
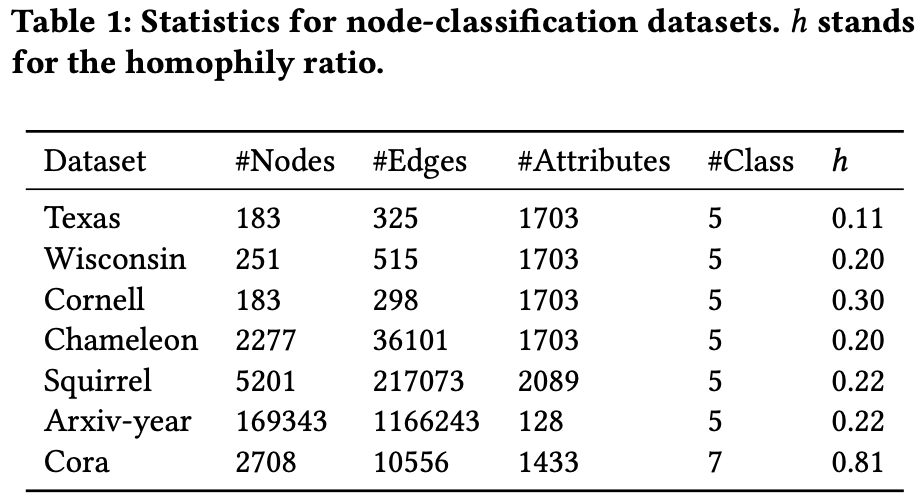
1. 背景
“预训练-微调”(pre-train then fine-tune)范式推动了图神经网络(GNNs)的发展,使模型能够在缺乏特定任务标签的情况下学习通用知识。然而,预训练目标与下游任务之间的差异限制了该方法的整体效果。近年来,一些图Prompting方法尝试通过任务重构以及可学习的Prompt机制来弥合这一差距(任务重构与Prompting机制详细介绍请见章节"问题定义")。
但现有图Prompting方法在面对具有复杂分布的图时表现不尽如人意,尤其是在异配图(heterophily graphs)中,其邻接节点往往具有不同的标签。一方面,这类标签差异导致预训练阶段的学习目标与下游任务需求之间存在显著偏离。由于多数预训练技术是无标签的(label-agnostic),且在不同程度上依赖图结构,它们天然难以适应这类差异。例如,连边预测(link prediction)任务通常促使模型为相连节点生成相似的表示,忽略了它们之间可能存在的标签差异。因此,在异配图中,标签不同的相邻节点往往会被映射到相似的嵌入空间,如下图所示。
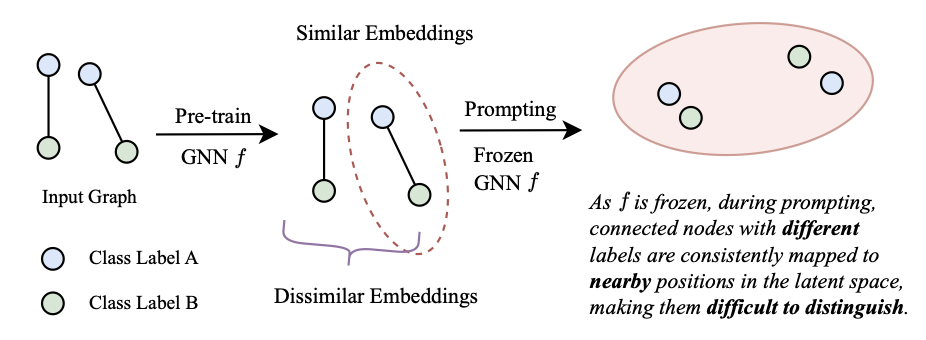
在Prompting阶段,现有方法通常会冻结图神经网络编码器(GNN encoder),并采用较为基础的Prompt策略(如MLP)。然而,冻结GNN参数限制了模型对下游任务中分布变化的适应能力。如上图所示,这一限制使得模型无法动态调整编码器参数,从而难以生成具有更强区分性的节点表示。同时,基础的Prompt机制也难以有效实现节点嵌入的解耦,最终影响模型的整体性能。
另一方面,现有方法通常仅使用GNN最后一层的Embedding作为Prompt输入,少数工作尝试融合所有中间层的Embedding。然而,这种做法忽视了异配图中不同跳数(Hop)节点在分布上的差异性,从而进一步限制了模型在异配图上的表现。
为应对上述问题,我们提出了分布感知的图提示微调方法(Distribution-aware Graph Prompt Tuning, DAGPrompT)。DAGPrompT通过引入GLoRA模块,在低秩近似的框架下,同时优化GNN的投影矩阵与消息传递机制,从而增强模型对分布变化的适应能力。此外,该方法设计了一套基于节点跳数的Prompt系统,以动态响应不同跳数下的结构与语义分布变化。我们在10个数据集和14种主流基线方法上进行了评估,结果表明DAGPrompT在节点分类和图分类任务中最多可将准确率提升4.79%,同时保持了良好的计算效率。基于该项工作整理的论文已被顶级会议WWW'25录用,欢迎阅读交流。
论文:DAGPrompT: Pushing the Limits of Graph Prompting with a Distribution-aware Graph Prompt Tuning Approach
作者:Qin Chen, Liang Wang, Bo Zheng, Guojie Song.
链接:https://arxiv.org/abs/2501.15142
2. 问题定义
预训练GNN的Prompting机制
设有一个在预训练任务 下训练得到的图神经网络模型 ,一组可学习的Prompt参数 ,以及对应于下游任务 的数据集 。我们引入一个任务重构函数 ,用于将下游任务重新映射为与预训练任务 相一致的形式。例如,可以通过引入伪节点(pseudo nodes),将原本的节点分类任务()转化为链路预测任务()。在这一转换中,模型通过预测真实节点与伪节点之间的连接概率,从而推断出节点的类别标签。
在Prompting阶段,模型 的参数保持冻结,仅对Prompt参数 进行优化。优化目标是最大化模型在重构后的任务 上预测正确标签 的概率,形式化如下:
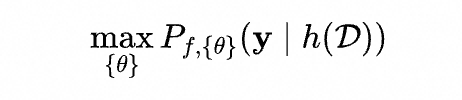
通过任务重构函数来统一下游任务
形式上,给定图 中的一个节点 ,我们定义其 跳邻域为 ,并将图神经网络编码器 所生成的嵌入表示记为 。基于此,我们将下游任务统一重构为链路预测形式,具体包括以下三种任务:
连边预测(Link Prediction):对于一个节点三元组 ,其中节点对 存在边,而 不存在边,期望模型满足: > ,其中,相似度函数 可采用余弦相似度等方式计算。
节点分类(Node Classification):对于一个包含 类标签的图,引入 个伪节点,其嵌入初始化为训练集中对应类别节点嵌入的均值。节点分类任务被重构为链路预测任务,通过判断节点 与哪个伪节点最可能建立连接,来确定其所属类别。
图分类(Graph Classification):对于一组具有 类标签的图,引入 个伪图,其嵌入表示初始化为训练集中各类别图嵌入的均值。与节点分类类似,图的标签预测被转化为图与伪图之间的连边概率计算问题,从而完成分类。
3. DAGPrompT模型
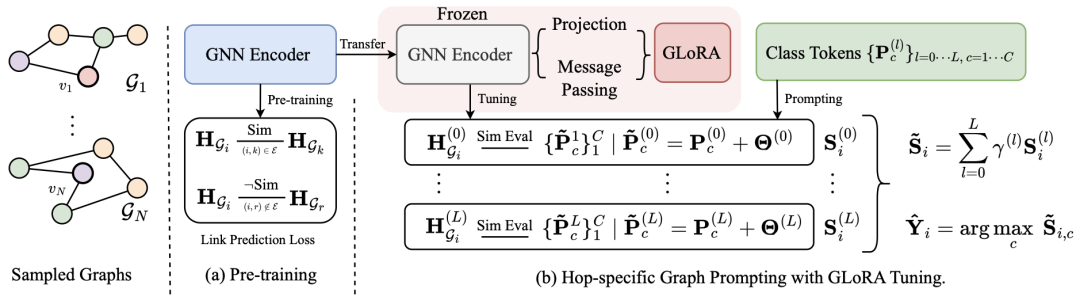
我们提出的DAGPrompT方法如图所示,分为两个阶段。
首先是一个无标签的图预训练(Pre-train)阶段,在这里我们采用经典的连边预测任务作为预训练的工具,算法如下图。

