

1. 南大、字节提出解耦扩散 transformers
2. 复旦、阶跃星辰提出多模态 SVG 生成模型 OmniSVG
3. 快手:形式化推理的后训练扩展
1. 南大、字节提出解耦扩散 transformers
扩散 transformers 虽然需要较长的训练迭代时间和众多推理步骤,但已显示出卓越的生成质量。在每个去噪步骤中,扩散 transformers 对噪声输入进行编码,提取低频语义成分,然后用相同的模块对高频进行解码。这种方案造成了固有的优化困境:对低频语义进行编码就必须减少高频成分,这就造成了语义编码和高频解码之间的矛盾。
为了解决这一难题,来自南京大学和字节跳动的研究团队提出了一种“解耦扩散 transformers”(Decoupled Diffusion Transformer,DDT),它采用解耦设计,将用于语义提取的专用条件编码器与专用速度解码器结合在一起。
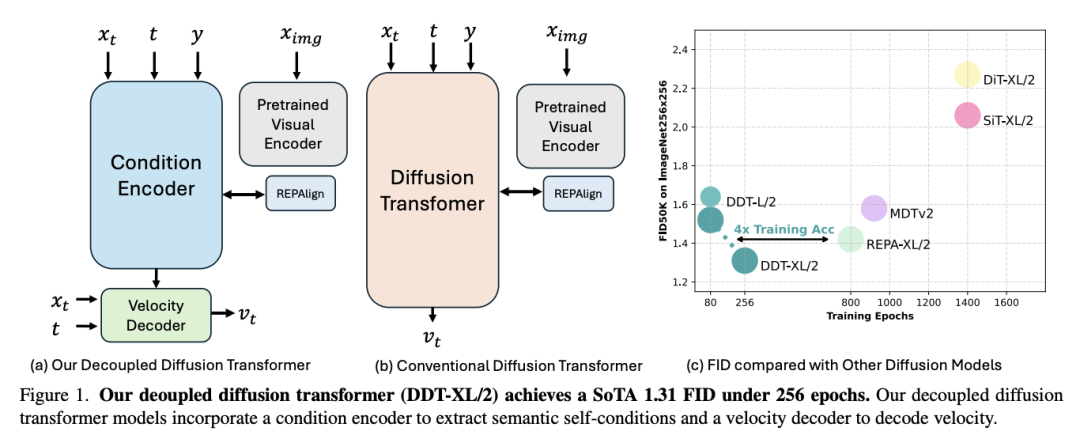
实验表明,随着模型大小的增加,更多的编码器可以提高性能。对于 ImageNet 256 × 256,他们的 DDT-XL/2 实现了 1.31 FID 的性能(与以前的扩散 transformers 相比,训练收敛速度提高了近 4 倍)。对于 ImageNet 512 × 512,DDTXL/2 实现了 1.28 的 SOTA FID。此外,这一解耦架构通过在相邻去噪步骤之间共享自约束,提高了推理速度。为了尽量减少性能下降,他们提出了一种新的统计动态编程方法来确定优化共享策略。
论文链接:https://arxiv.org/abs/2504.05741
2. 复旦、阶跃星辰提出多模态 SVG 生成模型 OmniSVG
可缩放矢量图形(SVG)是一种重要的图像格式,在图形设计中被广泛采用。生成高质量 SVG 的研究一直受到 AIGC 界设计人员和研究人员的关注。然而,现有的方法要么产生非结构化的输出,计算成本高昂,要么仅限于生成结构过于简化的单色图标。
