
DRUGAI
过渡金属催化的不对称反应在有机合成中具有重要意义。近年来,机器学习在加速新型催化反应开发方面展现出潜力,但对大量实验数据的依赖成为限制因素。研究人员提出了一种基于元学习的工作流程,利用文献数据提取反应共有特征,仅需少量样本即可预测新反应结果。该方法采用原型网络对烯烃的不对称加氢反应的对映选择性进行预测,并在多个数据规模下均优于随机森林和图神经网络等常规模型。在外部测试集中也表现出良好的泛化能力,展示了其在反应早期开发阶段数据稀缺情境下的广泛适用性。

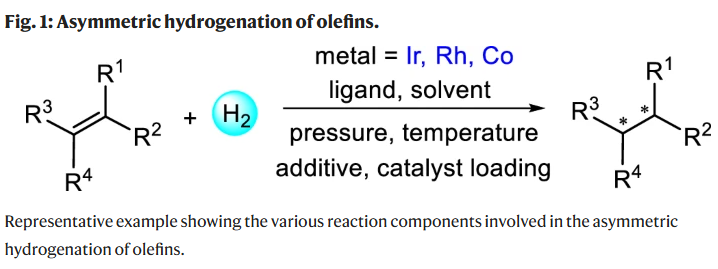
手性化合物在医药和材料等领域的广泛需求推动了不对称催化的发展。过渡金属催化的烯烃不对称加氢(AHO)是一种高效获取高纯度手性分子的关键方法,因其选择性高、原子经济性强而备受关注。这促使研究人员不断设计新型金属催化剂和手性配体,以实现更广泛底物的高对映选择性加氢。然而,对于未官能化或四取代烯烃的加氢仍面临挑战,传统催化剂设计方法往往耗时费力,因此亟需借助数据驱动方法简化反应开发流程。
近年来,机器学习在化学空间探索中迅速发展,广泛应用于预测分子性质及反应结果,如产率、区域选择性和立体选择性等。无监督学习方法也被用于可视化反应性模式,辅助催化剂设计和底物筛选。贝叶斯优化等策略也被引入用于反应条件优化。
机器学习模型的预测性能高度依赖于训练数据,这些数据通常来源于文献或高通量实验(HTE)。尽管HTE数据质量高、标准化良好,但公开数据种类有限;相比之下,文献数据覆盖面广但质量参差不齐,反应类型多样但底物组合变化较少。因此,亟需构建能从文献数据中提取知识并在样本有限情况下实现准确预测的模型。元学习作为一种“学会学习”的策略,近年来在低数据学习场景中逐渐受到关注。
