
DRUGAI
大型语言模型(LLMs)正日益推动医疗应用的发展。然而,GPT-4o 等专有模型由于无法在医疗机构内部部署,难以满足严格的数据隐私法规,限制了其在临床中的实际应用。相比之下,DeepSeek 等开源模型因支持在具备 IT 基础设施的医院内部进行高效微调,成为更具前景的替代方案。为验证 DeepSeek-V3 与 DeepSeek-R1 的临床实用性,研究人员将其在临床决策支持任务中的表现与 GPT-4o、Gemini-2.0 Flash Thinking Experimental 等专有模型进行基准对比。结果基于125个涵盖常见与罕见疾病的真实病例,具备统计学效力,显示 DeepSeek 模型整体表现与专有模型相当,部分情境下更优。本研究表明,开源 LLM 有望在符合法规要求的前提下,为真实世界医疗应用提供可扩展且安全的技术路径。

大型语言模型(LLMs)正在迅速成为医学领域的变革性工具,显示出在多种临床应用中的潜力。其处理和理解复杂医学信息的能力,为提升临床决策效率、自动化管理任务以及改善患者护理提供了新机遇。LLMs 能够分析大量电子健康记录中的非结构化数据,为临床医生在诊断与治疗中提供高效的信息支持。随着人工智能技术的不断成熟,这些模型有望在快速发展的医学知识背景下,成为提升医疗服务质量的重要助力。
然而,LLMs 融入临床实践仍面临诸多挑战,需充分考虑验证流程和伦理问题。若要在临床常规中广泛应用,这些模型必须符合如 GDPR 和 HIPAA 等数据隐私法规,以及欧盟 MDR 与美国 FDA 等医疗器械相关法规。也就是说,模型应具备可解释性、可审计性,并严格符合医疗监管标准——这是目前多数专有模型尚未满足的条件。数据隐私、算法偏差,以及生成不准确或误导性内容的风险依旧令人担忧。患者使用生成式人工智能所带来的新挑战也进一步突显了建立稳健验证体系和明确实施指南的必要性,以确保 LLM 在临床环境中的安全与有效应用。
