
DRUGAI
今天为大家介绍的是来自美国密歇根大学Paul M. Zimmerman团队的一篇论文。找出有效的反应条件可能是具有挑战性的,即使对于有大量先例的反应也是如此。在此,作者引入了对反应条件进行排序的模型,作为优先安排实验的一种概念上全新的方法,这与主流的产率回归方法截然不同。具体来说,标签排序(仅使用底物的输入特征进行操作)将被证明比先前的模型更好地推广到新底物。在实际反应条件选择场景中的评估——从4个或18个条件中选择,以及有或没有缺失反应的数据集——证明了标签排序的实用性。通过博尔达方法(Borda's method)进行排序聚合以及相对简单性是标签排序实现持续高性能的关键特征。

选择反应条件是有机化学家的一项常规但重要的任务。这项任务并不简单,尤其是对于那些不同底物需要不同条件的反应。文献、用户指南或有经验化学家的建议可以帮助筛选条件,能够进一步将可能性缩小到更少数量(k)的最有希望的实验将具有实际用途(图1A)。因此,成功预测反应条件的关键是选择k个最佳条件,这相当于一个排序问题。
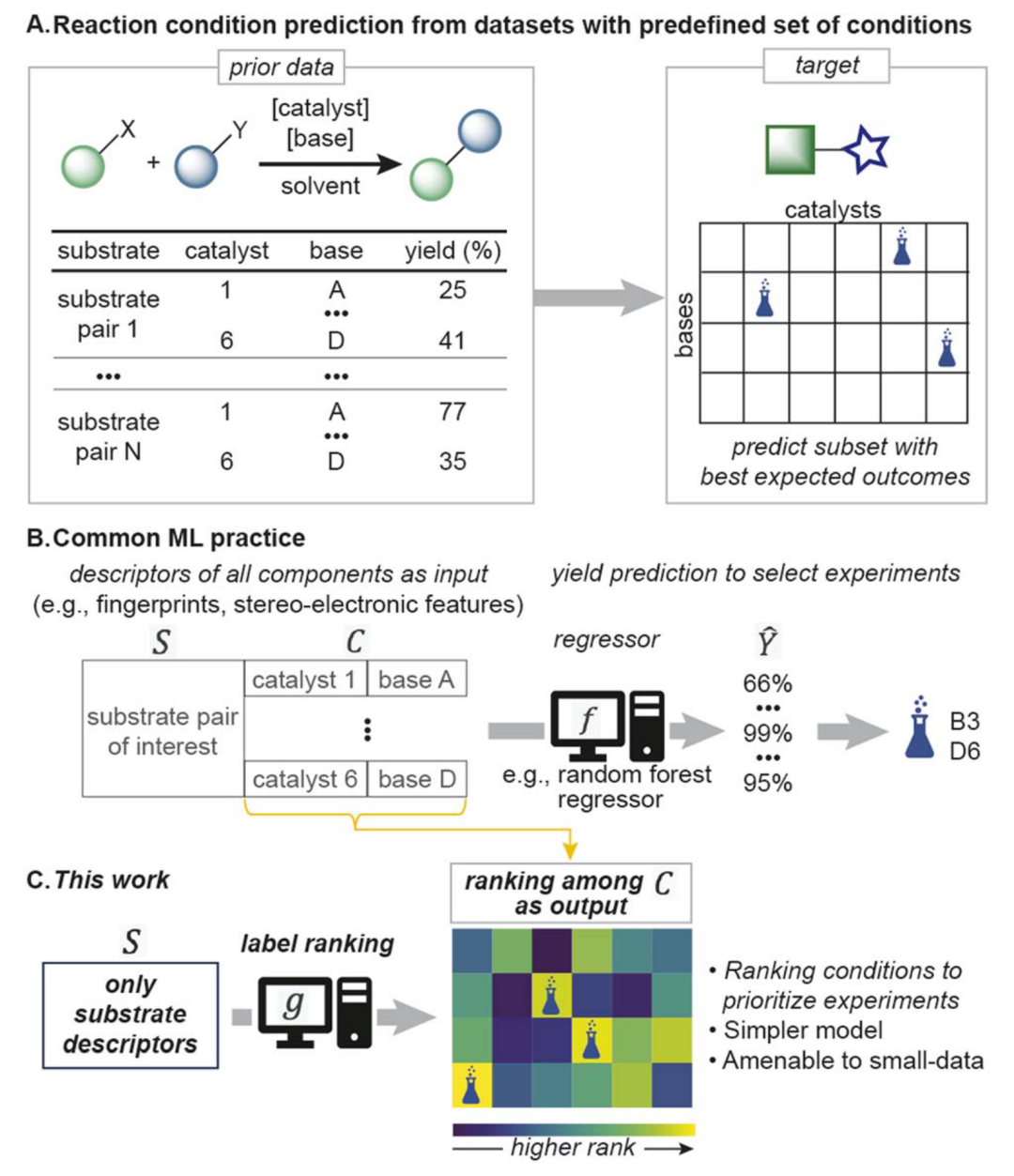
图 1
机器学习(ML)在有机合成决策方面已经表现出前景。大多数用于优先考虑反应条件的ML方法集中在量化产率或选择性上。例如,产率被建模为底物和试剂的函数,使用多变量回归技术:Y = f(S,C),其中Y是预测产率,S和C分别表示底物和反应条件描述符(图1B)。虽然可行,但这种方法并不直接模拟主要目标——反应条件相对于彼此的表现如何——且成功高度依赖于回归器的精度。此外,涉及未见底物的产率预测可能不可靠,即使使用密集数据集,也会导致>15%的误差。替代的、更简单的策略可能会更好地推广,并提高ML在反应条件选择这一日常问题中的实用性。
