
2025 年 1 月 20 日,DeepSeek 发布了他们最新的开放权重推理模型 DeepSeek-R1,该模型在基准测试性能上与 OpenAI 的 o1 相当。该版本引起了大量争议,最引人注目的是 DeepSeek 可能低估或歪曲了其模型的训练成本。我认为这种说法不可信,原因我将在本期中探讨。
除了关于模型的训练成本之外,我还想澄清我们对模型的架构、训练过程、性能和定价的实际了解。
建筑
DeepSeek R1 的架构与该公司于 2024 年 12 月发布的早期模型 DeepSeek v3 相同。我在两周前的 Gradient Updates 期刊中介绍了该模型的关键架构细节,因此我在这里只提供一个简短的高级总结。
总体而言,该模型是一个非常稀疏的专家混合体,总共有 6710 亿个参数,但每个代币只有 370 亿个活跃的参数。专家分为两类:一类是“共享专家”,每个代币始终路由到该类,另一类是 256 个“路由专家”,其中 8 个对于任何特定处理的代币都是活跃的,并且模型训练试图确保平衡的路由。大多数参数是路由专家的 MoE 参数,我们可以通过以下基于 HuggingFace 的模型配置文件的健全性检查来确认这一点:
路由的 MoE 参数 = (MoE 块) * (路由的专家) * (每个专家的张量) * (MoE 中间维度) * (模型隐藏维度) = 58 * 256 * 3 * 2048 * 7168 = 6530 亿
DeepSeek v3 还使用了一种称为多头潜在注意力 (MLA) 的新机制来减小 KV 缓存的大小,而不会像其他流行的方法(如分组查询和多查询注意力)那样造成性能损失。这是以增加解码过程中注意力的算术成本为代价的,这使得 DeepSeek v3 在其他语言模型中不同寻常,因为它在长上下文推理期间是算术绑定而不是内存绑定。注意力的算术成本变得与参数乘法累加相当,在过去 5000 个令牌的上下文长度附近,相比之下,Llama 3 70B 仅发生在 50,000 个令牌的上下文长度附近。
