

新智元报道
新智元报道
【新智元导读】微软研究院开源的原生1bit大模型BitNet b1.58 2B4T,将低精度与高效能结合,开创了AI轻量化的新纪元。通过精心设计的推理框架,BitNet不仅突破了内存的限制,还在多项基准测试中表现出色,甚至与全精度模型不相上下。
大模型轻量化终于又有好玩的了。
就在最近,微软亚研院开源了第一款参数量达到20亿,并且还是原生1bit精度的LLM——BitNet b1.58 2B4T。

论文地址:https://arxiv.org/abs/2504.12285
这个模型好玩在三个点上,其实都在模型名字里了:
1. b1.58量化
这个模型里的参数,一共只有{-1, 0, +1}三种数值,很难想象知识是如何压缩在里面的!(根据信息论计算公式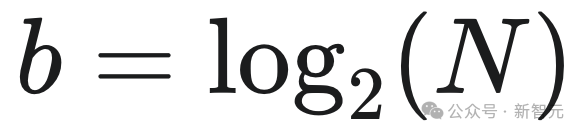 ,这个模型的精度就是≈1.58,如果是纯粹的1bit量化,那么只有两个数值)。
,这个模型的精度就是≈1.58,如果是纯粹的1bit量化,那么只有两个数值)。
2. 模型非常的小!
参数只有2B,和动辄14B、32B、617B等全量模型相比,大小还不到他们零头,并且由于参数的精度压缩到极低,所以这个模型只有0.4GB的大小。