为了生成高质量和复杂的 SVG,来自复旦大学和阶跃星辰的研究团队提出了 OmniSVG,这是一个利用预训练视觉语言模型(VLM)生成端到端多模态 SVG 的统一框架。通过将 SVG 命令和坐标参数化为离散 token,OmniSVG 将结构逻辑与底层几何解耦,从而在保持复杂 SVG 结构的表现力的同时实现高效训练。
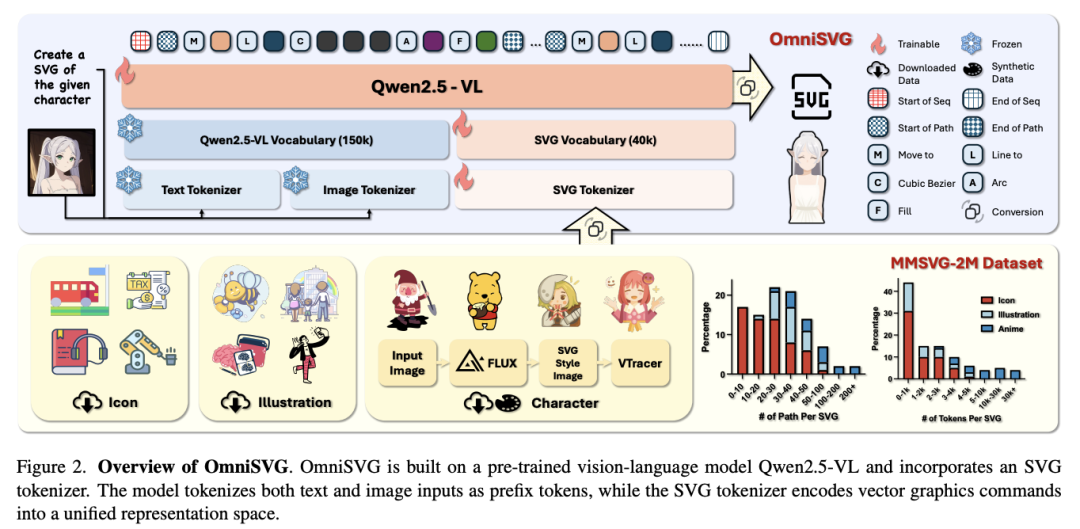
为了进一步推动 SVG 合成的发展,他们提出了一个多模态数据集 MMSVG-2M,其包含 200 万个标注丰富的 SVG 资产,以及用于条件 SVG 生成任务的标准化评估协议。
实验表明,OmniSVG 的性能优于现有方法,并证明了其融入专业 SVG 设计工作流程的潜力。
论文链接:https://arxiv.org/abs/2504.06263
3. 快手:形式化推理的后训练扩展
通过大语言模型(LLM)实现的自动化定理证明(ATP),凸显了使用 Lean 4 代码进行形式化推理的潜力。然而,ATP 还没有因为 OpenAI o1/o3 和 Deepseek R1 展示的后训练扩展而发生显著变化。
在这项工作中,快手团队研究了 ATP 的整个后训练,旨在使其与自然语言推理模型的突破保持对齐。首先,他们用一个混合数据集继续训练当前的 ATP 模型,该数据集由大量 statement-proof 对和其他数据组成,旨在纳入模仿人类推理和假设完善的认知行为。接下来,他们利用 Lean 4 编译器返回的结果奖励探索强化学习。
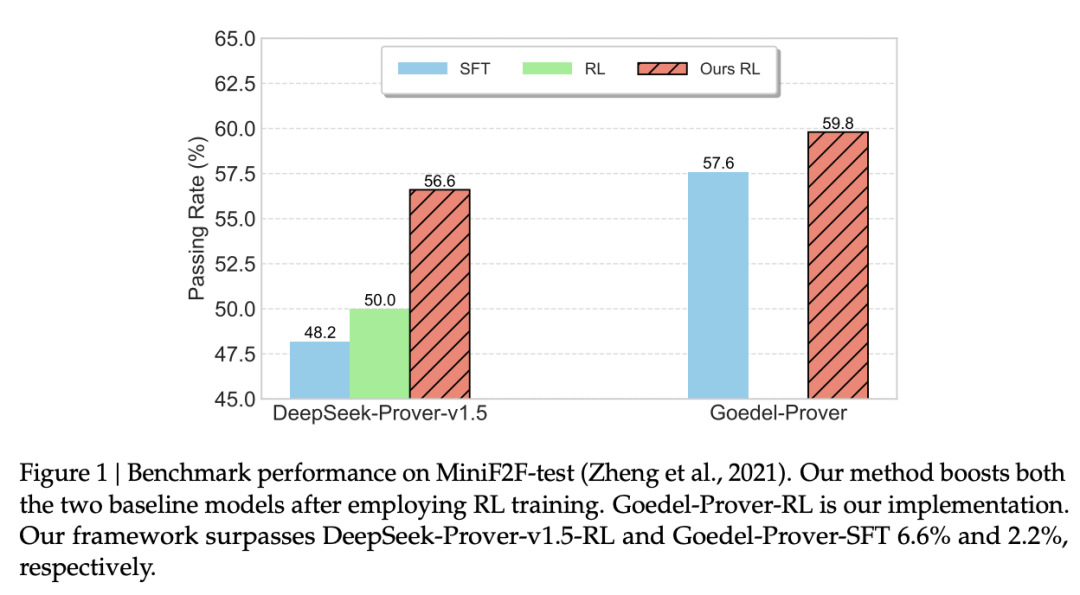
通过持续训练和强化学习过程,他们成功改进了现有的形式化证明器,包括 DeepSeek-Prover-v1.5 和 Goedel-Prover,在 whole-proof 生成领域取得了 SOTA。例如,他们在 MiniF2F 上实现了 59.8% 的通过率(pass@32)。
