

速览热门论文
1. 周伯文坐镇!清华、上海AI Lab团队提出“测试时强化学习”
2. 复旦团队推出多 agent 社会构建系统 BookWorld
3. 字节团队提出并行隐藏解码 Transformer
4. Progent:首个 LLM agent 权限控制机制
5. UC 伯克利团队推出 AI 推理框架 APR
1. 周伯文坐镇!清华、上海AI Lab团队提出“测试时强化学习”
在这项工作中,清华大学教授、上海 AI Lab 实验室主任兼首席科学家周伯文团队,针对大语言模型(LLM)中的推理任务,研究了无明确标签的强化学习(RL)。该问题的核心挑战是在推理过程中,在无法获得 ground-truth 信息的情况下进行奖励估算。虽然这种设置似乎难以实现,但我们发现,测试时扩展(TTS)中的常见做法(如多数投票)能够产生适合用于推动 RL 训练的有效奖励。
为此,他们提出了一种在无 token 数据上使用 RL 训练 LLM 的新方法——测试时强化学习(TTRL),其利用预训练模型中的先验,实现了 LLM 的自我进化。
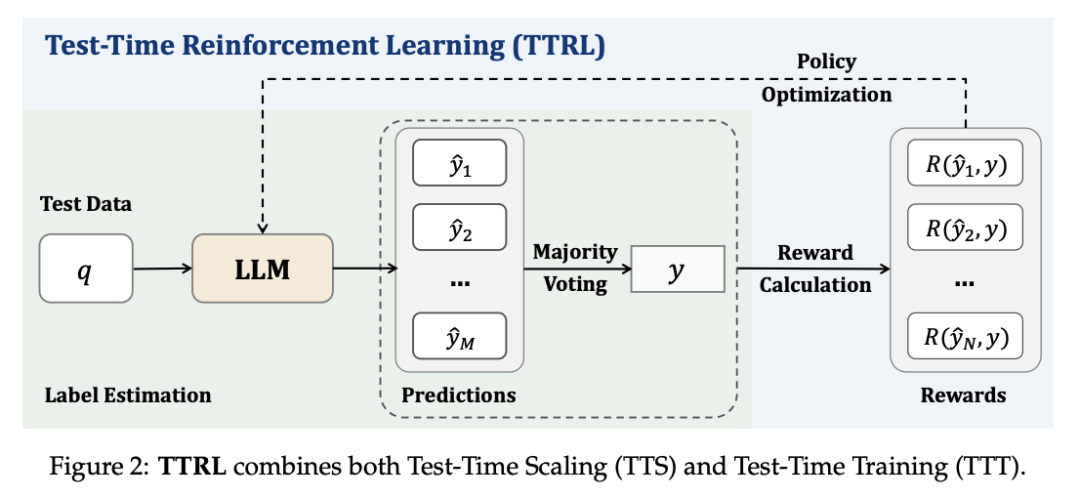
实验证明,TTRL 可以持续提高各种任务和模型的性能。值得注意的是,TTRL 将 Qwen-2.5-Math-7B 在 AIME 2024(仅使用未标记测试数据)上的 pass@1 性能提高了约 159%。此外,尽管 TTRL 只受 Maj@N 指标的监督,但表现出的性能一直超过初始模型的上限,并接近直接在带有 ground-truth 标签的测试数据上训练的模型的性能。实验结果验证了 TTRL 在各种任务中的普遍有效性,并凸显了 TTRL 在更广泛的任务和领域中的潜力。
论文链接:https://arxiv.org/abs/2504.16084
2. 复旦团队推出多 agent 社会构建系统 BookWorld
大语言模型(LLM)的通用能力,使得通过多 agent 系统进行社会模拟成为可能。之前的研究主要集中在从零开始创建的 agent 社会,为 agent 分配新定义的角色。然而,尽管模拟已有的虚构世界和角色具有重要的实用价值,但在很大程度上仍未得到充分探索。
在这项工作中,复旦阳德青副教授团队推出了一个用于构建和模拟基于书籍的多 agent 社会的综合系统——BookWorld,其涵盖了现实世界中的各种复杂情况,包括多样化的动态角色、虚构的世界观、地理限制和变化等,可以实现故事生成、互动游戏和社会模拟等多种应用,为扩展和探索虚构作品提供了新的途径。
