
本文分享阿里妈妈智能创作与AI应用团队在图文广告创意方向上提出的商品图文海报生成模型,通过构建字符级视觉表征作为控制信号,可以实现精准的图上中文逐像素生成。基于该项工作总结的论文已被 CVPR 2025录用,并在阿里妈妈业务场景落地,欢迎阅读交流~
论文:PosterMaker: Towards High-Quality Product Poster Generation with Accurate Text Rendering
作者:Yifan Gao*, Zihang Lin*, Chuanbin Liu, Min Zhou, Tiezheng Ge, Bo Zheng, Hongtao Xie
链接:https://arxiv.org/abs/2504.06632
1. 引言
商品图文海报在电商平台中发挥着至关重要的作用,一张优秀的图文创意可以有效展示商品与卖点,吸引用户点击与购买。制作商品图文创意需要将商品放置于适当的背景环境中进行拍摄,之后选择合适的字体、颜色,将商品卖点等文字信息添加到图像上,以确保文字吸引人、易读且与背景相协调。这个过程颇具专业性,对于中小商家而言有一定的门槛,制作成本较高。随着大型文本到图像(T2I)模型的飞速发展,使用图像生成模型合成此类商品海报正逐渐引起越来越多研究者的关注。本文专注于商品图文海报生成任务,具体任务定义为:给定描述背景场景的prompt(提示词)、用户指定的商品前景图像以及一些文案内容和期望摆放的位置,我们的目标是开发一个模型为用户一键生成图文海报。
对于这个任务,一种直接的解决思路是首先生成无文字的商品场景图,之后预测文本属性(例如颜色和字体)并在图像上渲染它们。然而,这样的训练数据难以获取,因为字体、颜色(包括渐变等复杂属性)、描边等文本属性难以直接从海报中识别提取,如果使用模板合成训练数据则容易造成模式单一、与商家图片分布不一致等问题。另一个思路是通过逐像素生成的方法进行学习,这样可以直接学习专业设计海报的分布,本文关注于这种单阶段的解决方案,其主要挑战是如何确保文本渲染的准确性。许多近期的研究工作[1,2,3]提出了改善大型扩散模型文本渲染准确性的方案,部分研究工作已能在英语中实现高渲染准确率,但对于中文等非拉丁语言,实现高渲染准确率仍然是一个挑战。原因主要在于中文字符数量众多,且书写结构复杂、变化多样,直接通过训练让模型单独记住每个字的字形十分困难。本文指出,高精度文本渲染的关键在于构建字符级的视觉特征作为控制信号,为此我们构建了一个鲁棒的字符级表征,并提出TextRenderNet,一种基于SD3[1]的ControlNet[4]结构模型,采用字符级表征作为控制信号来渲染视觉文本,成功实现了高精度的视觉文本生成。
在商品海报生成任务中,另一个重点是如何将用户指定的商品生成到所需场景中,同时保持高保真度,不改变商品细节。基于subject-driven的方法通常无法确保生成图的商品细节与输入图完全一致,因此我们选择使用inpainting的方法绘制背景,这样可以保持前景细节不变。但我们发现背景inpainting有时会出现商品周围长东西的问题,例如运动鞋多画一个鞋跟变成高跟鞋,近期一些相关工作[5,6]也观察到类似现象。为了解决这个问题,我们设计了一个检测器来检测这类情况,之后我们将检测器作为奖励模型,通过反馈学习来优化提升商品前景的保真度。
