

速览热门论文
2.DeepMind:LLM 是贪婪的 agent
3.MIT 打造机器学习版「元素周期表」
4.字节推出高保真「人脸变换模型」DreamID
1.Meta:利用自回归模型生成高分辨率图像
自回归(AR)模型在语言生成领域长期占据主导地位,近年来也逐步扩展至图像合成任务。但相较于扩散模型,AR 模型通常被认为在生成质量和效率方面存在劣势,主要原因在于其需处理大量图像 token,导致训练和推理成本高,且限制了生成分辨率。
为了解决这个问题,Meta 团队提出了一种新颖、简单的方法 Token-Shuffle,旨在减少 Transformer 中的图像 token 数量。该方法的核心基于对多模态大语言模型(MLLM)中视觉词汇维度冗余的观察:即视觉编码器生成的低维视觉特征可直接映射到高维语言词汇空间。利用这一点,他们考虑了两个关键操作:
token-shuffle:在输入阶段沿通道维度合并空间局部 token,从而显著降低输入 token 数量;
token-unshuffle:在 Transformer 模块后对预测 token 进行还原,恢复其空间结构以生成最终图像。
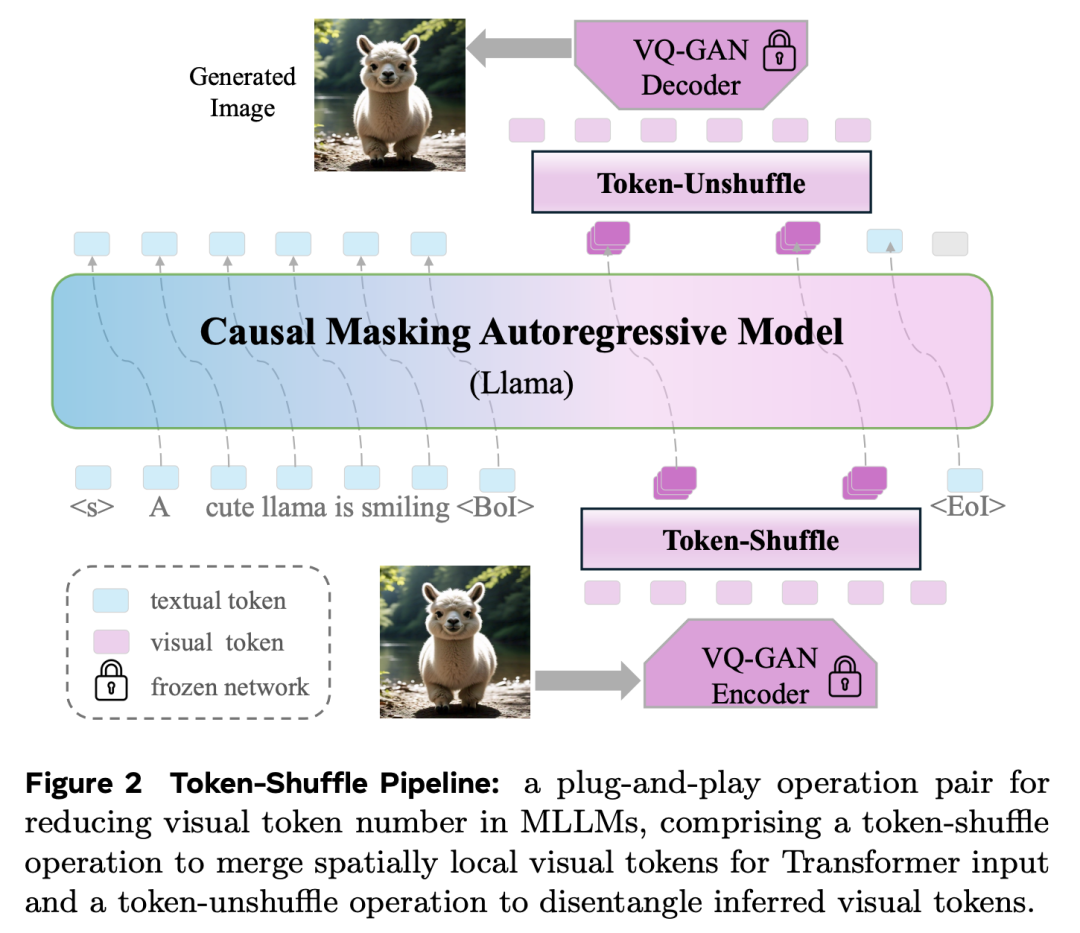
该方法支持与文本提示联合训练,无需额外预训练文本编码器,就可以在保持高效训练与推理的同时,实现统一的“下一个 token 预测”式高分辨率图像生成。
