
点击蓝字
关注我们

Part1 大模型训练成本现状与趋势分析
Part2
1.计算资源稀缺性与硬件市场结构性失衡
2.高质量数据资源的稀缺性与获取成本攀升
3.算法复杂度与技术挑战的多维演进
Part3
1.创新壁垒与市场集中化
2.资源分配不均与全球化挑战
3.可持续性问题与环境影响
Part4 行业应对策略与创新路径
1.算法效率优化与小型化研究
2.基础设施创新与算力民主化
3.数据共享与开放协作模式
Part5 政策建议与治理框架
1.国家级计算基础设施与公共资源配置
2.创新激励机制与竞争政策调整
3.生态系统培育与能力建设
人工智能大型语言模型(Large Language Models, LLMs)已成为计算智能范式转换的核心驱动力,其在自然语言处理、多模态内容生成、复杂推理及知识检索等领域展现的突破性能力,正在重构各行业的技术应用图景。然而,伴随这一技术革命的是指数级攀升的计算经济成本,已成为制约行业持续创新的结构性瓶颈。
纵观大模型演进历程,其计算成本增长曲线呈现出令人忧虑的超线性特征。从计量学视角看,参数规模与训练成本之间存在明显的幂律关系(power-law relationship)。以里程碑式的模型为例,从2018年Google推出的BERT(3.4亿参数)到2020年OpenAI的GPT-3(1750亿参数),再到2023年的GPT-4(估计超过1万亿参数),参数量增长了近3000倍,而相应的训练成本从约30万美元飙升至可能超过1亿美元,呈现出近乎指数级的增长轨迹。学术研究表明,顶级AI大模型的计算需求每6.2个月翻倍,远超传统摩尔定律预测的计算能力提升速度(每18个月翻倍),形成了所谓的“逆摩尔定律”(inverse Moore's Law)现象。这种计算经济学困境促使我们重新审视当前AI技术路线的可持续性,并探索替代性技术路径的可能性。
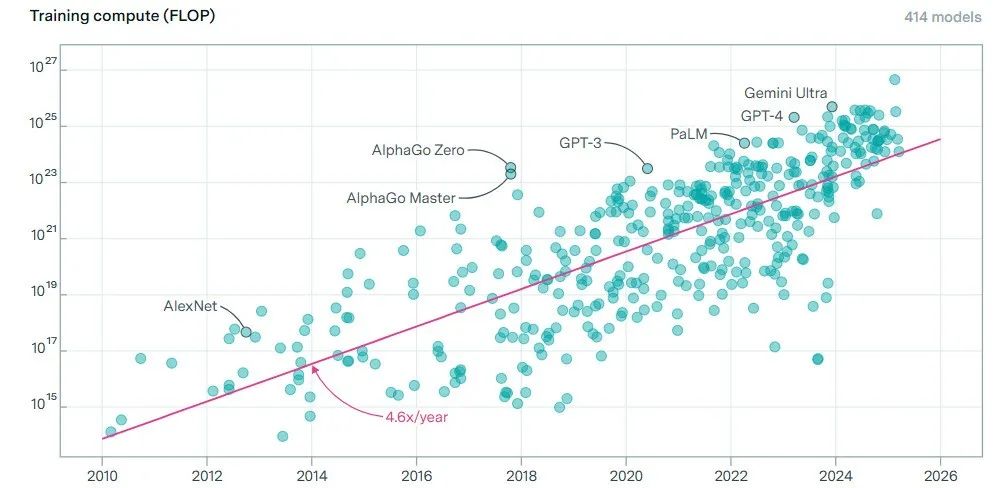
来源:网络
从宏观经济角度分析,这种成本结构已对创新生态系统产生显著影响。计算资源的集中化配置趋势显现,资本密集型企业在关键技术路径上建立了先发优势,并通过规模经济效应持续强化其市场地位。同时,训练成本的高门槛正在重塑创新动力学(innovation dynamics),从开放式创新向寡头垄断创新转变,使得技术路线的多样性和试错空间受到制约。这一现象不仅对产业结构具有深远影响,也引发了技术伦理学和分配正义层面的反思。
模型训练的主要成本驱动因素是高性能计算基础设施,其中GPU(图形处理单元)等专用加速硬件的获取与运维成本占据主导地位。从技术经济学角度看,这一领域呈现出典型的供需不平衡与市场结构性缺陷:
硬件供应链寡头垄断与价格刚性:高端AI芯片市场高度集中,NVIDIA一家独大的局面导致定价权集中,缺乏有效竞争的市场治理机制。以最新一代AI加速器为例,NVIDIA A100/H100 GPU单卡市场价格从初始的1万美元攀升至3-4万美元,涨幅超过200%,远超其制造成本增长。这种价格刚性反映了市场的结构性扭曲。根据哈佛商学院的研究,此类市场垄断导致了高达40-60%的超额利润,而这部分利润实质上是从AI创新主体向硬件供应商的价值转移。
来源:网络
计算集群规模与并行效率的非线性关系:大模型训练需要构建大规模并行计算集群,当前技术路径下,GPT-4级别模型的训练集群规模已达25,000-30,000张高端GPU,构成了一个超级计算系统。然而,并行计算的阿姆达尔定律(Amdahl's Law)表明,随着系统规模扩大,通信开销和同步问题导致计算效率呈对数下降,形成了规模与效率的权衡困境。技术实践表明,当集群规模超过10,000个计算节点时,系统整体利用率通常降至70%以下,造成显著的资源浪费。
