNs to derive significant insights from graph data by engaging with various auxiliary problems designed specifically to exploit the inherent structure and content of graphs. By focusing on internal graph characteristics rather than relying on external labels, these tasks allow GNNs to develop node embeddings that reflect both local and global graph properties. These pretext tasks are not only fundamental in teaching GNNs to decode complex relationships within graph data but also instrumental in enhancing their predictive performance across a myriad of real-world applications.
图预训练任务使图神经网络(GNNs)能够通过参与各种辅助问题来从图数据中提取重要见解,这些辅助问题专门设计用于利用图固有的结构和内容。通过关注内部图特征而不是依赖外部标签,这些任务允许 GNNs 开发出反映局部和全局图属性的节点嵌入。这些预训练任务不仅对于教授 GNNs 解码图数据中的复杂关系至关重要,而且对于提高它们在众多现实世界应用中的预测性能也具有重要作用。
3.1.1 Graph Contrastive Learning
3.1.1 图对比学习
In graph contrastive learning, the objective is to distinguish between nodes, edges, or subgraphs based on their structural and feature-based differences and similarities. By training a model to identify which components of a graph are similar to or different from one another, GNNs can learn rich and discriminative embeddings for each node or subgraph. Techniques typically involve generating positive samples (similar nodes or subgraphs) and negative samples (dissimilar ones) and designing a loss function that maximises the distance between embeddings of dissimilar samples while minimising the distance between similar ones. This form of learning is particularly effective in capturing nuanced patterns and dependencies within the graph, which are crucial for tasks such as anomaly detection, community detection, and node classification.
在图对比学习中,目标是根据结构和基于特征的不同和相似性来区分节点、边或子图。通过训练模型来识别图中哪些组件彼此相似或不同,GNN 可以学习到每个节点或子图的丰富和判别性嵌入。通常涉及生成正样本(相似节点或子图)和负样本(不相似的),并设计一个损失函数,最大化不同样本嵌入之间的距离,同时最小化相似样本之间的距离。这种学习形式特别有效于捕捉图中的细微模式和依赖关系,这对于异常检测、社区检测和节点分类等任务至关重要。
3.1.2 Graph Generation
3.1.2 图生成
Graph generation tasks focus on the ability of GNNs to predict and reconstruct graph structures. This can involve predicting missing parts of a graph, generating entirely new graphs based on learned patterns, or even predicting future states of dynamic graphs. The generation process typically uses a sequence-to-sequence model or variational autoencoder framework where the model learns to output a sequence of nodes and edges that constitute a graph. By repeatedly generating graphs and comparing them to real examples, the GNN learns to internalise the rules and distributions governing the formation and evolution of graph structures. This pretext task is invaluable for applications such as network design, where the goal is to optimise the topology of a network.
图生成任务关注于图神经网络预测和重建图结构的能力。这可能涉及预测图的缺失部分,根据学习到的模式生成全新的图,甚至预测动态图的未来状态。生成过程通常使用序列到序列模型或变分自编码器框架,模型学习输出构成图的节点和边序列。通过反复生成图并与真实示例进行比较,GNN 学习内部化控制图结构形成和演化的规则和分布。这项前缀任务对于网络设计等应用非常有价值,其目标是优化网络的拓扑结构。
3.1.3 Graph Property Prediction
3.1.3 图属性预测
In this task, GNNs are trained to predict properties of the graph, which could be global (pertaining to the entire graph) or local (pertaining to individual nodes or edges). Examples of properties include the centrality of nodes, the presence of specific substructures, or the stability of the graph under certain conditions. This form of learning requires the model to understand both the local interactions and the global structure of the graph to make accurate predictions. It’s particularly useful for tasks where understanding the underlying physical, biological, or social properties of a system is essential, such as predicting protein interfaces in biological networks or resilience of social networks under stress.
在这个任务中,图神经网络被训练来预测图的各种属性,这些属性可以是全局的(与整个图相关)或局部的(与单个节点或边相关)。属性示例包括节点的中心性、特定子结构的存在或图在特定条件下的稳定性。这种学习形式要求模型理解图中的局部交互和全局结构,以便做出准确的预测。这对于理解系统的潜在物理、生物或社会属性至关重要的任务特别有用,例如预测生物网络中的蛋白质界面或社会网络在压力下的弹性。
3.2 Downstream Adaptation
3.2 下游适配
In the process of downstream adaptation for GNNs, the techniques of unsupervised representation learning, fine-tuning, and prompt-tuning are pivotal in refining the model to address specific tasks effectively. Each of these techniques plays a distinct role in transitioning from generalised pre-training to task-specific performance enhancement and offer distinct advantages and can be chosen based on the specific requirements of the task, the availability of labelled data, and the desired level of adaptation.
