
DRUGAI
今天为大家介绍的是来自台北荣民总医院的邱士华教授与美国加州大学的Kai-Wei Chang教授团队发表的一篇论文。多模态大语言模型(MLLMs)在现代医疗领域带来了革新性的突破,特别是在放射学报告自动生成(RRG)这一尖端技术领域。尽管基于2D MLLM的放射学报告生成技术已经相当成熟,但在3D医学影像方面的应用研究仍然有限。针对这一现状,研究团队构建了包含18,885对影像-文本数据的3D-BrainCT数据集,并开发了BrainGPT模型。该模型通过临床视觉指令优化(CVIT),专门用于生成3D CT放射学报告。研究中发现,传统的语言模型评估方法难以准确衡量生成报告的医学诊断价值,因此团队创新性地提出了特征导向的放射学任务评估体系(FORTE)。该评估体系从医学诊断的核心要素出发,综合考虑病变程度、解剖标志物、影像特征和临床印象等多个维度。测试结果显示,BrainGPT在FORTE评估中获得了0.71的平均F1分数,其中临床印象评分最高,达到0.779。更值得注意的是,在模拟临床真实场景的人机对比测试中,74%的BrainGPT生成报告被评估者认为与人工撰写的报告质量相当。这项研究为3D医学影像的自动报告生成提供了完整的技术框架,包括数据集建设、模型优化和评估体系,为推动人机协作在下一代医疗领域的应用奠定了基础。

人工智能在现代医疗领域掀起了一场革命。尽管卷积神经网络(CNN)在医学图像分类和特征分割方面取得了显著成果,但其输出结果往往局限于特定场景,难以与完整的医学诊断报告相媲美。为弥补这一临床差距,研究者们开发了一系列报告生成模型,特别是在胸部X光解读方面取得了突破性进展。