

驱动科学研究的人工智能正逐渐改变科学研究的模式,在探索以通专融合实现通用人工智能 (AGI) 的进程中,通用基座大模型,尤其是具备跨模态理解能力的多模态大模型至关重要——多模态大模型的创新突破,将大幅提升模型同时处理文本、图像、视频等数据的能力,从而为科研创新提供基础性支撑。
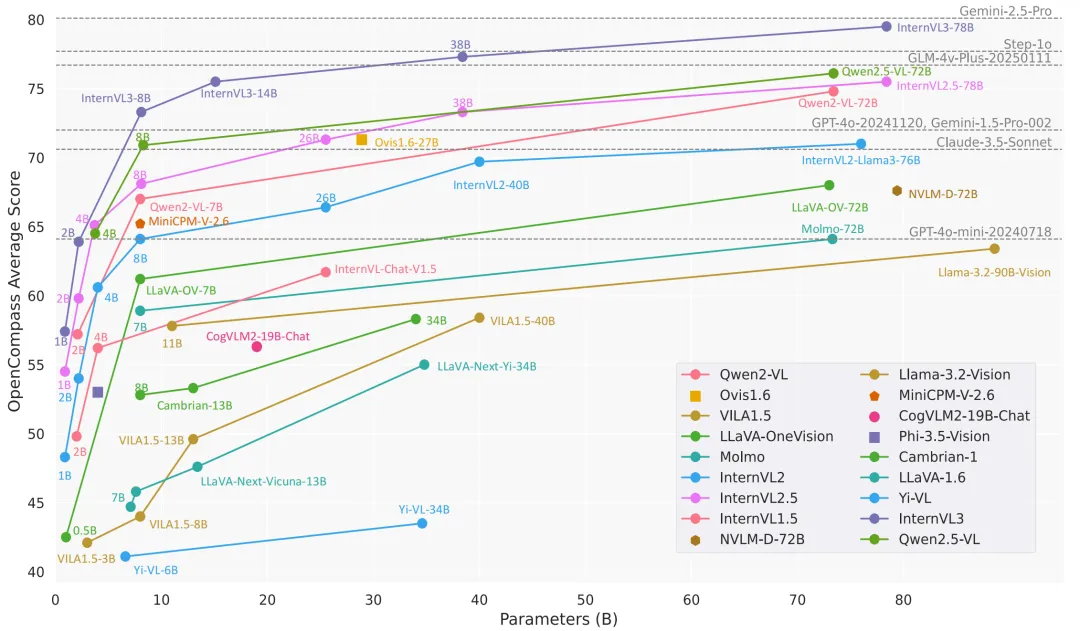
2025 年 4 月 16 日,上海人工智能实验室 (上海AI实验室) 升级并开源了通用多模态大模型书生·万象 3.0 (InternVL3)。通过采用创新的多模态预训练和后训练方法,InternVL3 多模态基础能力全面提升,在专家级基准测试、多模态性能全面测试中,10 亿~780 亿参数的 全量级版本在开源模型中性能均位列第一,同时大幅提升了图形用户界面 (GUI) 智能体、建筑场景图纸理解、空间感知推理以及通识学科推理等方面的能力。
• 在专家级多学科领域知识推理基准测试 MMMU 中再次突破开源模型极限,取得 72.2 分;
• 基于司南 OpenCompass 开源评测框架,研究团队对 InternVL3 进行了全面系统的评估,包括多学科推理、文档理解、多图像 / 视频理解、现实世界理解、多模态幻觉检测、视觉定位、多语言能力以及以语言为中心的基准测试。评测结果显示,InternVL3 在开源多模态大模型中性能表现最优,创造了开源多模态大模型的性能新标杆,性能接近闭源模型 Gemini-2.5-Pro;
• 创新提出原生多模态预训练方法,将语言和多模态学习整合于同一个预训练阶段,提升及拓展多模态能力的同时,进一步提升纯语言能力;

创新的多模态预训练方法
高效的多模态后训练策略
监督微调