论文链接:https://arxiv.org/abs/2504.06122
4. 通才机器人新突破:统一世界模型 UWM
模仿学习是制造通才机器人的一种有前途的方法。然而,由于依赖于高质量的专家示范,针对大型机器人基础模型的扩展模仿学习仍然具有挑战性。与此同时,描述各种环境和各种行为的大量视频数据容易获得,它们提供了有关真实世界动态和 agent 与环境交互的丰富信息。然而,由于缺乏大多数现代方法所需的动作注释,将这些数据直接用于模仿学习并不容易。
在这项工作中,来自华盛顿大学和丰田研究所的研究团队提出了“统一世界模型”(UWM),这是一个可以利用视频和动作数据进行策略学习的框架。具体来说,UWM 将动作扩散过程和视频扩散过程整合到一个统一的 transformer 架构中,其中每种模态都有独立的扩散时间步。
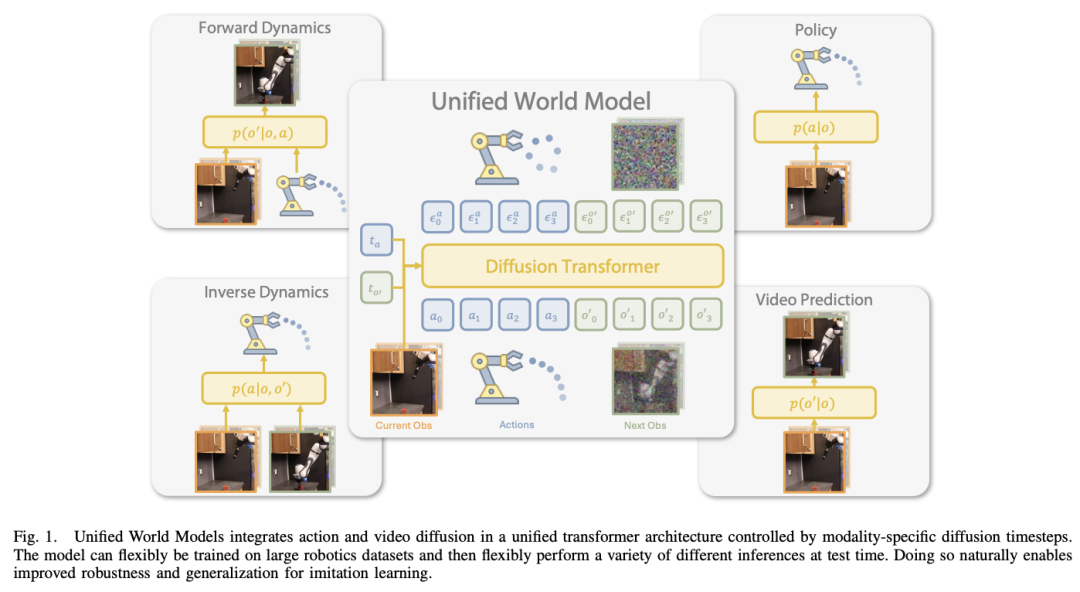
研究表明,只需控制每个扩散时间步,UWM 就能灵活地表示策略、正向动力学、逆向动力学和视频生成器。通过模拟和实际实验,他们证明了:(1)UWM 可以在大规模多任务机器人数据集上进行有效的动态和动作预测预训练,从而产生比模仿学习更普适和鲁棒的策略;(2)UWM 通过独立控制特定模态,自然地促进了无动作视频数据的学习。
论文链接:https://arxiv.org/abs/2504.02792
5. 上海 AI Lab:免训练、高分辨率文生图框架 HiFlow
文生图扩散(diffusion)/流(flow)模型因提供灵活视觉创作的能力,引起了广泛关注。然而,由于高分辨率内容的稀缺性和复杂性,高分辨率图像合成仍然面临挑战。