目前,微软的LLaVA-Med和谷歌的Med-PaLM Multimodal等多模态大语言模型在X光片和单层CT扫描报告生成方面已经展现出初步成效。然而,这些模型仍面临着几个关键挑战:首先,模型对病理特征的描述能力如何;其次,在定位病变时的解剖学精确度如何;最后,能否准确评估病变的程度和大小。此外,现有的单层CT图像数据往往是人工预选的确诊病例,这可能导致评估结果出现偏差。因此,建立完整的3D影像数据集来测试MLLMs在真实诊断场景中的表现变得尤为重要。针对这些问题,研究提出了三个解决方案:
构建了包含18,885对数据的3D-BrainCT数据集;
引入临床视觉指令调优(CVIT)概念,增强模型的医学领域知识;
提出特征导向的放射学任务评估(FORTE)结构,包含程度、标志物、特征和印象四个关键评估维度。
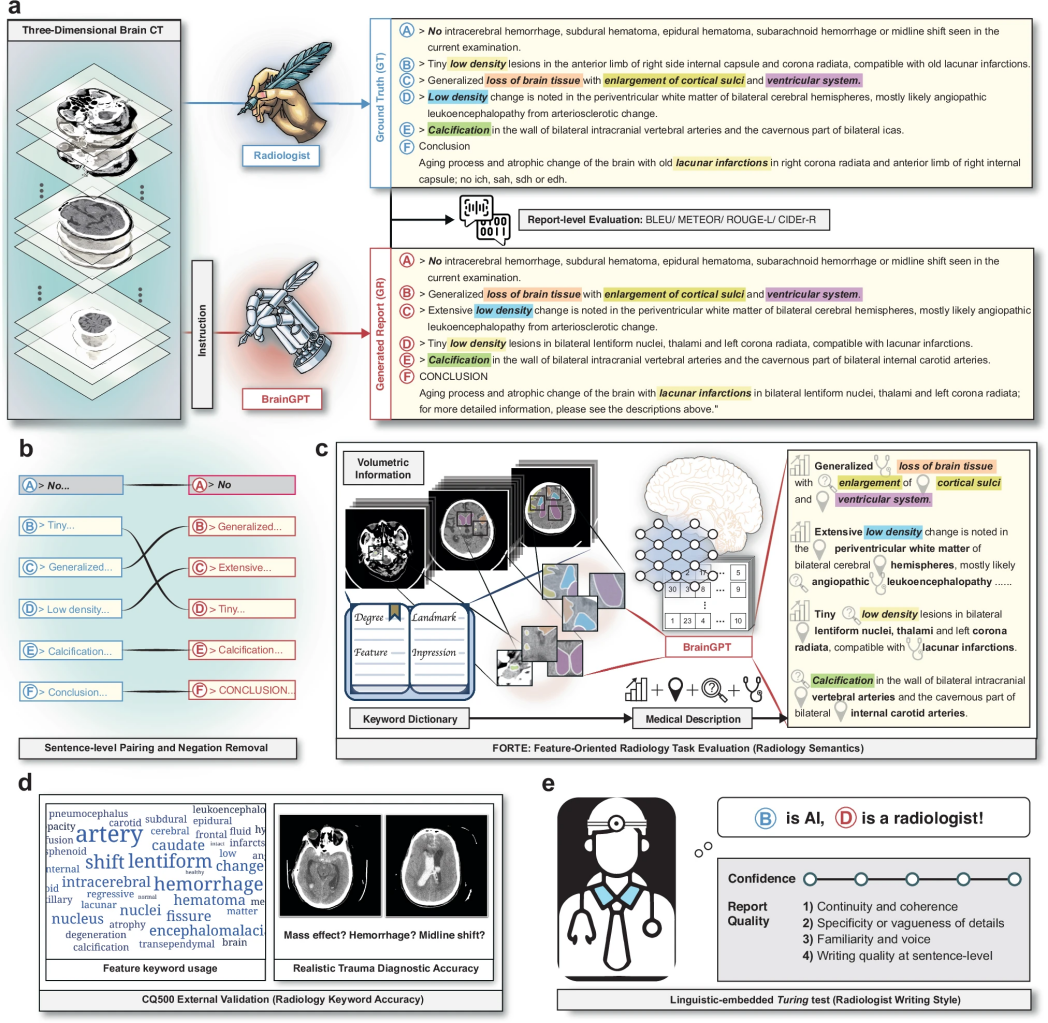
图 1
图1展示了该研究在脑部CT和一般医学图像解读中MLLM应用的全面框架。
用视觉指令微调训练BrainGPT
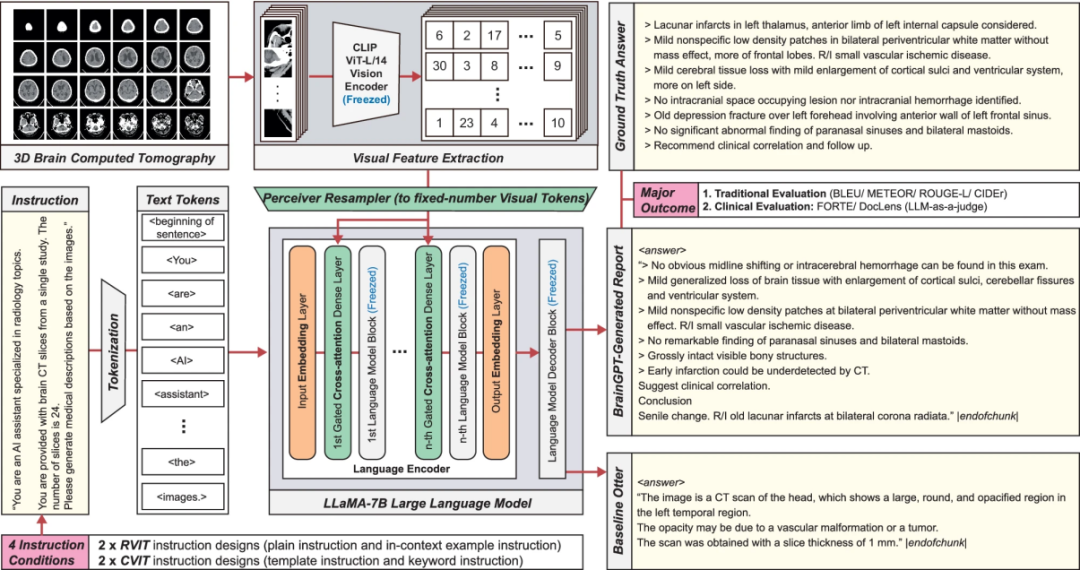
图 2
为了实现基于医学多模态大模型(MLLM)的3D颅脑CT报告生成,研究团队收集了真实的3D-BrainCT数据集,并采用视觉指令微调(visual instruction tuning)方法训练BrainGPT模型(图2)。
在模型微调过程中,研究团队探索了两类指令微调策略:
标准视觉指令微调(RVIT):
基础指令:仅向模型提供其作为放射学助手的角色说明
上下文示例指令:在基础指令的基础上增加3个示例(3-shot),帮助模型理解任务
临床视觉指令微调(CVIT):