能源消耗与碳足迹问题:从能源经济学视角看,大模型训练的能耗问题不容忽视。以GPT-4类模型为例,其完整训练周期的能耗约为700-1000 MWh,相当于约10,000户美国家庭一个月的用电量。这不仅带来直接的电力成本(约10-15万美元),还产生了大量碳排放,与全球碳减排目标形成张力。根据最新研究,一个大型语言模型的训练可能产生300-500吨二氧化碳当量的排放,相当于70-100辆汽车一年的排放量。
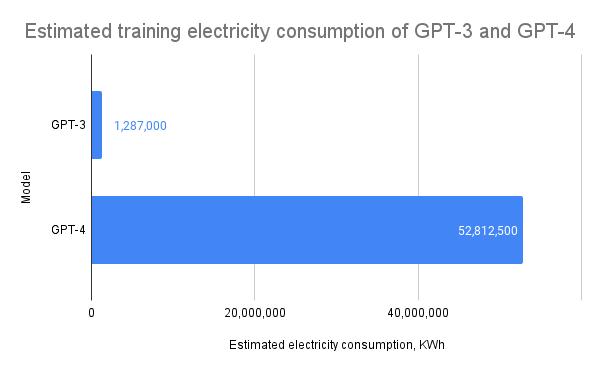
随着大模型架构的标准化,高质量训练数据已成为模型性能差异化的关键要素,但其获取面临多重挑战:
数据枯竭现象与边际成本递增:开放互联网上的自由文本数据已被广泛采集利用,形成了所谓的“数据枯竭”(data exhaustion)现象。研究表明,英文互联网上高质量、无重复、合规可用的文本数据总量约为3-5万亿词元(tokens),而当前SOTA大模型的训练已使用了其中大部分。这导致每增加一单位优质数据的边际成本呈指数级增长。一些企业报告称,高质量专业领域数据的获取成本已从2020年的每百万词元5-10美元上升至2024年的50-100美元,增幅达10倍。
数据标注的劳动密集型特性与成本结构:虽然无监督学习减少了对标注数据的依赖,但强化学习人类反馈(RLHF)、事实对齐等技术仍需大量人工标注。以RLHF为例,高质量的偏好对比数据集构建通常需要专业知识和严格质控,平均标注成本为每条对比数据2-5美元。根据公开资料,ChatGPT训练过程中使用的人类反馈数据集成本估计超过700万美元,占其初期训练总成本的12-15%。

来源:STYLE FACTORY
数据合规性与治理成本:随着全球数据隐私法规如GDPR、CCPA等的实施,数据获取、存储和处理的合规成本显著上升。企业需要建立复杂的数据治理架构,包括数据来源审计、隐私保护处理、权限管理和安全监控等多层次系统。据麦肯锡全球研究院估计,完整的数据合规体系建设与维护成本已占大型AI项目总成本的8-12%,且这一比例仍在上升。
大模型的训练过程面临诸多技术层面的复杂挑战,每一维度都对成本曲线产生影响:
优化算法的收敛性与计算效率权衡:随着模型规模扩大,优化过程中的梯度噪声、不稳定性和病态条件数(ill-conditioning)问题日益严重。当前的随机梯度下降类算法在超大规模参数空间中效率低下,通常需要数万至数十万次迭代才能达到收敛。研究表明,参数规模每增加10倍,收敛所需的计算步骤约增加3-4倍,形成了不利的计算复杂度增长态势。
分布式训练架构的系统复杂性:大模型训练需要高度优化的分布式系统支持,包括数据并行、模型并行、流水线并行等多种策略的协同应用。这些系统的设计、实现和调优需要跨领域专业知识,形成了显著的人力资本投入。顶级AI实验室的分布式训练框架开发团队规模通常在50-100人,年度运维成本达数千万美元。这种系统复杂性也限制了能够进行前沿研究的机构数量。
工程实践与理论优化之间的鸿沟:虽然学术界提出了诸多提升训练效率的理论方法,如低秩适应(Low-Rank Adaptation)、参数高效微调(Parameter-Efficient Fine-Tuning)等,但将这些方法应用于超大规模生产环境面临诸多挑战。理论与实践之间的转化率偏低,导致实际训练效率提升有限,无法抵消规模扩大带来的成本增长。
综合而言,大模型训练成本飙升是计算资源、数据资源和技术复杂性等多重因素交织作用的结果,呈现出典型的"复杂系统"特征,难以通过单一维度的优化获得根本性突破。
大模型训练的能源消耗已成为不容忽视的环境问题。据估计,训练一个大型语言模型可能产生数百吨二氧化碳排放,相当于数十辆汽车全年的排放量。随着模型规模继续扩大,其能源需求和碳足迹也将增加,这与全球减碳目标产生冲突。行业面临如何平衡AI创新与环境可持续性的重大挑战。减少AI训练的环境影响已成为政策制定者和企业必须考虑的重要议题。
