

在数字化转型与 AI 爆发的时代,数据已成为企业最核心的战略资产。如何高效管理、分析并挖掘数据价值,成为科技公司竞争的关键赛道。Databricks 作为数据与 AI 领域的代表性企业,从开源项目 Spark 起步,逐步发展为估值超 600 亿美元的行业巨头,其成长历程不仅折射出大数据技术的演进史,更揭示了科技公司如何通过连续的战略跃迁实现指数级增长。
本文以 S 曲线理论为分析框架,深度解构 Databricks 的三次关键战略跃迁,还原了其技术商业化路径中的关键决策——如拒绝本地化部署的短期利益、与微软 Azure 的生态合作以及从开源社区到企业级服务的平衡艺术。在研究 Databricks 当前战略时,作者指出其三大核心布局:通过湖仓一体架构实现数据平台整合,构建开源分发网络形成生态壁垒,以及转向为 AI 数据库。
Databricks 的特别之处在于,它既抓住了大数据、云计算、AI 三次技术浪潮的叠加红利,又通过平台化战略将短期技术优势转化为长期生态护城河。面对未来,其挑战不在于生存,而在于能否在 AI 应用爆发期成为底层基础设施——正如 CEO Ghodsi 所言,“让 Databricks 成为所有 AI 应用背后的数据库”。Databricks 完美诠释了从 SaaS 转向 AI 的 S 型曲线跃迁,对科技领域创业者具有战略参考价值。
(本文经授权后由 OneFlow 编译。原文:https://www.generativevalue.com/p/databricks-and-the-future-of-data-369)
作者 | Eric Flaningam
OneFlow 编译
翻译|张雪聃
题图由 SiliconCloud 生成
1
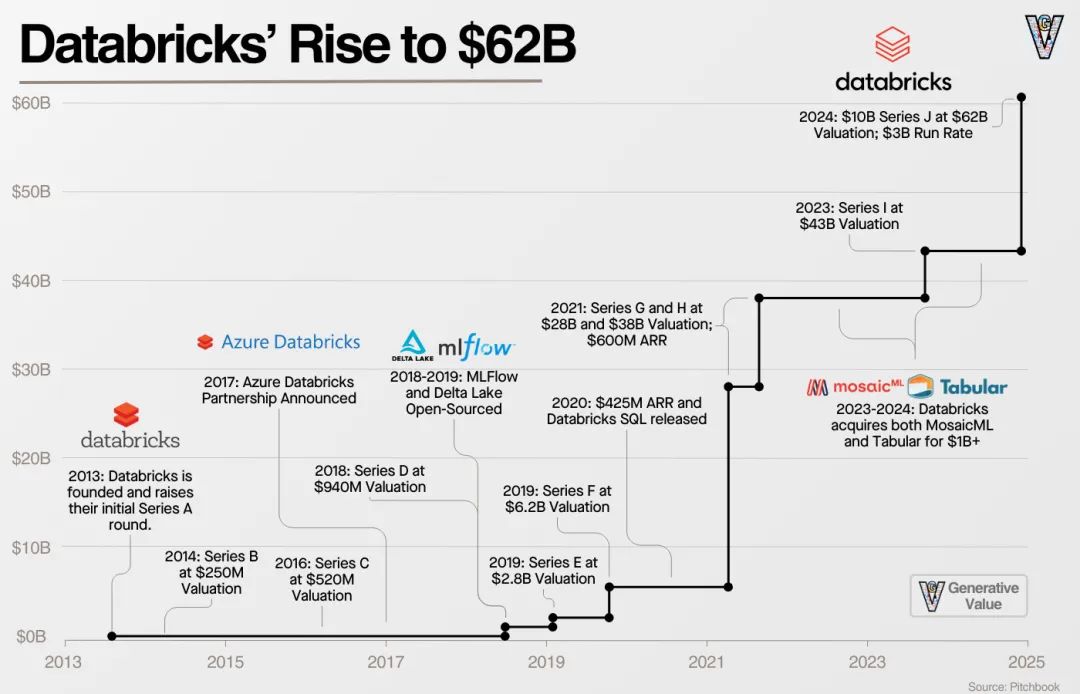
Databricks 的发展历程
Netflix 大奖赛
有些故事本身就精彩得无需润饰,Databricks 的创立历程正是这样一个例子。
2006 年,Netflix 面向所有能够将其推荐算法准确率提升 10% 的团队或个人发起了一项名为 “Netflix Prize” 的竞赛,奖金高达 100 万美元。