尽管开源 LLM 在 lmarena.ai 等基准测试中的表现长期不及 GPT-4o 等专有模型,但这一差距正在迅速缩小,尤其是随着 Llama 3.1 和 Mistral Large 2 等开源模型的发布。近期,一些先进开源模型如 DeepSeek-V3 和 DeepSeek-R1 相继问世,与此同时,具有显式推理能力的模型如 Gemini-2.0 Flash Thinking Experimental(Gem2FTE)与 OpenAI o1 也引起广泛关注。DeepSeek 模型参数规模超过5000亿,与专有模型相当,同时具备透明性和本地部署能力,可在医院自有 IT 环境中运行,显著降低部署成本。尽管主流排行榜评估的是通用任务表现,但关键问题仍在于这些开源模型是否能在实际临床任务中,如鉴别诊断和治疗决策等方面匹敌专有模型,并在临床工作流中体现出推理能力的优势。
为此,研究人员对开源和前沿专有 LLM 进行了系统性的临床决策支持任务性能评估。评估内容涵盖诊断与治疗推荐任务,对象包括 DeepSeek-V3、DeepSeek-R1,以及当前 LLM 排行榜上表现突出的 GPT-4o 与 Gem2FTE。
尽管 LLM 在选择题类基准测试中表现优异,但其在临床决策支持中的评估仍然较为有限。目前尚无公认的标准基准用于衡量 LLM 的临床实用性。研究人员采用一套精心整理的110个病例集进行对比分析,该数据集最初用于评估 GPT-4、GPT-3.5 和 Google 搜索在临床决策中的表现。与自动化选择题不同,此基准由医学专家手动评估模型生成的文本内容。这些病例主要来自医学教科书,模拟门诊或急诊等初诊情境,仅包含医生与患者对话的关键信息,既贴近真实临床情境,也考验模型在信息不完整背景下的实用表现。模型输出结果由医学专家基于5分李克特量表评分。
