
在大模型掀起互联网各行业变革的时代,搜索广告能否借助大模型的东风,为广告营收与消费者购物体验带来持续增量?本文介绍阿里妈妈搜索广告相关性团队在相关性大模型建设、大模型赋能在线模型以保障淘宝消费者体验的前沿研究工作。
▐ 概述
在电商搜索系统中,精准的搜索结果相关性建模对于提升用户体验和保障用户满意度具有重要意义。近期,基于大语言模型(LLM)的相关性建模方法展现了强大的性能和长尾场景的泛化能力,相较于传统神经网络方法具有显著优势。然而,LLM相关性建模方法在实际应用中仍面临两大挑战:其一,模型参数量庞大且计算需求高,难以直接应用于线上环境;其二,尽管模型蒸馏是可行方向,LLM的相关性建模本质上是一个黑箱过程,其中蕴含的丰富知识难以被有效提取和应用。针对这些挑战,我们提出了一个思维链可解释LLM驱动的多维知识蒸馏架构,以充分挖掘大模型知识,提升电商相关性建模效果。该框架包含两大核心组件:其一,可解释相关性大模型(ELLM-rele),从电商相关性业务视角出发,通过将相关性建模分解为多个中间步骤,采用思维链推理(Chain-of-Thought, CoT)的方式重构相关性任务,从而在提升模型可解释性的同时,提高大模型判别准度;其二,大模型多维知识蒸馏架构(MKD),从大模型概率分布和思维链推理知识两个维度,将ELLM-rele中的丰富知识迁移到在线部署的相关性模型中,提升在线模型相关性建模能力。实验表明,我们提出的大模型多维蒸馏方法大幅提升了学生相关性模型的语义交互能力和长尾场景泛化能力,在保障消费者购物体验方面均取得了显著效果。
基于该项工作整理的论文已被顶级会议WWW'25高分录用,欢迎阅读交流。
论文:Explainable LLM-driven Multi-dimensional Distillation for E-Commerce Relevance Learning
作者:Gang Zhao, Ximing Zhang, Chenji Lu, Hui Zhao, Tianshu Wu, Pengjie Wang, Jian Xu, Bo Zheng
论文地址:https://arxiv.org/abs/2411.13045
1.引言
在电商平台中,搜索引擎作为连接用户与商品的关键媒介,其服务质量直接影响平台用户体验。在此背景下,准确判断搜索词与商品之间的语义相关性,过滤不匹配商品,成为提升用户体验和保障用户长期满意度的重要技术基础,语义相关性建模技术也因此持续受到学术界和工业界的广泛关注。