一个有趣的替代想法是仅使用底物特征从预定义的条件列表中对反应条件进行排序,即C = g(S)(图1C),这将减少模型复杂性(g(S)比f(S,C)更简单)。分类算法原则上可以通过将每个训练底物的前k个反应条件视为正标签来实现这一目标。然而,在典型的稀疏标记训练数据集情景中,底物将有缺失的反应条件,分类器可能会错过前k个条件。因此,分类器的实际效用将随着缺失数据点数量的增加而降低。作为分类器的替代方案,标签排序(LR)是另一种形式为C = g(S)的策略,它输出候选反应条件的排名(参见标签排序算法),并且与不完整的数据集兼容。通过减少与回归器相关的复杂性以及与分类器相比对完整数据集的需求,LR可以为使用小型数据集预测反应条件提供实用工具。
因此,LR是一种新颖的策略,它可以通过优先考虑有效的反应条件来促进实验活动,而无需广泛的组合数据集。相应地,作者评估了LR模型与回归器和分类器相比,从更大的预选可能性列表中选择顶级反应条件的效用。作者考虑了合成重要反应的相对较小的数据集,包括有缺失反应的情况。
标签排序算法
LR指的是一类机器学习算法,它根据示例(底物)的特征预测预定义标签集(反应条件)的排名。LR不同于标准数据科学问题中的分类和回归,但在概念上位于两者之间。二元分类器从两个选择中预测——是或否——而回归器的预测可以是任何数字。另一方面,LR需要从有限标签集的所有可能排序中进行选择。由于这个输出空间是离散的,所以它比回归更简单。同时,由于有比分类更多的可能结果,LR可以捕捉更微妙的关系。
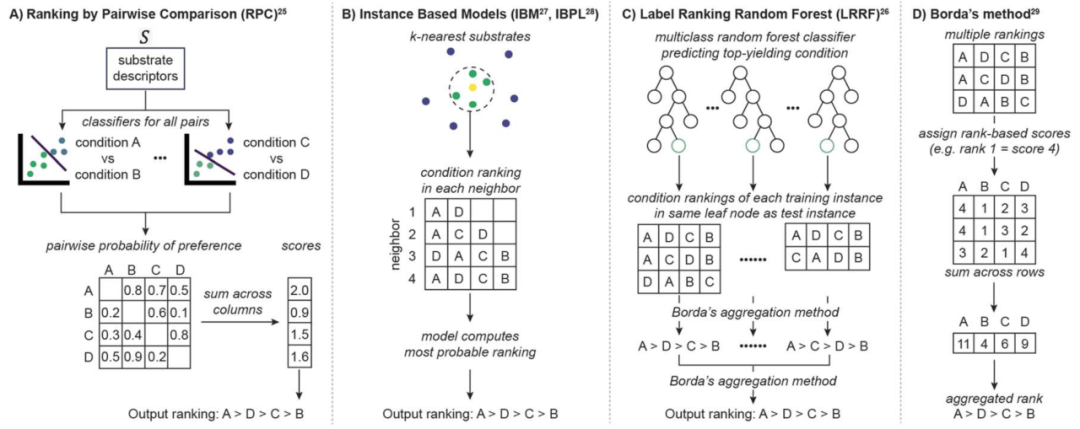
图 2