他们首次将自回归文本到图像生成的分辨率提高到了 2048x2048,并取得了令人满意的生成性能。在 GenAI 基准测试中,2.7B 模型在高难度文本提示上获得了 0.77 的总分,比自回归模型 LlamaGen 高 0.18,比扩散模型 LDM 高 0.15。大规模人工评估结果亦表明,其在文本对齐、图像质量与视觉表现方面具有显著优势。
研究团队表示,Token-Shuffle 有望成为 MLLM 架构中高效、高分辨率图像生成的一项通用设计。
论文链接:https://arxiv.org/abs/2504.17789
2.DeepMind:LLM 是贪婪的 agent
大语言模型(LLM)利用常识和思维链(CoT)推理,可以有效地探索和高效地解决复杂领域的问题。然而,人们发现 LLM agent 存在次优探索和“知行差距”,无法根据模型中的知识有效地采取行动。
在这项工作中,Google DeepMind 团队系统地研究了 LLM 在决策场景中表现次优的原因。特别是,他们仔细研究了 3 种普遍存在的失败模式:贪婪、频率偏差和知行差距。他们建议通过对自生成的 CoT 推理依据进行强化学习微调来缓解这些缺陷。
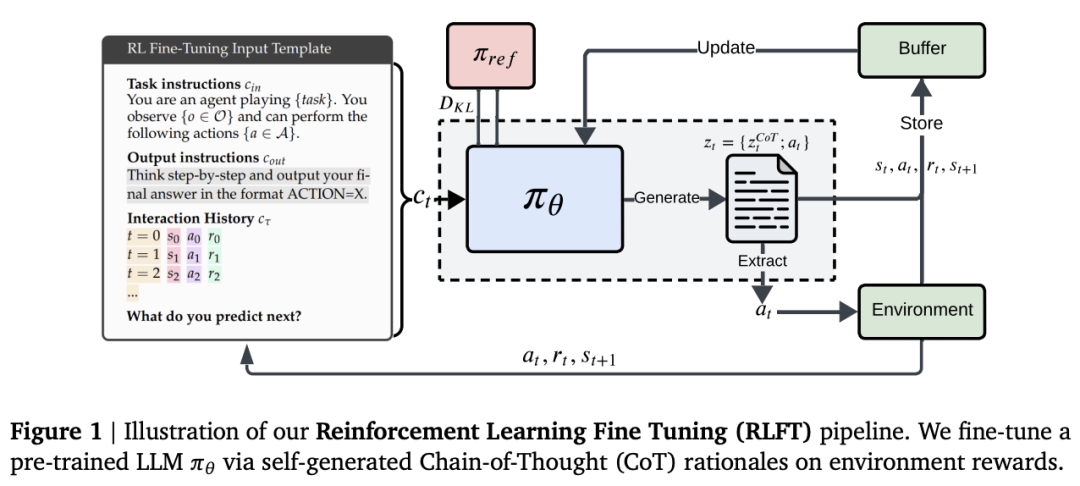
他们在多臂老虎机、情境式老虎机和井字棋中进行的实验表明,强化学习微调通过增加探索和缩小知行差距,提高了 LLM 的决策能力。