结合以上所提及的技术,本文构建了一个名为PosterMaker的模型,能够根据用户输入信息生成商品图文海报,在中文的句子级生成准确率上超过90%。
2. 方法
2.1 任务定义
本文关注的商品图文海报任务定义为:
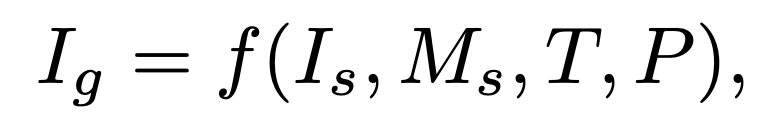
其中 表示生成的海报图像, 代表商品前景图像, 是商品前景的Mask。 表示期望生成的文本内容和位置,是描述背景场景的提示词 prompt。后续章节将详细介绍 PosterMaker 模型的具体设计。
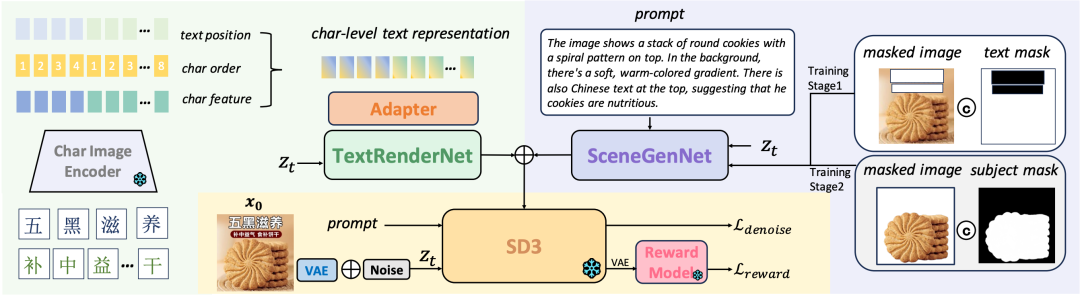
2.2 整体模型框架
PosterMaker 基于 Stable Diffusion 3(SD3)[1]开发,模型框架如图1所示。本文提出两个模块,分别是 TextRenderNet 和 SceneGenNet,旨在解决海报生成任务。TextRenderNet 专门设计用于学习视觉文本渲染,以字符级视觉特征作为输入,实现精确和可控的文本渲染。SceneGenNet 则接受一张商品前景图、一个 Mask(指示哪些内容应保持不变)和一个提示词 prompt,学习在 prompt 所描述的期望场景中生成商品前景。TextRenderNet 和 SceneGenNet 都基于ControlNet[4] 结构设计,由多个级联的 MM-DiT block 组成,使用 SD3 底模的权重进行参数初始化。TextRenderNet 和 SceneGenNet 的每个 MM-DiT block 的输出直接添加到 SD3 底模相应 block 的输出中。
2.3 字符级视觉特征:实现精确文本渲染的关键
近期关于图上文字渲染的研究方法[3,7]通常使用字形图像(glyph image)和行级(line-level)OCR特征作为控制条件。然而,这些控制信息无法准确代表字符:1)字形图像容易受到文本大小和形状的影响,稳定性较差。2)行级视觉特征缺乏细粒度的笔画特征,同时受到 OCR 模型对较长文本识别能力的限制。为了解决这些挑战,本文提出了一种即插即用且强大的字符级文本表示,其中每个字符由一个 token 精确表示。具体来说,假设文本 包含 个字符。对于每个字符 ,本文通过预训练的OCR编码器 分别提取其视觉特征,然后进行平均池化以获得紧凑的字符表示向量 。因此,字符级文本表示定义为:
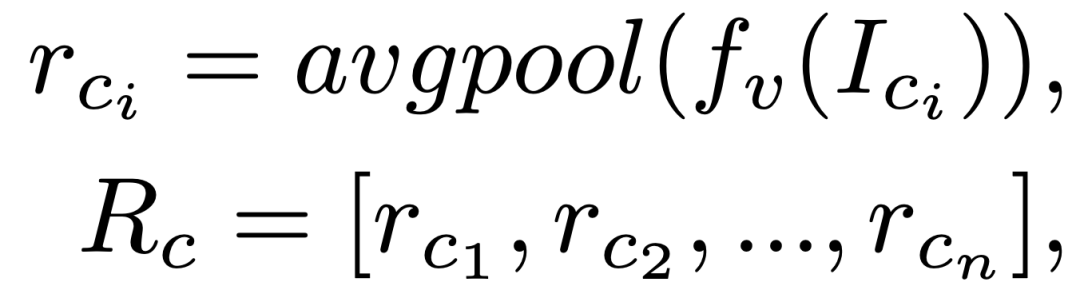
其中 是以固定字体渲染的第个字符的图像,而 为字符级文本表示。我们观察到,与先前的方法相比,我们提取自字符字形图像的表示使得模型能够感知字符笔画结构并实现更高的文本准确性。此外,由于字符总数量是固定的,我们可以预先提取每个字符的表示并将其存储在字典中,省去了在线渲染和特征提取的需求,从而显著简化了训练和推理流程。最后,由于该文本表示缺乏顺序和位置的信息。因此,本文引入字符顺序的位置编码 来表示文本中字符的顺序。此外,受到 GLIGEN[8] 的启发,本文将文字位置框的坐标进行傅立叶编码为 ,以控制文字的渲染位置。本文将 、 和 在特征维度上拼接以构建最终的文本表征,该表征经过一个Adapter调整特征维度后输入到 TextRenderNet 中作为控制信号指导模型生成相应的视觉文本。