在监督微调阶段, InternVL3 沿袭了 InternVL2.5 中提出的随机图像压缩、平方损失重加权和多模态数据拼接等技术。与 InternVL2.5 相比,InternVL3 在监督微调阶段使用了更高质量且更多样化的训练数据,研究团队进一步扩充了工具使用、三维场景理解、图形用户界面操作、长上下文任务、视频理解、科学图表、创意写作以及多模态推理等方面的训练样本。
混合偏好优化
在预训练和监督微调阶段,模型被训练基于先前的正确单词来预测下一个单词。然而在推理过程中,模型是基于其自身之前的输出来预测下一个单词。训练与推理阶段中单词的真实分布和模型预测分布之间存在差异,这将引入分布偏移,进而削弱模型的长序列输出以及思维链 (CoT) 推理能力。为了缓解这个问题,研究团队采用了混合偏好优化 (MPO) 方法,通过引入来自正样本和负样本的额外监督,帮助模型修剪自身分布,以使模型的预测分布和真实分布进一步对齐,从而减少分布偏移、提高模型推理性能。
多模态测试时增强 (Test-Time Scaling)
测试时增强已被证明是增强 LLMs 和 MLLM 推理能力的有效方法。在 InternVL3 中,研究团队采用 Best-of-N 评估策略,并使用 VisualPRM-8B 作为评估模型,以选择最佳的响应进行推理和数学评估。
特色多模态能力
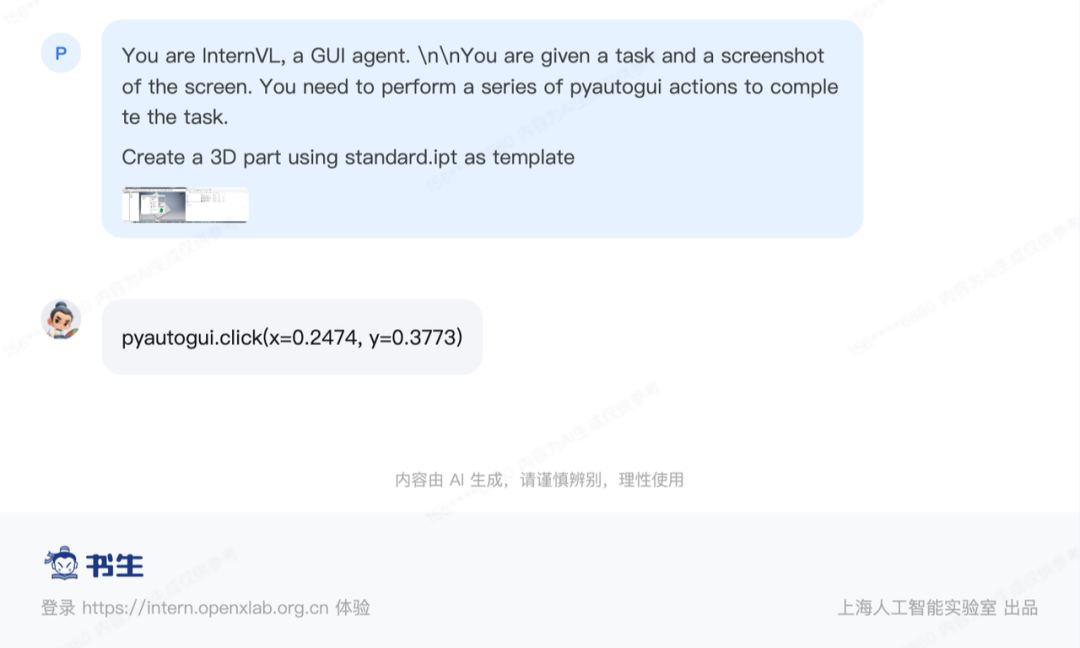
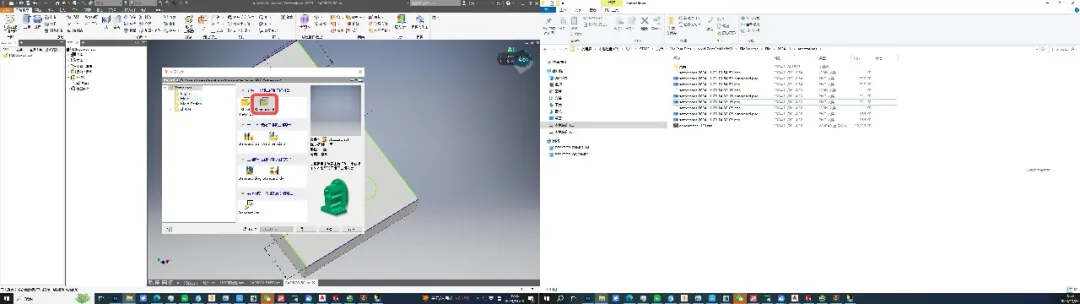
GUI智能体
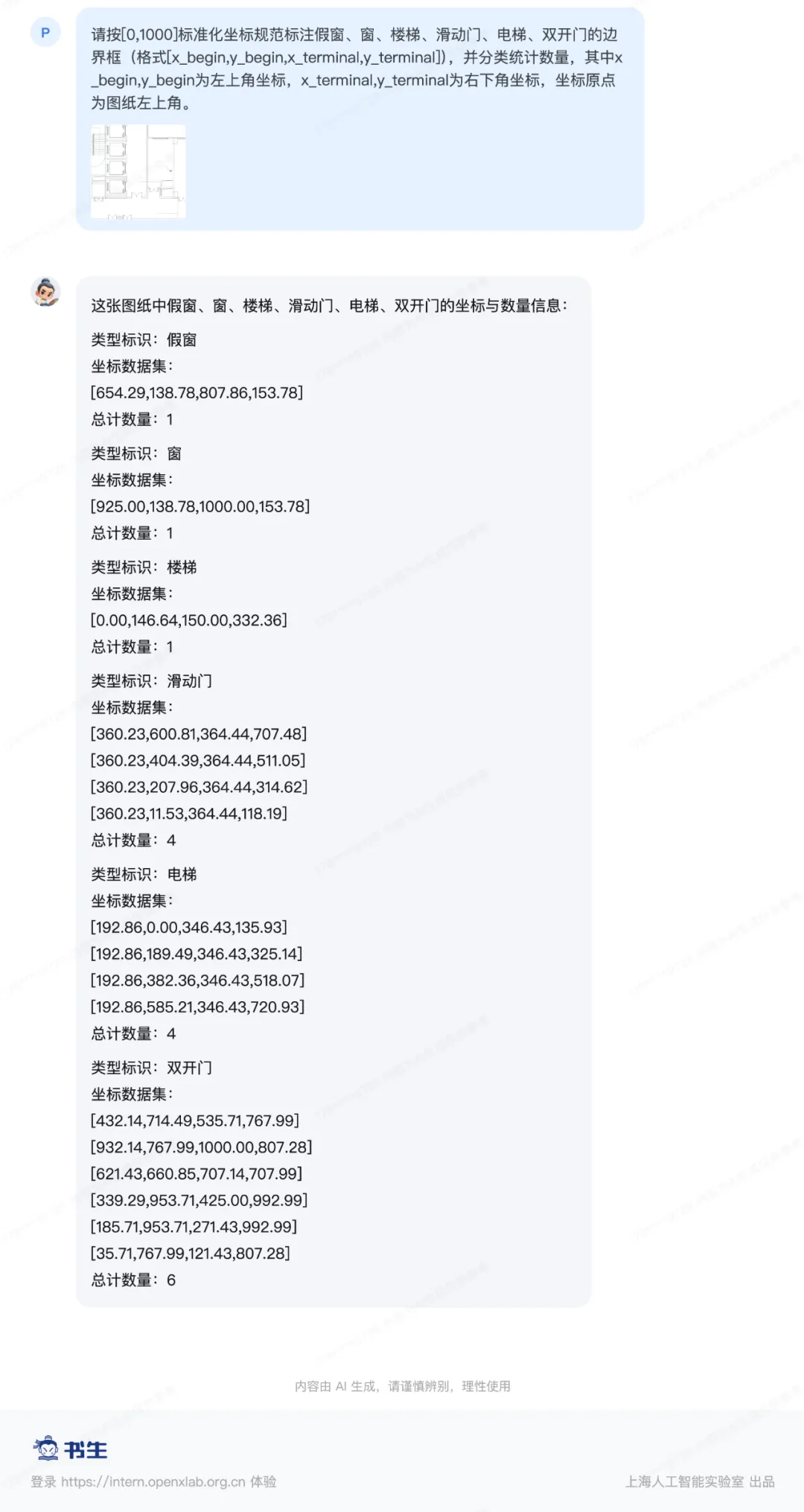
建筑场景图纸理解
空间感知推理
在空间感知与推理方面,InternVL3 在现有的测试集上取得了最优表现,表明其在仅依赖视觉输入的条件下,具备较强的空间推理与理解能力。这一能力对于后续在机器人、自动驾驶等任务中的应用具有重要意义。
给模型看一个视频并提问:
These are frames of a video.
You are a robot beginning at the doorframe and facing the tv. You want to navigate to the sofa. You will perform the following actions (Note: for each [please fill in], choose either 'turn back,' 'turn left,' or 'turn right.'): 1. Go forward until the tv 2. [please fill in] 3. Go forward until the sofa. You have reached the final destination.
A. Turn Left
B. Turn Back
C. Turn Right
Answer with the option's letter from the given choices directly.
模型很好地理解了空间方位,并做出了正确的选择:C!
本文由 Hugging Face 中文社区内容共建项目提供,稿件由社区成员投稿,经授权发布于 Hugging Face 公众号。文章内容不代表官方立场,文中介绍的产品和服务等均不构成投资建议。了解更多请关注公众号:
https://hf.link/tougao
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