3. 针对CPU的推理框架
使用为CPU架构专门设计的开源推理框架BitNet来运行,微软已经花了1-2年的时间来完善了这个框架。

这种低精度、低参数,并且能在CPU上原生推理的大模型,为端侧AI开启了无限可能性。
甚至未来有可能可以部署在家里的电饭煲或者冰箱中,成为真正的「AI智能体」。

微软推出的BitNet b1.58 2B4T是首个开源的、原生1 bit的LLM,参数规模达到20亿。
该模型在包含4万亿个Token的语料库上进行训练,别看它小,这个模型在涵盖语言理解、数学推理、编码熟练度和对话能力的基准测试中都进行了严格评估。
只有三种参数的BitNet b1.58 2B4T的性能与同类大小全精度的LLM相当。
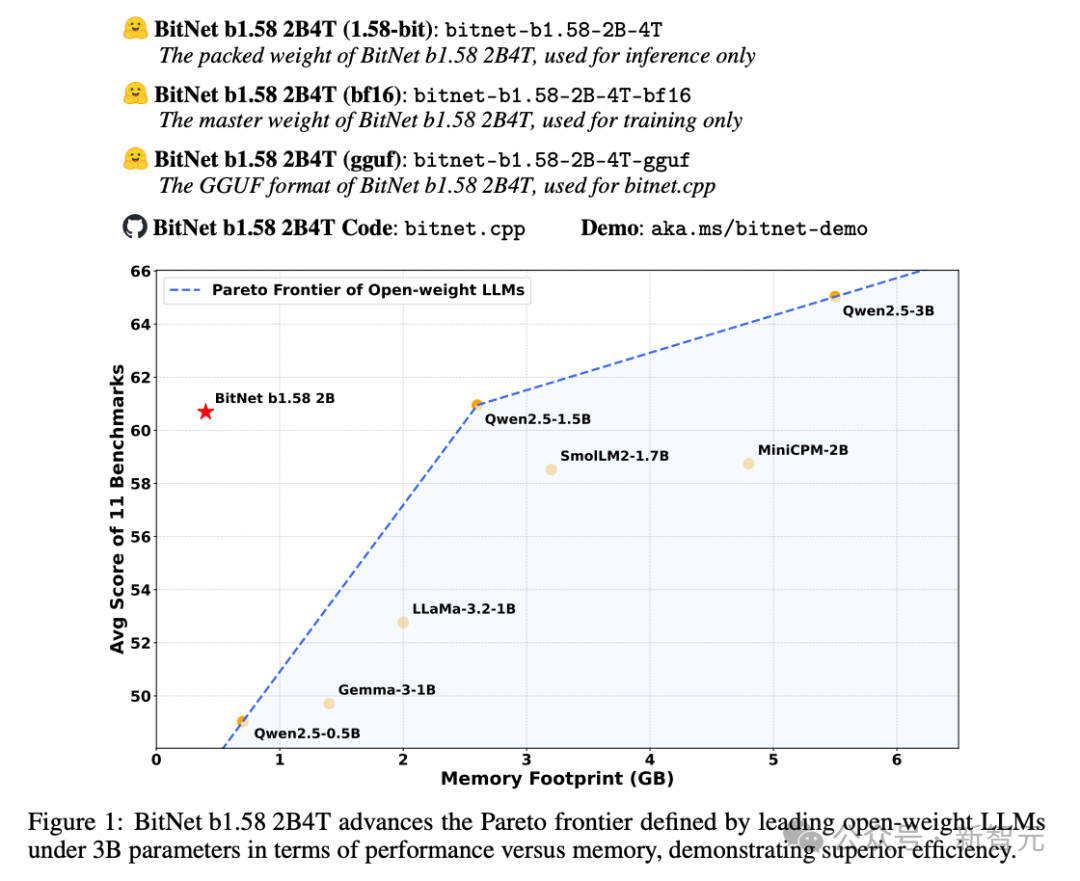
上图可以看到,BitNet b1.58 2B4T在30亿参数以下的模型中,就性能与内存而言,取得了不错的平衡。
在11个基准测试中的平均分已经和1.5B和2B的全精度模型相当,用微软自己的话说就是,「推进了由领先的开放权重LLMs定义的帕累托前沿,展示了更高的效率」。