元学习通过在多个相关任务中训练模型以提取共享知识,并在遇到新任务时快速适应。尽管该方法起初主要应用于计算机视觉,近年来也逐步扩展至药物发现领域,在低数据条件下提升分子性质预测与优化能力。同时,也有研究将其用于高通量实验数据上的反应产率预测。
尽管机器学习模型在高通量数据集上表现良好,但面对文献数据的稀疏性和多样性,反应预测仍具挑战。为此,研究人员设计了一种元学习模型,用于提升基于文献数据的预测能力。该方法以过渡金属催化的烯烃不对称加氢反应为例,验证了模型在小样本条件下的良好泛化性能。所提出的方法适用于各类反应任务,尤其在反应开发初期数据有限时,可实现快速有效的预测。
结果
数据集构建
研究人员引用了Hong课题组建立的一个包含近12,000条过渡金属催化烯烃不对称加氢(AHO)反应的文献数据集。每条反应记录包含底物、金属、配体、产物、溶剂、添加剂、压力、温度和催化剂用量等信息。数据中,约90%的反应使用铱或铑催化剂,钴催化反应仅占1%。研究人员补充了近年报道的钴催化反应数据,最终获得11,932条AHO反应数据,其中包括Ir催化反应5009条、Rh为6391条、Co为532条。
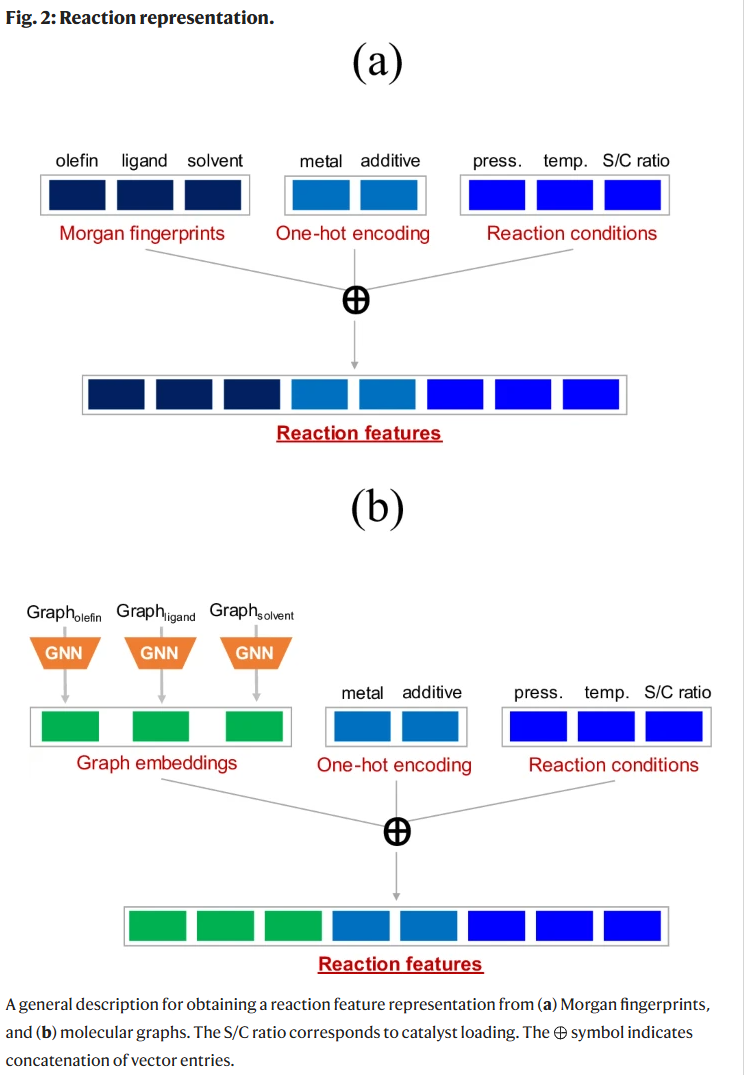
特征表示
为表示反应特征,采用两种方式:其一是基于Morgan指纹,将底物、配体、溶剂的512位指纹(radius 2)与金属种类、添加剂有无的独热编码及反应条件(温度、压力、催化剂用量)拼接,形成1544维特征向量;其二是将分子图输入图神经网络(GNN)提取64维节点特征,通过Set2Set全局池化形成512维图嵌入,同样结合其他信息拼接为1544维输入。