LR的两个主要组成部分之一是使用ML模型从底物中学习。例如,通过成对比较进行排序(RPC,图2A)学习预测底物在所有可能的条件对中产率更高的条件。RPC采用基于概率的分类器,如逻辑回归器或随机森林(在本工作中使用随机森林)来比较这些对。另一种ML技术涉及基于实例的概率模型(IBM或IBPL,图2B),它们与最近邻模型相关。这些模型从训练数据中识别与查询最相似的底物,假设底物特征相似性意味着反应活性相似性。另外,标签排序随机森林(LRRF,图2C)利用随机森林分类器来预测产率最高的条件。对于任何选择的LR算法,新的反应物进入模型并产生多个信息片段(反应条件的成对偏好、多个邻居,以及对于RPC、基于实例的模型和LRRF,分别具有相同最佳条件的训练实例)。为了输出单一预测,这些选择需要组合成单一排名,这在LR算法的第二个组成部分中实现。
LR的第二个组成部分将多个信息片段聚合成反应条件的排名。尽管这项任务简单,但没有一种通用策略可以产生最优排名。在众多近似方法中,博尔达方法(图2D)因其效率、处理缺失数据的修改版本的可用性,以及与其他聚合方案相比的竞争性能而常被用于LR。LRRF使用的博尔达方法根据每个反应条件的位置为其分配分数。然后,通过对每个条件在多个排名中收集的总分进行排序来确定最终输出排名。RPC使用的是这一过程的一个变体,其中分数是基于一个条件优于另一个条件的概率来分配的。IBM和IBPL利用概率模型来计算给定最近邻居排名的最可能排名。因此,LR是一个模块化框架,可以组合不同的模型和聚合策略来预测反应条件之间的排名。
LR算法的结构使得即使某些底物的训练数据缺失,也可以生成涉及所有反应条件的预测。这是因为模型可以通过应用从已标记数据中学到的内容来填补空缺(RPC、IBM和IBPL),或者在聚合过程中用对应于中间排名的分数((条件总数+1)/2)代替空条目(LRRF)。这表明LR模型可以以数据高效的方式进行训练,这对于尚未评估所有可能的底物-反应条件对的情况将是实用的。为了评估LR的效用,作者从文献中收集了各种结构良好、与合成相关的反应数据集。