在 GNN 的下游适应过程中,无监督表示学习、微调和提示调优等技术对于优化模型以有效解决特定任务至关重要。这些技术各自在从泛化预训练过渡到特定任务性能提升的过程中扮演着独特的角色,提供了不同的优势,可以根据任务的特定要求、标记数据的可用性和所需的适应程度来选择。
3.2.1 Unsupervised Representation Learning
3.2.1 无监督表示学习
Unsupervised representation learning focuses on leveraging the representations learned by GNNs during pre-training without using any labelled data. In this approach, the model utilises the embeddings it generated during the pretext tasks to perform downstream tasks. For example, a GNN might be used to generate embeddings that capture the structural and feature-based properties of nodes within a graph, which can then be applied to tasks like clustering or anomaly detection where specific labels are not necessary. This method is particularly useful in scenarios where labelled data is scarce or when the task benefits from rich, feature-based representations that do not rely on supervised training signals.
无监督表示学习侧重于利用 GNN 在预训练期间学习到的表示,而不使用任何标记数据。在这种方法中,模型利用它在预训练任务中生成的嵌入来执行下游任务。例如,GNN 可以用来生成嵌入,捕捉图中节点的结构和基于特征的属性,这些属性可以应用于不需要特定标签的任务,如聚类或异常检测。这种方法在标记数据稀缺或任务受益于丰富、基于特征的表示而不依赖于监督训练信号的情况下特别有用。
3.2.2 Fine-Tuning
3.2.2 微调
Fine-tuning is a more direct adaptation method where the pre-trained GNN is adjusted with a relatively small amount of labelled data. This technique fine-tunes the model parameters to minimise the loss on specific tasks such as node classification or link prediction. During fine-tuning, the entire network or parts of it are trained (or fine-tuned) using the downstream task’s training data, which adjusts the weights learned during the pre-training to better suit the specific characteristics and requirements of the target task. This method ensures that the model not only retains the general capabilities developed during pre-training but also enhances its ability to perform well on tasks that are closely aligned with the end goals of the application.
微调是一种更直接的适应方法,其中预训练的 GNN 通过相对少量的标记数据进行调整。这种技术通过微调模型参数来最小化特定任务(如节点分类或链接预测)上的损失。在微调过程中,整个网络或其部分使用下游任务的训练数据进行训练(或微调),这调整了预训练期间学习的权重,以更好地适应目标任务的特定特征和需求。这种方法确保模型不仅保留了预训练期间开发的通用能力,而且增强了其在与应用程序最终目标紧密相关的任务上表现良好的能力。
3.2.3 Prompt-Tuning
3.2.3 提示微调
Prompt-tuning is a novel adaptation technique inspired by advances in natural language processing, particularly in the context of large language models like GPT-3. In prompt-tuning, the GNN is provided with task-specific prompts or instructions that guide the model to generate the desired output using its pre-trained knowledge. This does not involve traditional fine-tuning of the model’s weights; instead, it relies on the model’s ability to respond to structured cues or prompts that frame the task in a way that the model can apply its pre-existing knowledge. This method is particularly effective for tasks where the model needs to generalise from broad pre-trained knowledge to specific applications without extensive retraining.
提示调整是一种受自然语言处理领域最新进展启发的创新适应技术,特别是在 GPT-3 等大型语言模型背景下。在提示调整中,图神经网络(GNN)被提供与任务特定的提示或指令,引导模型利用其预训练知识生成所需输出。这并不涉及模型权重的传统微调;相反,它依赖于模型对结构化提示或提示的响应能力,这些提示以模型能够应用其现有知识的方式对任务进行框架化。这种方法特别适用于模型需要从广泛的预训练知识泛化到特定应用,而无需大量重新训练的任务。
4.0 结论
The utilisation of Graph Neural Networks (GNNs) in machine learning represents a pivotal advancement in the processing and analysis of graph-structured data. This article reviews a survey paper by Wenqi Fan et al., that highlights the specialised capabilities of GNNs in managing complex data, emphasising their ability to preserve structural integrity while effectively leveraging local node information. We have summarised the main architectural frameworks underpinning GNN technology, with a particular focus on neighbourhood aggregation-based models and graph transformer-based models, as well as the role of self-supervised learning in enhancing GNN capabilities.