主流的相关性建模方法可分为两个技术流派:表征式建模和交互式建模范式。前者专注于为搜索词和商品生成高质量语义表征,通过相似度计算或轻量级后交互模块实现相关性判断。得益于其可预先缓存商品表征的特性,该方法在在线场景中得到广泛应用,但其弱交互特性导致模型性能受限,特别在长尾样本场景中表现尤为明显。后者通过在语义编码阶段引入查询-商品交互机制或构建复杂交互模块,展现出更强判别能力,但高计算复杂度使其难以应用于在线系统。这两类方法本质上是针对不同应用场景在性能与效率之间的权衡,但在大模型时代均有提升空间。
近期,大语言模型(LLM)凭借其海量先验知识储备,在相关性建模任务中展现出突破性性能。具体而言,我们首先基于7B的Qwen大模型,通过直接对搜索Query和AD生成相关性判断结果,不仅刷新了判别准度纪录,更显著提升了长尾样本的泛化能力。然而,电商平台的巨量客流和服务延迟限制使得大模型直接部署面临严峻挑战。现有研究表明,通过知识蒸馏将大模型能力迁移至小模型是可行思路,但现有大模型异构蒸馏方法大多停留在数剧增强层面,而忽略了大模型内在知识的价值。针对相关性判断任务,其决策过程天然具备高度可解释性——例如可将整体相关性判别解构为品类匹配、品牌识别、型号匹配等多个子维度的判断过程。因此,我们可以将相关性判别重构为推理任务,通过大模型的思维链推理能力显式捕获这些路径,既能靠推理过程进一步提升大模型判别准度,又可以增强可解释性,产出中间推理知识供在线相关性模型深入挖掘,这为创新性解决方案提供了可能。
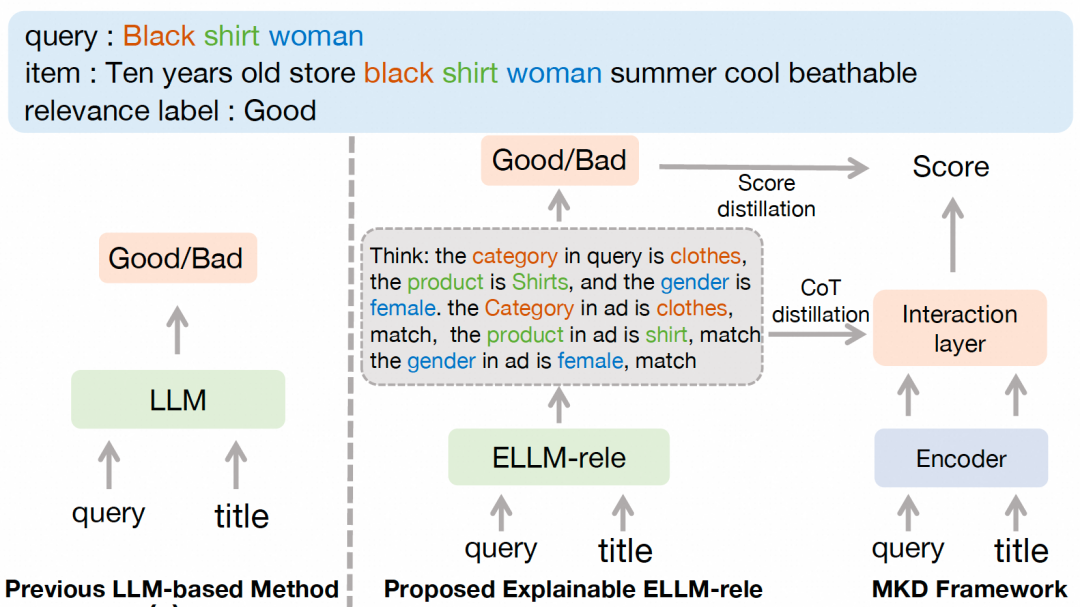
基于上述洞察,我们首次提出了一种面向电商相关性建模的可解释相关性大模型,及大模型多维知识蒸馏框架,主要包含两大核心组件:其一,可解释相关性大模型(ELLM-rele)通过将相关性判别任务重构为子维度思维链推理任务,提升大模型的判别准度与决策透明性。具体而言,我们根据电商场景实际需求将相关性评估标准分解为多个细粒度层面,捕获各个子维度下相关性证据,并通过人工标注构建思维链案例样本对LLM进行监督微调,使其具备稳定的多维度推理能力。其二,大模型多维知识蒸馏框架,通过概率分布蒸馏与思维链知识注入的双重机制,将大模型知识有效迁移至在线相关性模型。在概率分布维度,我们提取大模型判别Token在词表空间中的概率并转化为相关性打分知识;在思维链维度,解析推理路径中Query和AD的关键语义单元和细粒度相关性知识,并通过序列标注和注意力分数调节的蒸馏任务,将细粒度相关性判别知识注入到现有交互式和表征式学生模型中,提升模型深度语义交互能力。
2.核心方法
2.1 相关性任务的思维链推理建模