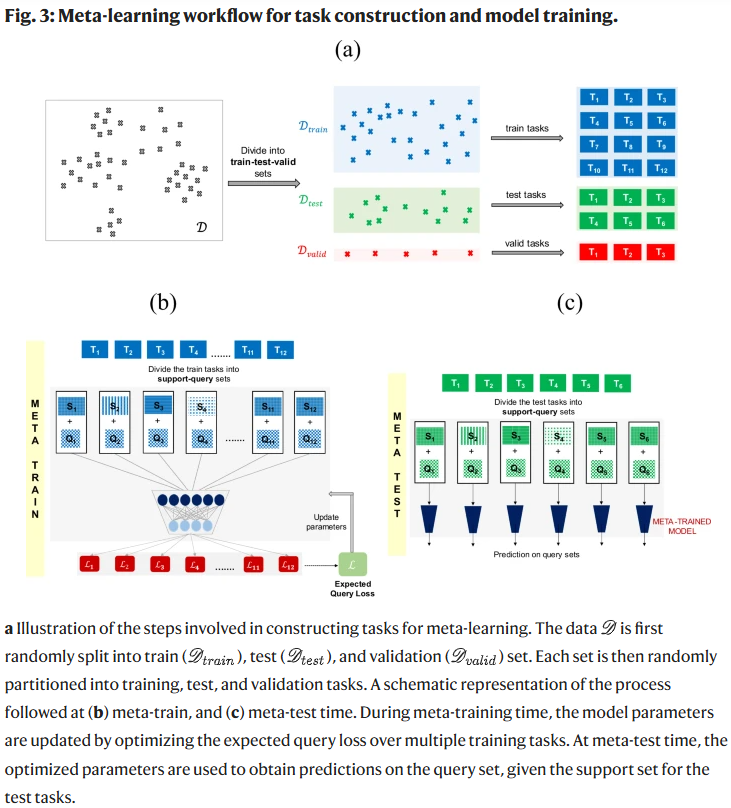
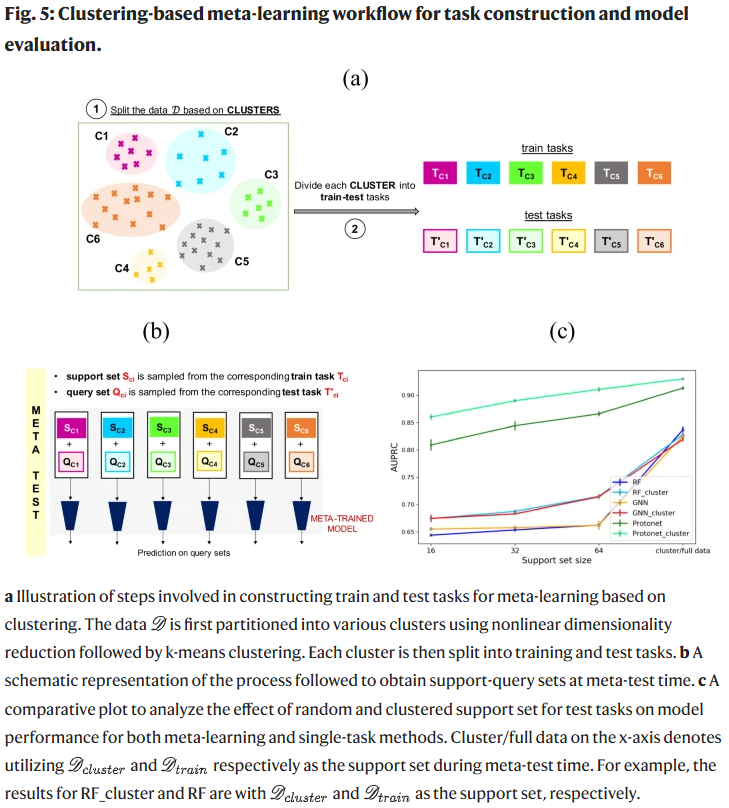
数据集划分与任务构建
数据集被随机划分为训练集(9032条)、验证集(500条)和测试集(2400条)。在元学习框架中,每个训练任务被划分为支持集和查询集,模型先在支持集学习,再在查询集评估。测试时,使用支持集大小为16、32和64的设置,以探讨模型在小样本条件下的表现。
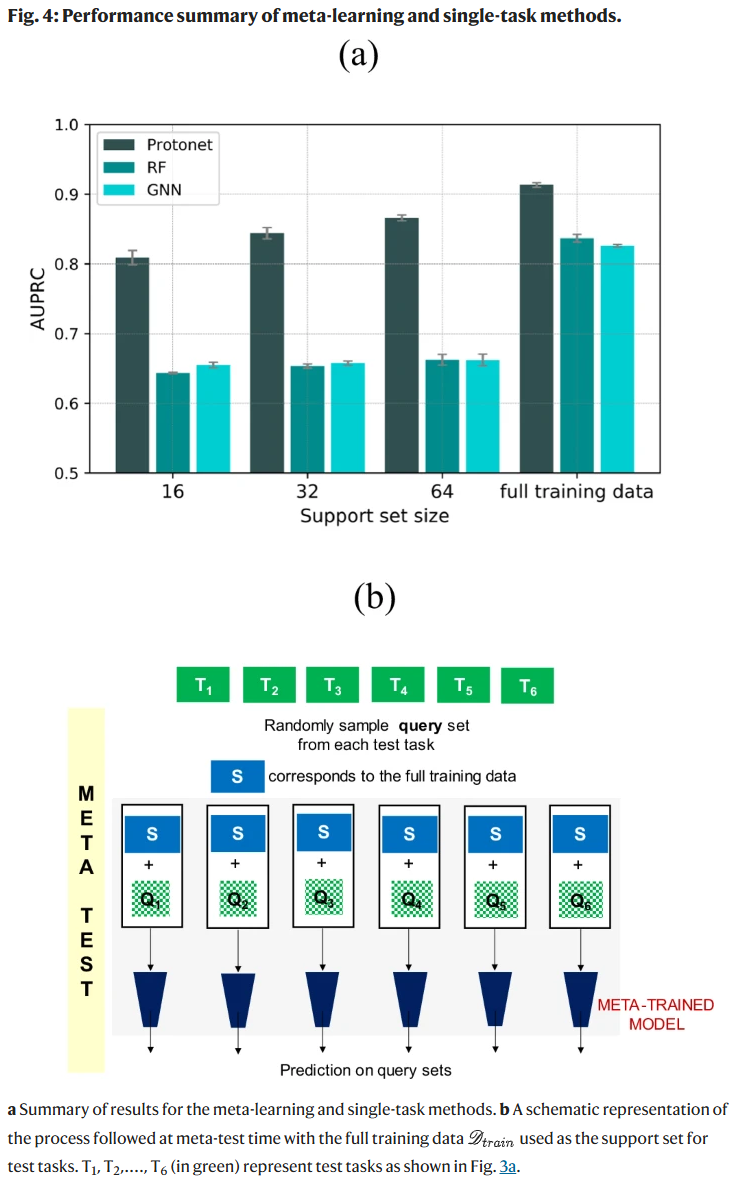
模型训练与性能评估
将反应对映选择性(%ee)划分为两类:大于80%和小于等于80%。采用AUPRC和AUROC评估模型分类性能。实验表明,原型网络(Protonet)在所有支持集大小下均显著优于随机森林(RF)和图神经网络(GNN)。即便仅使用32个支持样本,Protonet的性能也可媲美使用完整训练数据训练的单任务模型。进一步,若使用整个训练集作为测试任务的支持集,Protonet达到最佳性能(AUPRC=0.9133)。
基于聚类的任务构建策略
为优化任务构建方式,引入了“meta-cluster”策略。通过UMAP降维后对1544维反应指纹聚类,使用K-means将数据划分为10个簇,每个簇构成一组训练或测试任务。测试时,从同一簇中选取训练数据作为支持集,测试数据作为查询集。该策略在所有支持集大小下均提升模型性能,Protonet_cluster在64个支持样本下AUPRC达0.9300,优于标准元学习方法。