2.4 提高前景保真性
在商品海报生成任务中,商品前景的保真度至关重要,即模型需要确保生成的海报中商品主体与用户指定的商品保持一致。为了实现这一目标,我们构建了 SceneGenNet 用于背景 inpainting,该模块学习根据 prompt 将商品前景绘制到对应背景上,同时精确地保持前景主体细节。但是,基于背景 inpainting 的方法有时会错误地延展商品前景,从而降低商品主体的保真性,我们称之为“前景延展” (或俗称“长东西”)现象。为了缓解这一问题,我们开发了一个模型来检测前景延展现象,并使用它作为奖励模型来微调 PosterMaker,提高商品前景的保真度。
2.4.1 前景延展检测器
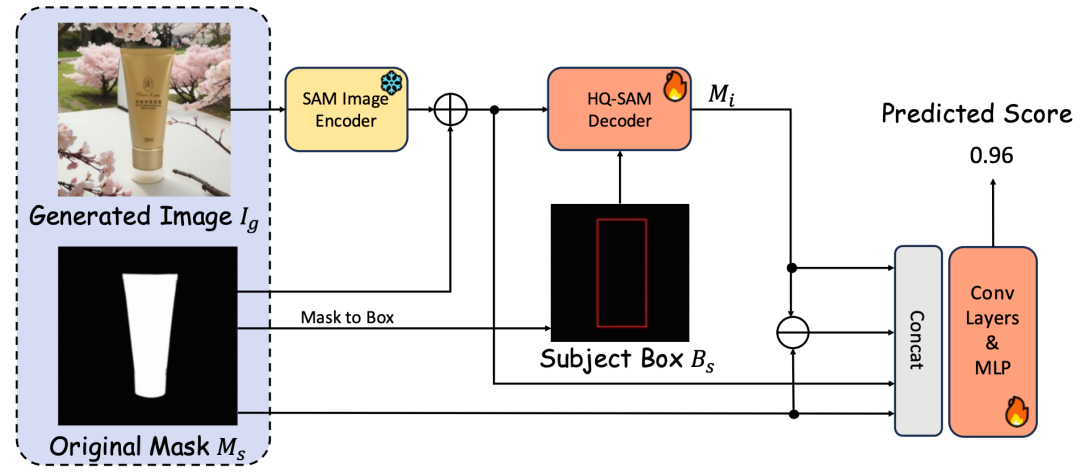
本文基于 HQ-SAM[9] 开发了前景延展检测器 . 具体地,本文将生成的图像 输入到 SAM[10] 的图像编码器中。然后将前景 mask 和对应的边界框 分别作为 mask prompt 和 box prompt 输入到 HQ-SAM 的解码器,以获取中间 mask 。接下来,我们将从SAM编码器提取的图像特征与 、 和 在通道维度上拼接。拼接特征通过卷积层和MLP层进行处理,以预测生成图像中是否存在前景错误延展的问题。检测器的模型结构如图2所示。
2.4.2 主体保真的反馈学习
离线训练后的前景延展检测器 用作奖励模型监督 PosterMaker,以提高商品主体的保真性。具体地,假假设反向过程的总步数为 ,我们参照 ReFL[11] 先进行 步推理得到 ,其中 ~ 。然后,我们直接进行一步推理,由 直接得到 以加速反向过程。接着 被解码为生成图像 。检测器 预测 的前景延展 score,该 score 作为奖励损失用于优化生成器 (即PosterMaker)。奖励损失函数具体定义如下:
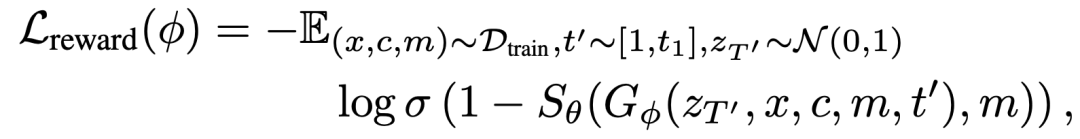
其中 从训练数据 中采样得到,分别表示前景商品图像、控制条件和主体 mask。为了避免过拟合,对于那些前景延展 score 低于 0.3 的情况,本文不计算奖励损失。
本文的总训练损失函数定义为:

其中 是用于调整奖励损失和去噪损失权重的超参数。
2.5 训练策略
为了高效地训练 PosterMaker,本文使用了一种两阶段训练策略,旨在解耦文本渲染和背景图像生成的学习。在第一阶段,训练任务是局部文本编辑。我们冻结 SceneGenNet,仅优化 TextRenderNet 和 Adapter。由于我们用 inpainting ControlNet 的预训练权重对 SceneGenNet 进行初始化,其能够良好地填充局部背景,使得 TextRenderNet 可以专注于学习文本的生成。在第二阶段,训练任务是前景保持的文本到图像生成。在这个阶段,我们冻结 TextRenderNet,仅训练 SceneGenNet。在这一阶段,SceneGenNet 专注于从训练数据学习海报场景和创意设计。本文提出的两阶段训练策略使得 TextRenderNet 和 SceneGenNet 可以专注于各自的任务,从而实现高效的训练。