在电商相关性学习任务中,我们旨在通过分析用户查询Query与AD商品标题之间的语义关联,获取一个能够反映两者相关性的语义分数,从而判断该Query-AD对属于“相关”或“不相关”的情况。为了提升基于大语言模型的相关性建模方法的可解释性和准度,我们将原本的文本分类任务转化为思维链(CoT)推理过程。具体而言,基于电商场景的业务属性,我们将相关性判别标准分解为多个细粒度的维度,例如商品类别、品牌、型号、款式等。通过将这些维度的匹配结果进行综合判断,最终得出整体的相关性结论。如果任意一个维度不匹配,例如品牌不匹配,我们就可以得到一个细粒度的结果,例如“不相关-品牌不符”。只有当所有维度均匹配时,最终的判断结果才会是“相关”。基于这一思路,给定一个Query-AD对,我们可以根据下述步骤为其构建一个显式思维链推理过程:Step1,提取Query中涉及的各个子相关性维度,及各自的相关性证据;Step2,从AD标题中提取相应维度下的相关性证据并判定子维度下的相关性匹配结果;Step3,最后汇总各维度下的相关性匹配结果,得出最终整体“相关”或“不相关”的结论。详细思维链建模过程如图2所示。这种设计不仅使电商相关性学习任务能够以可解释的思维链推理形式进行建模,还提供了额外的细粒度知识,为后续的多维知识蒸馏奠定了基础。
2.2 可解释相关性大模型ELLM-rele
我们提出的相关性大模型ELLM-rele构建过程可分为两个阶段:高质量思维链标注生成与模型监督微调。
首先,针对现有标注数据集构建高质量思维链标注。在实际业务场景中,我们面临着日均千万级的大模型数据推理请求,由于算力资源限制我们只能采用轻量化的7B参数级大模型,然而这类模型的思维链推理能力难以满足相关性判别任务需求。为解决这一矛盾,我们创新性地引入异构大模型协同标注策略:选取Qwen2-72B与LLama3-70B两种高性能大模型,通过提示工程充分发挥其上下文学习能力生成多样化的思维链标注。具体地,针对数据集中的每个搜索对(包含Query、AD标题及人工标签),我们精心设计包含任务指令与示例样本的上下文提示模板。为确保标注质量,特别采用自洽性采样策略——分别从两个大模型各采集5条推理路径,形成包含10条候选路径的标注池。最终通过结果对齐筛选,保留与人工标签一致的优质思维链,构建出包含思维链推理过程的大模型监督微调数据。这种双模型协同机制有效避免了单一模型可能产生的标注偏差,为后续训练奠定坚实基础。
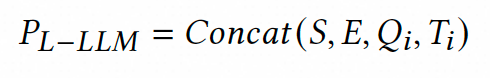
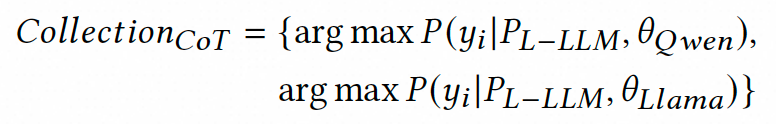
