
DRUGAI
今天为大家介绍的是来自美国麻省理工和英国剑桥大学团队合作的一篇论文。肽是无处不在且重要的生物分子,能自组装成多样化的结构。尽管已有大量研究探索了化学组成和外部条件对自组装的影响,但缺乏一项系统性研究来整合这些数据以揭示全局规则。在本研究中,作者通过人类专家的手动处理和大型语言模型辅助的文献挖掘相结合的方式,建立了一个肽组装数据库。因此,作者收集了超过1000条实验数据条目,包含肽序列、实验条件和相应的自组装相的信息。利用这些数据,作者开发了机器学习模型,在组装相分类方面表现出优异的准确率(>80%)。此外,作者利用开发的数据集对GPT模型进行微调,用于肽文献挖掘,该模型在从学术出版物中提取信息方面明显优于预训练模型。这一工作流程可以通过指导实验工作,提高探索潜在自组装肽候选物的效率,同时加深对其支配机制的理解。

自组装是自然界中普遍存在的现象,在分层生物材料的形成中起着关键作用。从有机分子和蛋白质到核酸和两亲性化合物,各种构建块在各种分子相互作用的驱动下可以自组装成纳米和微观尺度的结构。在这些构建块中,肽凭借其简单而多功能的化学组成和非共价的弱分子间相互作用,呈现出独特的结构和功能特性。在过去几十年中,很多研究已报道了丰富多样的自组装肽基纳米结构,包括管、纤维、带、板和球体。这些组装的肽作为结构化、功能性生物材料,应用范围广泛,从药物递送系统和组织工程到催化和电子学。
肽的自组装行为受系统中的基础热力学和动力学的调控。肽可以采取特定的组织形式,如supramolecular α helices、β sheets和β-hairpins,这些是特定组装纳米结构的关键构建块。因此,大量研究表明,可以使用一系列因素来操控系统形成特定的二级结构。这些包括内在参数,如肽序列和化学修饰,以及外在因素,如pH值、温度、溶剂类型和浓度。
机器学习(ML)和人工智能(AI)已经成为跨越计算机科学之外各个领域的独特且宝贵的工具。例如,使用ML和AI技术设计具有目标功能的全新蛋白质彻底改变了生物工程。一个相关领域是多肽自组装,其中经典ML算法[随机森林(RF)]和深度学习(DL)方法[图神经网络或基于transformer的模型]已被应用于预测在不同氨基酸序列下多肽材料的聚集倾向。目前,经典ML算法在短肽组装预测方面显示出最大的潜力。
而生成大量合成分子的实验数据集是具有挑战性的;因此,用于训练这些模型的数据集通常是从粗粒化(CG)分子动力学(MD)模拟或基于物理化学性质的统计算法中收集的。与实验方法相比,计算方法提供了高效率,但受到其准确性和适用的内在/外在参数范围的限制。此外,在蛋白质科学中常被预测的聚集倾向是基于表面积定义的,仅反映了蛋白质聚集的能力,而非这些聚集体的结构多样性。因此,收集全面的实验数据对于理解肽材料的自组装行为并为数据驱动研究奠定基础至关重要。