模板指令:在基础指令中加入结构化的临床QA模板,使其输出更符合放射学报告格式
关键词指令:在基础指令中融入基于关键词的分类引导,以强化报告的临床术语表达
基于这些微调策略,研究团队训练了四种BrainGPT变体:BrainGPT-plain、BrainGPT-example、BrainGPT-template、BrainGPT-keyword,使其在CT解释任务上具备不同层次的临床合理性。
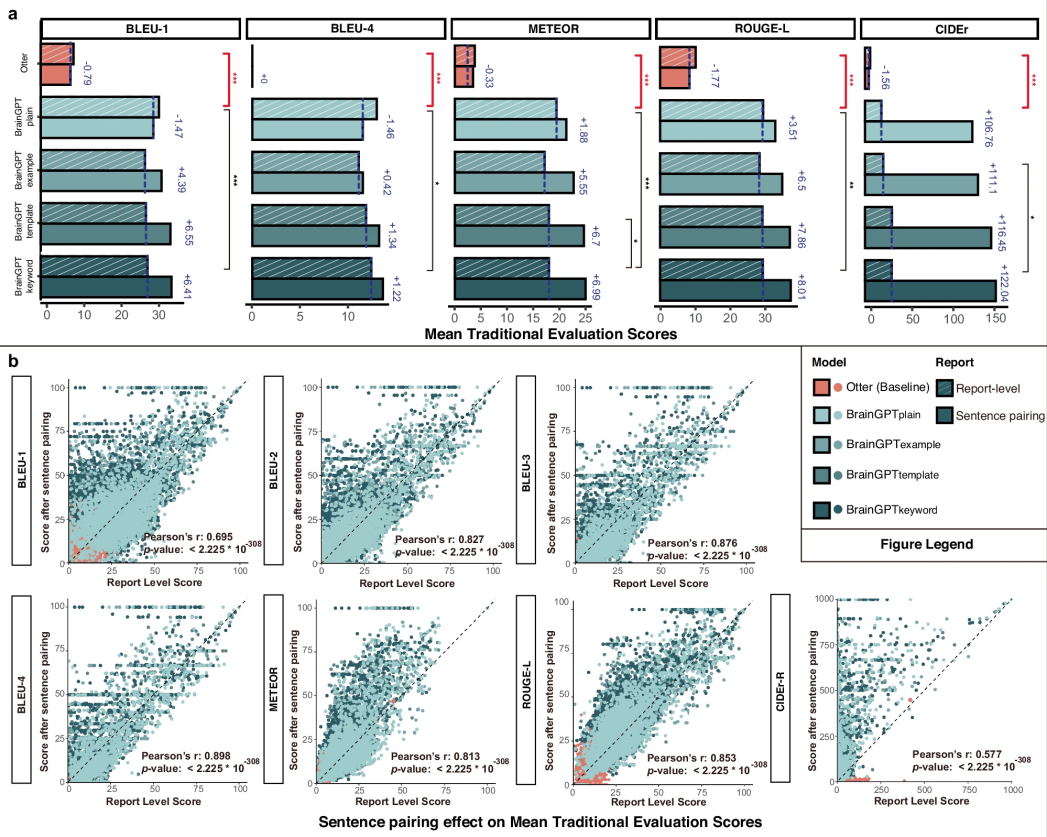
图 3
在完整的CT报告评估中,所有微调后的BrainGPT模型在传统评估指标上均显著优于基线 Otter 模型(图3a)。其中,基线Otter模型在BLEU-4评分仅为0,CIDEr-R评分为5.9,表明其生成的CT报告在n-gram匹配度和临床术语使用频率上存在明显不足。此外,研究团队发现,传统评估指标与报告实际质量之间存在偏差。
值得注意的是,除CIDEr-R之外,其他传统评估指标未能体现RVIT和CVIT方法带来的逐步增强的精细度。这一结果表明,现有的传统评估方法对放射学报告的临床价值缺乏足够的敏感性。
语句对齐
为探讨基于列表的脑部 CT 报告架构是否导致传统评估指标得分偏低,研究团队引入语句对齐方法,将多句段落拆分为更小的语义单元,以优化评估精度。实验结果显示,句子对齐显著提升了传统评估指标得分,平均提升幅度如图3a所示。在所有BrainGPT模型上,大多数传统评估指标得分均显著提高(图3b)。进一步分析发现,BLEU-2、BLEU-3、BLEU-4、METEOR 和 ROUGE-L 之间存在高度线性相关性。