综上所述,大模型训练成本飙升已远超单纯的技术经济问题,深刻影响着产业结构、全球格局和社会伦理。这要求我们在技术解决方案之外,也关注其背后的深层次社会经济意涵。
大模型训练成本高企的根本原因在于计算复杂度与参数规模的超线性关系,因此算法层面的效率优化自然成为突破瓶颈的第一道防线。近年来,算法效率研究已从初期的边缘改进发展为系统性变革,形成了多条并行的技术路线。
知识蒸馏技术作为其中最具实用价值的方向,通过“教师-学生”架构重塑了模型训练的基本思路。该方法不再追求从零训练更大模型,而是将已有大模型(教师)的知识有效迁移至轻量级模型(学生)中,实现"以大养小"的知识传承。微软研究院的DistilBERT项目证明了这一方法的实用性——通过精心设计的蒸馏目标函数,一个仅保留原BERT 40%参数量的轻量模型成功保留了原模型95%的性能指标,同时推理速度提升2.5倍,内存需求降低60%。这种“小而强”的模型为资源受限场景提供了可行解决方案,如移动设备部署和低成本云服务。
与此同时,参数效率研究正在从另一角度挑战传统的密集参数模型范式。稀疏化与量化技术以降低参数精度和减少非零参数为核心思路,探索更紧凑的模型表示。谷歌DeepMind团队开发的QLoRA(Quantized Low-Rank Adaptation)技术采用4位或8位量化表示参数,并结合低秩适配方法进行微调,显著降低了内存需求与计算开销。这些技术不仅直接减少了训练资源消耗,还创造了“一次训练、多种精度部署”的灵活适配能力,使模型可根据应用场景弹性调整资源需求。

更具革命性的是,一些研究团队正在挑战“更大即更好”的主流范式,转向探索结构更优的小型模型。这一研究方向的核心洞察在于:模型能力不仅取决于参数规模,更依赖于训练数据质量、优化策略和架构设计的系统协同。斯坦福大学的研究进一步表明,对于特定任务,精心设计的10亿参数模型在多轮对话、理解能力和创造性任务上可以超越参数量大10倍的通用模型,这对重新思考AI研发路径提供了重要启示。
这些算法效率创新正在根本上改变行业的竞争逻辑,从单纯的“规模军备竞赛”转向“效率与专业化竞争”。随着研究深入,我们或许将看到AI发展路径的多元化——超大规模基础模型与高效专业化模型并行发展,共同构成更丰富的AI技术生态系统。
算法优化之外,计算基础设施的创新同样是降低训练成本的关键杠杆。当前AI训练硬件市场由NVIDIA等少数厂商主导的局面正面临多元化挑战,新型专用AI芯片的涌现为产业带来更多选择。谷歌的张量处理单元(TPU)通过面向矩阵计算的专用架构设计,在大模型训练任务上实现了比通用GPU高40%的能效比;而百度昆仑芯片则针对中文自然语言处理场景进行了深度优化,对特定任务提供了更高的性价比选择。更激进的架构创新来自Cerebras、SambaNova等创新公司,它们突破了传统芯片设计理念,采用晶圆级集成或领域特定架构,为模型训练提供差异化解决方案。随着这些竞争者的成熟与规模化,AI计算硬件市场的垄断局面有望被打破,价格竞争机制也将更好发挥作用,直接降低训练成本。
与此同时,云计算模式正在重塑AI计算资源的获取方式。传统的本地部署模式要求企业投入巨额前期资本购置硬件,形成高门槛;而基于云的AI平台则转向”按需使用、即用即付”的弹性经济模式,显著降低了准入成本。AWS的SageMaker、微软Azure的ML Studio和阿里云的PAI等云服务通过资源池化与调度优化,提高了整体算力利用率,有效降低了大模型训练成本。更具创新性的是“即付即用”(pay-as-you-go)的微粒度计算经济模型,使小型组织能够在不承担硬件折旧风险的情况下,获取世界级的AI训练能力。这种基础设施即服务(IaaS)的商业模式不仅降低了初创企业的财务压力,也提高了创新周期,使构想到原型的时间大幅缩短。