当涉及从文献中收集数据,通常称为文献挖掘时,由于出版物数量庞大,人类专家审阅所有相关论文比较困难。最近出现的大型语言模型(LLMs),为挖掘研究人员撰写的学术文本并以快速、自动和系统化的方式收集目标信息提供了创新方法。在LLMs的支持下,许多材料研究成功地从学术出版物的摘要文本中提取了有关材料组成和性质的信息。然而,由于摘要简洁、结构良好且清晰,语言模型可以轻松处理,不像具有稀疏和混合模态信息(文本、图像、标题、参考文献等)的更复杂主文本。因此,仅有少数研究对大量出版物的主要文本进行了文献挖掘,而这些工作使用了更复杂的处理步骤从论文中提取知识,然后用于训练LLMs。摘要只提供最小量的信息,通常缺乏详细的实验程序和结果,这两者对于理解和复制自组装过程都是必不可少的,因此限制了其在挖掘全面文献数据方面的效用。
在本研究中,作者整理了一个自组装短肽数据集,包含组装相和相应实验条件的信息。这个数据集来源于先前建立的肽自组装数据库SAPdb中选取的出版物,信息由人类专家提取。
模型部分
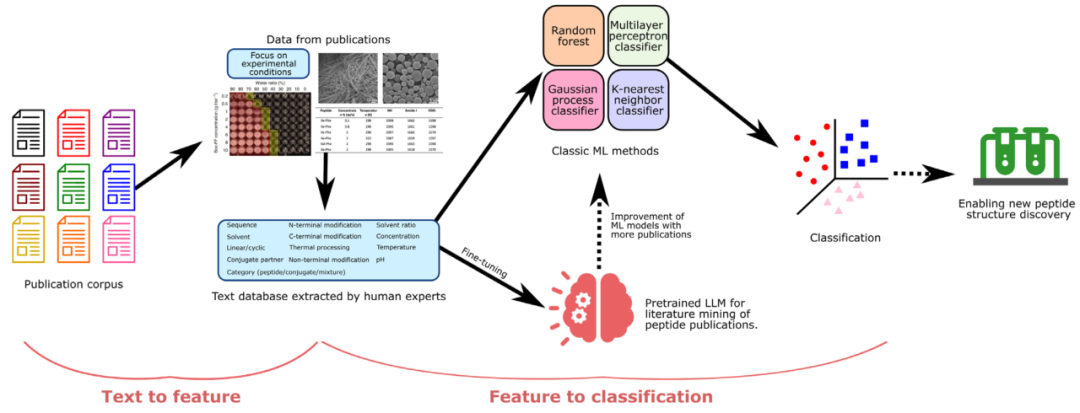
图 1
本研究的整体工作流程如图1所示。作者首先根据先前的多肽数据库SAPdb,直接从出版商和科学数据库(如PubMed数据库)收集与多肽自组装相关的科学出版物。SAPdb是一个包含来自301篇论文的1049个实验验证的短肽(二肽和三肽)条目的集合。作者根据每篇出版物是否可以纳入作者的机器学习预测特征模板对整个数据库进行筛选。
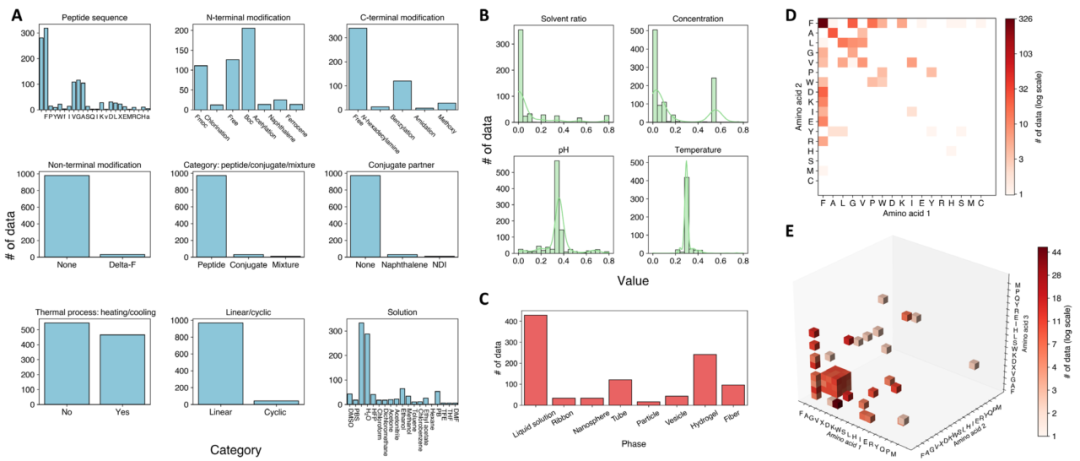
图 2
在作者的特征模板中,作者有九个分类特征和四个数值特征,如图2(A和B)所示。超出这些特定特征进行实验控制的学术出版物由于稀少和效用有限而未被纳入数据库。经过筛选过程,作者确定了共75篇出版物。所有75篇出版物都在Zenodo (DOI: 10.5281/zenodo.14791268)中被引用。通过这些选定的出版物,作者着重从主要文本中提取实验细节和组装相,最终获得了总计1012个数据条目。
利用整理好的数据库,作者随后训练机器学习模型,从肽序列和实验参数预测自组装相。为了在分类中获得最佳性能,作者比较了多种经过超参数优化的经典机器学习算法,这些在以下内容中有更详细的讨论。与成本高昂且耗时的肽合成和表征过程相比,机器学习模型能够以中等准确率快速分类肽。然而,论文阅读和数据收集的手动过程需要大量人力资源且耗时。