最后,他们研究了传统的探索机制(如 ϵ-greedy)和 LLM 特有的方法(如自我校正和自一致性),以便在决策中对 LLM 进行更有效的微调。
论文链接:https://arxiv.org/abs/2504.16078
3.MIT 打造机器学习版「元素周期表」
随着表征学习领域的发展,出现了大量不同的损失函数来解决不同类别的问题。
在这项工作中,来自 MIT、谷歌和微软的研究团队提出了一个单一的信息论方程,它概括了机器学习中大量的现代损失函数。特别是,他们提出的框架表明,几大类机器学习方法都在精确地最小化两个条件分布(监督表征和学习表征)之间的综合 KL 发散。这一观点揭示了聚类、谱方法、降维、对比学习和监督学习背后隐藏的信息几何。
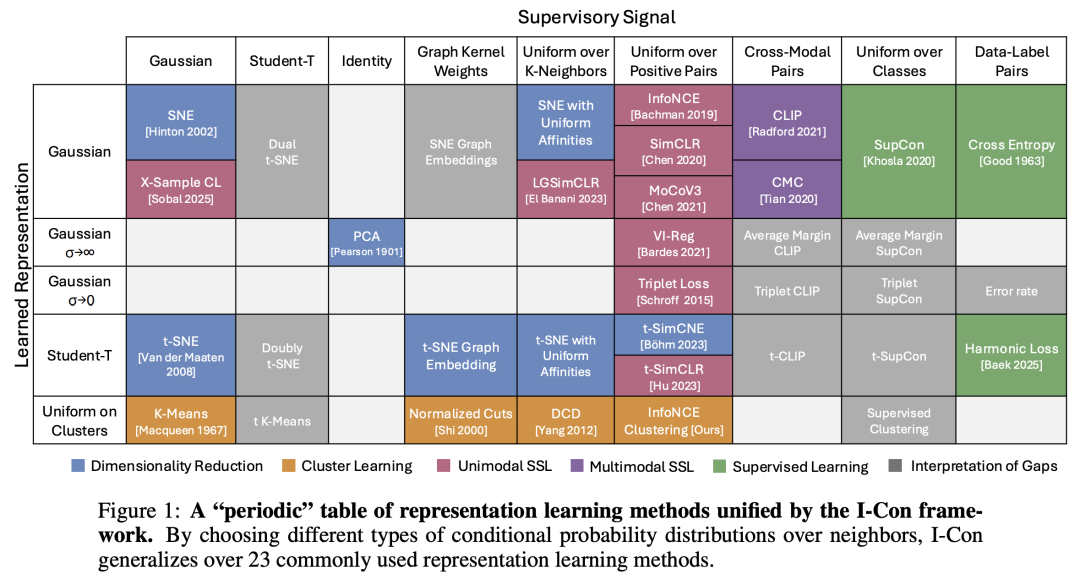
通过结合以往其他技术,这一框架开发出了新的损失函数。他们不仅提出了一系列证明,将超过 23 种不同的方法联系在一起,而且还利用这些理论成果创建了 SOTA 无监督图像分类器,在 ImageNet-1K 上的无监督分类方面比之前的 SOTA 方法提高了 8%。
他们还证明,I-Con 可以用于推导有原则的去偏(debiasing)方法,从而改进对比表示学习方法。
论文链接:https://arxiv.org/abs/2504.16929
4.字节推出高保真「人脸变换模型」DreamID