从四个候选条件中预测产率最高的反应条件翻译
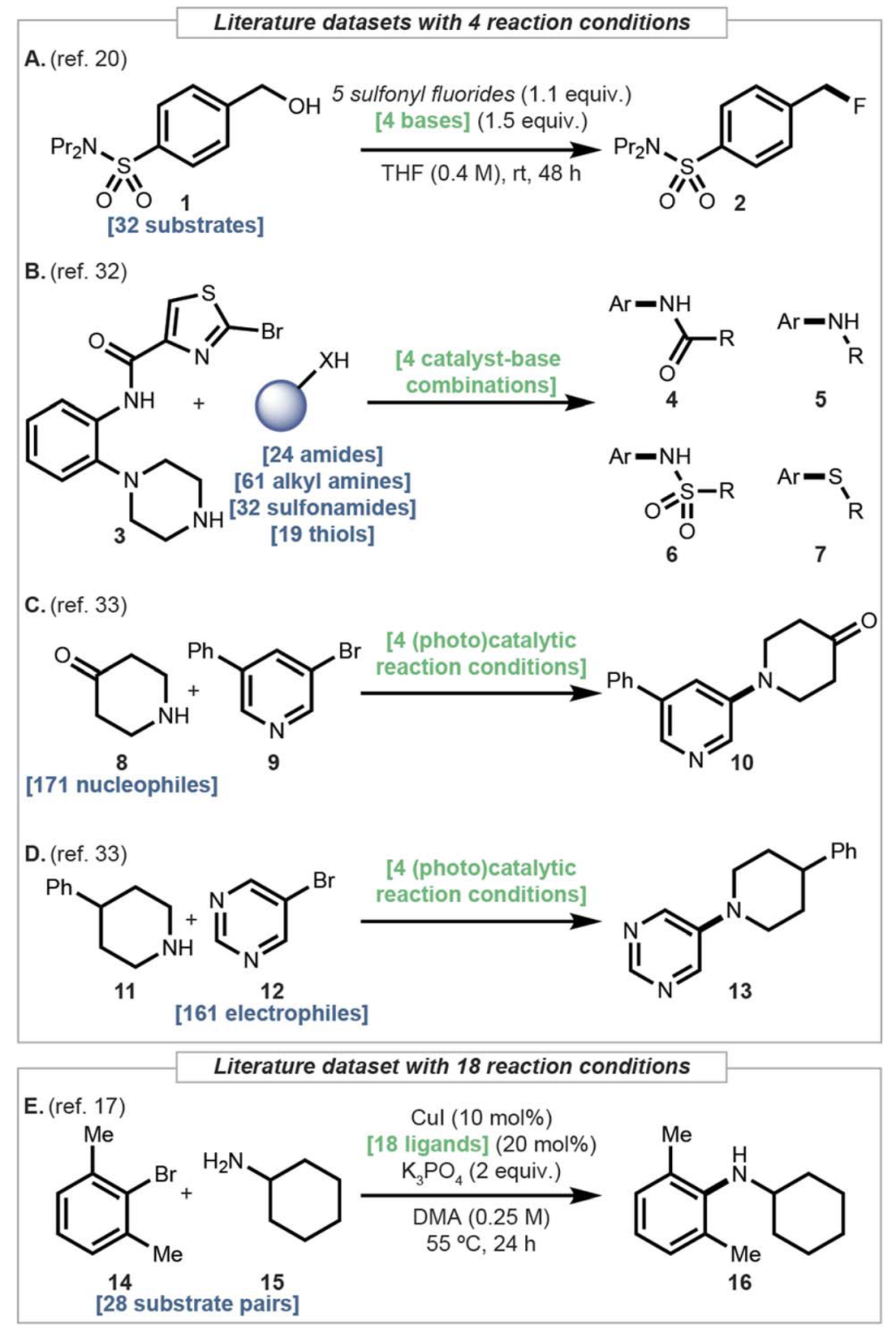
图 3
初步研究集中在比较不同算法在从四个候选条件中选择产率最高条件的效用(图3A-D中的数据集)。对于基于随机森林的模型(回归器、分类器、LRRF和RPC),反应用物理描述符表示。相比之下,由于从原始物理描述符计算的最近邻可能对推断反应活性相似性不那么有意义,因此对基于实例的模型(KNN、IBM和IBPL)使用了1024位、半径为3的基于计数的Morgan指纹。最终推荐的反应条件选择如下:对于每个测试底物,RFR预测每个反应条件候选的产率,使用预测值最高的那个。另一方面,对于RFC,制定了一个多类分类问题。多类RFC给出1-4中的单一预测,即给定底物,哪个条件将给出最高产率。为每个底物选择了预测类。对于LR,选择了排名最高的条件。基线对应于单独选择在训练数据中平均产率最高的反应条件,这对于不同底物需要不同条件的转化预计会不足。
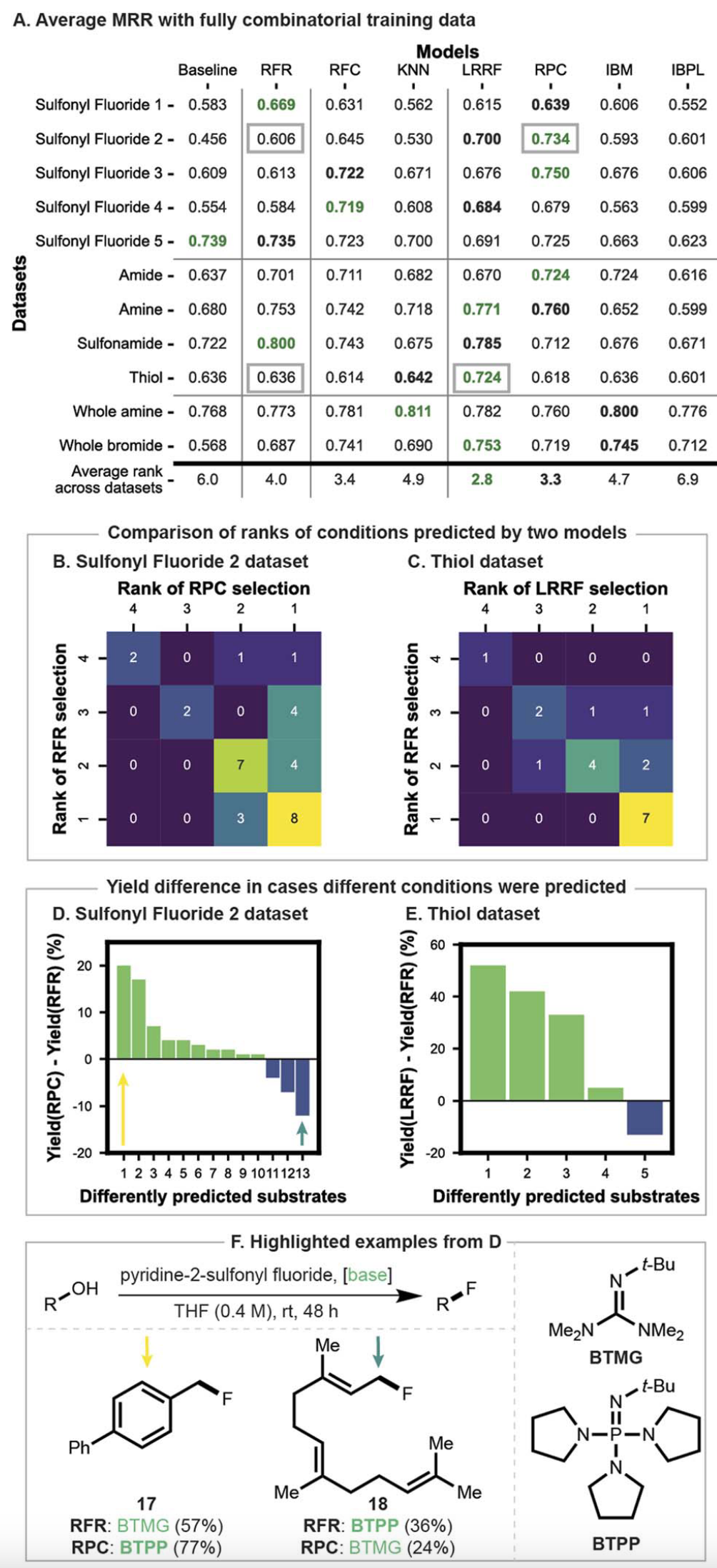
图 4
图4A显示了每个模型在每个数据集上实现的平均倒数排名(MRR)。前五行对应于图3A中描述的脱氧氟化数据集。基线难以提出有意义的建议,因为最佳表现的碱因底物而异。随机森林回归器(RFR)在四种情况下优于基线,而随机森林分类器(RFC)在三种情况下(第2-4行)优于RFR。两种基于随机森林的LR算法——LRRF和RPC——在三种情况下(第2-4行)优于RFR。特别是RPC在四个数据集(第1-3行和第5行)中实现了高于RFC的MRR。基于实例的模型表现相对较低,很少优于RFR。这些结果表明,虽然大约100个完全组合的训练数据点可能足以训练有效的回归器,但分类器和LR都可以作为选择良好反应条件的有用替代方案。