因此,作者进一步利用预训练的大型语言模型(GPT-3.5 turbo)加速文献挖掘过程。该大型语言模型被设计用于执行一项称为"命名实体提取"(NER)的任务,使模型能够根据给定的目标实体从文本文档中高效提取关键信息。为了使GPT模型专门理解与肽自组装相关的科学写作,手动整理的数据集被分为训练集和测试集,训练集用于微调GPT-3.5 turbo模型,测试集用于性能评估。作者证明,微调可以显著提高信息提取的性能,并且只需要少量数据进行迁移学习。
通过微调后的大型语言模型助手,作者能够对未来出版物或研究工作(如那些研究较长肽的研究)进行高效的文献挖掘,这些研究不在选定的出版物之列。这些由大型语言模型获取的未来数据可以进一步添加到作者的数据库中,并用于提高作者相分类机器学习模型的性能。因此,所提出的方法为一种自主工作流程铺平了道路,该工作流程能够持续从论文中收集数据,扩充现有数据集,并完善分类模型。此外,这一工作流程有潜力促进实验设计和有前景的肽候选物筛选。
数据集的特征和统计数据
整理好的多肽数据集的统计数据如图2所示。数据集有九个分类特征,包括:(i) "肽序列",即肽的氨基酸序列,特定指二肽(长度为2)或三肽(长度为3);(ii) "N端修饰",描述肽N端的化学修饰,如保护基;(iii) "C端修饰",涉及肽C端的化学修饰;(iv) "非端基修饰",指R基团的化学修饰;(v) "类别:肽/偶联物/混合物",表明肽系统是由单一肽、偶联物还是混合物组成;(vi) "偶联伙伴",识别偶联体系中的偶联肽;(vii) "热处理:加热/冷却",表明实验过程中是否存在温度变化,如加热或冷却;(viii) "线性/环状",区分线性和环状自组装肽;以及(9) "溶液",详细说明溶液环境,包括溶剂和溶质的信息。每个分类特征的可能值及其在作者数据集中的出现频率如图2A所示。
除了分类特征外,数值特征在确定肽的自组装相方面也起着至关重要的作用。作者在此研究了四种不同的数值特征:(i) "溶剂比例",描述溶液中溶剂的体积比;(ii) "浓度",定义为溶解肽的浓度(mg/ml);(iii) "pH值",即溶液环境的pH值;以及(iv) "温度",表示进行自组装实验的环境温度。这些数值特征的直方图显示在图2B中。所有数值特征均基于数据库中发现的最大值和最小值在0到1之间进行标准化。
分类和数值特征的组合构成了完整的输入实验条件,共包含13个特征。相应的输出自组装相分布如图2C所示。如图所示,在出版物中最常见的相是"无组装"情况,这在原始SAPdb数据库中并未包含。尽管如此,这些实例对于训练相预测的机器学习模型至关重要,因为它们为数据库贡献了宝贵的非正例。