当时的背景是:互联网的迅速发展催生了海量数据,尤其是非结构化数据。企业开始探索如何更高效地利用这些数据。要实现这一点,企业必须能够存储数据、编写算法,并将算法运行在这些数据之上,这对计算能力提出极高要求。当时的主流技术是 2006 年发布的 Hadoop,但 Hadoop 运行效率低,用起来相当复杂,难以真正满足“大数据时代”的实际需求。

Databricks A轮融资路演材料
因此,Netflix 需要一种更高效方式来运行算法。到 2009 年,已经有大约 5 万人报名参加了这场比赛,但仍然没有人真正达到那 10% 的改进目标。Netflix 提供的数据集规模巨大:包含 1.8 万多部电影、超过 1 亿条评分记录,以及 45 万名用户的数据。
当时,加州大学伯克利分校的博士生 Lester Mackey 决定参赛,但他很快就遇到了一个问题:没有任何工具能够高效处理这么大的数据集。他的同班同学 Matei Zaharia(如今已是数据界传奇人物)开发了一个新工具,用来更高效地处理算法。这个工具就是 Spark 的前身。
Mackey 借助 Zaharia 开发的工具,对整个数据集进行了多轮迭代,最终实现了 Netflix 期望的 10% 准确率提升。不幸的是,他们的提交时间晚了 20 分钟,最终大奖被 AT&T 的一个团队夺走。(不禁让人想起龟兔赛跑的古老寓言)
Spark 崛起与 Databricks 的创立
在这个阶段,Zaharia 在 Yahoo 工作时发现了大数据处理的问题。作为 Hadoop 早期贡献者,他深知其不足之处。于是,他决定与伯克利 AMPLab 的学术伙伴们联手共同开发 Spark,并通过 Databricks 将其商业化。

Databricks A轮融资路演材料
Databricks 的早期愿景与如今的目标非常相似:提供一个统一的分析平台,赋能人工智能。
我们不妨退一步思考:为什么 Databricks 需要存在?这可以归结为两个问题:
1.为什么需要 Spark?
当时,大数据处理非常困难,而且未来会越来越难。如果企业想要从海量数据中提取有价值的信息,就需要像 Spark 这样的工具。
推动力#1:大数据。
2.为什么需要 Databricks?