图神经网络(GNN)在机器学习中的应用代表了在处理和分析图结构数据方面的关键进步。本文回顾了 Wenqi Fan 等人的一篇综述论文,该论文突出了 GNN 在管理复杂数据方面的专门能力,强调它们在保持结构完整性的同时,有效地利用局部节点信息的能力。我们总结了支撑 GNN 技术的核心架构框架,特别关注基于邻域聚合的模型和基于图变换器的模型,以及自监督学习在增强 GNN 能力中的作用。
Furthermore, the implementation of self-supervised learning strategies within the graph machine learning arena demonstrates how these methods enable GNNs to generate meaningful data representations without extensive reliance on labelled datasets. This approach is particularly beneficial in environments where acquiring comprehensive labelled data is challenging or impractical. Overall, the research paper presents a comprehensive review of the current advancements in GNN technology and methodologies, underscoring the ongoing evolution of this field as it adapts to new challenges and leverages deep learning more effectively. As GNNs grow increasingly sophisticated, their impact is expected to increase, driving further innovations in graph-based data analysis and applications.
此外,在图机器学习领域实施自监督学习策略,展示了这些方法如何使 GNN 能够生成有意义的特征表示,而无需大量依赖标记数据集。这种方法在获取全面标记数据具有挑战性或不切实际的环境中尤其有益。总体而言,该研究论文全面回顾了当前 GNN 技术和方法的发展,强调了该领域如何适应新挑战并更有效地利用深度学习。随着 GNN 变得越来越复杂,其影响预计将增加,推动基于图的数据分析和应用方面的进一步创新。
5.0 参考文献
Pan, S., Luo, L., Wang, Y., Chen, C., Wang, J., & Wu, X. (2024). Unifying Large Language Models and Knowledge Graphs: A Roadmap. arXiv:2306.08302v3 [cs.CL].
C. Rosset et al., “Knowledge-aware Language Model Pretraining,” arXiv:2007.00655, 2020.
P. Lewis et al., “Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks,” in Proceedings of NeurIPS, vol. 33, 2020, pp. 9459–9474.
Y. Zhu et al., “LLMs for Knowledge Graph Construction and Reasoning: Recent Capabilities and Future Opportunities,” arXiv:2305.13168, 2023.
Z. Zhang et al., “PretrainKGE: Learning Knowledge Representation from Pretrained Language Models,” in Proceedings of EMNLP Findings, 2020, pp. 259–266.
A. Kumar et al., “Building Knowledge Graph Using Pre-trained Language Model for Learning Entity-aware Relationships,” in Proceedings of the 2020 IEEE International Conference on Computing, Power and Communication Technologies (GUCON), 2020, pp. 310–315.
X. Xie et al., “From Discrimination to Generation: Knowledge Graph Completion with Generative Transformer,” in Proceedings of WWW, 2022, pp. 162–165.
Z. Chen et al., “Incorporating Structured Sentences with Time-Enhanced BERT for Fully-Inductive Temporal Relation Prediction,” in Proceedings of SIGIR, 2023.
Kipf, T. N., & Welling, M. (2017). Semi-supervised classification with graph convolutional networks. Paper presented at the International Conference on Learning Representations (ICLR).
Hamilton, W. L., Ying, R., & Leskovec, J. (2017). Inductive representation learning on large graphs. Paper presented at the Neural Information Processing Systems (NeurIPS).
Zhang, J., Shi, X., Xie, J., Ma, H., King, I., & Yeung, D.-Y. (2020). Graph-Bert: Only attention is needed for learning graph representations.
Rong, Y., Bian, Y., Xu, T., Xie, W., Wei, Y., Huang, W., & Huang, J. (2020). Self-supervised graph transformer on large-scale molecular data.
Liao, R., Li, Y., Song, Y., Wang, S., Hamilton, W., Duvenaud, D., Urtasun, R., & Zemel, R. (2019). Efficient graph generation with graph recurrent attention networks. Paper presented at NeurIPS 2019.
Sun, K., Lin, Z., & Zhu, Z. (2020). InfoGraph: Unsupervised and semi-supervised graph-level representation learning via mutual information maximization. Paper presented at ICLR 2020.
You, J., Ying, R., Ren, X., Hamilton, W., & Leskovec, J. (2018). GraphRNN: Generating realistic graphs with deep auto-regressive models. Paper presented at ICML 2018.
Zhang, Z., Cui, P., & Zhu, W. (2020). Deep learning on graphs: A survey. IEEE Transactions on Knowledge and Data Engineering.
Grover, A., & Leskovec, J. (2016). node2vec: Scalable feature learning for networks. Paper presented at KDD 2016.
Sanh, V., Wolf, T., & Rush, A. (2020). A Primer in BERTology: What we know about how BERT works. arXiv preprint arXiv:2002.12327.



内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