

速览热门论文
1. 超越Transformers,谷歌发布「深度学习架构设计」通用框架 Miras
2. 奖励,就是工具学习所需要的一切
3. 浙大、vivo 团队:借助人类演示增强移动 GUI Agent
4. 思维操纵:外部 CoT 可加速大模型推理
1. 超越 Transformers,谷歌发布「深度学习架构设计」通用框架 Miras
设计高效和有效的架构骨干,一直是增强基础模型能力的核心研究方向。受注意力偏差这一人类认知现象的启发——优先考虑某些事件或刺激的自然倾向—— Google Research 团队将神经架构(包括 Transformers、Titans 和现代线性递归神经网络)重新概念化为关联记忆模块,通过内部目标(即注意力偏差)学习键值映射。
令人惊讶的是,他们发现,大多数现有序列模型都利用点积相似性或 L2 回归目标作为其注意力偏差。他们还提出了一系列可供选择的注意力偏差配置及其高效的近似方式,以稳定训练过程并提升模型表现。然后,他们将现代深度学习架构中的遗忘机制重新解释为保留正则化的一种形式,为序列模型提供了一套新的遗忘门。
基于这些见解,他们提出了一个深度学习架构设计通用框架 Miras,基于以下 4 种选择:(1)联想记忆架构;(2)注意力偏差目标;(3)保持门;(4)记忆学习算法。他们进一步提出了三种新颖的序列模型——Moneta、Yaad 和 Memora,它们不仅超越了现有线性 RNN 的性能,同时也保持了训练过程的高效并行性。
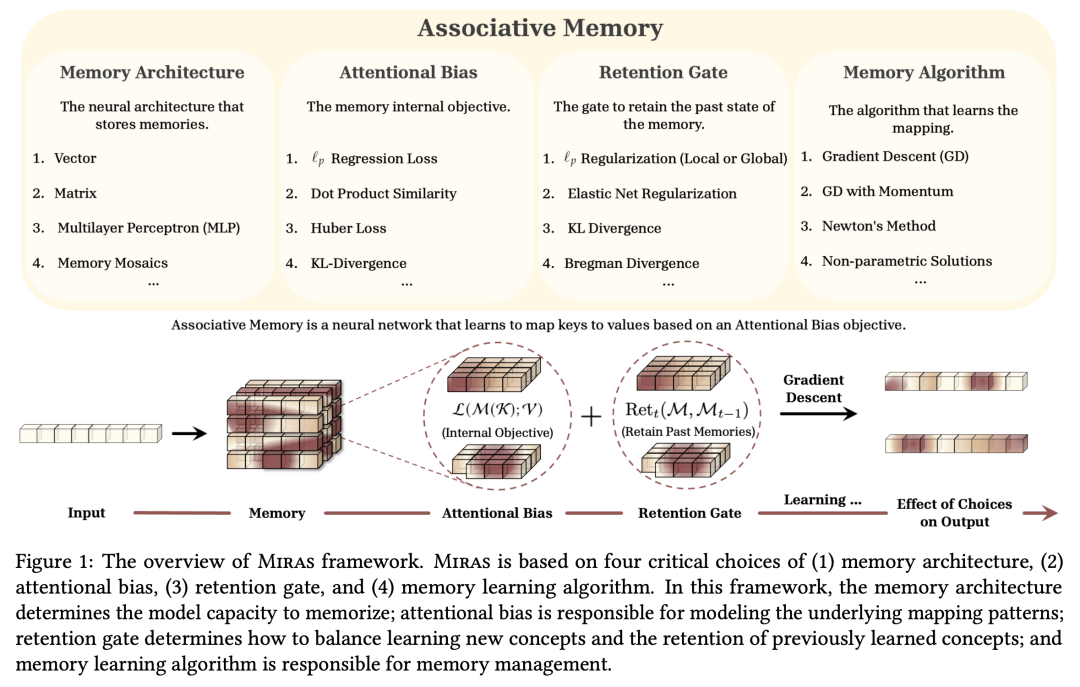
实验表明,Miras 的不同设计选择会产生不同强度的模型。例如,Miras 的某些实例在语言建模、常识推理和需要高密度信息召回的任务中展现出了优异的性能,甚至超过了 Transformers 和其他现代线性循环模型。
论文链接:https://arxiv.org/abs/2504.13173
2. 奖励,就是工具学习所需要的一切
当前的大语言模型(LLM)通常通过监督微调(SFT)来获得工具使用能力。然而,SFT 在面对陌生或复杂的工具使用场景时,往往难以实现良好的泛化。近年来,强化学习(RL)取得了进展,尤其是类似 R1 的模型,已经展现出良好的推理能力和泛化能力。但在工具使用任务中,奖励设计仍面临诸多挑战:一方面,工具种类繁多,调用时参数各异;另一方面,粗粒度的奖励信号难以提供有效学习所需的细粒度反馈。
在这项工作中,伊利诺伊大学香槟分校团队首次在 RL 范式中对工具选择和应用任务的奖励设计进行了全面研究。他们系统地探索了各种奖励策略,分析了它们的类型、规模、粒度和时间动态。基于这些见解,他们提出了针对工具使用任务的原则性奖励设计,并将其应用于使用群体相对策略优化(GRPO)训练 LLM。
对不同基准的实证评估表明,这一方法能够产生鲁棒、可扩展和稳定的训练效果,相较基础模型性能提升了 17%,相较 SFT 模型提升了 15%。这些结果凸显了合理的奖励设计在提高 LLM 的工具使用能力和泛化性能方面的关键作用。
论文链接:https://arxiv.org/abs/2504.13958
3. 浙大、vivo 团队:借助人类演示增强移动 GUI Agent