其次,Databricks 团队很清楚:管理大数据将变得越来越困难。云计算从根本上解锁了可以独立扩展计算和存储能力的可能,而且几乎可以实现无限计算和存储。虽然开源软件强大,但管理起来非常复杂,因此,Databricks 既拥有 Spark 的强大功能,又具备托管云软件的操作简便性。
推动力#2:云计算。
Databricks 甚至在年收入仅为 1000 万美元时拒绝了一家金融服务公司提出的 2000 万美元报价,拒绝提供本地部署版本。

Databricks A轮融资路演材料
他们将 Databricks 描述为一个“让简单的事情变得简单”并且“让复杂的事情成为可能”的工具。简而言之,相比 Hadoop,Spark 让大规模计算负载更快速且更具成本效益。Spark 驱动程序接收用户编写的程序,并将需要执行的任务分配出去。集群管理器为任务分配所需的资源,而执行器根据任务进行处理。
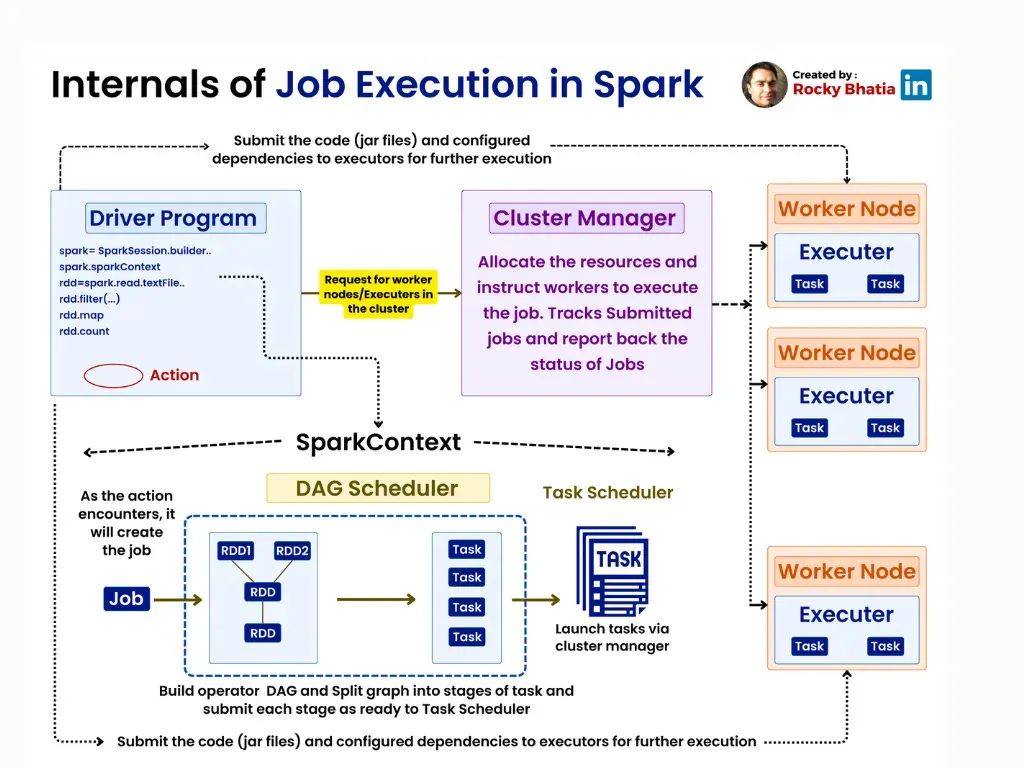
来源: https://rockybhatia.substack.com/p/apache-spark-explained-architecture
由于机器学习负载非常依赖计算资源,Databricks 最初的客户群体都是大型公司的数据科学家和机器学习工程师。相反,Snowflake 的负载更侧重于商业智能。
值得注意的是,Spark 是一个处理框架,而不是数据库。因此,它是一种分配计算负载的方式,并不用于存储数据。它位于 S3 这样的原始对象存储之上,通常运行结构化和半结构化数据的负载。Snowflake 等工具的核心价值却完全不同,它们一开始就是为结构化数据而设计的数据仓库。
Sparks 快速发展…Databricks 也实现了飞跃
2013 年到 2015 年,Databricks 团队一直持续推动 Spark 项目,寻找那个人人都在说却很难真正抓住的“产品市场契合度”。
2015 年,正如 Ghodsi 所说:“Spark 爆火了……那时,我们感觉自己已经成功了,但还没有盈利。那时我们进入了困难期,我们不得不思考,如果不能盈利,或许是一地鸡毛。公司经历了一段内省期。”
随后,Ali Ghodsi 于 2016 年接任 CEO,领导团队也发生了变化,Databricks 引入了一支具有企业软件销售经验的团队。