本研究重点关注诊断与治疗推荐两个核心任务,因其对患者预后影响最显著,同时也更容易出错,常被纳入不良事件分析与指南制定框架。为涵盖更广泛场景,病例涵盖内科、神经科、外科、妇科及儿科多个专科,包含常见病、较少见疾病及罕见病,确保疾病频率均衡。为提升统计效力,研究将基准集扩展至125例,便于在系统配对模型比较中进行显著性检验并进行多重检验校正。
在诊断任务中(图1),Gem2FTE 明显劣于 DeepSeek-R1 和 GPT-4o,而 DeepSeek-R1 与 GPT-4o 表现相当。所有新模型在诊断方面的表现均明显优于 GPT-4、GPT-3.5 和 Google,在多个专科下的表现均较一致。在诊断罕见疾病方面,各模型表现基本一致,仅 Gem2FTE 显著下降。值得一提的是,相较于此前研究中 GPT-4、GPT-3.5 和 Google 搜索在罕见病诊断中表现不佳的结论,本研究模型在此方面展现出更好的适应性。此外,DeepSeek-R1 并未在诊断上超越 DeepSeek-V3,两者表现无显著差异。
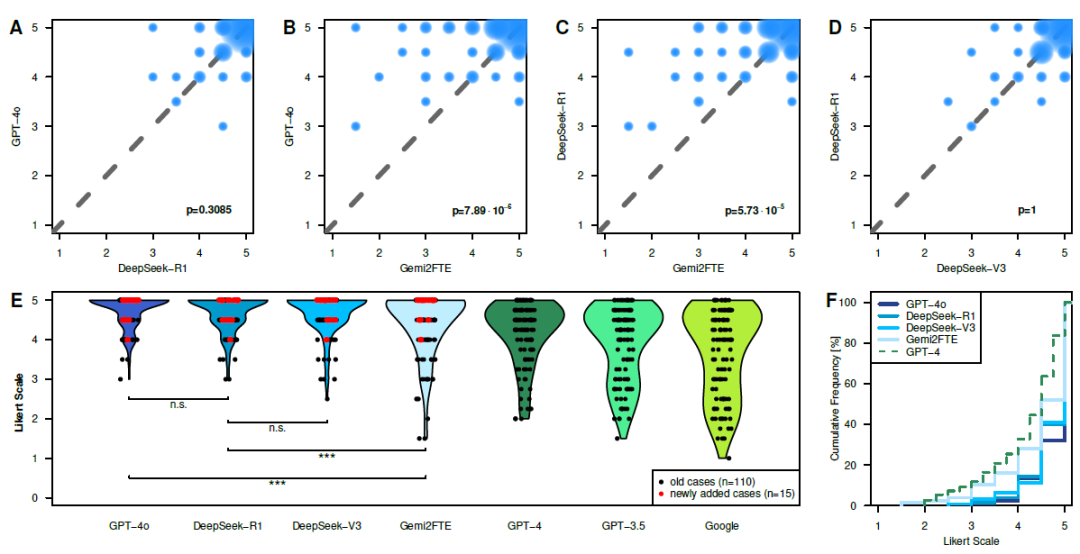
图1:模型在诊断任务中的表现
在治疗推荐任务中(图2),GPT-4o 与 DeepSeek-R1 均优于 Gem2FTE,且 GPT-4o 与 DeepSeek-R1 表现相当。与此前基准中的 GPT-4 与 GPT-3.5 相比,GPT-4o 与 DeepSeek-R1 表现更佳,而 Gem2FTE 并无优势。各模型在不同专科下表现大致均衡,仅 Gem2FTE 在神经科治疗推荐中存在显著劣势。
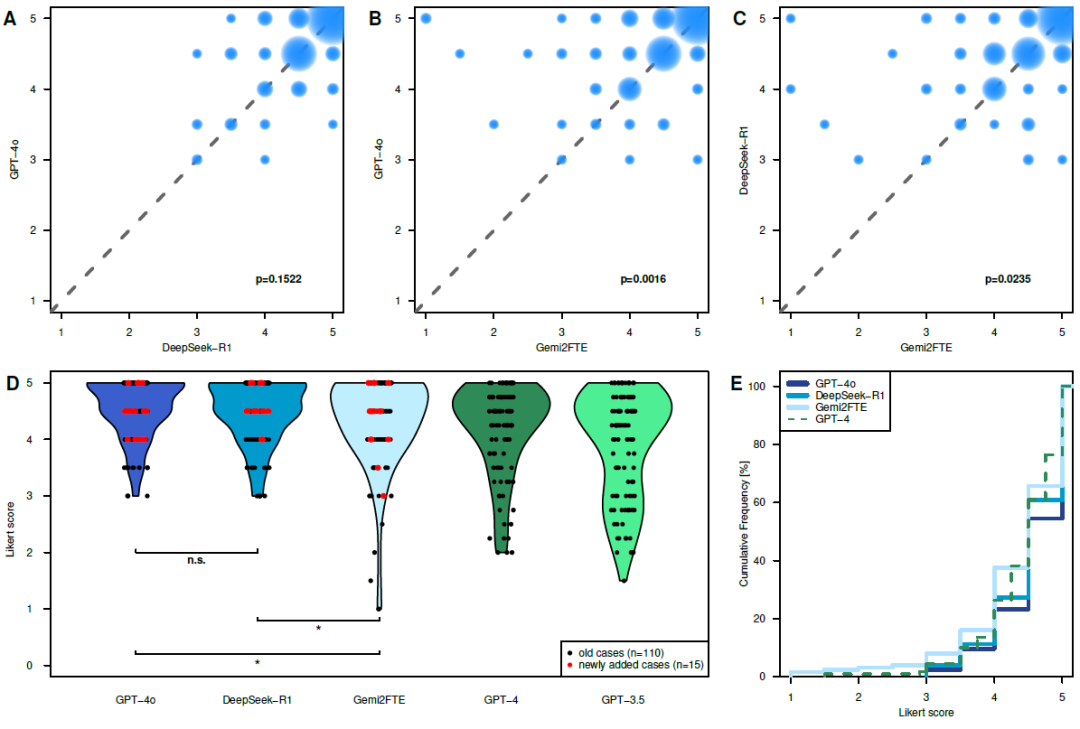
图2:模型在治疗推荐任务中的表现
DeepSeek-V3 与 DeepSeek-R1 在两个关键临床任务中的出色表现,与 GPT-4o 不相上下,说明开源 LLM 有望作为诊断、鉴别诊断及治疗推荐的辅助工具。令人意外的是,Gem2FTE 虽在通用榜单中排名领先,却在临床任务中表现不佳,可能与其模型体量小于其他模型有关。