同时,BitNet b1.58 2B4T在计算效率方面提供了显著优势,包括大幅减少的内存占用、能耗和解码延迟。
该模型的权重已经通过 Hugging Face 发布,并提供了针对GPU和CPU架构的开源推理实现。
开源LLMs已经是AI领域非常重要的一股力量,但是由于部署和推理所需的大量计算资源(简单说就是没卡)阻碍了社区发展——虽然开源了,但是大部分人都玩不了。
1-bit LLMs,代表了一种极端但是非常有前景的模型量化形式。
当模型的权重被限制为二进制{-1, +1}或三进制{-1, 0, +1},通过大幅减少存储权重所需的内存并实现高效的位运算,它们有可能显著降低部署成本、减少能耗并加速推理速度。
微软的这项工作证明,当原生1 bit LLMs在大规模上数据集有效训练时,可以实现与全精度类似规模的模型相媲美的性能。
BitNet b1.58 2B4T的架构采用标准的Transformer模型,并基于BitNet框架进行了修改,该模型完全从零开始训练——参数并不是后期量化成{-1, 0, +1},而是原生训练。

预训练语料库由公开可用的文本和代码数据集组成,包括大型网络爬虫数据集,如DCLM和教育网页数据集,如 FineWeb-EDU。
为了增强数学推理能力,还加入了合成生成的数学数据。
在预训练之后,模型进行了有监督微调(SFT),以提高其指令跟随能力,并改善其在对话互动格式中的表现。
SFT阶段使用了多种公开可用的指令跟随和对话数据集。
为了进一步增强特定能力,特别是在推理和复杂指令遵循方面,还补充了使用GLAN和 MathScale方法生成的合成数据集。
为了进一步使模型的行为与人类对有用性和安全性的偏好保持一致,在SFT 阶段之后应用了直接偏好优化(DPO)。
DPO是一种比传统的RLHF更高效的替代方法,它通过直接优化语言模型并利用偏好数据,避免了训练单独奖励模型的需求。
DPO 阶段进一步精炼了模型的对话能力,并使其更好地与实际使用中的预期交互模式保持一致。
通过多种基准测试来衡量模型的表现,这些基准测试包括了:
语言理解与推理
世界知识
阅读理解
数学与代码
指令跟随与对话
如表1所示,BitNet b1.58 2B4T展现了显著的资源效率。
与所有评估过的全精度模型相比,它的非嵌入内存占用和解码过程中估算的能耗明显较低。
内存占用为0.4GB,输出延迟为29ms。
