1. 谷歌欲 AI 技术封锁:不愿对外分享前沿成果2. OpenAI 学院正式上线:AI 知识、技能免费学4. 工作 8 年后,Meta AI 主管即将辞职5. 软银:计划为“星际之门”筹集 160 亿美元3. Agent S2:Computer Use agent 通才-专家框架5. AI 推理全靠背?o1、R1 答不对小学推理问题
据外媒消息,Google DeepMind 已开始不愿发布其前沿研究成果,因为它试图在争夺人工智能(AI)行业主导地位的竞争中保持优势。7 位在职和已离职研究科学家称,由诺奖得主 Demis Hassabis 领导的这一团队引入了更严格的审查程序,这使得发表有关 AI 的研究变得更加困难。他们称,该团队最不愿意分享那些可能被竞争对手利用、让 Gemini AI 处于竞争劣势的论文。“一位前研究人员表示:“不能发表论文,对研究人员来说就是毁掉职业生涯的行为。”值得一提的是,当前使得生成式 AI 领域爆发的基础便来自谷歌的 Transformers 论文。2. OpenAI学院正式上线:AI知识、技能免费学今日凌晨,OpenAI 正式上线了 OpenAI 学院(OpenAI Academy)。每个人都可以通过视频和活动学习人工智能(AI)知识或技能,而且是免费的。目前,OpenAI 学院已经提供了几十个小时的内容,还在持续更新中。OpenAI 首席执行官 Sam Altman 在 X 上发帖称,由 GPT-4o 模型驱动的图片生成功能现已向所有用户开放。由于该工具可以被用于将图片转换成日本动画公司吉卜力工作室(Studio Ghibli)的风格,吸引了越来越多的用户使用,同时也引发了人们对版权和该公司所使用的训练数据的关注,因为两者风格相似。此外,OpenAI 昨日表示,它以 3000 亿美元的估值获得了由软银领投的 400 亿美元融资。