介绍该方法的 DeepSeek v2 论文中的消融实验表明,使用 MLA 比 GQA 和 MQA 具有显着的性能提升。目前尚不清楚我们可以在多大程度上信任这些结果,但这可能有助于基本模型以相对较低的推理成本获得高质量。
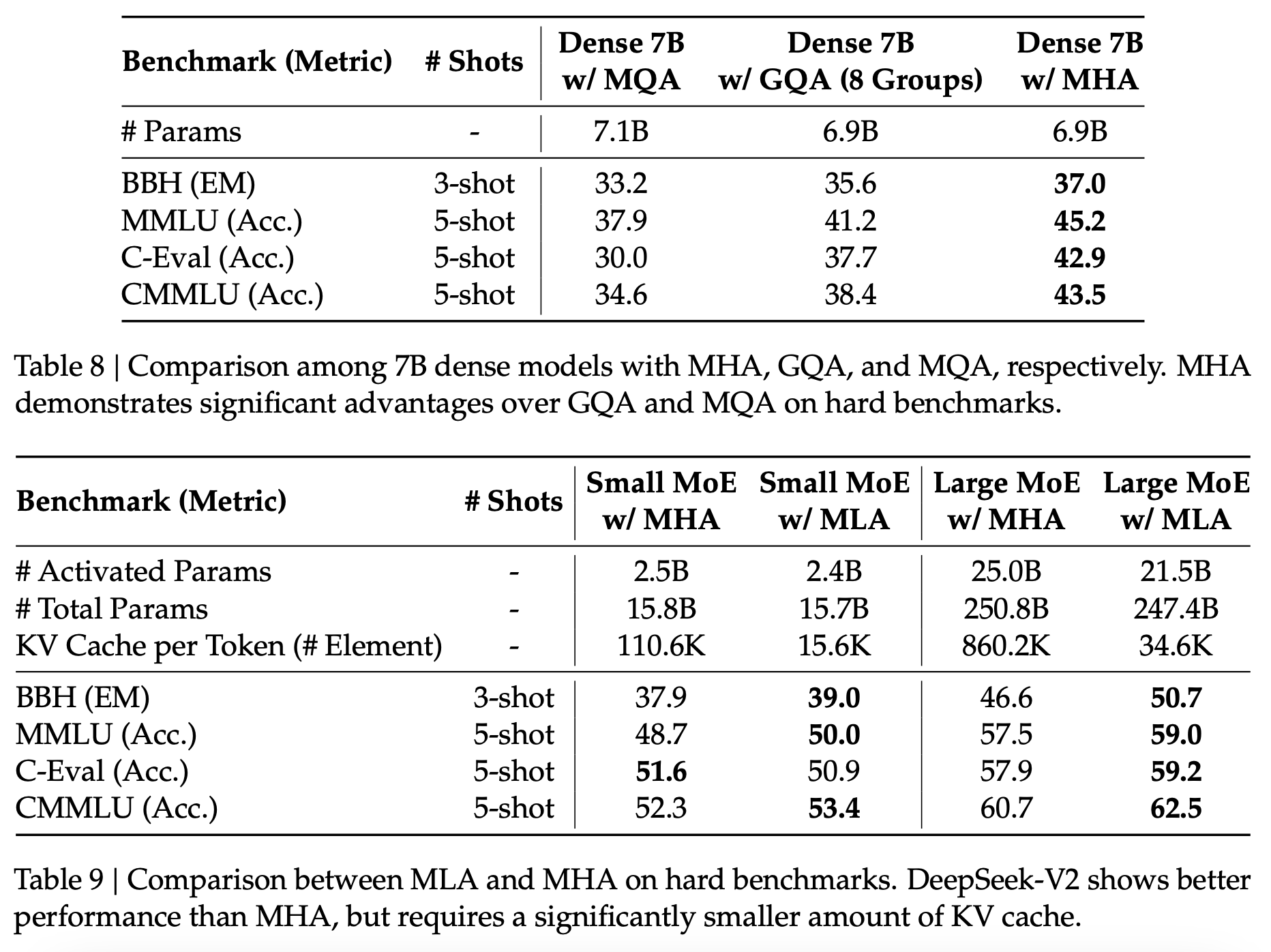
Figure 1: Results of the ablation experiments for attention mechanisms from the DeepSeek v2 paper.
Many of these innovations are quite old: for example, MLA was introduced in the v2 paper which came out in June 2024. The real improvement of R1 over V3 is the use of reinforcement learning to improve reasoning performance, which I will cover in the next section. However, the architecture of the base model still matters because reinforcement learning works much better on base models which already have high intrinsic performance, as this reduces the sparsity of the initial reward signals during RL. So understanding how DeepSeek was able to build a performant base model to build their reasoner on top of is still important.