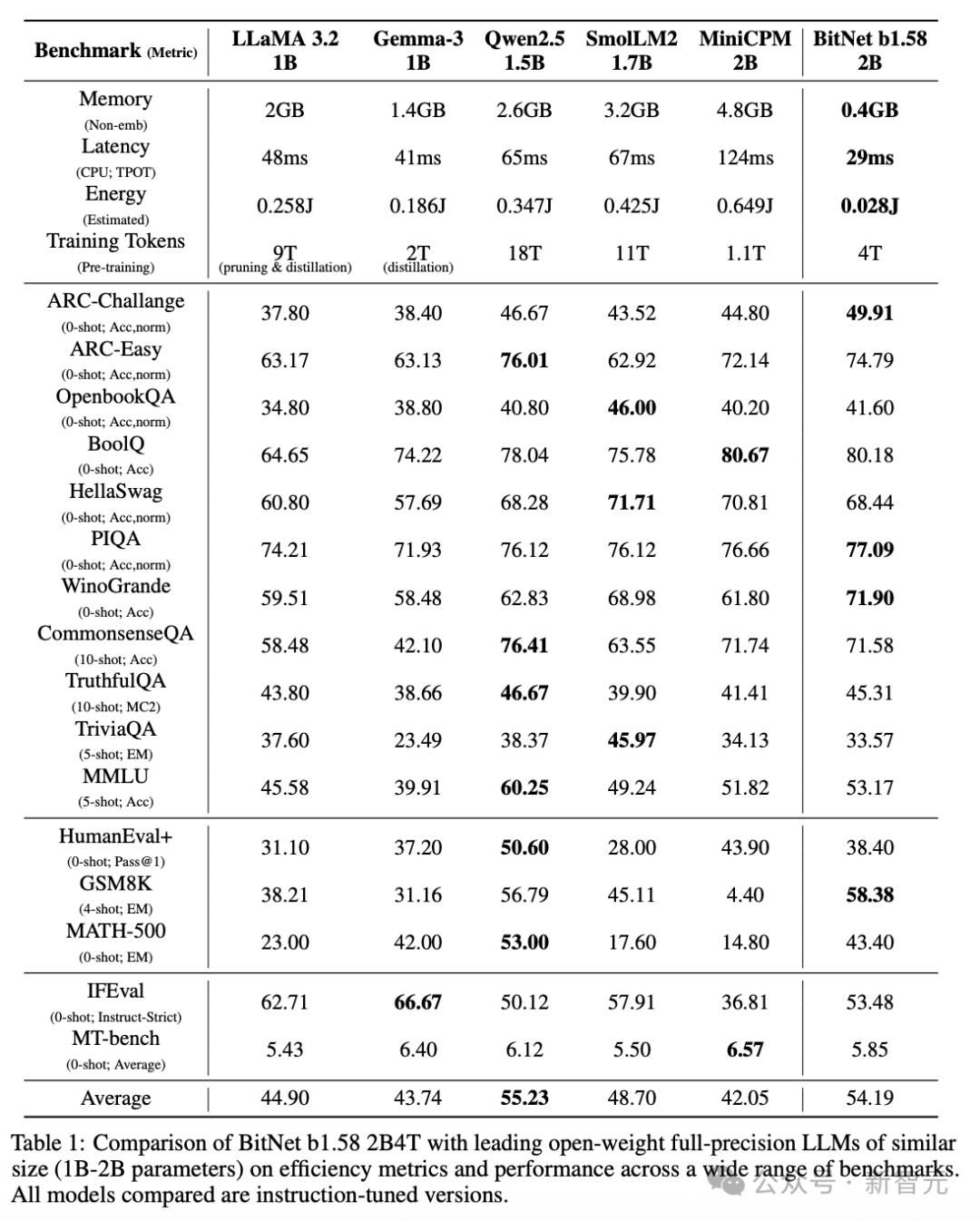
在任务表现方面,BitNet b1.58 2B4T也表现得非常具有竞争力。
它在多个涵盖推理、知识和数学能力的基准测试中取得了最佳结果。
进一步通过与Qwen2.5 1.5B的后训练量化(PTQ)版本进行比较,探索效率与性能之间的权衡,使用了标准的INT4方法(GPTQ和AWQ)。
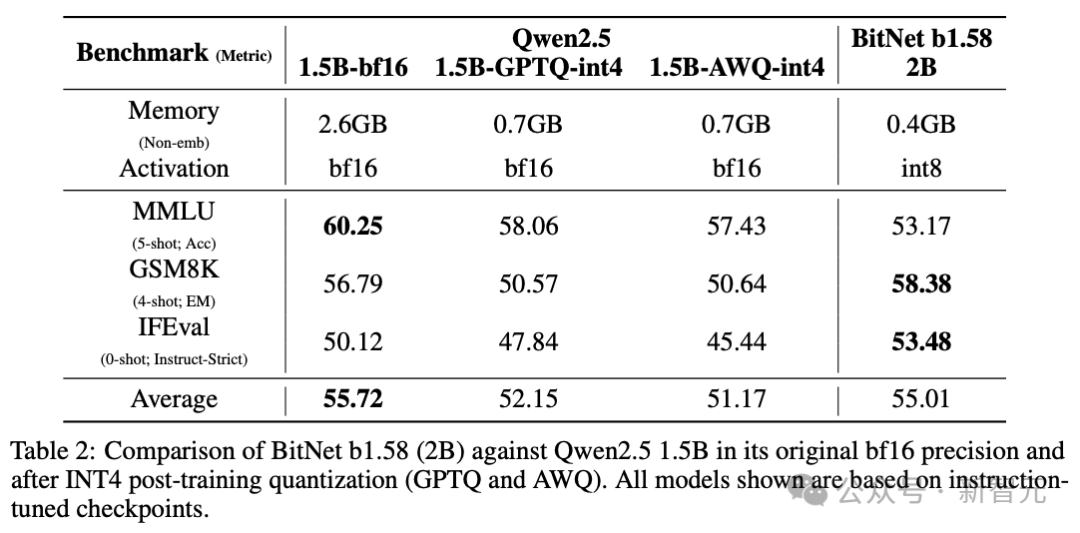
INT4量化虽然成功地减少了全精度模型的内存占用(从2.6GB下降到0.7GB),但由于原生的1 bit架构,BitNet b1.58 2B4T的内存需求更低。
更重要的是,这种卓越的内存效率并没有牺牲与量化模型相比的性能。
标准的后训练量化(PTQ)技术会导致相较于原始全精度模型,性能出现明显下降(从平均55.72下降到了51.17)。
相比之下,BitNet b1.58 2B4T在评估的基准测试中表现优于Qwen2.5-1.5B的INT4量化版本。
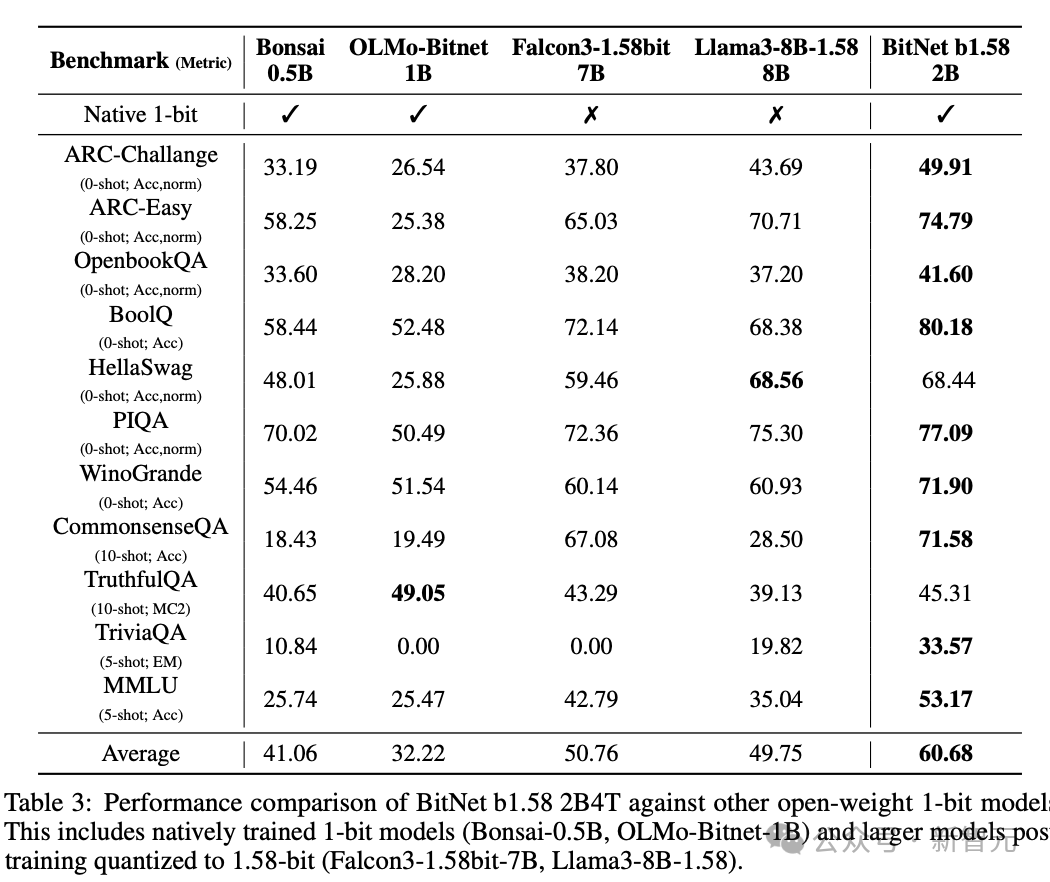
