

行业动态
1.两名前 OpenAI 高管加入 Murati 新公司
2.a16z 正寻求募集 200 亿美元,用于 AI 公成长期投资
3.北京:智能算力规模超 2.2 万 P,支持 MaaS 平台集聚发展
4.北京:支持跨领域、多任务、自规划的通用智能体发展
热门论文
1.Hugging Face:重新定义小型高效多模态模型
2.为何推理重要?一文读懂多模态推理
3.QAlign:一种新的测试时对齐方法
前 OpenAI 首席技术官 Mira Murati 的新公司 Thinking Machines Lab 迎来了两位新顾问:前 OpenAI 首席研究官 Bob McGrew 和前 OpenAI研究员 Alec Radford。
McGrew 于 2017 年加入 OpenAI,并先后担任研究副总裁、首席研究官,于 2024 年 9 月离职;Radford 是 GPT 研究论文的主要作者,在 OpenAI 工作近 10 年后选择离开。
目前,这家公司的员工中有数十名来自 OpenAI 和 Google DeepMind 等顶级 AI 实验室。
据路透社消息,风险投资公司 Andreessen Horowitz 正在寻求筹集约 200 亿美元,这将是该公司历史上规模最大的基金。
消息人士称,a16z 已告知有限合伙人,该基金将致力于人工智能公司的成长期投资,并吸引热衷于投资美国公司的全球投资者。此外,相当一部分资金将用于该公司投资组合中对人工智能公司的后续投资。
据科创板日报报道,在阿里云 AI 势能大会上,北京市政府副秘书长杨烁表示,目前,在京人工智能企业已超 2400 家,核心产业营收超 3000 亿。备案 123 款大模型产品,数量全国第一。数据基础制度先行区发布 100 个大模型高质量数据集,数据总量 150PB。智能算力规模超 2.2 万 P,京津冀蒙环京算力供给廊道已形成。
他表示,下一步,将协同各方力量,加快大模型的行业深度应用:一是支持 MaaS 平台在京集聚发展,通过“算力券”支持培育一批有代表性的示范工程和标杆产品,通过“数据券”政策支持一批“首开放”数据集;二是推动行业软件企业全面具备模型能力,优先在基础软件、工业软件、事务处理软件、新型安全软件等领域组织策划重点项目;三是支持软件企业加快智能化技术改造;四是健全人工智能应用服务生态。
据财联社报道,北京市经济和信息化局印发《北京市关于支持信息软件企业加强人工智能应用服务能力行动方案(2025年)》,深化北京市通用人工智能产业创新合作伙伴机制,组织信息软件企业、大模型厂商与金融、能源、交通、安防、教育、医疗等行业龙头用户结成伙伴,合作形成行业大模型落地的标杆示范典型案例,通过“首方案”支持,对解决方案中非硬件部分采购额给予最高不超过3000万元奖励。
支持创新主体开发跨领域、多任务、自规划的通用智能体,对已取得生成式人工智能产品服务上线批号、首次在各类应用商店上架的通用智能体,优先协调算力保障,并对运营服务中调用算力和模型成本给予最高不超过 3000 万元支持。
热门论文
1. Hugging Face:重新定义小型高效多模态模型
计算资源的大量需求,限制了大型视觉语言模型(VLM)在移动和边缘设备上的部署。而较小的 VLM 通常照搬大型模型的设计选择,如大量图像 token 化,导致 GPU 内存使用效率低下,设备应用的实用性受到限制。
在这项工作中,来自 Hugging Face 和斯坦福大学的研究团队提出了 SmolVLM,这是一系列专为资源节约型推理而设计的紧凑型多模态模型。他们系统地探索了架构配置、token 化策略和数据整理,以优化低计算开销。通过这些探索,他们确定了一些关键的设计选择,以最小的内存占用在图像和视频任务中大幅提高性能。他们的小模型 SmolVLM-256M 在推理过程中使用了不到 1GB 的 GPU 内存,尽管开发时间相差 18 个月,但其性能却超过了 300 倍之多的 Idefics-80B 模型。他们的大模型有 2.2B 个参数,可与消耗两倍 GPU 内存的 SOTA VLM 相媲美。SmolVLM 模型还具备强大的视频理解能力。