训练
我看到关于 R1 的公开讨论经常混淆模型训练的预训练和强化学习阶段,因此我想在这里明确区分这两个阶段。
训练前
DeepSeek r1 的预训练运行是 DeepSeek v3。v3 的技术报告提供了有关他们如何训练模型的大量细节:他们在 2048 个 H800 GPU 的集群上使用了混合 FP8 精度训练,在这个集群上处理每万亿个令牌的训练数据需要 3.7 天,因此大约需要 180000 个 H800 小时。他们还表示,他们的总训练数据集大小为 14.8 万亿个代币,这意味着训练成本约为 14.8 * 180,000 = 266 万 H800 小时,如果我们将 H800 小时的成本定价为 2 美元,则约为 5.3M 美元。
对这些数字的怀疑数量令人惊讶,但对于以这种方式训练的具有这种架构的模型来说,这些怀疑是很高的。14.8 万亿个代币的数据集大小是合理的,并且与这种规模的其他模型一致。假设这是有效的,那么这个模型的预训练需要 6 * (370 亿) * (14.8 万亿) = 3e24 FLOP。如果我们假设 DeepSeek 的训练集群由具有 PCIe 外形尺寸的 H800 组成,那么每个 H800 应该能够每秒 1.5e15 FP8,而 DeepSeek v3 的 55 天训练运行的隐含模型 FLOP 利用率 (MFU) 最终约为 23%。
人们一直怀疑 3e24 FLOP 数字的一个原因是,该模型的性能似乎与使用相当数量的资源训练的其他模型不一致。例如,Llama 3 70B 及其后续迭代的训练计算量大约是其两倍,并且在基准测试中明显低于 DeepSeek v3。性能差异背后的原因是算法的进步:我们知道 Llama 3 70B 缺乏创建 DeepSeek v3 的许多关键架构创新,因此它的计算效率较低也就不足为奇了。我们对数据质量方面的情况知之甚少,但如果 DeepSeek 在这方面也改进了 Llama 系列,我不会感到惊讶。
如果有的话,平淡无奇的模型 FLOP 利用率表明,DeepSeek 训练运行的真正神秘之处不是它为什么这么便宜,而是它为什么这么贵。显而易见的答案是 MoE 培训很困难,但这是相当肤浅的,并没有解决实际问题,因此我将提供一个粗略的计算,说明为什么我们预计以高 MFU 来安排这次培训运行会很困难。
DeepSeek 在训练运行中使用了 64 路专家并行度。在这种情况下,大多数 EA 都位于彼此不同的 GPU 上,因此如果我们假设连续层的 EA 激活不相关,那么在进入和退出几乎所有代币的 MoE 区块时,我们需要 GPU 间通信。这样做的通信成本是多少?
粗略估计,由于每个 token 由 8 个活跃的 expert 处理,因此必须将维度 7168 的残差流向量发送给每个活跃的 expert。这需要对每个区块和每个令牌进行,并且由于激活的精度为 16 位,因此我们需要
16 位 * 8 * 7168 * 58 * 14.8 万亿 = 1e20 字节
让我们悲观地假设所有这些通信都必须通过 InfiniBand 进行,在 DeepSeek 的集群中,它可能支持 50 GB/s 的每 GPU 读取带宽。在这种情况下,在前向传递中仅 MoE 进入通信所需的时间将为
1e20 字节 / (2048 * 50 GB/s) = 11 天 7 小时
这非常糟糕,因为对于 MoE 后的 all-reduce 和 all-to-all作,我们需要将其乘以几次,然后再乘以 2 以考虑向后传递和向前传递。如果我们进行所有这些调整,我们很容易以仅专家并行通信为目的,占用超过 55 天的时间。DeepSeek 意识到了这一点,并采取了多种措施来解决这个问题:
-
他们使用 arithmetic 实现了专家并行通信的高效重叠,以隐藏一些通信时间。
-
他们仔细调整了他们的训练设置,这样即使每个路由的专家在大约 1/32 的代币中处于活跃状态,专家激活也不是彼此独立的。在网络拓扑中靠近的专家更有可能一起被激活,通过将大部分专家并行通信转移到 NVLink 上进行,这大大降低了上述通信成本。