Databricks B 轮融资路演材料
绝大部分创始团队成员至今仍在公司留任(且持续参与决策),他们主导技术研发,而新团队则专注于技术商业化落地。
这场转型的一部分,就是 Databricks 在一定程度上弱化其开源属性。Ghodsi 坦言:"我们必须拥有自己的独家秘方——那些不能轻易让超大规模云服务商获取的核心技术。这一转型至关重要却也困难重重......但这是通向成功的唯一路径。若非这次战略转向,我们可能早已不复存在。"
推动力#3: 开源的崛起
开源技术的商业化至今仍是初创企业面临的难题,且没有放之四海而皆准的解决方案。但 Databricks 决定将更多 Spark 的功能转为专有功能,以此构建面向客户的独特价值主张。
那么 Databricks 如何盈利?由于不直接存储数据,其营收主要来自计算成本的高额溢价。这种模式建立在云基础设施提供商之上,因此 Databricks 还能在供应商成本基础上再加收一层溢价。鉴于大数据业务的特性,其主要客户群体为大型企业或拥有海量数据的初创公司。
自此,Databricks 的业务开始腾飞。
Databricks B 轮融资演示材料
2017 年,Databricks 做出了一项极具战略眼光的决定——与 Microsoft Azure达成合作。双方联合开发了一款产品,Microsoft 的客户可以直接购买 AzureDatabricks,并与 Azure 的其他服务进行集成,Databricks 和 Microsoft 双方都能从中获得收入。Databricks 借助 Microsoft 的分销网络和销售团队,将自家的技术植入到微软的客户体系中,从而扩大了自身影响力。
这一合作模式的成功经验,很可能为后来微软与 OpenAI 的合作提供了重要参考。
Databricks 主流化
在接下来的五年里,Databricks 完成了五轮融资,估值从 5.2 亿美元飙升至 280 亿美元:
2018 年 D 轮融资 1.4 亿美元
2019 年 E 轮融资 2.5 亿美元
2019 年 F 轮融资 4 亿美元
2021 年 G 轮融资 10 亿美元
2021 年 H 轮融资 16 亿美元,估值达 280 亿美元