移动 GUI Agent 在自动执行任务方面展现出巨大潜力,但在应对现实世界中多样化的场景时,仍面临通用性不足的挑战。传统方法往往依赖预训练模型或大规模数据集进行微调,然而在面对多样化的移动应用和用户特定任务时,往往难以奏效。
来自浙江大学和 vivo 的研究团队提出了一种新思路:通过引入人类演示来增强移动 GUI Agent 的能力,重点在于提升其在未见场景中的表现,而非一味依赖更大规模的数据集来追求泛化能力。为了实现这一范式,他们提出了 LearnGUI,这是第一个专门用于研究移动 GUI Agent 中 基于演示的学习的综合数据集,包括 2252 个离线任务和 101 个带有高质量人类演示的在线任务。他们进一步开发了多 agent 框架 LearnAct,其能够自动从演示中提取知识,从而提高任务完成度,集成了三个专业 agent:用于知识提取的 DemoParser、用于相关知识检索的 KnowSeeker 和用于演示增强任务执行的 ActExecutor。
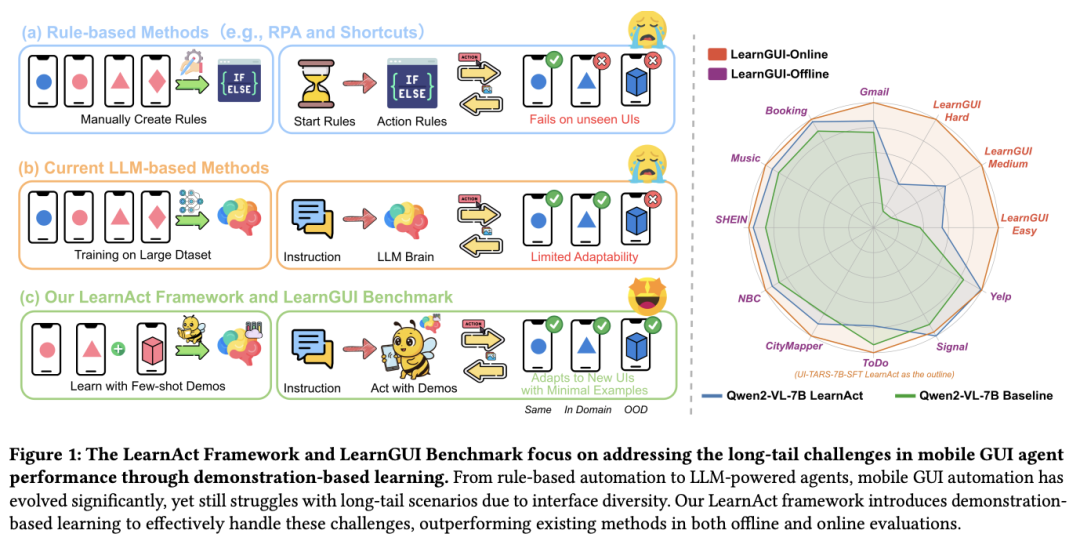
实验结果表明,在离线和在线评估中,模型性能都有显著提高。在离线评估中,一次演示就能提高模型性能,将 Gemini-1.5-Pro 的准确率从 19.3% 提高到 51.7%。在在线评估中,这一框架将 UI-TARS-7B-SFT 的任务成功率从 18.1% 提高到 32.8%。LearnAct 框架和 LearnGUI 基准确立了以演示为基础的学习方法,这是使移动 GUI Agent 更具适应性、个性化和可部署性的一个有前途的方向。
论文链接:https://arxiv.org/abs/2504.13805
4. 思维操纵:外部 CoT 可加速大模型推理
扩展测试时计算可以有效增强大型推理模型(LRM)在多种任务中的推理能力。然而,LRM 通常存在“过度思考”问题,即模型会产生大量冗余推理步骤,但带来的性能提升却十分有限。现有的工作依赖于微调来缓解过度思考,但这不仅需要额外数据和非常规训练流程,还可能带来安全风险和较差的泛化能力。
通过实证分析,来自香港科技大学和蚂蚁集团的研究团队揭示了 LRM 行为的一个重要特征,即在思考 token 之间插入由较小模型生成的外部思维链(CoT),可以有效地操纵模型产生更少的思维。基于这些见解,他们提出了一个简单而高效的管道——ThoughtMani,使 LRM 能够绕过冗余的中间步骤,降低计算成本。
他们在多个任务上进行了大量实验,验证了 ThoughtMani 的实用性与高效性。例如,当应用于 LiveBench/Code 数据集上的 QwQ-32B 时,ThoughtMani 保持了原有性能,并将输出 token 数减少了约 30%,而 CoT 生成器的开销却很小。此外,他们还发现 ThoughtMani 平均提高了 10% 的安全对齐度。
由于模型供应商通常会同时提供不同大小的模型,ThoughtMani 为构建更高效、可访问性更强的 LRM 系统提供了现实可行的解决方案。
论文链接:https://arxiv.org/abs/2504.13626
整理:学术君
如需转载或投稿,请直接在公众号内留言

内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