作者还可视化了作者数据库中二肽和三肽的出现频率,如图2(D和E)所示。对于二肽,FF正如预期的那样是研究最多的肽。FF是阿尔茨海默病淀粉样β肽的核心识别基序,可以在不同的外部刺激下形成多种相,包括水凝胶和空心纳米管。对于三肽,含FF的序列也常被观察到(在x-y或y-z平面上的数据中可见),XFF具有最高的出现频率(其中X是任何给定的氨基酸)。这是由于XFF已被研究的实验条件范围广泛所致。除了苯丙氨酸外,甘氨酸是在二肽和三肽情况下第二个研究最多的氨基酸。此外,就整体研究量而言,二肽的研究占主导地位,超过了三肽。
用于相预测的机器学习算法
有了整理好的数据集,作者现在能够训练机器学习算法,用不同的实验条件和肽序列进行相预测。分类特征根据类别数量转换为独热编码。所有输入特征然后连接成一维(1D)向量,作为经典机器学习算法的输入。作者比较了四种不同的经典机器学习算法:随机森林(RF)、多层感知器(MLP)分类器、高斯过程分类器(GPC)和K近邻分类器(KNC)。为了优化这些模型的性能,作者对每个模型进行了超参数网格搜索。考虑到数据集在八个不同相之间的不平衡(图2C),作者整合了精确度、召回率和F1分数等指标,对四种不同的机器学习算法进行全面评估。
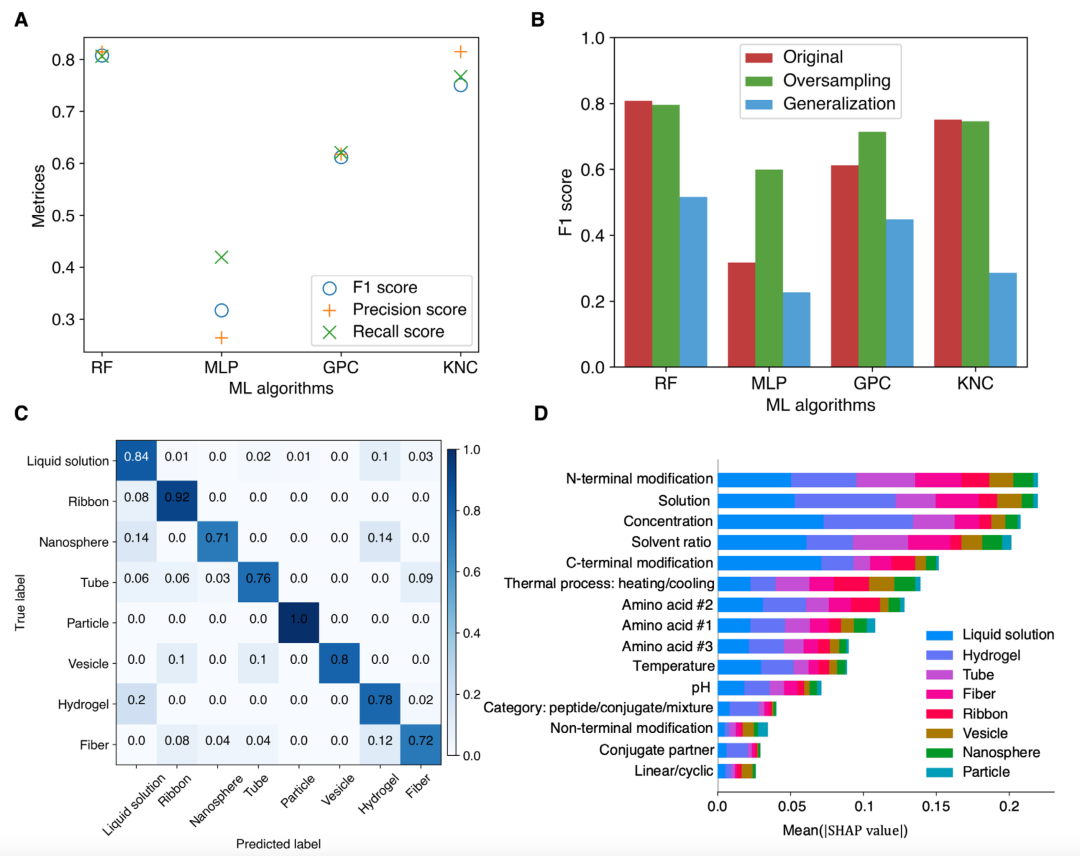
图 3
在测试的机器学习模型中,RF表现最佳,在所有三个指标上获得了最高分数(精确度=0.814,召回率=0.806,F1=0.808)(图3A)。KNC模型排名第二,因为它表现出与RF模型相当的精确度分数,而其召回率和F1分数略低。这表明KNC的性能更容易受到数据集不平衡的影响。与RF和KNC算法相比,MLP分类器表现出更差的准确性,不仅整体分数较低,而且不同指标之间存在较大差异。
为了进一步评估作者机器学习模型的性能,作者使用一种称为合成少数类过采样技术(Synthetic Minority Oversampling Technique,SMOTE)的过采样技术来解决数据集的不平衡问题。SMOTE方法通过在现有少数类实例之间进行插值,生成少数类的合成示例以平衡数据集。当使用过采样数据集时,MLP分类器和GPC模型的F1分数有了很大提高,而RF和KNC算法保持了与原始数据集观察到的相当的性能(图3B)。在评估的四个模型中,RF模型在使用合成平衡数据集测试时始终表现出最高的准确率。然而,作者当前随机分割数据集的方法可能会引入偏差,因为训练集和测试集都可能包含来自同一出版物的数据。这是因为单篇论文通常为数据集贡献多个数据条目。为了评估作者模型的泛化能力,作者根据出版物将数据集分为训练集和测试集,这确保了测试集中的数据来自训练集完全未见过的出版物。如图3B所示,在泛化测试集上评估的模型的F1分数明显低于原始情况。然而,RF模型仍然表现出相对较高的F1分数(大于0.5),考虑到总共有八个相类别,随机相猜测只能达到0.125的分数,这一点值得注意。