目前,ChatGPT 的周活跃用户已达 5 亿,月活跃用户达 7 亿,付费用户达到了 2000 万。据外媒报道,在 Meta 工作 8 年的 AI 研究部门负责人 Joelle Pineau 表示,她计划于今年 5 月离职。她在社交媒体上写道:“今天,随着世界发生重大变化,随着 AI 竞赛加速,随着 Meta 准备开启新的篇章,现在是时候为其他人创造空间去从事这项工作了。”Pineau 在麦吉尔大学担任计算机科学教授,她一直是 Meta 以“开源”方式构建 AI 系统(如开源大语言模型 Llama)的代表。据外媒报道,软银正在为“星际之门”项目寻求高达 165 亿美元的融资,这将是这家企业有史以来最大的一笔以美元计价的融资。知情人士表示,这笔过桥贷款可以帮助软银主导 OpenAI 的 400 亿美元融资,该轮融资被称为有史以来最大的一轮融资,OpenAI 估值将达到 3000 亿美元。软银首席执行官孙正义此前表示,该公司将在未来 4 年内在美国投资 1000 亿美元,创造至少 10 万个以 AI 和相关基础设施为重点的工作岗位。
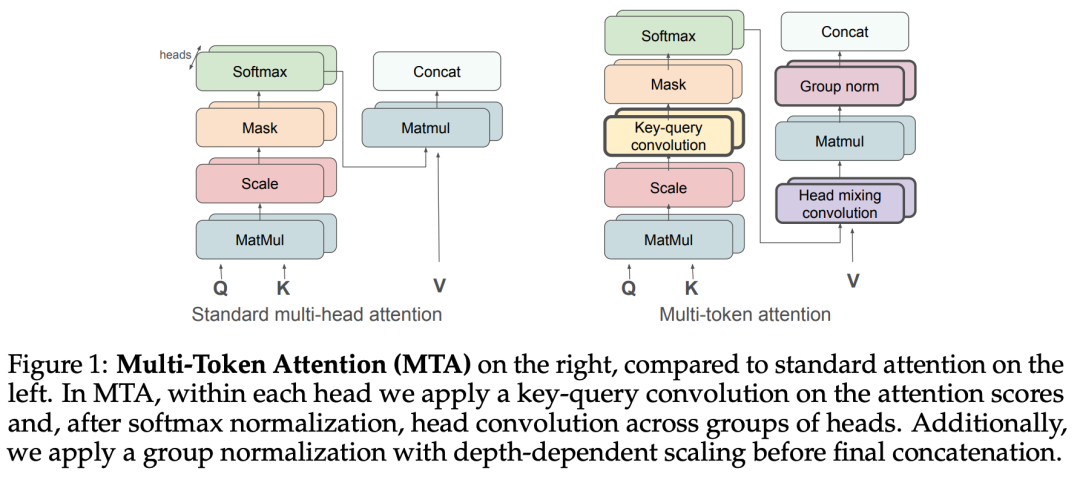
软注意力(Soft attention)是大语言模型(LLM)在给定上下文中定位相关部分的关键机制。然而,单个注意力权重仅由单个查询和 key token 向量的相似性决定。这种“单一 token 注意力”限制了用于将相关部分与上下文其他部分区分开来的信息量。为此,Meta 团队提出了多 token 注意力(MTA),其允许 LLM 同时将多个查询和 key 向量作为其注意力权重的条件。这是通过对查询、key 和(注意力)头进行卷积操作来实现的,允许附近的查询和 key 影响彼此的注意力权重,从而实现更精确的注意力。