在这项工作中,字节团队提出了基于扩散的人脸变换模型 DreamID,它能够实现高水平的 ID 相似性、属性保留、图像保真和快速推理。
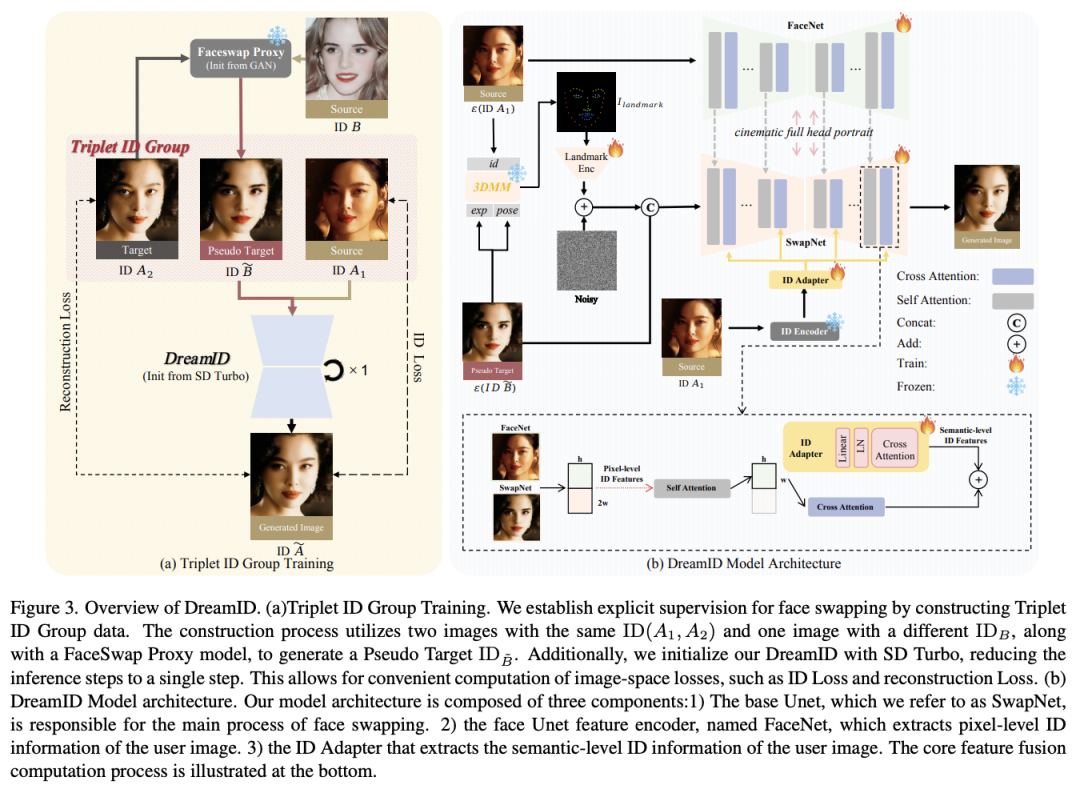
典型的人脸变换训练过程通常依赖于隐式监督,很难取得令人满意的结果,与之不同,DreamID 通过构建三重身份组数据,为人脸交换建立了显式监督,大大提高了身份相似性和属性保持性。
扩散模型的迭代特性为利用高效的图像空间损失函数带来了挑战,因为在训练过程中执行耗时的多步采样以获取生成的图像是不切实际的。为此,他们利用加速扩散模型 SD Turbo,将推理步骤减少到单次迭代,实现了高效的像素级端到端训练,并具有明确的三重 ID 组监督。
此外,他们还提出了一种改进的基于扩散的模型架构,包括 SwapNet、FaceNet 和 ID Adapter。这种鲁棒的架构充分释放了三重 ID 组显式监督的能力。
最后,为了进一步扩展这一方法,他们在训练过程中修改了三重 ID 组数据,以微调和保留特定属性,如眼镜和脸型。
广泛的实验证明,DreamID 在身份相似性、姿势和表情保持以及图像保真度方面实现了 SOTA。
论文链接:https://arxiv.org/abs/2504.14509
整理:学术君
如需转载或投稿,请直接在公众号内留言

内容中包含的图片若涉及版权问题,请及时与我们联系删除


评论
沙发等你来抢