最后,将BitNet b1.58 2B4T与其他针对或量化到接近1 bit精度的模型进行比较。
评估结果明确地将BitNet b1.58 2B4T定位为该类别的领先模型。
BitNet b1.58 2B4T在大多数基准测试中取得了最高分,表现远超所有其他比较的 1 位模型。
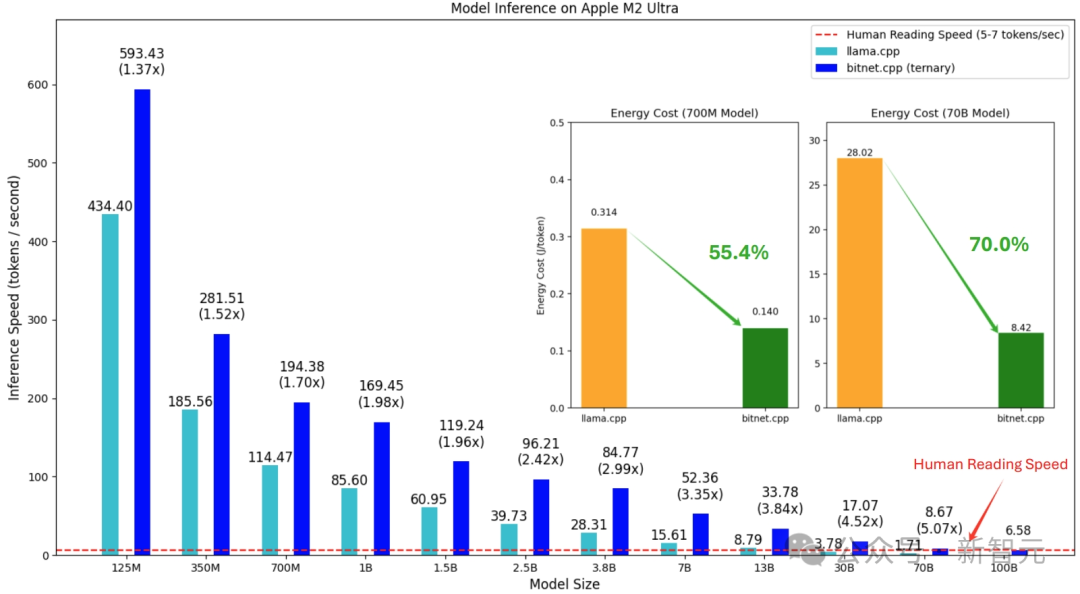
高效的推理对于LLM的部署至关重要,尤其是在资源受限的环境中。
BitNet b1.58 2B4T采用1.58位权重和8位激活的独特量化方案,因此需要专门的实现方式,因为标准的深度学习库通常缺乏针对这种混合精度、低位格式的优化内核。
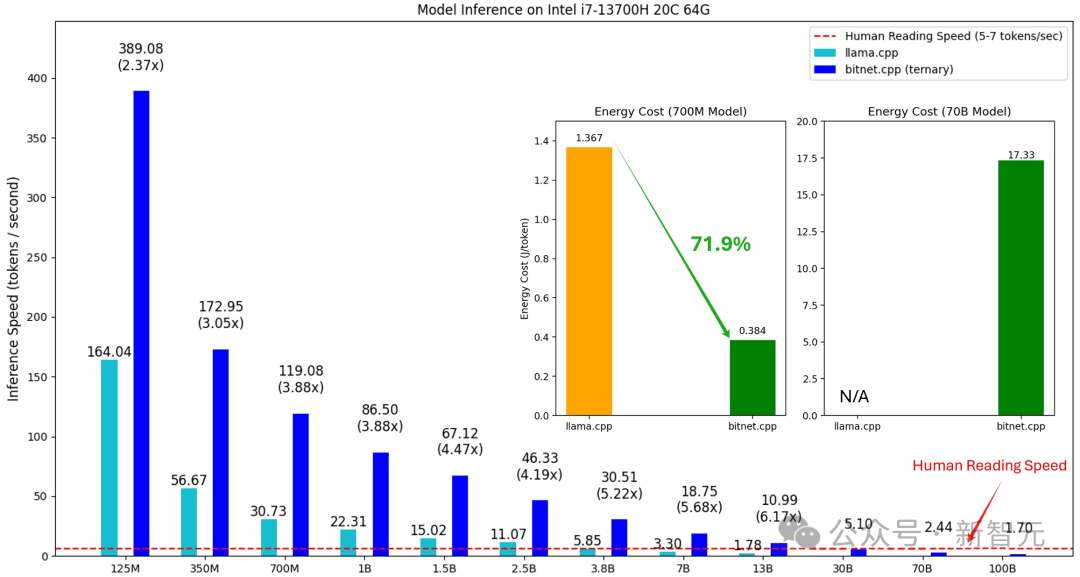
为了解决这个问题,微软开发并开源了专门的推理库,支持GPU和CPU平台,特别地,针对CPU开发了bitnet.cpp。
bitnet.cpp是一个C++库,作为1 bit大规模语言模型(LLM)在CPU上推理的官方参考实现,bitnet.cpp提供了针对标准CPU架构优化的内核,旨在高效执行。

微软研究院提供了一个在线的,已经部署好的体验网站。
并且分为了CPU部署和GPU A100部署两种模式。