3. 实验结果
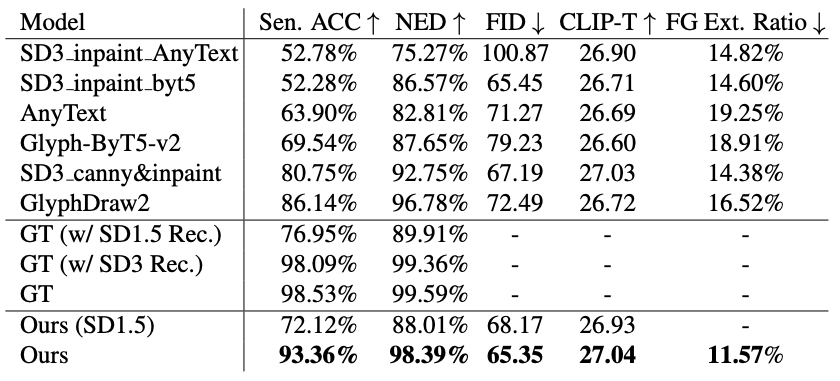
本文从淘宝收集了160k商品图文海报用于模型训练与测试。我们参照 Anytext[3] 论文的评估方法使用两个指标进行文本渲染准确性的评估:句子准确率(Sen. Acc)和归一化编辑距离(NED)。我们另外计算FID 指标以衡量生成图像的视觉质量,以及 CLIP-T 指标以评估文本-图像的一致性。此外,我们通过人工评测统计出现商品前景长东西问题的比例(FG Ext. Ratio)。
3.1 定量指标
如下表所示,本文方法在所有对比指标上均超过对比方法,在文字精度上取得超过90%的句子准确率,显著超过现有对比方法。
3.2 定性可视化
本文将生成结果与基线方法进行可视化对比,可以看出,本文方法生成的文字更精确,对于小字也可以较准确地生成。

3.3 消融实验
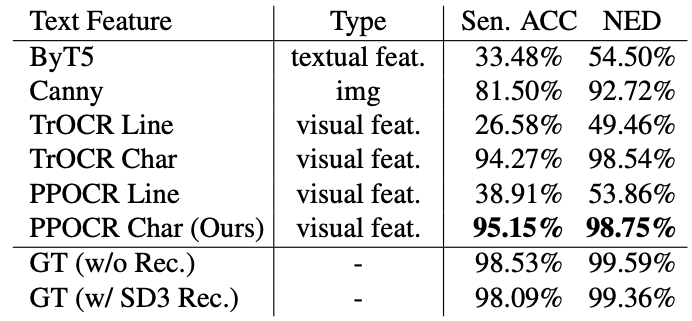
本文进行消融实验以探究不同控制条件对视觉文本渲染的有效性,结果如下表所示,实验结果表明,使用字符级视觉特征可以取得最高的文字渲染精度,而使用“字符级文本特征”和“行级别(line-level)视觉特征”均不能取得很好的效果,说明对于可控文本渲染任务而言,“字符级”和“视觉特征”这两个条件缺一不可。本文方法的文字精度已逼近对GT图片使用SD3 VAE重建的精度上限,这进一步验证了本文观点:“字符级视觉特征是实现高精度文本渲染的关键”。
本文还对所提出的主体保持反馈学习方法进行消融验证,如下表所示,使用奖励损失 训练我们的模型可以有效降低前景错误延展的比例(FG Ext. Ratio),同时维持其他性能指标基本不变,这些结果表明本文提出的主体保真反馈学习方法在减轻前景延展问题方面的有效性。

4. 应用
基于本文技术构建的升级版模型已落地万相营造(阿里妈妈旗下专注商业经营领域的AI创意生产工具),助力商家制作图文创意。此外,在本文技术基础上,我们搭建了一条商品海报自动批量生产链路,对生图结果进行投放实验,在部分场景已取得正向投放效果。以下展示了一些线上生成的优质结果。




5. 总结
本文介绍了 PosterMaker,一个商品图文海报生成模型。在商品图文海报生成任务中,本文针对文本渲染和商品保真度问题提出了有效的解决方案。本文通过构建鲁棒的字符级视觉特征作为控制信号,实现了超过 90% 的中文文本渲染准确率,有效应对了复杂书写系统带来的挑战。另外,本文引入基于背景 inpainting 的 SceneGenNet 和主体保真反馈学习的方法,进一步提升了生成海报的产品保真度。实验结果表明,PosterMaker 在各项评估指标上显著优于现有技术,充分验证了其有效性。本文相关技术也已落地万相营造工具以及阿里妈妈广告投放场景。
🏷 关于我们
我们是阿里妈妈智能创作与AI应用,专注于智能创意创作与投放、AIGC、LLM应用等方向,欢迎各业务方关注与业务合作。同时,真诚欢迎具备CV、NLP和推荐系统相关背景同学加入!