聚类稳健性验证
为验证聚类策略的稳健性,分别考察了不同支持集采样过程和不同聚类数量(10/15/20)的影响。结果显示,Protonet_cluster在不同设定下均表现稳定,AUPRC波动范围极小,说明该方法对聚类方法和簇数量不敏感,具有良好泛化能力。
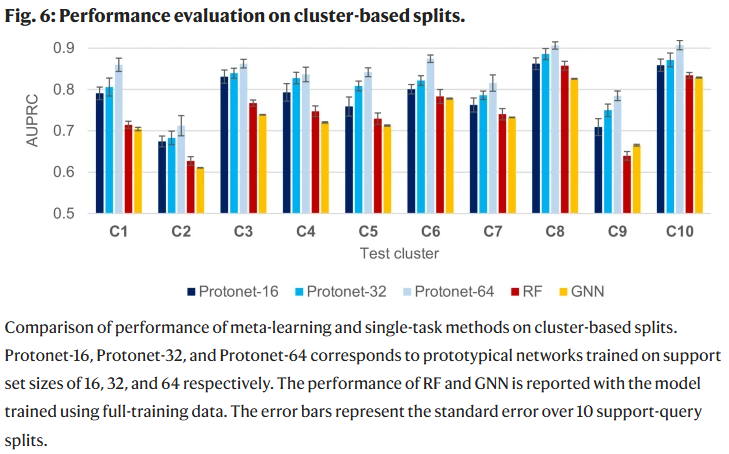
更具挑战性的评估:留一簇验证
最后,研究人员评估了更具挑战性的“留一簇”验证方式。将10个簇中任意一个作为测试任务,其余用于训练,分别重复10次。即便在这种设置下,Protonet依旧在所有簇上优于单任务模型。支持集样本越多,模型性能越高,大多数簇的AUPRC高于0.80,部分如C8、C10甚至接近0.90。
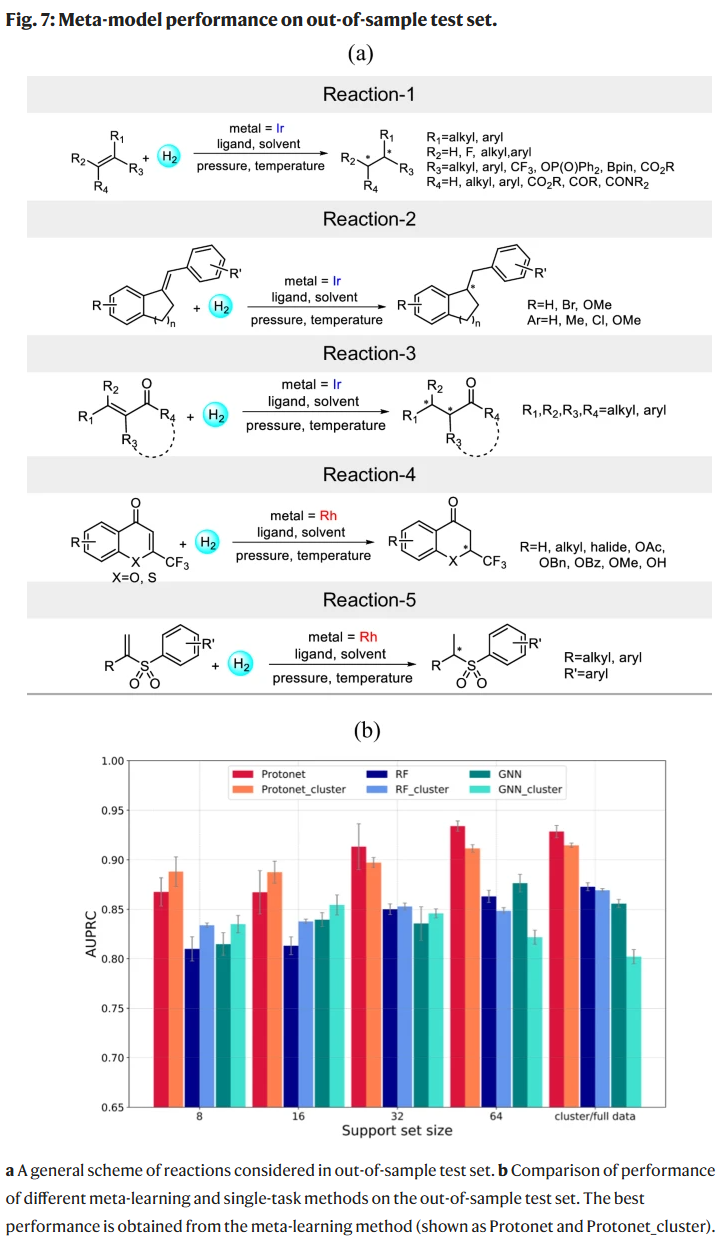
模型在样本外测试集中的表现
为进一步评估元模型的泛化能力,研究人员从近期文献中额外提取了245条不包含在原始训练数据中的Ir和Rh催化AHO反应。这些反应中部分底物或配体与训练数据相似,但反应整体(即底物、配体和条件的组合)是全新的。选取的反应具有广泛的应用潜力,包括二、三、四取代烯烃的不对称加氢反应,以及一些具有药物开发意义的结构单元,如含氟色原酮和砜类化合物。