广泛的评估证明,MTA 在一系列主流基准测试中实现了更高的性能。值得注意的是,在标准语言建模任务和需要在长上下文中搜索信息的任务中,它的性能都优于 Transformer 基线模型。
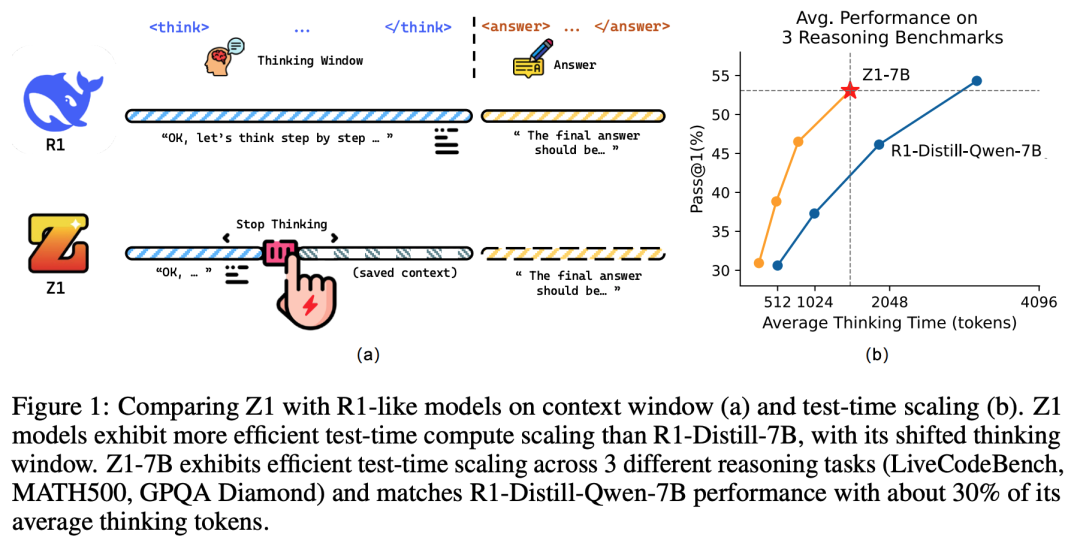
论文链接:https://arxiv.org/abs/2504.00927大语言模型(LLM)可以通过测试时计算扩展来实现更强的复杂问题解决能力,但这往往需要更长的上下文和大量的推理 token 成本。来自清华大学和耶鲁大学的研究团队提出了一种高效的测试时扩展方法,其可以在与代码相关的推理轨迹上训练 LLM,从而在保持性能的同时减少多余的思考 token。Z1-7B 使用长短轨迹数据进行训练,并配备了 Shifted Thinking Window,可以根据问题的复杂程度调整推理水平,并在不同的推理任务中表现出高效的测试时扩展能力,只需约 30% 的平均思考 token 就能达到 R1-Distill-Qwen-7B 的性能。值得注意的是,Z1-7B 只对代码轨迹进行了微调,但在更广泛的推理任务中表现出了通用性。论文链接:https://arxiv.org/abs/2504.008103. Agent S2:Computer Use agent通才-专家框架
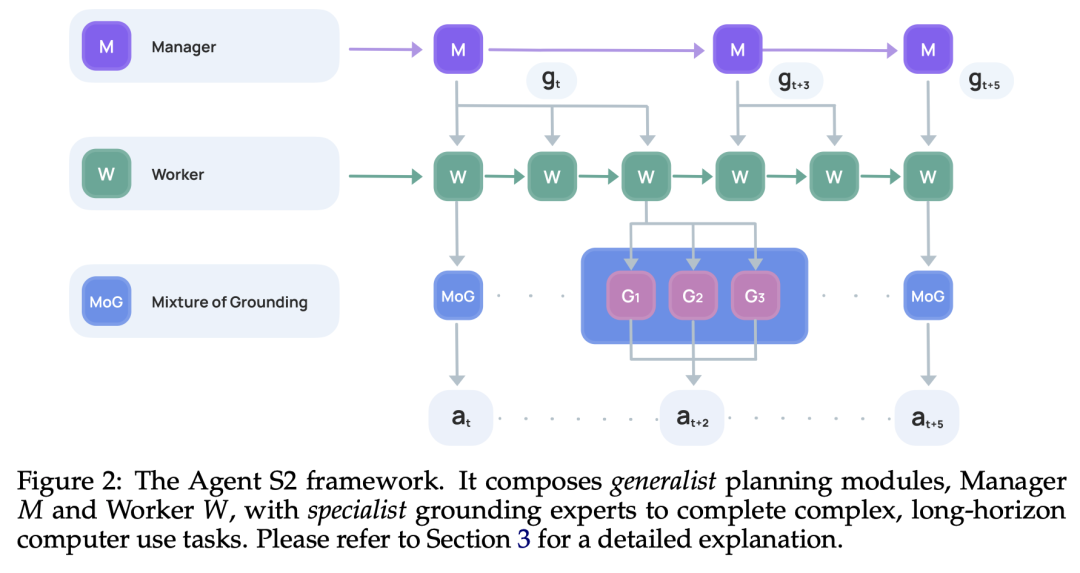
当前的 agent 面临着以下挑战:GUI 元素的不精确接地(grounding)、长程任务规划困难,以及依赖单一通用模型完成不同认知任务的性能瓶颈。
Simular Research 团队推出了 Agent S2 框架,其可以将认知责任分派给不同的通才和专才模型。他们提出了一种新颖的混合接地技术(Mixture-of-Grounding),以实现精确的 GUI 定位,并引入了主动分层规划(Proactive Hierarchical Planning),根据不断变化的观察结果,在多个时间尺度上动态完善行动计划。