H800 的 NVLink 比 H100 慢(与 225 GB/s 相比,全缩减带宽约为 100 GB/s),但它们的 NVLink 仍应比 InfiniBand 快四倍,因此如果它有效,这将是一个很大的胜利。
尽管他们在硬件优化方面做出了巨大努力,但他们仍然只能将 MFU 提高到 23%,这一事实表明,在实践中训练 MoE 模型是多么烦人。它们在现实世界中的效率比纯粹基于算术的计算所建议的那样要低得多,正如我在上一期专注于 MoE 推理的期刊中所讨论的那样。
R1-Zero 的 RL 训练
现在我们继续讨论 r1 论文本身所做的贡献:将基本 v3 模型转换为推理器的强化学习。本文没有 v3 技术报告那么详细,但仍然包含足够的信息,让我们推断强化学习阶段必须需要多少计算。
以下是 DeepSeek-R1(生成检查点 Deepseek-R1-Zero 的那个)的核心基于推理的强化学习循环的样子:
- 我们抽样一批 B 题。对于其中每个选项,模型都会生成 G 个可能的答案完成。模型决定这些完成何时终止,但假设在整个 RL 训练过程中,每个完成的平均长度为 L。
- 每次完成 i = 1, 2, ..., G 都会分配一个奖励r_i。这有时以基于规则的方式完成(例如,代码的单元测试和数学问题的最终答案正确性检查),有时使用另一个 LLM 来执行答案评分。
- 我们通过减去平均值并除以标准差来标准化 G 奖励。
- 然后,我们对代理预期奖励目标的 K 步进行梯度上升,以使我们的模型更有可能产生高回报答案,而不太可能产生低回报答案。由于我们的 G 部署对策略行为的指导与我们当前的模型相去甚远,因此我们会惩罚在目标中偏离当前策略太远的情况。
- 我们重复上述过程 N 次。整个强化学习算法被称为组相对策略优化 (GRPO),由 DeepSeek 在之前的工作中引入,作为更常用 PPO 的更便宜的替代方案。
当我们以这种方式分解过程时,很容易为 RL 训练第一阶段的 FLOP 成本提供一个粗略的表达式。通常,我们可以通过假设每个前向和反向传递的每个参数每个令牌 6 个 FLOP 来实现这一点,但 DeepSeek v3 独特的算术密集型注意力机制提高了这一成本。在 RL 期间使用的平均上下文长度 L = 4000 时,注意力 FLOP 最终与解码过程中的参数 FLOP 相当,因此平均而言,我们为每个活动参数和生成的每个令牌花费 4 FLOP 而不是 2 FLOP。对于每个探索阶段之后的第一个梯度步骤,我们只需要支付一次此成本,因为后续步骤依赖于我们之前已经采样的轨迹。
反向传播步骤也会受到影响,但事实证明,我们可以毫不费力地忽略这个影响。因为我们在很长的序列长度上执行每一步,所以我们可以负担得起从它们的潜在值向量中解压缩键和值向量,并通过不同的计算图进行反向传播,而不是我们所做的前向传递。这增加了一些额外的成本,但并不大,因此我们可以大致假设反向传播的通常成本为每个令牌的每个活动参数 4 FLOP。
考虑到 DeepSeek v3 的 370 亿个活动参数数量,我们得到了最终的估计值
推理 RL 计算成本 = N * B * G * (L 个令牌) * (37B 参数) * (8 个 FLOP/参数/令牌) +
N * (K-1) * B * G * (L 令牌) * (37B 参数) * (6 个 FLOP/参数/令牌)
该论文为我们提供了有关计算中的关键参数的信息:
-
N*K 是整个 RL 训练中梯度步骤的总数,我们知道这等于论文中各种数字的大约 8000 个。在之前的工作中,DeepSeek 使用 K = 1,在这种情况下,我们有 N = 8000。
-
通过查看论文中的图 3,我们可以推断出这些步骤中 L 的平均值约为 4000。
-
B 和 G 在本文中没有明确说明,但在之前的工作中,DeepSeek 使用了 B = 1024 和 G = 64。这是我计算中最大的不确定性来源。例如,DeepSeek 使用 B = 512 表示 R1 是非常合理的,在这种情况下,这里的所有成本估算都会高出 2 倍。
我暂时继续使用 B = 1024,但在解释结果时牢记这一点很重要。