为此,上海 AI Lab 团队提出了一个免训练(training-free)、模型无关(model-agnostic)的框架——HiFlow,其可释放预训练流模型的分辨率潜力。具体来说,HiFlow 在高分辨率空间内建立了一个虚拟参考流,它能有效捕捉低分辨率流信息的特征,通过低频一致性的初始化对齐、结构保持的方向对齐和细节保真度的加速对齐 3 方面为高分辨率生成提供指导。

通过利用这种流对齐指导,HiFlow 提高了 T2I 模型高分辨率图像合成的质量,并展示了其个性化变体的多功能性。实验验证,HiFlow 在实现高分辨率图像质量方面优于目前 SOTA 方法。
论文链接:https://arxiv.org/abs/2504.06232
6. 南加大:自适应课程强化微调 AdaRFT
强化微调(RFT)在增强大语言模型(LLM)的数学推理能力方面显示出潜力,但通常在采样和计算方面效率低,需要大量训练。
在这项工作中,南加州大学团队提出了 AdaRFT(自适应课程强化微调),这是一种通过自适应课程学习提高 RFT 效率和最终准确性的方法,可根据奖励信号动态调整训练问题的难度,确保模型始终在具有挑战性但可解决的任务上进行训练。这种自适应采样策略能保持最佳难度范围,避免在太容易或太难的问题上浪费计算,从而加快学习速度。AdaRFT 只需要对标准 RFT 算法(如 PPO)进行轻量级扩展,而无需修改奖励函数或模型架构。
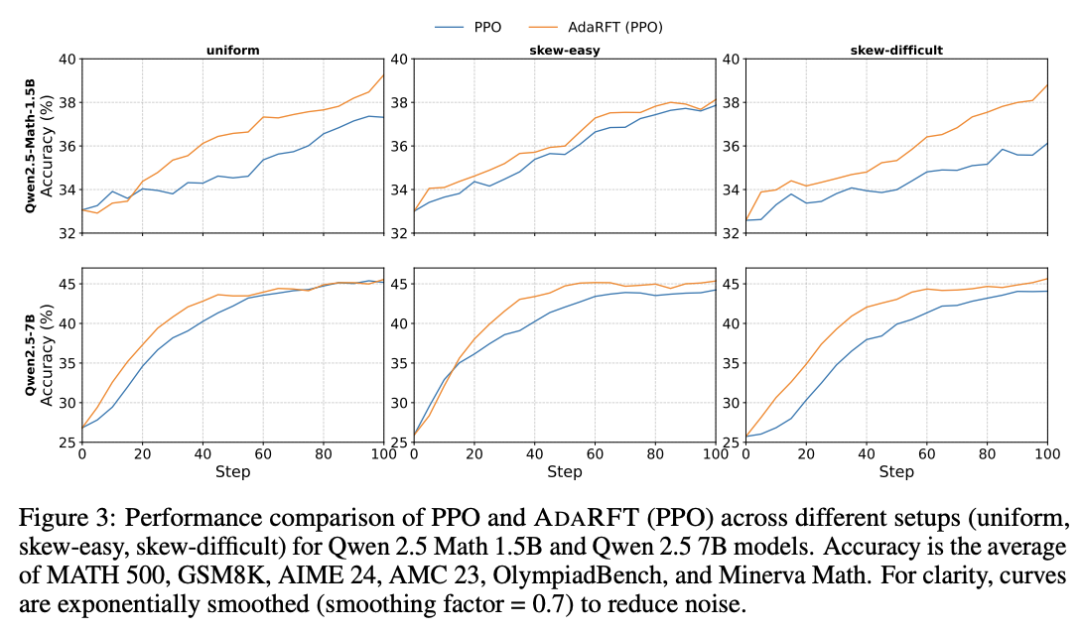
在竞赛级数学数据集(包括 AMC、AIME 和 IMO 类型的问题)上进行的实验证明,AdaRFT 提高了训练效率和推理性能。他们评估了 AdaRFT 的多种数据分布和模型大小,结果表明它减少了 2 倍的训练步骤,并提高了准确性,提供了一个更具可扩展性和更有效的 RFT 框架。
论文链接:https://arxiv.org/abs/2504.05520
整理:学术君
如需转载或投稿,请直接在公众号内留言

内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