分布式训练基础设施的进步则开创了算力共享与协同计算的新范式。传统的单一组织封闭训练模式正让位于更开放的分布式协作架构。ELEUTHER AI联盟通过创新的协作框架,汇集了数百名志愿者的计算资源,成功训练了GPT-J、BLOOM等开源大模型,证明了分布式协作的可行性。其中,Hoplite等开源框架通过解决分布式训练中的通信瓶颈、容错机制和激励分配等核心问题,使跨组织协同训练变得更加可靠和高效。这种“众人拾柴火焰高”的分布式计算范式特别适合学术机构和非营利组织,通过汇集分散资源实现超出单一机构能力的大规模训练任务。更重要的是,这种协作模式超越了纯粹的成本考量,还促进了知识共享和多元视角的融合,有助于构建更具包容性的AI发展生态。
基础设施层面的这些创新正在系统性降低大模型训练的准入门槛,使更多元的参与者能够加入前沿研发,避免技术创新被少数拥有超级算力的机构垄断。随着专用硬件的普及、云服务的成熟和分布式架构的完善,我们有望看到一个更加平等和多样化的AI创新生态系统逐步形成。
数据作为AI训练的核心生产要素,其获取与利用效率直接影响着整体训练成本。面对数据获取日益困难的挑战,产业界正在重构数据协作模式,探索突破传统“数据孤岛”的新范式。行业数据联盟作为一种新兴协作形式,正在多个垂直领域展现活力。这种联盟基于共同目标与互惠原则,在保护各方商业利益的前提下实现数据资源的有限共享。
欧洲GAIA-X计划就是这一模式的典型代表——它通过建立数据主权云和联邦数据基础设施,为医疗、制造业等敏感领域创建了安全可控的数据交换环境。其核心在于通过技术架构设计与治理规则,平衡数据开放与安全的双重需求,让参与方能够在不失去数据控制权的情况下共享数据价值。
合成数据技术的兴起则为数据依赖型AI训练提供了全新思路。通过利用生成模型创建人工合成但具有真实特性的数据样本,研究者可以突破真实数据的稀缺性限制,同时规避隐私和版权问题。在医疗影像领域,基于生成对抗网络(GAN)和扩散模型的合成病理图像已被证明可以显著增强诊断模型的性能,同时避免了敏感医疗数据的直接使用。商业领域中,金融机构正使用合成交易数据训练欺诈检测系统,在不暴露客户信息的情况下提升模型鲁棒性。更具颠覆性的是,通过大模型自我提升的方法(model bootstrapping),研究者发现利用现有模型生成的合成数据可以训练更强的下一代模型,形成良性循环。
开源预训练模型的普及则从根本上改变了AI研发的游戏规则。传统范式要求每个参与者从零开始训练模型,形成了巨大的资源浪费;而“预训练-微调”的新范式则允许共享基础模型的训练成本,各参与者只需专注于低成本的特定领域适配。Hugging Face等开源社区通过构建“模型中心”,为全球开发者提供了数千个预训练模型,从通用大模型到专业领域小模型不等,极大降低了入门门槛。这种知识复用机制特别有利于创业公司和新兴市场参与者,使他们能够在有限资源下迅速实现AI应用落地。
这些数据资源优化策略正在重塑AI研发的基本逻辑,从封闭独立的竞争模式转向更具协作性的生态系统。开放协作不仅降低了单个参与者的成本负担,还通过知识共享、集体智慧和资源优化配置,提高了整个产业的创新效率。随着这些模式的成熟,我们有望看到AI技术民主化进程加速,技术红利更广泛地惠及各行各业,而非集中于少数资源丰富的科技巨头。
国家AI计算中心网络建设:参考高性能计算领域的成功经验,建议构建分层级的国家AI计算中心网络。具体而言,在国家层面建立超大规模AI计算中心,提供PFlop/s级计算能力;在区域层面布局中等规模计算节点;在高校和科研机构设立百余个小型特色计算集群。这一"中心-节点-集群"的三级架构将大幅提升计算资源利用效率,避免分散重复建设。
算力配额制度与优先领域支持:借鉴碳排放配额制度的思路,建立国家级AI算力配额分配机制。根据项目的社会价值、创新潜力和资源效率等维度进行评估,向优先发展领域(如医疗健康、气候变化、教育等公共价值领域)倾斜配置稀缺计算资源。