在此期间,公司持续推进其核心战略——平台化发展,并发布了开源数据/AI 社区的两大支柱产品:Delta Lake 和 MLflow。
MLflow 提供了构建机器学习模型的开源框架。Delta Lake 则采用 "开放表格式",通过存储数据湖中的元数据,显著提升了数据组织和处理效率。
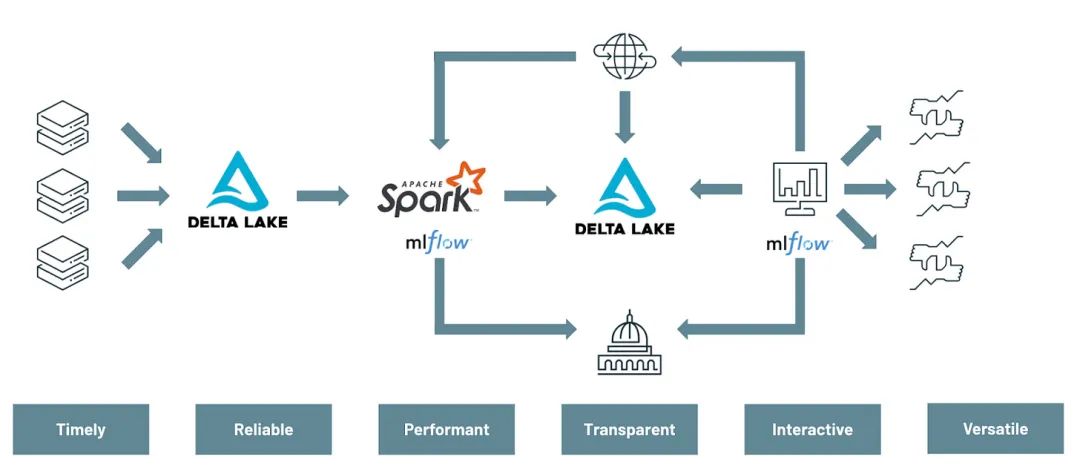
或许最重要的是,这为 Databricks 的“数据湖仓一体(data lakehouse)”愿景奠定了基础——让我们回到 2013 年 Databricks 的宏伟蓝图:建立一个统一的分析平台。
在 2010 年代,数据管理基本沿两条路径发展:一条是用于基于 SQL 分析的数据仓库,一条是用于存储大量非结构化数据的数据湖。但两者都存在明显问题:
数据仓库成本高昂、闭源,且难以处理非结构化数据;
数据湖管理困难,容易导致数据混乱无序。
Databricks 全力推进“数据湖仓一体”愿景,最终将其构想变为现实。湖仓一体架构融合了数据湖与数据仓库,带来三大核心优势:将数据管理集中到统一平台;向开源工具开放数据平台;实现理论上更低的成本。
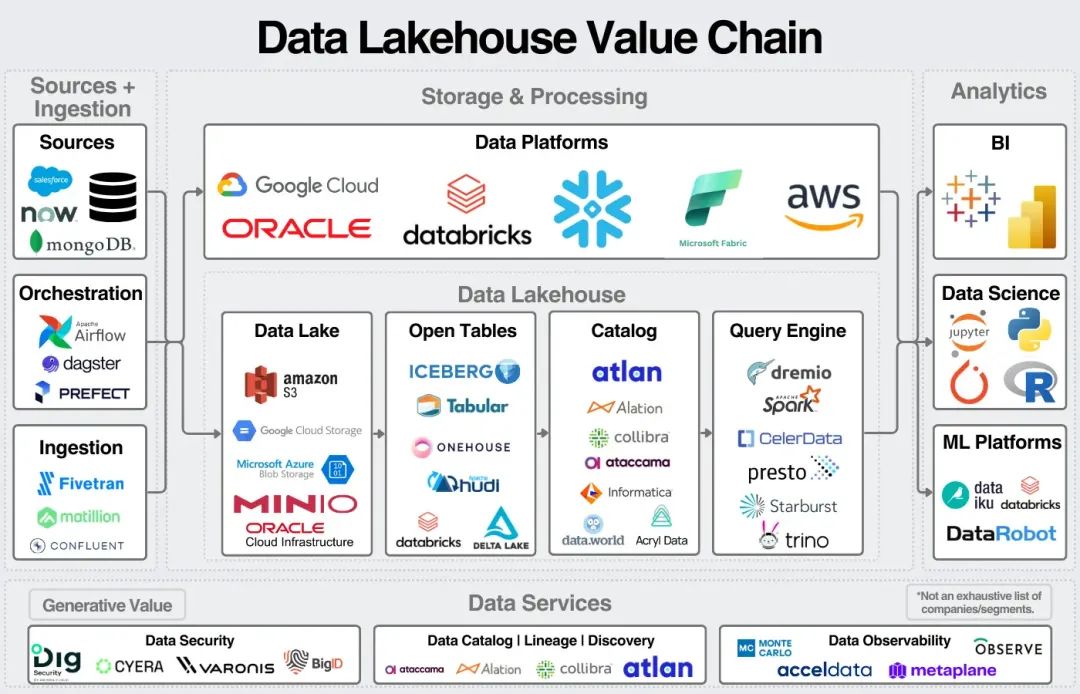
Databricks 在“数据湖仓一体”的市场推广上做得极为出色。这让我们重新聚焦其核心价值主张:通过单一平台管理全量数据,并轻松从数据中获取洞见。
这一主张还为其推出数据仓库产品 Databricks SQL 创造了条件——能够与 Snowflake 抗衡,该产品现已占公司营收的 20%。当企业将全部数据存储于统一平台时,必然需要同时容纳结构化与非结构化数据!
2
Databricks 发展现状
经过在 AI/ML 领域十余年的深耕,当 ChatGPT 引爆行业变革时,Databricks 已占据绝佳战略位置。
过去两年间,公司通过收购与产品迭代,构建了覆盖数据与 AI 全流程的解决方案,包括:数据摄取(Ingestion)、任务编排(Orchestration)、数据转换(Transformation)、分布式处理(Processing)、SQL 数据库服务、全套 AI 工具链(含智能体框架、智能体评估、向量搜索、AI 治理、模型微调服务及托管版 MLflow)。