▐ 参考文献
[1] Patrick Esser, Sumith Kulal, Andreas Blattmann, RahimEntezari, Jonas Muller, Harry Saini, Yam Levi, Dominik Lorenz, Axel Sauer, Frederic Boesel, et al. Scaling rectified flow transformers for high-resolution image synthesis. In Forty-first International Conference on Machine Learning, 2024.
[2] Zeyu Liu, Weicong Liang, Zhanhao Liang, Chong Luo, Ji Li, Gao Huang, and Yuhui Yuan. Glyph-byt5: A customized text encoder for accurate visual text rendering. In European Conference on Computer Vision, pages 361–377. Springer, 2024.
[3] Yuxiang Tuo, Wangmeng Xiang, Jun-Yan He, Yifeng Geng, and Xuansong Xie. Anytext: Multilingual visual text generation and editing. In The Twelfth International Conference on Learning Representations, ICLR 2024, Vienna, Austria, May 7-11, 2024.
[4] Lvmin Zhang, Anyi Rao, and Maneesh Agrawala. Adding conditional control to text-to-image diffusion models. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 3836–3847, 2023.
[5] Zhenbang Du, Wei Feng, Haohan Wang, Yaoyu Li, Jingsen Wang, Jian Li, Zheng Zhang, Jingjing Lv, Xin Zhu, Junsheng Jin, et al. Towards reliable advertising image generation using human feedback. In European Conference on Computer Vision, pages 399–415. Springer, 2024.
[6] Amir Erfan Eshratifar, Joao V.B. Soares, Kapil Thadani, Shaunak Mishra, Mikhail Kuznetsov, Yueh-Ning Ku, and Paloma De Juan. Salient object-aware background generation using text-guided diffusion models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, pages 7489–7499, 2024.
[7] Jian Ma, Yonglin Deng, Chen Chen, Haonan Lu, and Zhenyu Yang. Glyphdraw2: Automatic generation of complex glyph posters with diffusion models and large language models. arXiv preprint arXiv:2407.02252, 2024.
[8] Yuheng Li, Haotian Liu, Qingyang Wu, Fangzhou Mu, Jianwei Yang, Jianfeng Gao, Chunyuan Li, and Yong Jae Lee. Gligen: Open-set grounded text-to-image generation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 22511–22521, 2023.
[9] Lei Ke, Mingqiao Ye, Martin Danelljan, Yifan liu, Yu-Wing Tai, Chi-Keung Tang, and Fisher Yu. Segment anything in high quality. In Advances in Neural Information Processing Systems, pages 29914–29934. Curran Associates, Inc., 2023.
[10] Alexander Kirillov, Eric Mintun, Nikhila Ravi, Hanzi Mao, Chloe Rolland, Laura Gustafson, Tete Xiao, Spencer Whitehead, Alexander C. Berg, Wan-Yen Lo, Piotr Dollar, and Ross Girshick. Segment anything. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 4015–4026, 2023.
[11] Jiazheng Xu, Xiao Liu, Yuchen Wu, Yuxuan Tong, Qinkai Li, Ming Ding, Jie Tang, and Yuxiao Dong. Imagereward: Learning and evaluating human preferences for textto-image generation. In Advances in Neural Information Processing Systems, pages 15903–15935. Curran Associates, Inc., 2023.

也许你还想看
丨更真、更像、更美:阿里妈妈重磅升级淘宝星辰视频生成大模型 2.0
丨懂你,更懂电商:阿里妈妈推出淘宝星辰视频生成大模型及图生视频应用
丨NeurIPS'24 | FlowDCN:基于可变形卷积的任意分辨率图像生成模型

喜欢要“分享”,好看要“点赞”哦ღ~
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