在Prompting阶段,我们从两个方面对模型进行优化。一方面,通过GLoRA模块以低秩近似的方式对GNN编码器的参数矩阵与消息传递机制进行调整。具体而言,对于第 层的图神经网络,其表示形式如下:
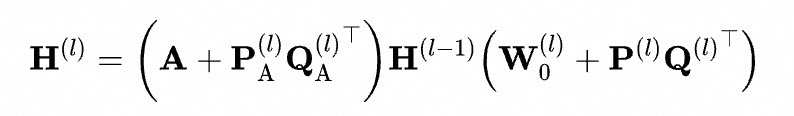
其中, 表示第 层图神经网络中被冻结的参数矩阵; 以及 分别为该层中可训练的低秩矩阵,对应的秩为 和 。其中 ,确保了参数高效可控。值得注意的是,对于超大规模图,项 可进一步压缩为边权(Edge Weight)形式,以提升计算效率。
LoRA in NLP vs Our GLoRA
与NLP中的传统LoRA相比,GLoRA是其在GNN领域的拓展。首先,GLoRA通过 调控GNN中的变换参数矩阵,这与传统LoRA的做法一致。不同之处在于,GLoRA进一步引入 ,用于调控图上的消息传播机制,在训练过程中动态强化有益连接(相当于提高边权),并抑制无关甚至有害的连接(相当于降低边权)。
另一方面,我们引入分层Prompting策略,针对每一层的节点嵌入及其对应的类标记(Class Token),分别计算相似度矩阵。随后,我们通过一组可学习的参数 对不同层级的相似度矩阵进行加权融合,以适应中心节点在不同跳数下对邻域信息的多样化需求。该过程如图所示:

4. 实验结果
我们主要在少样本节点分类任务(Few-shot Node Classification) 上对模型性能进行了评估,实验涵盖如图所示的7个数据集。
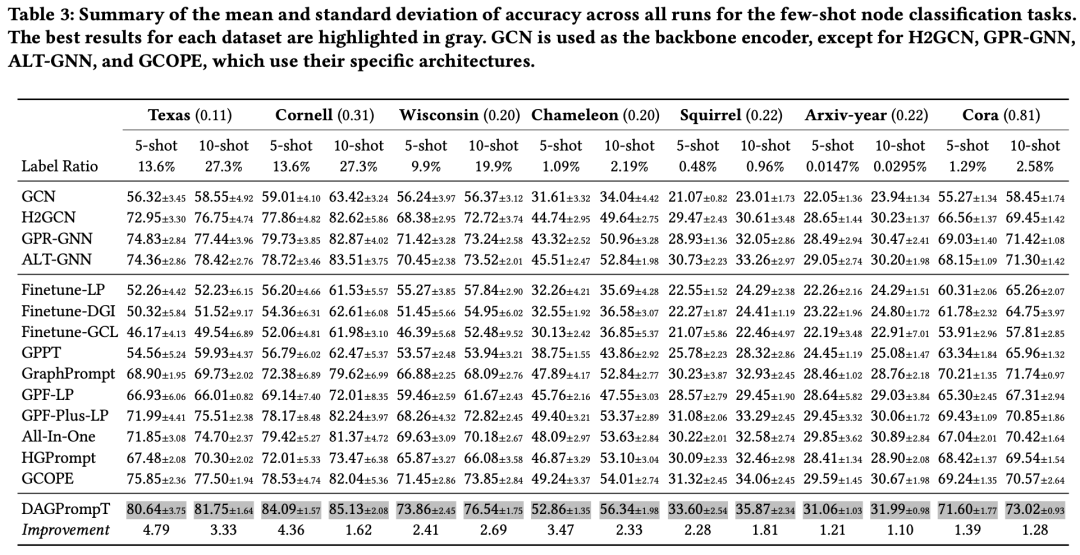
实验结果如上图,可以观察到以下几点:
DAGPrompT在各类基线方法中始终表现优越,且领先幅度显著。 尤其在异质性图(heterophily graphs)中性能提升更为明显。例如,在 Texas 数据集上,准确率提升高达 4.79%;在所有数据集上的平均提升为 2.43%。 在异质性图中,微调(fine-tuning)或 Prompting 方法有时反而不如从零训练的模型。 例如,从零开始训练的 H2GCN 在 Texas、Cornell 和 Wisconsin 数据集上的表现,超过了多数图Prompt方法。这一现象印证了我们在前文中的观点:在结构复杂的图上,预训练任务与下游任务之间存在较大的分布偏差,单纯依赖任务重构或Prompt机制难以充分弥合这一差异。异质性的存在限制了Prompt方法在学习有效嵌入时的表现。 在标签数量极少的情境下,从零开始训练的模型面临明显瓶颈,尤其是在异质性图上表现不稳。 在如 Chameleon、Squirrel 和 Arxiv-year 等标签比例较低的数据集中,即便是不考虑异质性的模型(如 GraphPrompt),其性能也优于部分异质性感知方法。这可能归因于前者在预训练与微调阶段能更充分地利用图结构信息,从而在数据稀缺的场景下取得更强的泛化能力。
5. 结论
本文将图Prompting范式扩展到了具有复杂分布的图结构,特别是异质性图(heterophily graphs)。我们发现,现有方法在此类场景下的泛化能力有限,甚至在某些情况下不如从零训练的简单模型。要在复杂图上实现更优的泛化表现,需要应对两个关键挑战:(1)提升模型对下游任务中新分布的适应能力,缓解因异质性导致的预训练与微调之间的分布差异;(2)实现Prompt在不同节点跳数下的针对性对齐。
为此,我们提出了DAGPrompT模型,创新性地结合了GLoRA模块和跳数自适应(Hop-specific)图Prompting模块,分别对应上述两个核心挑战。我们在10个数据集和14个主流基线方法上的实验结果表明,DAGPrompT在节点分类任务中的准确率最高提升可达 4.79%,充分验证了方法的有效性与优越性。
▐ 关于我们
外投和品牌广告算法团队是阿里妈妈核心算法团队之一,服务于阿里妈妈最具有创新性和增长性的业务。依托于淘天集团庞大而真实的营销数据,以AI技术驱动实现客户在站外进行效果营销和在站内外进行品牌广告营销的能力。我们持续探索深度学习、联邦学习、运筹优化和博弈论在外投效果广告和品牌广告中的应用。团队近些年也在WWW、KDD、SIGIR等知名会议上发表过多篇论文,也有联邦学习和图学习等多个开源框架。欢迎加入我们,一起成长。📮 简历投递邮箱:liangbo.wl@taobao.com

↑扫码投简历&查看岗位详情↑

也许你还想看

喜欢要“分享”,好看要“点赞”哦ღ~
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