随后,基于超大模型的思维链标注对7B级大模型进行监督微调。由于7B级模型的思维链推理能力有限,我们通过思维链标注数据将Qwen2-72B和LLama3-70B超大模型的推理能力注入Qwen2-7B模型。具体训练过程中,输入提示仅保留任务指令与Query-AD搜索对的核心信息,移除上下文示例以平衡准度与推理效率。通过优化负对数似然损失函数,强制模型学习从搜索对到完整思维链的映射关系。实验表明,上述设计能够在保证大模型准度的同时,降低推理延迟,以满足业务要求。
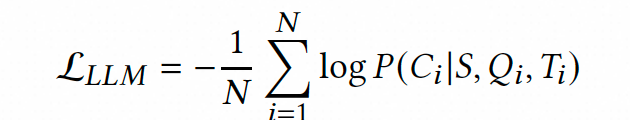
2.3 大模型驱动的多维知识蒸馏
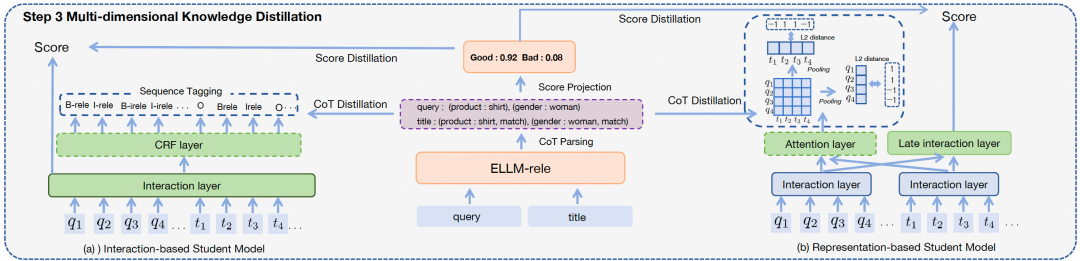
在获得具有思维链推理能力的大模型ELLM-rele后,我们通过相关性分数分布蒸馏和思维链推理知识蒸馏,深入挖掘大模型知识,赋能在线相关性模型。
相关性分数分布蒸馏
通过监督微调,ELLM-rele能够学习相关性推理的输出模板,并在推理序列的末尾生成“相关”或“不相关”的相关性判断结果(相关性判别Token)。考虑到判别Token的概率分布中包含细粒度的相关性程度信息,我们将这些概率转化为相关性得分,用以指导学生模型的训练,以缩小与教师模型之间的差距。
在数据采样与伪标签预测阶段,为了充分挖掘教师模型的知识潜力,我们不仅采用人工标注数据,还从真实场景中采集海量未标注数据进行伪标签生成。具体而言,我们从淘宝搜索日志中抽取数千万级别的查询词-商品标题对构成数据集D,其中每个样本 经由教师模型ELLM-rele处理后,将生成包含判定标志的相关性推理序列,并输出整个词表的概率分布,该分布反映了各词汇单元作为输出的可能性。
随后,为了排除非相关词汇的干扰并提取纯粹的相关性信息,我们仅聚焦于Good和Bad两个判定标志的概率值。设 和 分别表示教师模型对这两个判定标志的预测概率,我们通过概率归一化处理将其转化为0到1之间的连续相关性评分。
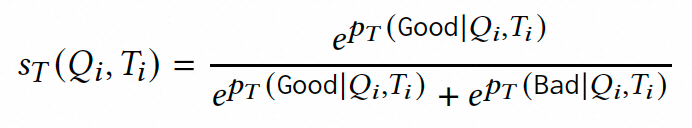
最后,我们通过通过最小化KL散度损失,使学生模型的相关性打分分布与教师模型的打分对齐。通过优化该目标函数,学生模型不仅能够继承教师模型的二值化相关性决策能力,还能深入吸收其概率分布层面的相关性程度知识,从而全面提升相关性判定的准确性。
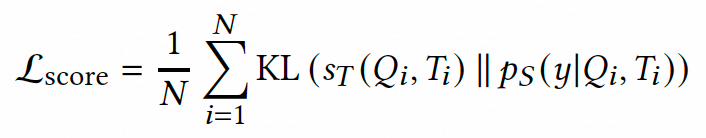
思维链知识蒸馏
为了进一步挖掘ELLM-rele的内在知识,我们在分数蒸馏的基础上,提出了思维链推理知识蒸馏。通过将相关性建模为思维链推理,ELLM-rele可以生成中间的推理步骤,阐明了导致最终“相关”或“不相关”的决策过程。这些推理步骤展示了Query与AD标题之间细粒度语义交互过程,突显了具体相关证据(例如类别、品牌等)及其对齐情况。因此,我们对CoT序列进行结构化解析,作为细粒度的字粒度监督信号,并通过辅助蒸馏任务将交互知识注入到学生模型中。考虑到适应交互式和表征式学生模型的可扩展性,我们设计了下述两种CoT蒸馏任务。