跨国算力共享机制与国际协作平台:考虑到单一国家难以独立支撑前沿AI研发的全部成本,建议积极推动国际算力共享合作。
多元化研发资助与风险分担机制:传统的竞争性项目资助模式难以适应AI领域的高风险特性,建议构建更多元化的资助工具组合。这应包括前期探索性研究的无条件资助、中期里程碑付款的阶段性资助以及成果产出后的奖励性资助等多种形式。特别是对于商业前景不确定但技术创新性高的项目,可采用风险分担方式,降低创新主体的财务风险,为高风险创新项目提供失败保护,鼓励大胆尝试突破性方向。
反垄断政策的AI特定框架:考虑到AI领域的特殊竞争动态,传统反垄断框架需要调整。建议将数据优势和计算资源集中度纳入反垄断审查范围。特别关注“基础模型提供商-应用开发者”之间的垂直关系,防止通过API访问条件限制下游创新。在并购审查中,重点防范大型科技公司通过收购来巩固计算和数据优势的行为,确保AI市场的长期竞争活力。
税收激励与知识产权保护创新:针对AI研发的特殊成本结构,建议设计针对性的税收激励政策。同时,创新知识产权保护机制,允许基础研究免费使用AI模型,而商业应用则支付基于规模和收益的层级式授权费用。这种机制有助于平衡知识传播与创新激励之间的张力。
AI综合试验区与监管沙盒:建立国家级AI综合试验区,在特定区域实施更灵活的监管政策和资源支持,加速创新验证和商业化。试验区内可探索先行先试的数据共享机制、跨境数据流动规则、算力共享平台等创新安排,为全国性政策提供实践经验。同时设立AI监管沙盒(regulatory sandbox),允许在可控环境中测试前沿应用,平衡创新与风险管控的关系。
教育体系改革与跨学科人才培养:AI人才短缺是驱动成本上升的重要因素,需要系统性改革教育培养体系。建议在高等教育阶段设立"AI+X"交叉学科专业,培养兼具领域知识与AI技术能力的复合型人才。在职业教育层面,建立面向产业需求的技能培训体系,特别是加强数据工程、大规模分布式系统等专业人才的培养,降低行业人力成本。
中小企业AI赋能计划:针对中小企业面临的AI应用门槛高问题,建议实施系统性的赋能计划。具体措施包括:建立行业级预训练模型库,免费或低成本向中小企业开放设立技术咨询服务体系,提供专业指导;组织产业联盟,促进规模化协作训练和应用。通过这些措施,使AI技术红利能够更广泛地惠及产业生态各层级参与者,避免技术垄断带来的发展不平衡。
通过上述多层次、多维度的政策组合,可以构建一个平衡创新活力与公平包容的AI发展环境,引导产业生态向更可持续、更开放的方向演进,使AI技术真正成为推动人类共同进步的积极力量。
2.Xu, Lingling, et al. "Parameter-efficient fine-tuning methods for pretrained language models: A critical review and assessment." arXiv preprint arXiv:2312.12148 (2023).
3.Touvron, Hugo, et al. "Llama 2: Open foundation and fine-tuned chat models." arXiv preprint arXiv:2307.09288 (2023).
4.Bhardwaj, Eshta, Rohan Alexander, and Christoph Becker. "Limits to AI Growth: The Ecological and Social Consequences of Scaling." arXiv preprint arXiv:2501.17980 (2025).