值得注意的是,与其他n-gram评估指标相比,语句对齐对CIDEr-R指标的提升幅度最大。此外,研究还发现,随着临床视觉指令微调(CVIT)复杂度的增加,传统评估指标得分同步提升,其中CIDEr-R 指标的增长最为明显。语句对齐不仅减少了输入报告与生成文本之间的顺序依赖,还进一步凸显了临床指令设计在逐行鉴别性诊断报告生成中的重要作用。
面向特征的放射学任务评估(FORTE)
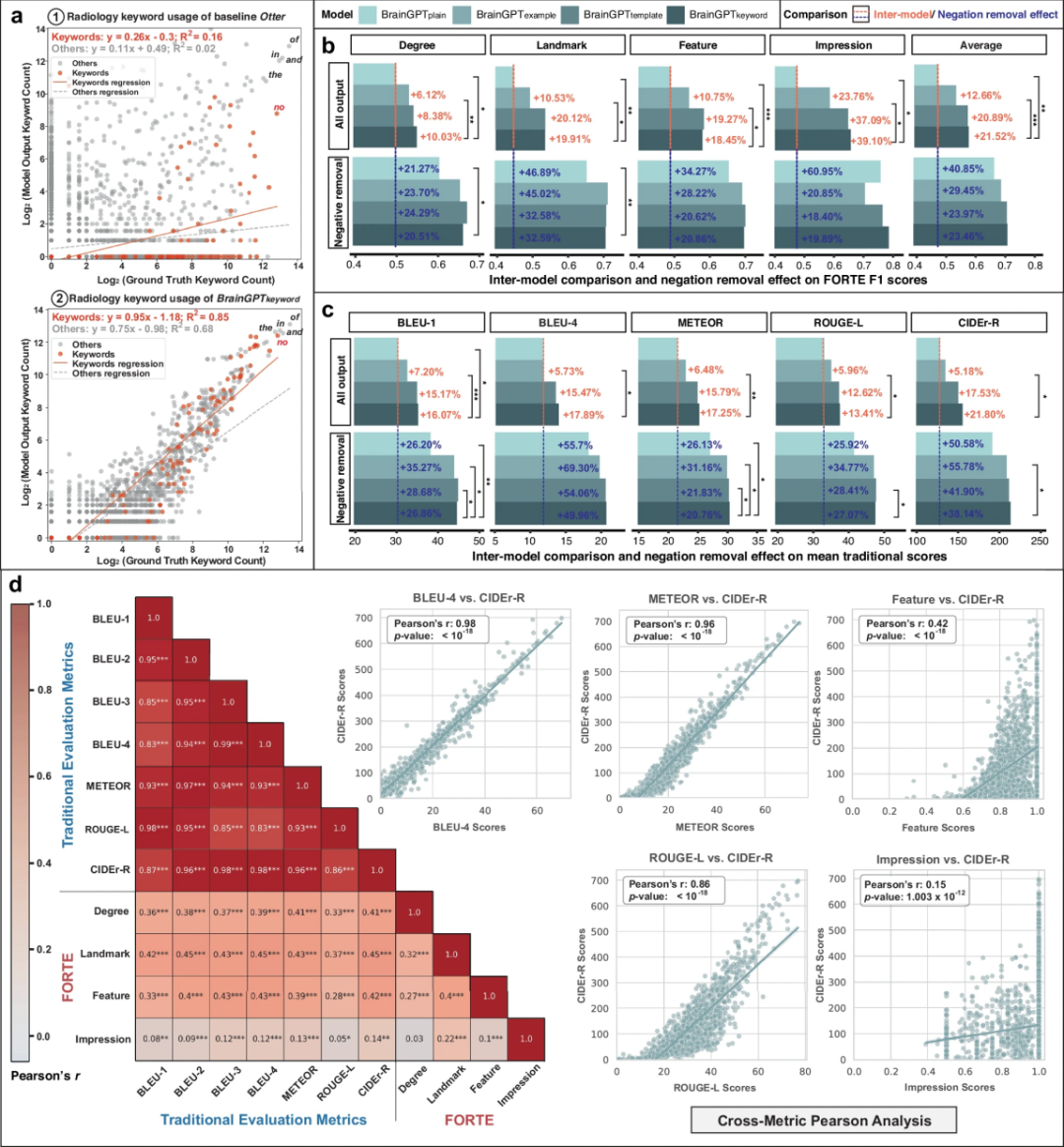
图 4
由于CIDEr-R能够捕捉视觉指令微调(Visual Instruction Tuning)过程中的层级临床特性,研究团队假设其词频-逆文档频率(TF-IDF)组件对放射学报告中的罕见关键词具有敏感性。因此,研究人员分析了真实报告(ground truth)和模型生成报告中的术语频率(图4a)。结果显示,基线模型Otter召回放射学关键词的能力较弱,而经过视觉指令微调后的BrainGPT模型在影像描述中显著提高了放射学关键词的使用率。BrainGPT-keyword模型在不同频率的放射学关键词上均保持了较高的召回率。
基于关键词频率实验和对CheXpert分类器的深入分析,研究团队提出了一种新的评估方法——面向特征的放射学任务评估(FORTE)。该方法专注于报告中医学信息的密度,通过结构化的关键词提取来提升评估效果,主要包含三个方面:
处理放射学报告的多语义上下文;
识别同义词,以扩展相关术语范围;
可适用于多种影像模态。