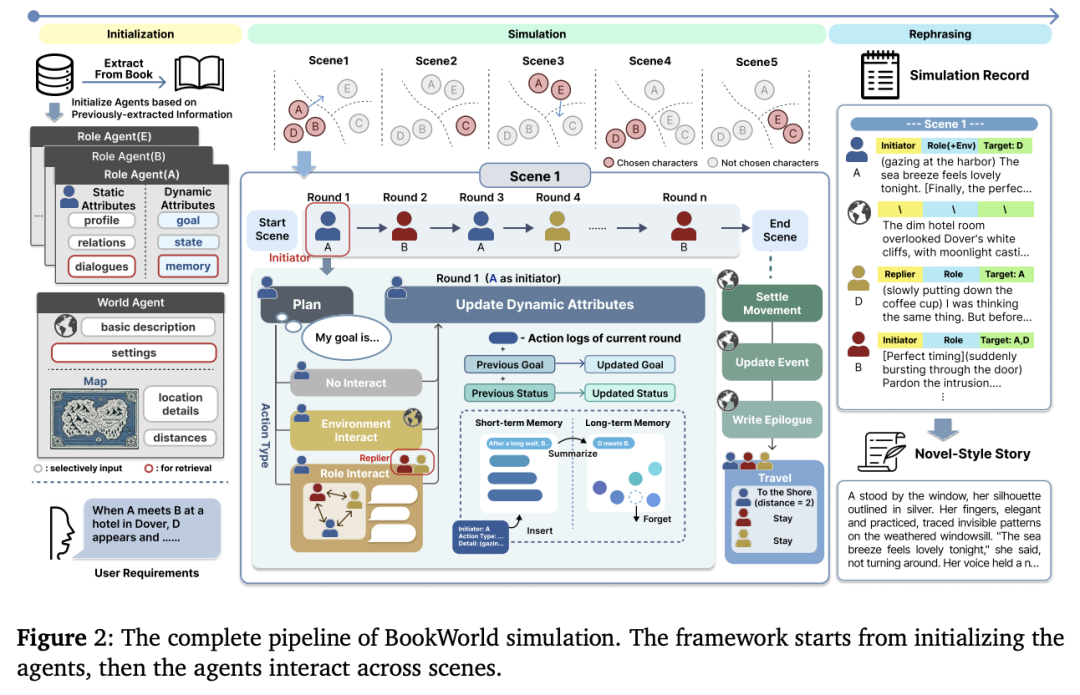
大量实验证明,BookWorld 在保持忠实于原书籍的同时,还能生成富有创意的高质量故事,其胜率高达 75.36%,超过了以往方法。
论文链接:https://arxiv.org/abs/2504.14538
3. 字节团队提出并行隐藏解码 Transformer
大语言模型(LLM)的近期进展证明了(输入序列)长度 scaling 在后训练中的有效性,但其在预训练中的潜力仍未得到充分挖掘。
在这项工作中,字节跳动团队提出了并行隐藏解码 Transformer(PHD-Transformer)框架,其可以在保持推理效率的同时,在预训练期间实现高效的长度 scaling。PHD-Transformer 通过 KV 缓存管理策略实现了这一目标,该策略可以区分原始 token 和隐藏解码 token。这一方法只保留原始 token 的 KV 缓存,用于长程依赖关系,同时在使用后立即丢弃隐藏的解码 token,从而保持了与 vanilla Transformer 相同的 KV 缓存大小,同时实现了有效的长度 scaling。
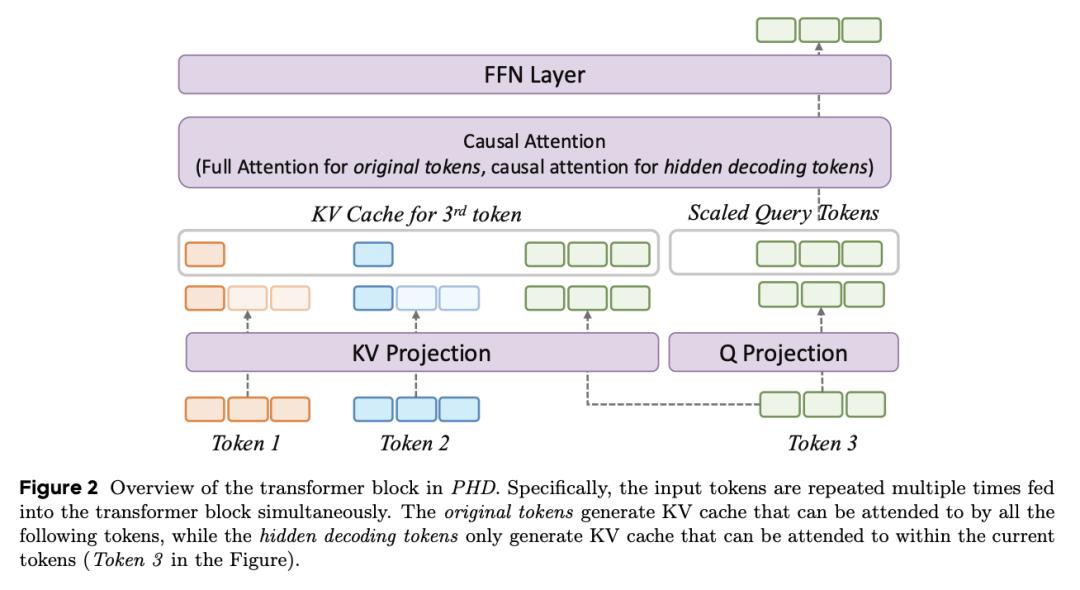
为了进一步提高性能,他们提出了两个优化变体:PHD-SWA 采用滑动窗口注意力来保留局部依赖性,而 PHD-CSWA 则采用分块滑动窗口注意力来消除预填充时间的线性增长。实验证明,在多个基准测试中,PHD-Transformer 都取得了一致的改进。
论文链接:https://arxiv.org/abs/2504.14992
4. Progent:首个 LLM agent 权限控制机制
基于大语言模型(LLM)的智能体(agent)可能带来巨大的安全风险。在与外部世界交互时,它们可能会遇到攻击者的恶意命令,从而导致执行危险的操作。解决这一问题的一个可行方法是执行最小特权原则:只允许完成任务所必需的操作,同时阻止不必要的操作。然而,要做到这一点是很有挑战性的,因为这需要在保证安全性和实用性的同时,覆盖不同的 agent 场景。