评估结果表明,Agent S2 在 Computer use 基准测试中取得了 SOTA 性能。
论文链接:https://arxiv.org/abs/2504.00906
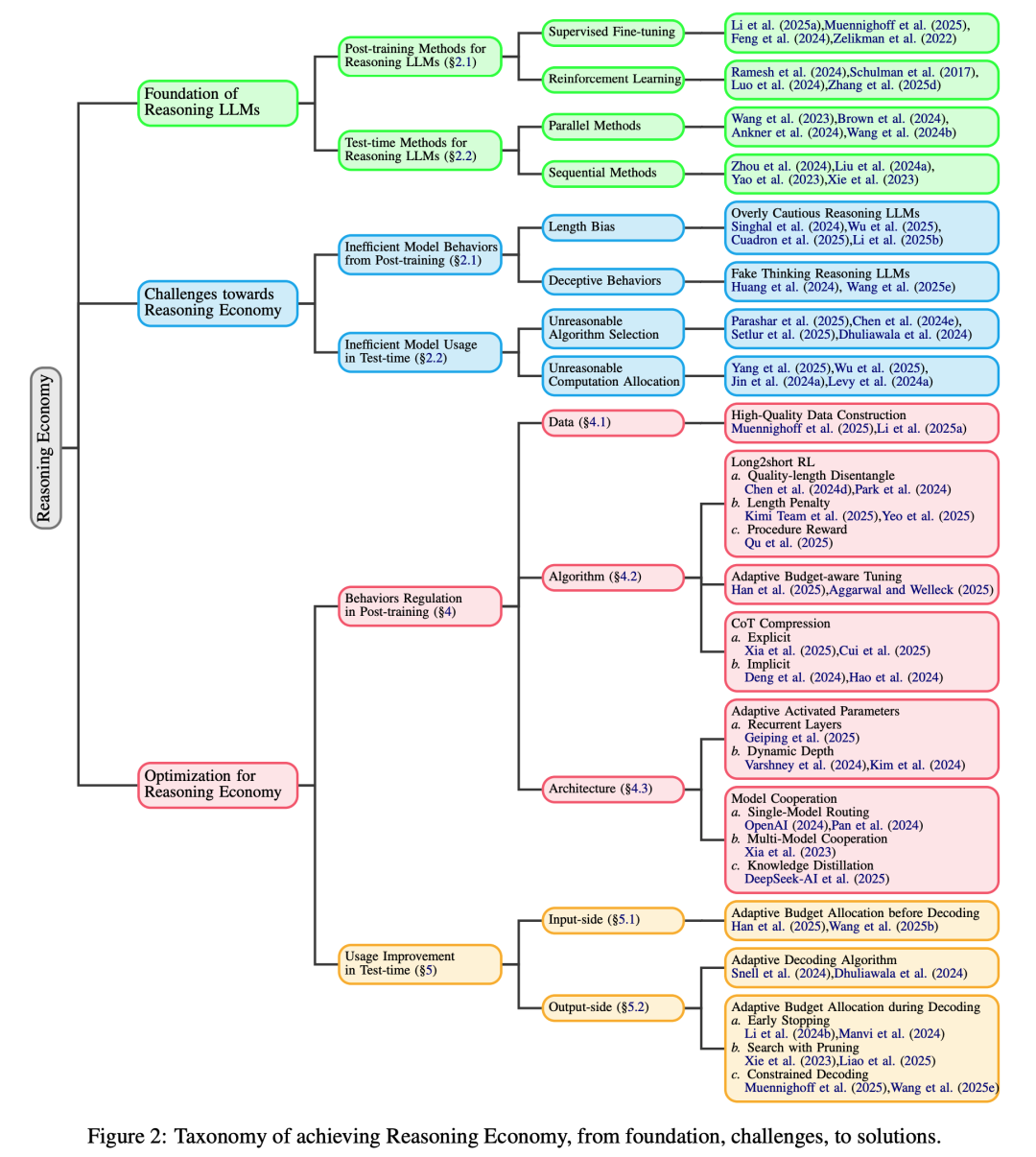
4. 综述:实现LLM的「推理经济性」
大语言模型(LLM)初步具备了执行复杂推理任务的能力,正在从快速直观的思维(系统 1)过渡到缓慢深入的推理(系统 2)。然而,平衡性能(收益)和计算成本(预算)之间的权衡至关重要,这就产生了推理经济性(reasoning economy)的概念。
来自香港中文大学和澳门大学的研究团队及其合作者全面分析了 LLM 后训练和测试时推理阶段的推理经济性,包括推理低效的原因、不同推理模式的行为分析,以及实现推理经济性的潜在解决方案。
论文链接:https://arxiv.org/abs/2503.24377
5. AI推理全靠背?o1、R1答不对小学推理问题
按照人类的标准,大语言模型(LLM)的推理能力是否真的来自于真正的智能,还是它们只是在背诵互联网水平训练中目睹的解决方案?
字节跳动 Seed 团队提出了多模态基准 RoR-Bench,用于检测 LLM 在被问及简单推理问题但条件发生微妙变化时的背诵行为。他们发现,现有的主流 LLM 一致表现出极其严重的背诵行为;只需改变条件中的一个短语,OpenAI-o1 和 DeepSeek-R1 等模型就会在小学水平的算术和推理问题上损失 60% 的性能。
论文链接:https://arxiv.org/abs/2504.00509
整理:锦鲤
如需转载或投稿,请直接在公众号内留言
内容中包含的图片若涉及版权问题,请及时与我们联系删除




评论
沙发等你来抢