研究团队将放射学关键词及其同义词划分为程度(degree)、解剖部位(landmark)、特征(feature)和诊断印象(impression)四个子集,以此对系统性能进行多维度评估。在 FORTE 评估中,高级CVIT模型(BrainGPT-template 和 BrainGPT-keyword)在F1分数上显著优于 RVIT 模型(图4b)。其中,BrainGPT-keyword在FORTE评估中的F1分数分别为0.548、0.533、0.574和0.649,表明临床指令微调的BrainGPT模型生成的脑部CT报告在放射学术语使用方面更加贴合原始诊断报告。
研究团队进一步比较了FORTE评估方法与传统评估指标(图4d),发现传统指标内部相关性较高,但与FORTE相关性较低。此外,FORTE的四个评估维度(degree、landmark、feature、impression)之间的相关性也较低。这表明FORTE能够涵盖传统评估指标未能有效刻画的疾病特征,提供更全面的评估视角。
研究人员在关键词使用频率分析中发现,“no”(否定词)在报告中出现频率极高,与“of”、“and”、“in”、“the”等常见词相当。这一现象与“报告偏差”假设相矛盾——即一般认为语言模型与普通人一样,更倾向于忽略负面描述。然而,临床上,放射科医生更倾向于使用面向上下文的描述来“排除”特定诊断目标,而BrainGPT在这方面表现不佳,导致报告中充斥着冗长的否定描述,而非精准、符合医学习惯的表达。研究团队将这一现象称为“解释泛滥”。为了解决这一问题,研究人员采用否定去除(Negation Removal)方法,以减少无关的否定描述,并提升报告的精准度(图4c)。
在CQ500外部验证集上评估BrainGPT泛化能力
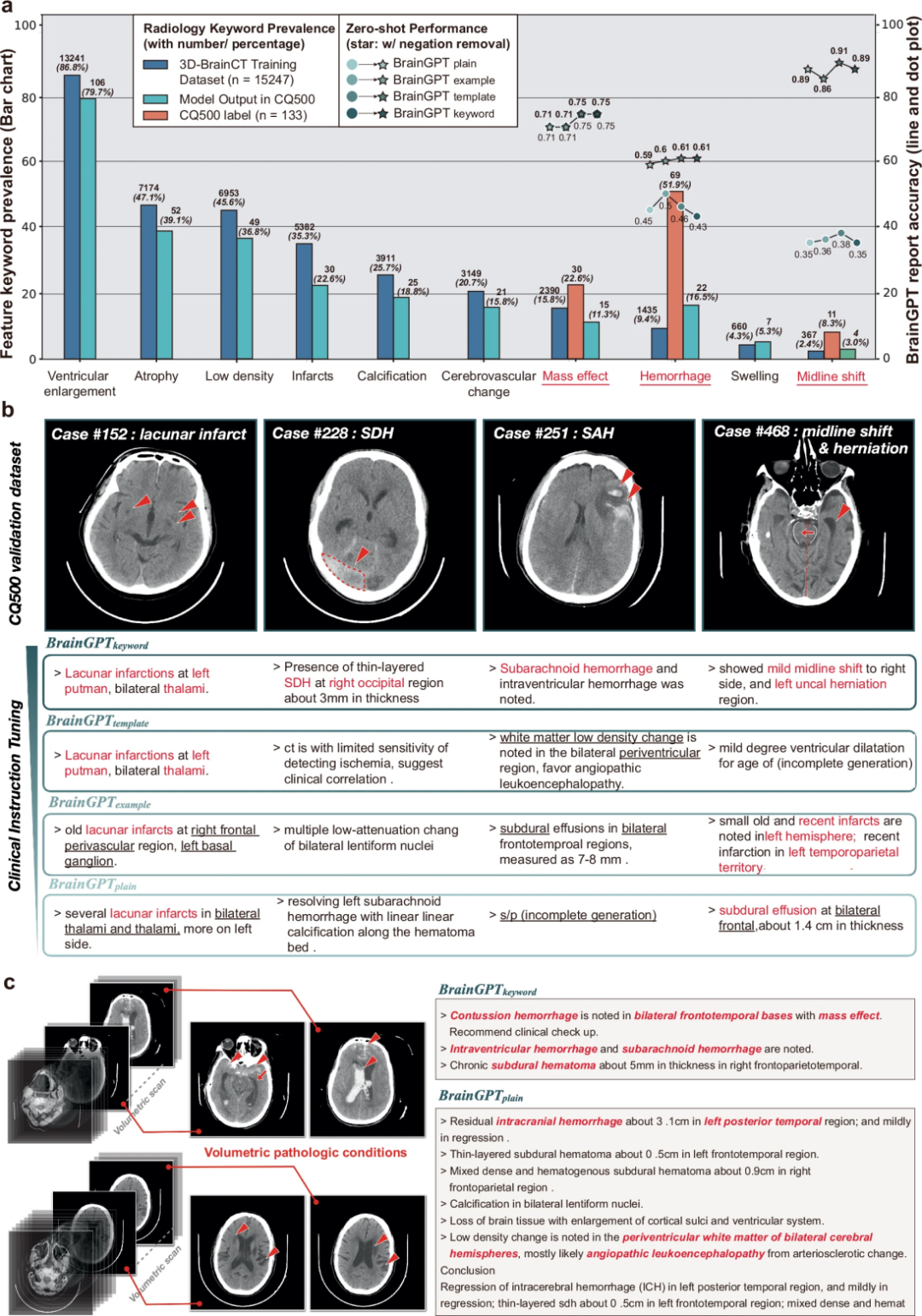
图 5