对于交互式的学生模型,我们通过在其交互后的表征上进行序列标注来注入推理知识。具体而言,我们根据CoT结构化解析结果,对Query和AD中与相关性证据对应的Token根据对齐情况进行BIO标注,在训练过程中使用条件随机场来获取CoT蒸馏损失。

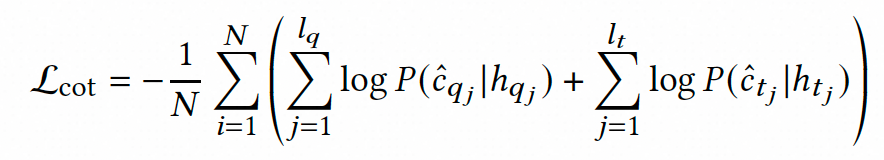
对于表征式学生模型,我们可以通过CoT序列中反映的交互知识来调节交互层注意力分数,从而让模型实现更好的语义交互。具体地,CoT推理过程包含的Query与AD标题中相关的Token,在交互过程中应获得更高的注意力分数,而无关的词应获得较低的分数。在此背景下,我们为Query和AD中的每个词构建了一个注意力调节因子,根据其相关性赋值。随后,基于这些调节因子,我们通过优化L2距离来调节学生模型的注意力分数,拉高相关Token间的注意力,降低无关Token间的注意力。

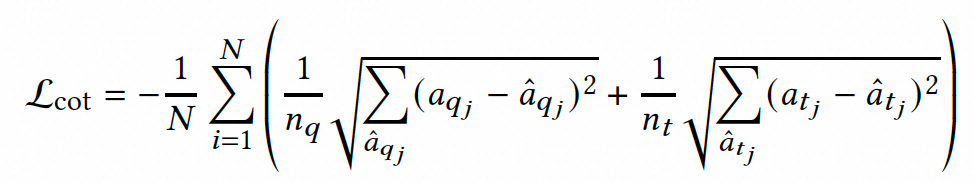
最后,在训练阶段,我们将上述知识蒸馏损失与原始交叉熵损失加权,作为最终的损失函数,使学生模型不仅能够学习到教师模型的相关性判定,还能继承其深层次的推理和概率知识,从而提升整体性能。
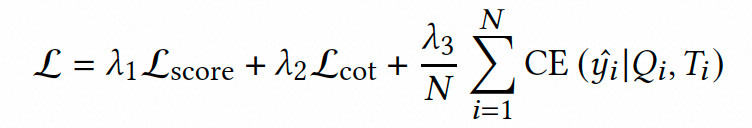
上述ELLM-rele和MKD的具体实现细节请参考论文原文。
3.实验发现
3.1 离线实验
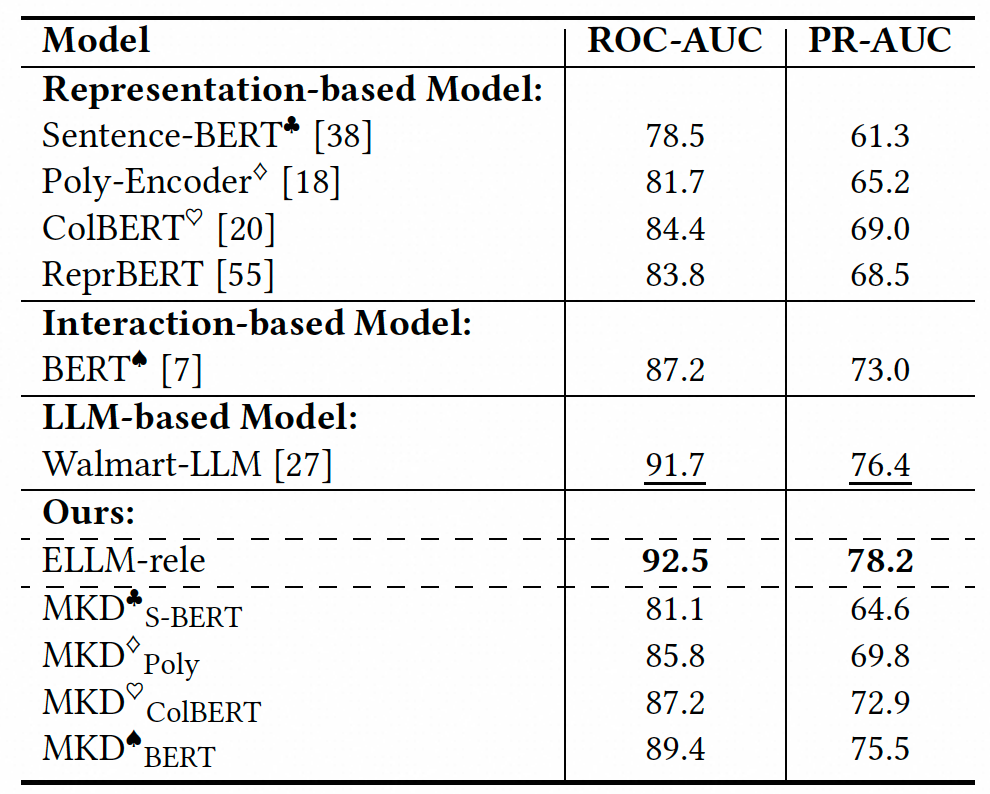
我们在搜索广告相关性人工标注测试集上,对比了ELLM-rele与黑盒式大模型、主流相关性专家模型与其各自进行大模型多维知识蒸馏后的效果差异。从表1的实验结果中我们可以获得下述观察:
1)基于大语言模型的方法表现优异,无论是ELLM-rele还是黑盒式大模型,相比传统的表征式和交互式专家模型在相关性评估任务中均能显著提升性能,表明利用大语言模型进行相关性建模能够有效利用其丰富的预训练知识,带来显著的效果增益。
2)通过将相关性建模转化为思维链推理任务,ELLM-rele相较于黑盒大语言模型在关键指标上实现了进一步突破。这种增强不仅体现在模型决策可解释性的提升,更通过细粒度语义推理过程强化了模型对复杂相关性任务的判断能力。