在标准方法中,训练集包含全部11,932条AHO反应,测试集为上述新提取的样本外数据。研究人员采用前文描述的两种任务构建策略,首先是将训练与测试数据随机划分为多个任务,分别进行支持集和查询集的训练与预测。设置四种支持集大小(8、16、32、64),查询集固定为128。结果表明,原型网络(Protonet)的表现显著优于随机森林(RF)和图神经网络(GNN)。在支持集为64的情况下,Protonet的AUPRC为0.9341,高于RF(0.8631)和GNN(0.8764)。由于测试数据中反应类型相近,支持集与查询集具有较高的内部相似性,这对Protonet的性能有积极影响。
在另一种meta-cluster方法中,支持集不再来自测试任务自身,而是选自与其特征相似的训练任务,无需为新反应额外进行实验。模型与数据保持不变,仅改变支持集的构建方式。结果显示,Protonet_cluster获得了AUPRC为0.9147,优于RF_cluster(0.8692)和GNN_cluster(0.8021)。在不同支持集大小下,Protonet和Protonet_cluster表现相当,仅在支持集为64时,Protonet略优。meta-cluster策略尤其适用于前期实验难以开展的情境。
整理 | WJM
参考资料
Singh, S., Hernández-Lobato, J.M. A meta-learning approach for selectivity prediction in asymmetric catalysis. Nat Commun 16, 3599 (2025).
https://doi.org/10.1038/s41467-025-58854-8
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