研究团队在CQ500颅脑CT数据集(n=133)上进行零样本外部验证,评估BrainGPT生成报告的能力。他们比较了BrainGPT生成的报告与CQ500 CT真实标签(ground truth),计算临床关键词检索率(图5a)。结果表明,BrainGPT在CQ500数据集中能够准确生成报告,并提及 脑室扩大、脑萎缩、梗塞、占位效应 等关键放射学术语,其频率与训练数据(3D-BrainCT)相近,证明BrainGPT具备良好的零样本CT报告生成能力。
研究进一步评估BrainGPT对腔隙性脑梗死、硬膜下出血、蛛网膜下腔出血、正中结构偏移伴占位效应的识别能力(图5b)。在腔隙性脑梗死病例中,BrainGPT-example成功识别丘脑和壳核的低密度梗死灶,但误拼写putamen为putmen,这可能受训练数据影响。研究团队评估 BrainGPT 在多病灶CT影像中是否仅关注某些病灶。结果显示,在某些多病灶 CT 中,BrainGPT 能区分不同类型的出血(脑挫伤、脑室内出血、蛛网膜下腔出血),但病变定位仍然不够精准(如仅提到“额颞叶”,未精确定位)。此外,BrainGPT 还成功描述慢性ICH吸收期及脑室周围血管性白质脑病(PVL)以及白质低密度,进一步证明其在鉴别诊断方面的潜力。
用LLM评估医疗报告的质量
本研究探讨了如何利用大语言模型(LLM)来评估医疗报告的质量。研究团队开发的BrainGPT系统在传统评估方法和新型FORTE评估框架中都展现出优秀表现。为了验证系统的可靠性,研究人员使用了DocLens(一种基于大语言模型的医疗文本评估工具)作为参考标准。
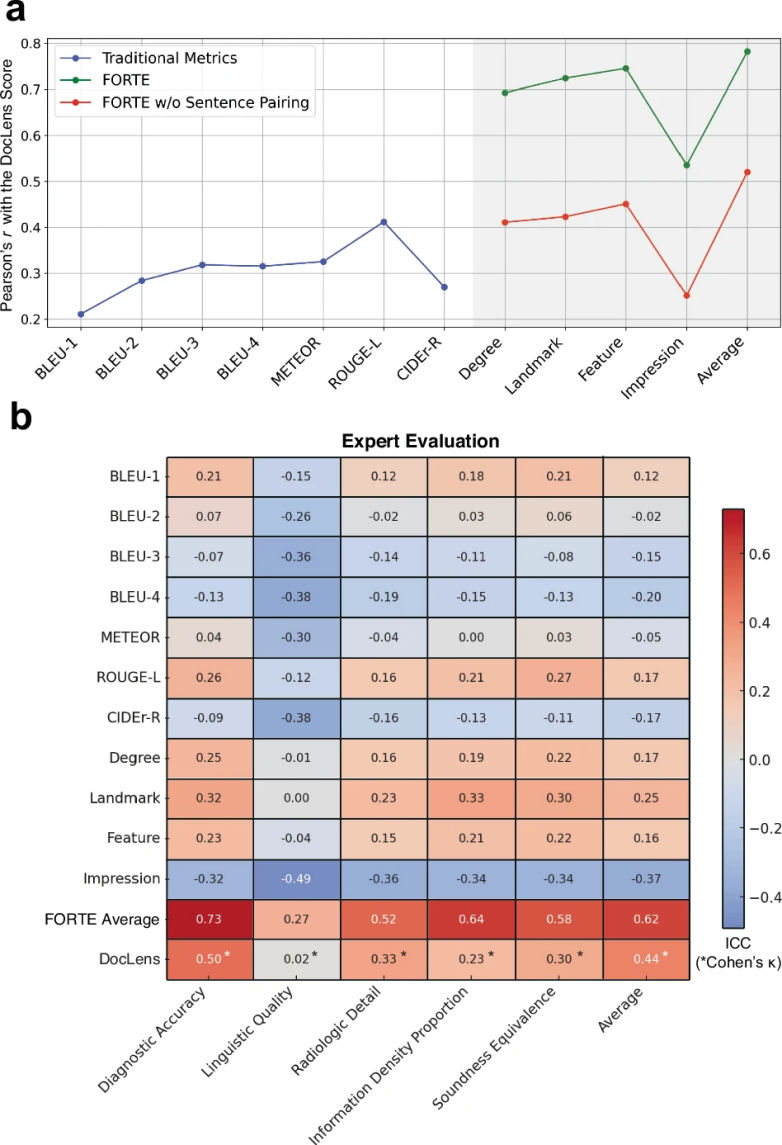