5.Soni, Vishvesh. "Impact of generative AI on small and medium enterprises’ revenue growth: the moderating role of human, technological, and market factors." Reviews of Contemporary Business Analytics 6.1 (2023): 133-153.
6.Myers, Devon, et al. "Foundation and large language models: fundamentals, challenges, opportunities, and social impacts." Cluster Computing 27.1 (2024): 1-26.
7.Stanford University (2024). "The 2024 AI Index Report". Stanford Institute for Human-Centered AI.
8.Kaplan, J., et al. (2020). "Scaling Laws for Neural Language Models". arXiv preprint arXiv:2001.08361.
9.Park, Sangchul. "Bridging the global divide in ai regulation: A proposal for a contextual, coherent, and commensurable framework." Wash. Int'l LJ 33 (2023): 216.
10.Dash, Saumya. "Green AI: Enhancing Sustainability and Energy Efficiency in AI-Integrated Enterprise Systems." IEEE Access (2025).
11.Liu, Vivian, and Yiqiao Yin. "Green AI: exploring carbon footprints, mitigation strategies, and trade offs in large language model training." Discover Artificial Intelligence 4.1 (2024): 49.
12.Iftikhar, Sunbal, and Steven Davy. "Reducing Carbon Footprint in AI: A Framework for Sustainable Training of Large Language Models." Proceedings of the Future Technologies Conference. Cham: Springer Nature Switzerland, 2024.
审核丨梁正 鲁俊群
清华大学人工智能国际治理研究院(Institute for AI International Governance, Tsinghua University,THU I-AIIG)是2020年4月由清华大学成立的校级科研机构。依托清华大学在人工智能与国际治理方面的已有积累和跨学科优势,研究院面向人工智能国际治理重大理论问题及政策需求开展研究,致力于提升清华在该领域的全球学术影响力和政策引领作用,为中国积极参与人工智能国际治理提供智力支撑。
新浪微博:@清华大学人工智能国际治理研究院
微信视频号:THU-AIIG
Bilibili:清华大学AIIG
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