基于对模型的全面评估,作者得出结论,RF模型是相位预测的最佳选择,因为它在所有测试中始终表现出色。图3C展示了RF模型预测的混淆矩阵,该矩阵比较了真实和预测的分类,直观地显示了不同类别中正确和错误预测的计数。混淆矩阵对角线上观察到的高值凸显了该模型在不同相位分类中的有效性和一致性。
在确定最佳模型并评估其性能后,作者旨在深入了解各种输入特征——从肽序列到外部刺激——如何影响最终输出,即自组装相。为了获得对模型的解释性,作者使用了SHapley加性解释(SHapley Additive exPlanations,SHAP)技术,这是一种博弈论方法,可解释输入特征对机器学习模型输出的重要性。在所有输入特征中,"N-末端修饰"、"溶液"和"浓度"是对相位分类总体影响最大的三个特征(图3D)。在两个最常见的相位("液体溶液"和"水凝胶")中,"浓度"是"无组装"相位的最关键特征,而"溶液"则是"水凝胶"相位的最重要特征。这是符合预期的,因为要形成新相,必须达到临界浓度。作者的模型揭示的相关性提供了宝贵的见解,可以指导实验设计。例如,研究人员在试图实现特定相位时,可以在实验中优先考虑最具影响力的特征(在SHAP分析中识别)。
LLM辅助文献挖掘
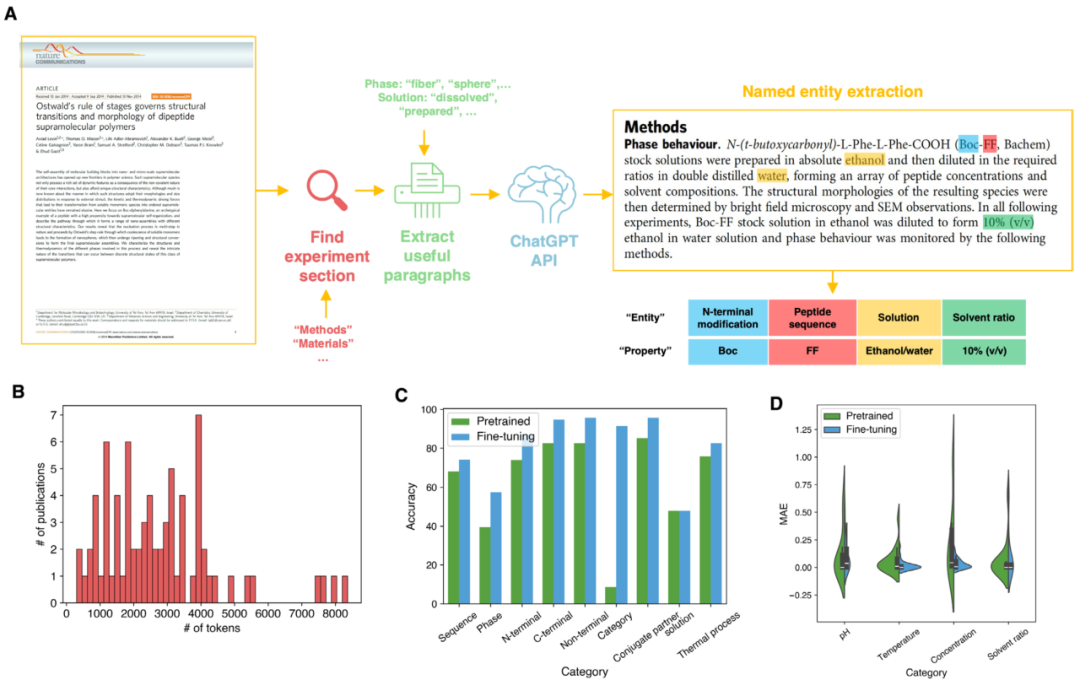
图 4
尽管人类专家手动从文献中提取数据能提供高准确度,但这种方式耗时且劳动密集。为了简化信息提取过程并提高数据收集效率,作者在此实施LLM用于自动挖掘多肽自组装文献,并进一步使用作者手动整理的数据库来微调和评估LLM的性能。LLM辅助文献挖掘的整体工作流程如图4A所示。作者首先从不同期刊出版商下载75篇学术出版物的PDF文件,然后使用PDFMiner Python包将PDF文件转换为文本。接着,通过搜索诸如"Material(s)"、"Method(s)"和"Experimental section/detail(s)"等章节标题来定位整个文本文档中的实验部分。如果没有找到章节标题,则保留所有文本以供进一步处理。之后,作者根据与目标收集信息相关的关键词出现来收集相关段落。例如,作者收集包含"fibers"和"hydrogel"等关键词的段落,以获取与自组装相关的内容。最后,作者将摘要文本添加到处理后的主要文本中,摘要提供了每篇科学论文的概述。作者对文本进行预处理以减少文本输入量,从而满足LLM训练和推理的token(单词数量)限制,并提高文献数据挖掘的效率。