在这项工作中,加州大学伯克利分校 Dawn Song(宋晓冬)教授团队提出了第一个用于 LLM agent 的权限控制机制——Progent,其核心是一种特定于领域的语言,用于灵活表达在 agent 执行过程中应用的权限控制策略。这些策略提供了对工具调用的细粒度约束,决定何时允许工具调用,并在不允许工具调用时指定退出路径。这样,agent 开发人员和用户就能针对其特定用例制定合适的策略,并确定性地执行这些策略以保证安全性。得益于其模块化设计,集成 Progent 不会改变 agent 的内部结构,只需对 agent 的实现进行小的改动,从而增强了其实用性和广泛采用的潜力。为了实现策略编写的自动化,他们利用 LLM 根据用户查询生成策略,然后对策略进行动态更新,以提高安全性和实用性。
广泛的评估表明,在 AgentDojo、ASB 和 AgentPoison 这 3 个不同的场景或基准中,Progent 既能实现强大的安全性,又能保持较高的实用性。此外,他们还进行了深入分析,展示了其核心组件的有效性以及自动策略生成对自适应攻击的抵御能力。
论文链接:https://arxiv.org/abs/2504.11703
5. UC 伯克利团队推出 AI 推理框架 APR
推理时计算的扩展大大提高了语言模型的推理能力。然而,现有方法有很大的局限性:序列化的思维链方法会产生过长的输出,导致延迟增加和上下文窗口耗尽,而并行方法(如自一致性)则存在协调不足的问题,导致冗余计算和有限的性能提升。
为了解决这些不足,加州大学伯克利团队推出了一个新的推理框架——自适应并行推理(Adaptive Parallel Reasoning,APR),其可以使语言模型端到端协调串行和并行计算。APR 通过使用 spawn() 和 join() 操作实现自适应多线程推理,从而推广了现有的推理方法。一个关键的创新是端到端强化学习策略,通过优化父线程和子线程来提高任务成功率,而无需预定义的推理结构。
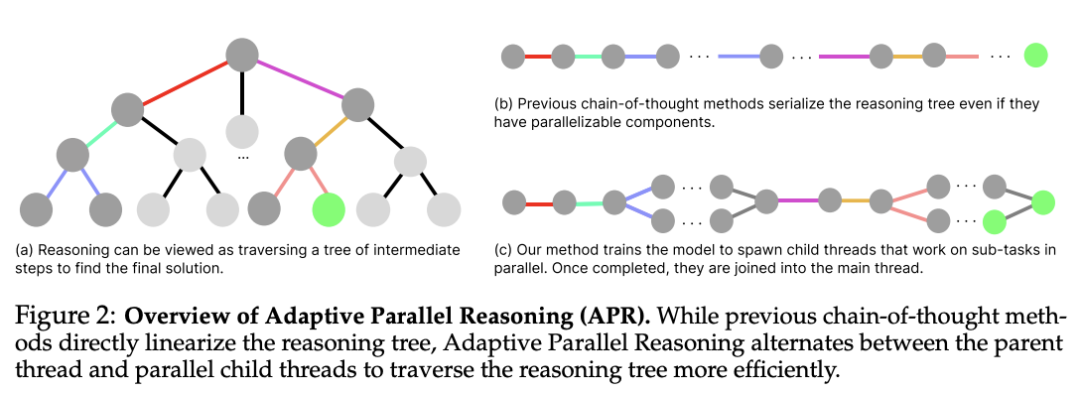
倒计时(Countdown)推理任务实验证明了 APR 的显著优势:(1)在相同上下文窗口内具有更高的性能(4k 上下文时为 83.4% vs. 60.0%);(2)随着计算量的增加,具有更出色的可扩展性(20k token 时为 80.1% vs. 66.6%);(3)在同等延迟条件下提高了准确性(约 5000ms 时为 75.2% vs. 57.3%)。
他们认为,APR 标志着语言模型朝着通过自适应计算分配自主优化推理过程的方向迈出了一步。
论文链接:https://arxiv.org/abs/2504.15466
整理:学术君
如需转载或投稿,请直接在公众号内留言

内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