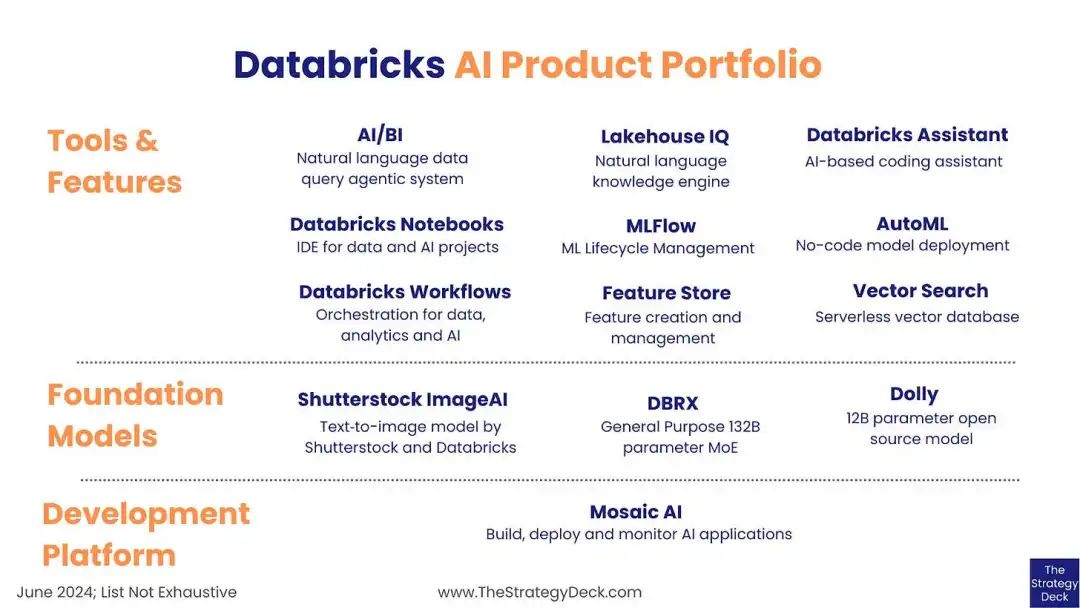
来源:战略路演材料
让我们退一步看,理解这类平台的难点在于其提供的功能十分繁杂。Databricks 的核心其实很简单:它旨在成为数据的统一层,帮助企业从数据中获取洞见。
数据科学:基于托管 Spark 后端运行,通过 Databricks Notebooks 编写代码的数据科学工作
数据仓库:存储所有结构化数据并进行查询
数据工程:数据流水线、流程编排、数据转换
构建自己的AI:传统机器学习(MLflow、特征存储、模型服务、模型训练、模型微调)与智能体(智能体框架、向量存储)
治理与安全:索引所有数据资产(知晓数据位置、内容及访问权限)
上层 AI 应用:据我推测,Databricks 的终极愿景是构建一个数据应用平台(如同一个“数据智能体”)。 你可以向这个数据智能体提出任何问题,它都能为你解答。这正是其自始以来的核心理念:不再局限于追溯“上周发生了什么”,而是前瞻性地预测“下周将会发生什么”。
Databricks 过去的发展历程,最终引领其走向今天的业务现状。2024 年 12 月,该公司成功完成 100 亿美元融资,估值达到 620 亿美元。伴随此次融资,其财务数据也随之可见:
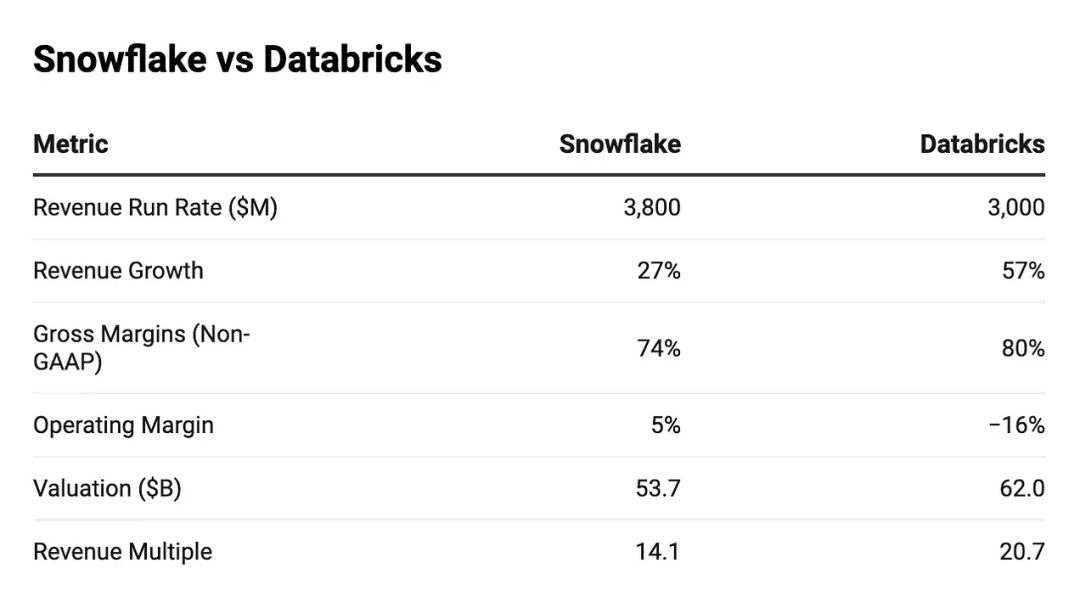
来源:https://www.tanayj.com/p/comparing-the-financials-of-databricks
必须指出,企业数据领域的竞争壁垒极为牢固。Databricks 十年后依旧会屹立不倒,并持续在行业中扮演关键角色。
从投资角度看,不确定性主要来自估值和增长预期。Databricks 年度经常性收入(ARR)已达 30 亿美元,较 2023 年底约 19 亿美元的水平增长 60%。据此计算:
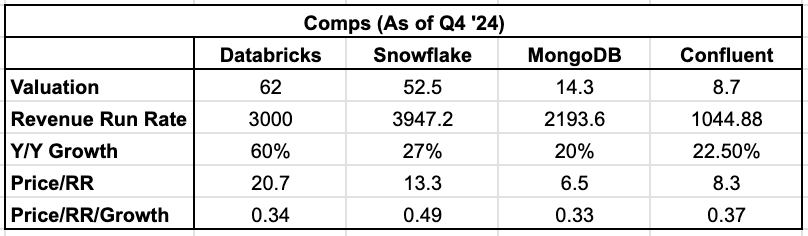
尤为有趣的是,在全行业增长普遍放缓的背景下,Databricks 却呈现出加速增长态势。其年增长率同比提升 10 个百分点,而图表所示其他三家公司的平均年增长率同比下滑约 7 个百分点。这个数据或许印证了:AI 领域确实蕴含着真实的价值潜力!