图4A的接下来四行显示了模型在具有四种亲核试剂的C-杂原子偶联反应上的表现(图3B)。作为具有不同底物偏好不同条件的小型数据集,观察到与前五行类似的趋势。与其他策略相比,基线表现平庸。RFR返回的结果不一,除了磺酰胺(在那里它排名第一)外,对于其他亲核试剂,它排在第3或第4位。RFC仅对酰胺返回了高于RFR的MRR,改进相对较小。LRRF和RPC总体表现良好,分别在三个和两个数据集中排在前2名。另一方面,基于实例的模型总体表现不佳,尽管IBM在酰胺数据集上得分尚可。这些结果意味着在低数据量情况下(少至19个底物)可以选择有效的反应条件,LR模型显示出高排名。
图4A的最后两行评估了图3C和D中数据集上的模型。这些数据集明显大于之前的数据集,规模大至前者的9倍(171个底物)。对于胺数据集,基线表现良好。所有基于RF的模型都难以获得有意义的更高分数,被KNN和IBM超越。相比之下,基线选择标准在溴化物数据集上表现最差。虽然RFR优于它,但在性能方面仅与KNN相当。LRRF总体上与IBM、RFC和RPC一起提供了最佳建议,但分数略低。总的来说,虽然基于实例的模型似乎在较大数据集上表现良好,但所有模型之间的性能差异相对较小。
在评估的所有数据集中,没有一种算法始终表现优越。虽然RFR与所有基于实例的模型相比返回了更高的平均排名,但它被替代模型超越。LRRF是总体表现最佳的,其次是RPC和RFC,支持它们作为在手头有完全组合数据集时从四个候选条件中选择最佳条件的有用策略。虽然这些从用MRR评估模型性能得出的结论很有用,但随后两段中的分析显示了这些分数如何转化为实验活动。