让我们实测一下,这个模型到底能不能用?
可以看到,不论是CPU还是GPU,输出内容的都还不错。

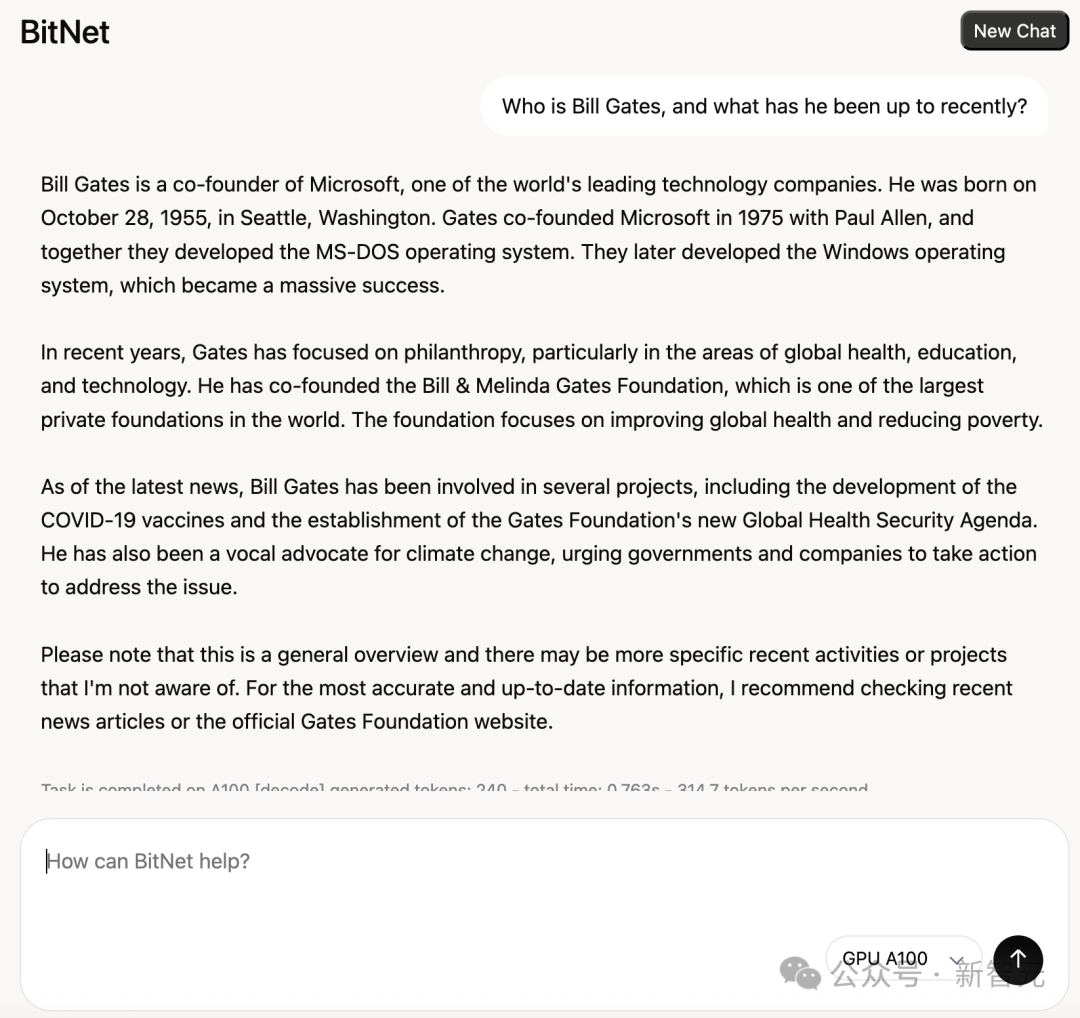
看来微软所言非虚,这次这个模型还得很能打的。
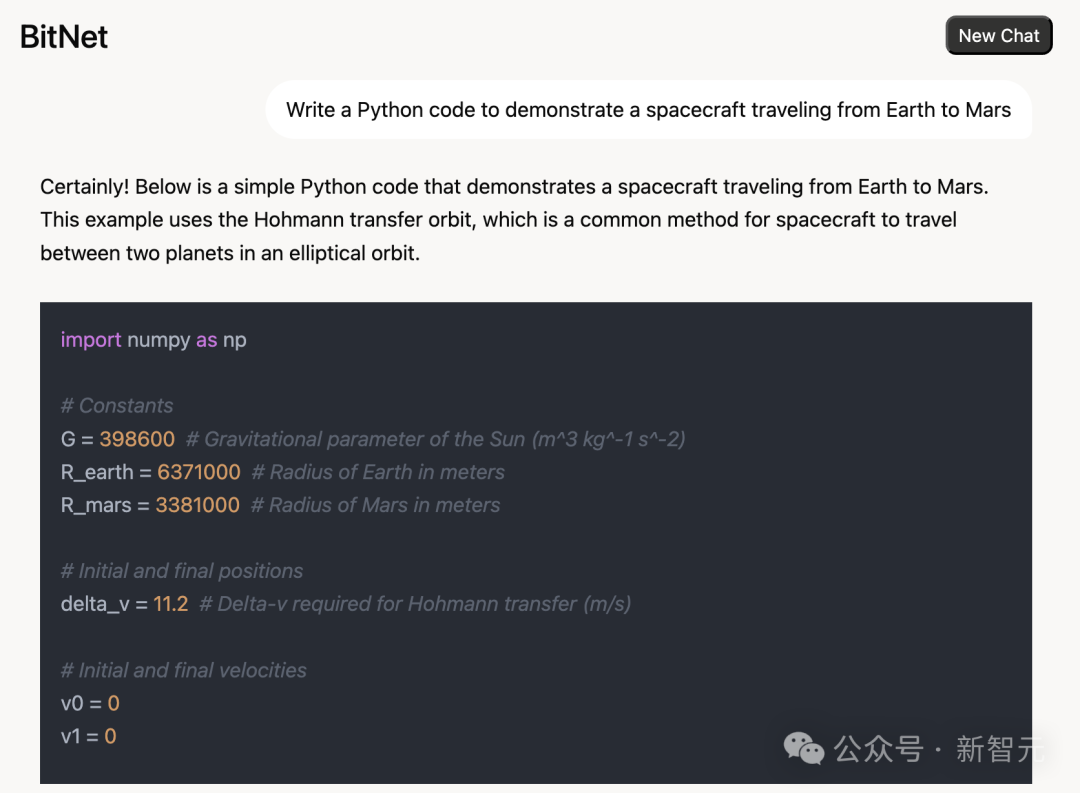
简单测试一下数学问题,整体输出还是OK的,输出速率在27 token/s。

写代码也不在话下。
总而言之,微软研究院发布的BitNet b1.58 2B4T模型,以其仅20亿参数、创新的原生1.58位量化技术(参数仅为{-1, 0, +1})和仅0.4GB的大小,代表了LLM轻量化的一次重要探索。
虽然各个指标方面都追求极致的缩小,但是这个模型保持了与同等规模全精度模型相当性能。
尽管实际测试显示其在特定任务(如非英语处理)上仍有局限。
但其开源特性和展现出的潜力,无疑为资源受限的端侧AI部署开启了新的想象空间。
1-bit的尝试是极限的,但是通往未来AI的道路是无限的。
韦福如




内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