图 6
研究发现,在对系统进行视觉理解能力强化训练前后,DocLens和FORTE的评分结果高度一致。未经训练时两者均为0.102,训练后分别提升至0.589和0.539,这表明FORTE评估框架与大语言模型的判断标准相符。图6a的分析结果显示,DocLens评分与FORTE评分呈现显著正相关,但与传统评估方法的相关性较低。这说明传统评估方法可能无法很好地衡量医疗报告中的语义复杂性。
为了进一步验证系统的实用性,研究团队邀请了两位医生对50份随机抽取的报告进行评估。如图6b所示,专家评分与FORTE评分在多个维度上显示出良好的一致性:诊断准确性(0.73)、语言表达质量(0.27)、放射学细节完整度(0.52)、密度描述准确性(0.64)和整体合理性(0.58),总体相关系数达到0.62。这些结果证实了BrainGPT能够生成准确、专业的放射学报告,而FORTE评估框架也能有效衡量报告的医学价值。
语言嵌入式图灵测试
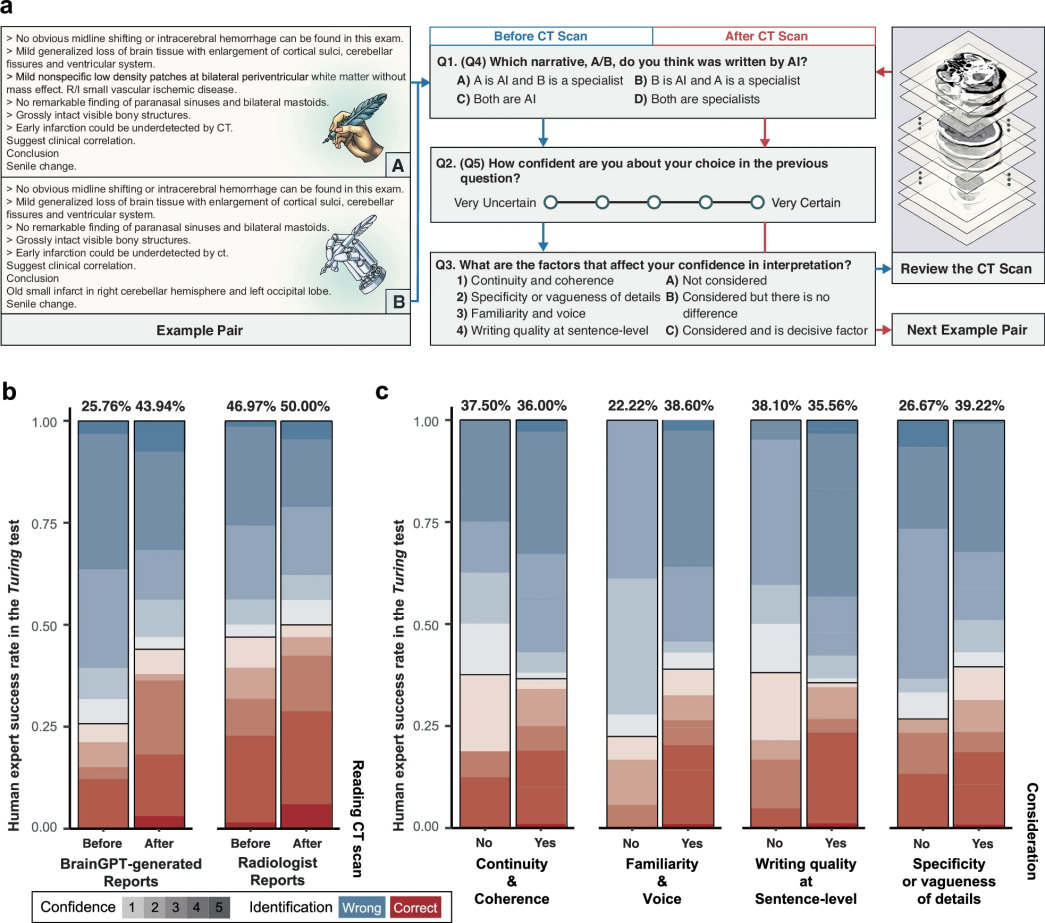
图 7
为了检验BrainGPT生成的医疗报告是否能达到以假乱真的程度,研究团队设计了一项特殊的识别测试(又称“图灵测试”)。如图7a所示,测试邀请了11位不同专业的医生参与,包括放射科、神经科和其他科室的专家,让他们判断6份脑部CT扫描报告是由人工撰写还是机器生成的。
测试结果令人惊讶。如图7b显示,在66次评估中,超过四分之三的机器生成报告被误认为是医生手写的。有趣的是,当评估者同时查看CT影像时,这种误判现象有所减少,但仍有56%的机器生成报告被误认为是人工撰写的。这说明查看实际影像确实有助于医生发现机器生成报告中的细微问题,比如描述不够准确或偏离重点等。