图4B和C比较了两对模型(RFR与RPC和LRRF),两者在MRR上相差0.1。为了理解这对预测最高产率条件意味着什么,比较了建议的质量。对角线上是两个模型预测相同反应条件的底物数量。对角线外对应于RFR预测的条件比另一个模型更好(对角线下)或更差(对角线上)的情况。在这两个数据集中,RFR和另一个模型推荐的条件同时位于更好的一半(右下象限),约占底物的65%。然而,替代模型比RFR更频繁地建议更好的反应条件(在图4B和C中分别为10比3和4比1)。其中有些情况下,RFR预测了两个较低产率的反应条件之一,而RPC或LRRF识别了最佳条件(图4B中有五个底物,图4C中有一个)。较低排名的预测将导致较低的产率,因此接下来对这一方面进行了量化。
图4D和E显示了个别底物的模型特定产率差异。蓝色和绿色条分别对应使用RFR相对于其他模型的产率益处和损害。这些比较揭示了特定底物,RPC和LRRF分别比RFR实现了近20%和50%的更高产率(最左侧绿色条)。对于图4D中的其余底物,益处不到10%。当RFR建议了更好的条件时,观察到类似的模式,最高益处(最右侧蓝色条)较小。虽然详细分布因数据集而异,但这些观察结果通常适用于基于RF的模型之间的比较(图S7-S17)。因此,在多个底物的累积益处很重要的情况下,应优先考虑性能更高的LR算法。
最后,图4F显示了图4D中产率差异最大的特定预测。当吡啶-2-磺酰氟作为氟化试剂时,RPC和RFR建议使用一种更大体积的碱,这可能是因为识别了底物的主要结构方面(立体可及性)。然而,这些模型并未统一捕捉到更微妙的特征(苄基17与烯丙基18)。
编译|黄海涛
审稿|王梓旭
参考资料
Shim, E., Tewari, A., Cernak, T., & Zimmerman, P. M. (2025). Recommending reaction conditions with label ranking. Chemical Science.
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