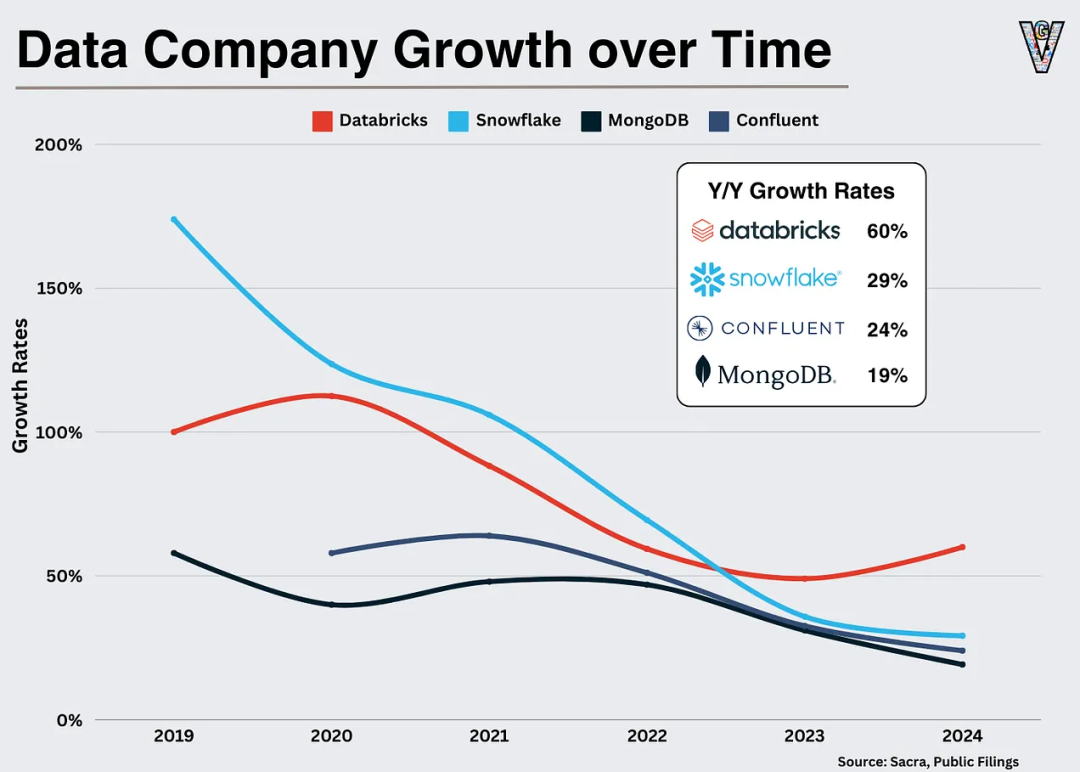
从宏观层面看,关于 Databricks 估值的核心问题可归结为三点:整个行业的增长前景、Databricks 超额增长势头的持续性,以及数据类企业估值倍数的整体收缩或扩大。
我在文章开头曾提到一个核心问题:如何才能有效地把握 S 曲线的成长机会?