75篇出版物预处理后的token数量分布如图4B所示。作者使用OpenAI API调用GPT模型从这些处理过的文本中提取信息。该任务被称为命名实体识别(NER),它从文本中识别并将关键信息元素分类为预定义类别(图4A)。为了提高模型在肽类文献挖掘命名实体识别方面的性能,作者使用肽类数据库对GPT模型进行微调。肽类数据库被分为训练集(52篇论文)和测试集(23篇论文)。鉴于大多数出版物产生多个数据条目,作者将来自同一出版物的所有数据条目合并为单一输出,使GPT模型能够更好地从单篇论文中提取多组目标实体。作者通过评估原始和微调后的GPT模型在手动整理数据集的测试论文上的预测准确性来比较它们的性能。
针对九个分类特征,作者将LLM的性能评估视为真假任务,比较LLM提取的特征与人类专家识别的特征。微调后的LLM在所有九个分类特征上明显优于预训练模型,平均准确率超过80%。相比之下,原始GPT模型仅达到62.7%的平均准确率。更具体地说,微调显著提高了分类查询预测的准确性。例如,识别特征"类别:肽/共轭物/混合物"(用于确定肽系统是由单一肽、共轭物还是混合物组成)的准确率在微调后从不到10%提高到超过90%。然而,微调并未改善模型提取"溶液"特征信息的能力。这一局限性源于几个因素:(i)"溶液"通常涉及多种化学物质,使全面信息的捕获变得复杂;(ii)在作为输入的处理文本中,关于溶液的信息经常稀疏或缺失(而是出现在图表中),这使得准确提取具有挑战性。
在数值特征方面,作者计算提取值与真实值之间的平均绝对误差(MAE),以比较有无微调的LLM的准确性。如图4D清晰展示,微调后的模型不仅获得了较低的MAE值,还表现出比预训练模型更窄的误差分布。这表明微调提高了GPT-3.5 turbo模型在肽文献挖掘方面的准确性和鲁棒性。通过作者微调的LLM,作者可以显著提高肽自组装规则学习数据集整理的效率。此外,由于实验条件对科学研究至关重要,这一工作流程可以适用于其他物理科学领域。
编译|黄海涛
审稿|王梓旭
参考资料
Yang, Z., Yorke, S. K., Knowles, T. P., & Buehler, M. J. (2025). Learning the rules of peptide self-assembly through data mining with large language models. Science Advances, 11(13), eadv1971.
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