结果表明,战略性的架构优化、积极而高效的 token 化以及精心策划的训练数据可显著提高多模态性能,从而促进在更小的规模上进行实用而节能的部署。
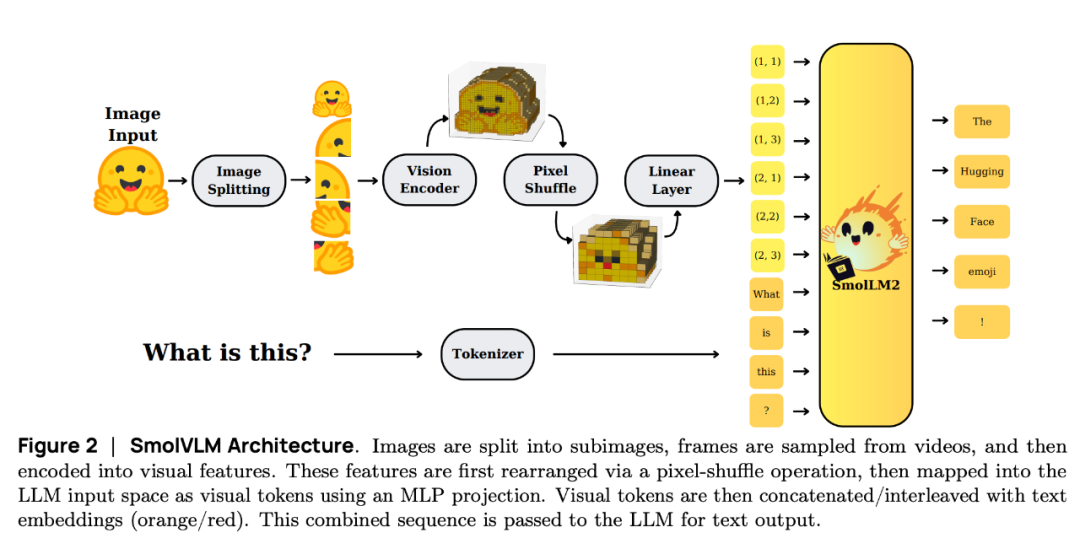
论文链接:https://arxiv.org/abs/2504.05299
推理是人类智能的核心,使人类能够结构化地解决各种任务中的问题。大语言模型(LLM)在算术、常识和符号领域的推理能力不断增强。然而,如何有效将这些能力扩展到多模态环境中仍是一个巨大的挑战。多模态推理带来了复杂性,例如处理跨模态的冲突信息,这就要求模型采用更好的解释策略。要应对这些挑战,不仅需要复杂的算法,还涉及评估推理准确性和一致性的鲁棒方法。
在这项工作中,来自罗切斯特大学的研究团队及其合作者对文本和多模态 LLM 中的推理技术进行了简明而概述。通过全面的比较,他们明确提出了推理的核心挑战和机遇,并重点介绍了后训练优化和测试时推理的实用方法。
增加测试时计算已成为提高语言模型性能的一个有前途的方向,尤其是在由于计算限制或私人模型权重导致模型微调不切实际或不可能的情况下。然而,现有的使用奖励模型(RM)的测试时搜索方法往往会随着计算量的增加而降低质量,这是由于对本质上并不完美的奖励代理进行了过度优化。
在这项工作中,华盛顿大学团队提出了一种新的测试时对齐方法 QAlign。当扩展测试时计算时,QAlign 会收敛到从每个单个提示的最优对齐分布中采样。通过采用马尔可夫链蒙特卡洛技术在文本生成方面的进展,这一方法可以在不修改基础模型甚至不需要访问 logit 的情况下实现更好的对齐输出。他们在使用特定任务 RM 的数学推理基准(GSM8K 和 GSM-Symbolic)上演示了 QAlign 的有效性,与现有的测试时计算方法(如 best-of-n 和 majority voting)相比,QAlign 显示了持续的改进。此外,当使用在 Tulu 3 偏好数据集上训练的更现实的 RM 时,QAlign 在各种数据集(GSM8K、MATH500、IFEval、MMLU-Redux 和 TruthfulQA)上的表现优于 DPO、best-of-n、majority voting 和 weighted majority voting。
这一方法是一种实用的解决方案,可在测试时使用额外的计算对语言模型进行对齐,而不会降低性能,扩大了无需进一步训练即可从现成语言模型中获得的能力范围。
论文链接:https://arxiv.org/abs/2504.03790
4. 北大团队提出 LLM 推理生成式评估框架 KUMO
大语言模型(LLM)是真正具有推理能力,还是只是从大量网络抓取的训练数据集中回忆答案?公开发布的基准一旦被纳入后续的 LLM 训练集,就不可避免地会受到污染,从而损害其作为忠实评估的可靠性。
为了解决这个问题,来自北京大学的研究团队及其合作者提出了一个生成式评估框架——KUMO,专门用于评估 LLM 的推理。KUMO 将 LLM 与符号引擎协同结合,动态生成多样化的多轮推理任务,这些任务的难度可部分观察和调整。通过自动流水线,KUMO 不断生成跨开放领域的新任务,使得模型展示真正的泛化而非记忆。
他们在 KUMO 创建的 100 个领域中的 5000 个任务上对 23 个最先进的 LLM 进行了评估,并以大学生的推理能力为基准。研究结果表明,许多 LLM 在简单的推理任务中的表现都超过了大学水平,而在复杂的推理挑战中,推理扩展 LLM 的表现也达到了大学水平。此外,LLM 在 KUMO 任务上的表现与新发布的真实世界推理基准的结果密切相关,这凸显了 KUMO 作为真正的 LLM 推理能力的持久评估工具的价值。
论文链接:https://arxiv.org/abs/2504.02810
整理:锦鲤
如需转载或投稿,请直接在公众号内留言

内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