研究团队还深入分析了影响医生判断的关键因素。如图7c所示,主要包括四个方面:报告的语气是否自然(影响29%的判断),描述细节的精确程度(影响37.60%的判断),内容的连贯性(影响33.33%的判断),以及句子表达的质量(影响33.33%的判断)。数据显示,当医生特别关注报告的语气特征时,识别出机器生成报告的准确率从22.22%提升到38.6%;当重点关注细节描述时,准确率则从26.67%提升到39.22%。这些发现为改进AI医疗报告生成系统提供了重要参考。这项研究全面展示了如何处理3D CT影像数据集、优化放射报告生成模型(BrainGPT),以及建立合理的医学评估标准(FORTE)的完整过程。
讨论
这项研究开创性地提出了一个用于生成3D脑部CT扫描报告的AI系统框架。研究团队通过临床知识优化、特殊的文本处理技术和多层次的评估方法,使BrainGPT能够生成高质量的医疗报告。与现有技术相比,该系统仅需12小时训练时间,且采用开源框架,大大提高了实用性。尽管研究在训练数据的多样性等方面还有待改进,但为AI辅助医疗诊断开辟了新的方向。
编译|于洲
审稿|王梓旭
参考资料
Li, CY., Chang, KJ., Yang, CF. et al. Towards a holistic framework for multimodal LLM in 3D brain CT radiology report generation. Nat Commun 16, 2258(2025).
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