3)我们提出的大模型多维知识蒸馏框架MKD在学生模型上的效果显著,相比于未经蒸馏的基线模型,MKD显著提升了不同类型学生模型的相关性评估性能。此外,MKD展现出良好的泛化能力,能够在多种建模范式下实现性能提升,证明了其在多样化应用场景中的鲁棒性和有效性。
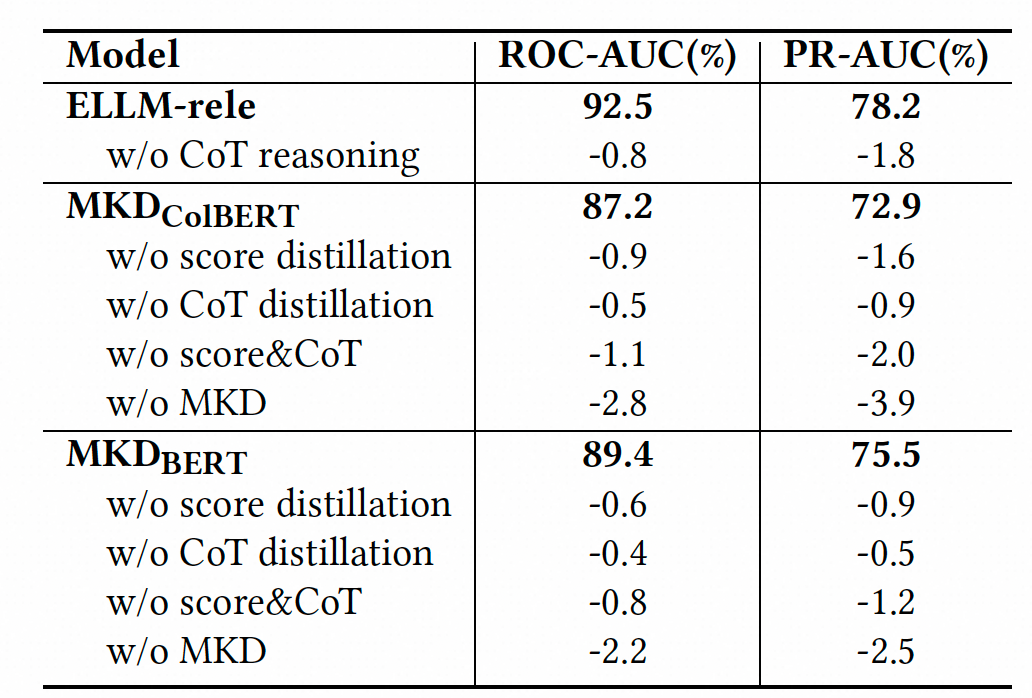
此外,为验证ELLM-MKD架构各模块的有效性,我们也开展了消融实验。从表2中我们可以观察到:为大模型引入思维链推理建模,以及为学生模型引入大模型分数分布、思维链推理知识蒸馏均对模型效果有着关键影响。
3.2 在线实验
我们将大模型多维知识蒸馏MKD集成至线上部署的在线相关性模型上开展在线A/B实验,实验结果表明,引入MKD框架可以提升用户点击率和转化率,人工评估进一步显示,搜索广告相关性关键业务指标得到了大幅提升,其中长尾样本的提升幅度尤为显著,验证了ELLM-MKD框架在提升相关性效果与用户体验方面的有效性。目前,该工作已全面服务淘宝搜索广告流量,而ELLM-rele不仅作为教师模型提供知识蒸馏支持,还被应用至相关性人工标注辅助、错误归因分析等衍生服务场景中。
更多离在线实验分析详见论文原文。
4.总结
本工作提出了基于可解释大语言模型的多维蒸馏框架,该框架在以下两个层面实现创新突破:首先,针对现有大语言模型在相关性建模中可解释性不足的问题,我们构建了可解释相关性大模型ELLM-rele,通过将相关性学习解耦为多步推理过程,将其建模为思维链驱动的推理任务;其次,为提升在线相关性模型的识别表现,设计了大模型多维知识蒸馏架构,从相关性分数分布与思维链推理两个维度,将ELLM-rele的知识迁移至基于交互式架构与表征式架构的学生模型。离线实验与在线A/B测试结果均表明,我们所提出的方法能有效提升电商相关性建模效果,显著优化消费者体验。在未来工作中,我们也会持续深耕电商相关性大模型建设与应用,探索更高效深入的知识蒸馏方式、挖掘更丰富的蒸馏知识来源。
▐ 关于我们
我们是阿里妈妈搜索广告算法团队,负责阿里最核心的营收来源,十年来通过产品和技术层面的不断自我革新升级,每年都能够保持业务高速增长,并在技术创新驱动业务成长同时,斩获包括阿里妈妈最佳团队奖、阿里妈妈总裁特别奖等多项大奖,欢迎各业务方关注与业务合作。同时,真诚欢迎具备搜广推、大模型、NLP、CV等相关背景同学加入,一起拥抱搜索广告大模型时代!感兴趣的同学欢迎投递简历加入我们。📮简历投递邮箱:irene.cyr@taobao.com

↑扫码投简历&查看岗位详情↑


喜欢要“分享”,好看要“点赞”哦ღ~
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