3
Databricks 与未来之路
当前,整个企业软件行业正面临两大发展趋势:软件行业整合与 AI 技术崛起。我认为 Databricks 如何驾驭这两大趋势将决定其未来十年的发展轨迹。
在我看来,这可以归结为其战略的三大核心要素:
1. 行业整合期的平台化布局
企业级 SaaS 经过十年狂奔后进入整合期。正如 Redpoint 所言:"市场领导者持续获得超额收益"。
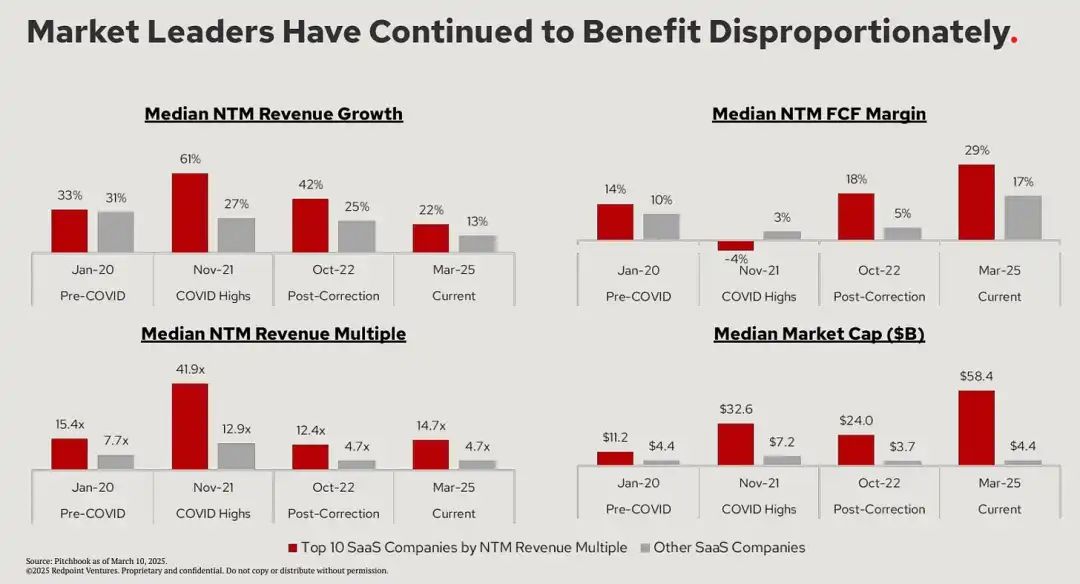
Source: https://x.com/loganbartlett/status/1770544385089994869
这意味着企业需要为其特定客户群打造尽可能宽广的平台生态。Databricks 正是这样实践的:通过持续发布新功能来支持整个数据生态系统。
这点单拎出来已足够强大了,而结合开源战略后便更具威力。
Databricks 的核心竞争力不仅在于平台化,更在于构建开源分发网络。
2. 打造开源数据分发网络
自创立之初,Databricks 就秉持开源优先理念。其早期的价值主张是:开源技术虽好但管理困难,那就让我们来处理这些难题吧。
如今开源生态蓬勃发展,其价值主张演进为:让我们托管所有开源项目,提供企业级管理版本,你只需专注产品创新。
这一策略的妙处在于:开源生态越繁荣,Databricks 发展就越好。由此形成的开源飞轮效应是:用户在平台上使用的开源产品越多,迁移成本就越高。
这正是 Databricks 早年对抗云巨头时运用的策略!
前两项战略(平台化布局与开源分发网络)旨在应对行业整合趋势,而第三项战略(AI 数据库转型)则着眼于行业增长机遇。
3. 转型 AI 数据库
Ghodsi 曾如此描述 Databricks 的未来(https://www.youtube.com/watch?v=pAcF3GV4ygM):"本质上它是个 AI 数据库。虽然我们不用这个称谓宣传,但底层逻辑就是如此。未来每个应用、每家企业都需要这种 AI 数据库。我希望我们能成为支撑所有这些应用的幕后力量。"
要实现这个愿景,Databricks 需要做两件事:吸引初创公司基于其平台开发解决方案;同时为 AI 应用打造尽可能多的原生集成。前者使其能分到 AI 应用浪潮的红利,后者则保护其核心数据业务。
诚如我前文所述, Databricks 十年后不仅会屹立不倒,更将在行业中占据举足轻重的地位。
真正的悬念在于:它的规模能扩张到何种程度,而这完全取决于执行力。
两年前,我曾预测 Databricks 可能创下科技 IPO 规模纪录。这个目标依然可期,据 Pitchbook 数据,Meta 在 2012 年上市时市值 810 亿美元。Databricks 能否在未来以 1000 亿美元市值上市呢?
虽然存在诸多变数,但并非没有可能。

即刻体验DeepSeek R1
cloud.siliconflow.cn
扫码加入用户交流群

内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