而 DeepSeek-R1 所增加的推理模块也未带来明显优势,反而增加了文本长度,降低了简洁性。其推理训练偏向数学、编程和逻辑等可验证任务,当前尚未显著提升其临床推理能力。因此,未来可通过基于临床数据的专属微调来提升诊断与治疗推荐效果。
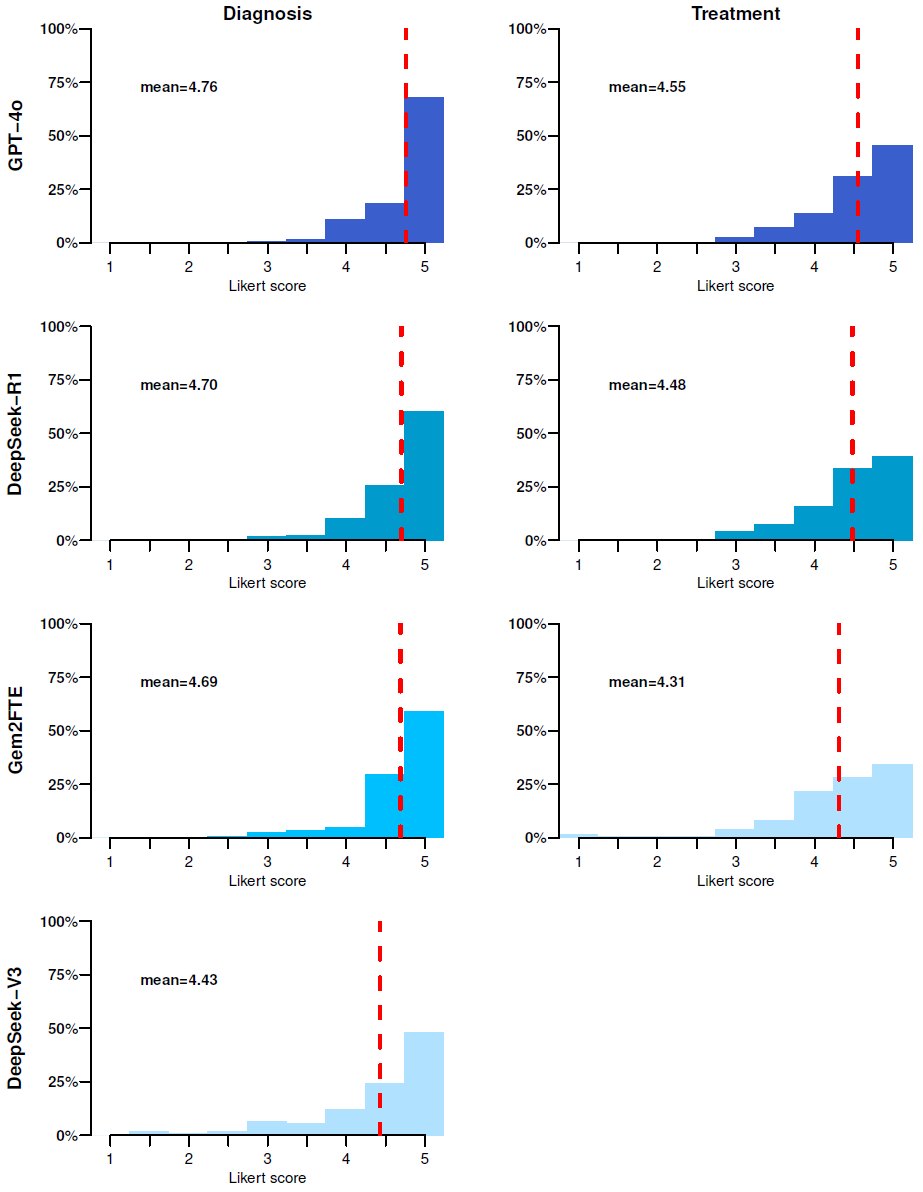
在诊断任务中,DeepSeek-R1 平均得分为 4.70(满分5分);治疗推荐中为 4.48。虽然部分推荐内容精准且紧跟医学指南更新(如抗菌治疗方案),但仍有不少情况未达到满分。以 DeepSeek-R1 为例,仅60%的诊断输出获得满分,治疗推荐中这一比例为39%。这表明若缺乏临床专家监督,模型的不准确信息可能带来潜在风险。所幸“人工幻觉”现象在所有模型中仅在少数案例中出现。
虽然本研究评估任务仍为临床应用的一部分,但结果已表明开源模型在诊断与治疗推荐方面具有辅助潜力。研究人员认为,结合权威医学文献、数据库支持、人类监督与透明训练流程,将进一步提升模型表现与稳健性。总之,本研究表明,开源 LLM 是具备现实可行性的临床辅助工具,在保障数据隐私和合规前提下,为医院量身定制、可安全部署的模型训练与应用提供了可扩展路径。未来还需开展更多临床研究,验证此类技术能否真正改善患者预后。
整理 | WJM
参考资料
Sandmann, S., Hegselmann, S., Fujarski, M. et al. Benchmark evaluation of DeepSeek large language models in clinical decision-making. Nat Med (2025). https://doi.org/10.1038/s41591-025-03727-2
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