结合所有这些,我们得出了初始推理 RL 阶段的最终成本估算为 6.1e23 FLOP,如果 RL 阶段具有与预训练相似的 MFU,则约为 $1M。这明显低于 DeepSeek v3 本身的训练前算术成本。强化学习期间的 MFU 必须比预训练差 5 倍,约为 5%,才能使 RL 的成本甚至与以 GPU 小时数衡量的预训练成本相当。
我们可以估计 RL 阶段可能需要多长时间才能看到如此低的 MFU 数据是否合理。生成的连续标记总数约为 N * L,根据 DeepSeekMath 论文,假设 K = 1,则为 3200 万个。DeepSeek 以每个请求每秒约 50 个令牌的速度为 R1 提供推理服务,按照这个速度,可以在 7 到 8 天内生成 3200 万个串行令牌。这足够短,我们预计串行时间限制不会成为他们的 RL 设置的问题,因此每秒 50 个令牌已经足够快了。有趣的是,这也与他们的 2048 H800 集群在与 DeepSeek v3 的预训练类似的 MFU 上运行时所需的算术费用一致。
以这种速度,RL 的代币生成部分需要多少成本?我们需要为整个 RL 阶段生成总共 N*B*G*L = 2T 代币,而 DeepSeek 最初对 V3 的未打折 API 价格是每百万个输出代币 1.1 美元,所以成本最多应该是(2T 代币)*(1.1 美元/百万代币)= $2.2M。按照目前每百万个代币 0.3 美元的折扣价格,这个估计值下调到 $600K,如果我们还考虑到反向传播的成本,这与之前的 $1M 估计值大致一致。
所有这些都表明,使 RL 成本与预训练成本相当所需的极低 MFU 数字是不现实的,我们可以从原始 FLOP 成本中得出的结论大致准确。
R1 的后续训练
产生 R1-Zero 的 RL 循环是推理训练的核心,但它并不是训练最终 R1 模型之前的唯一步骤。基于这个检查点,DeepSeek 策划了一个冷启动数据集(部分包括清理的 R1-Zero 输出),以便在进行 RL 训练的另一个阶段之前微调基本 v3 模型,类似于产生 R1-Zero 的过程。这种冷启动可以防止 RL 训练的早期不稳定,并确保模型的输出和思维链是人类可读的。我们在论文中关于第二个 RL 阶段的细节较少,但如果我们要保守一点,我们可以假设它与第一个阶段的成本相似,并将我们的初始成本估计翻倍以将其考虑在内。
完成此作后,DeepSeek 会创建一个受监督的微调数据集,其中包含来自最后一个检查点的大约 600K 推理样本和 200K 样本,这些样本进入 v3 本身的后训练,然后在两个 epoch 中根据所有这些数据对 v3 进行微调。如果每个样本的平均长度约为 8K,这与训练结束时 R1-Zero 达到的一致,那么这个 SFT 数据集总共有 800K * 8K = 6.4B 个标记,因此微调本身的成本可以忽略不计。这一步很有趣,因为它表明,对推理跟踪进行有限数量的微调就足以将基本模型转变为称职的推理器,这就解释了为什么 OpenAI 等实验室可能有兴趣对其推理跟踪保密。
总的来说,我认为从 V3 开始训练 R1 的 GPU 时间的美元成本的合理粗略估计约为 $1M,而 V3 本身的预训练花费为 $5M 。我之所以不简单地将之前的 $1M 数字翻倍,是因为我不知道 B = 1024 的选择是否正确,或者第二个 RL 阶段是否确实与第一个阶段的成本相同。以 $1M 的总成本估计,我认为我在任一方向上出错的可能性大致相同,因此这似乎是正确的数字。
最后要注意的是,所有这些数字都忽略了实验的计算成本、人员成本、管理开销等。严格来说,它们是我上面详细阐述的 R1 训练运行中的训练运行的硬件时间成本。
性能和定价
DeepSeek-R1 在基准测试中似乎与 OpenAI 的 o1 具有相似的性能,我们两者都有可用的分数。在 DeepSeek 引用两个模型结果的 11 个基准测试中,o1 在 6 个基准测试中击败了 R1,这与我们预期的结果差不多。我认为 o1 在整体性能上仍然应该优于 R1,因为当实验室发布自己模型的基准测试分数时通常会有发表偏差,但差异并不大,对于大多数用例,模型应该是可比的。
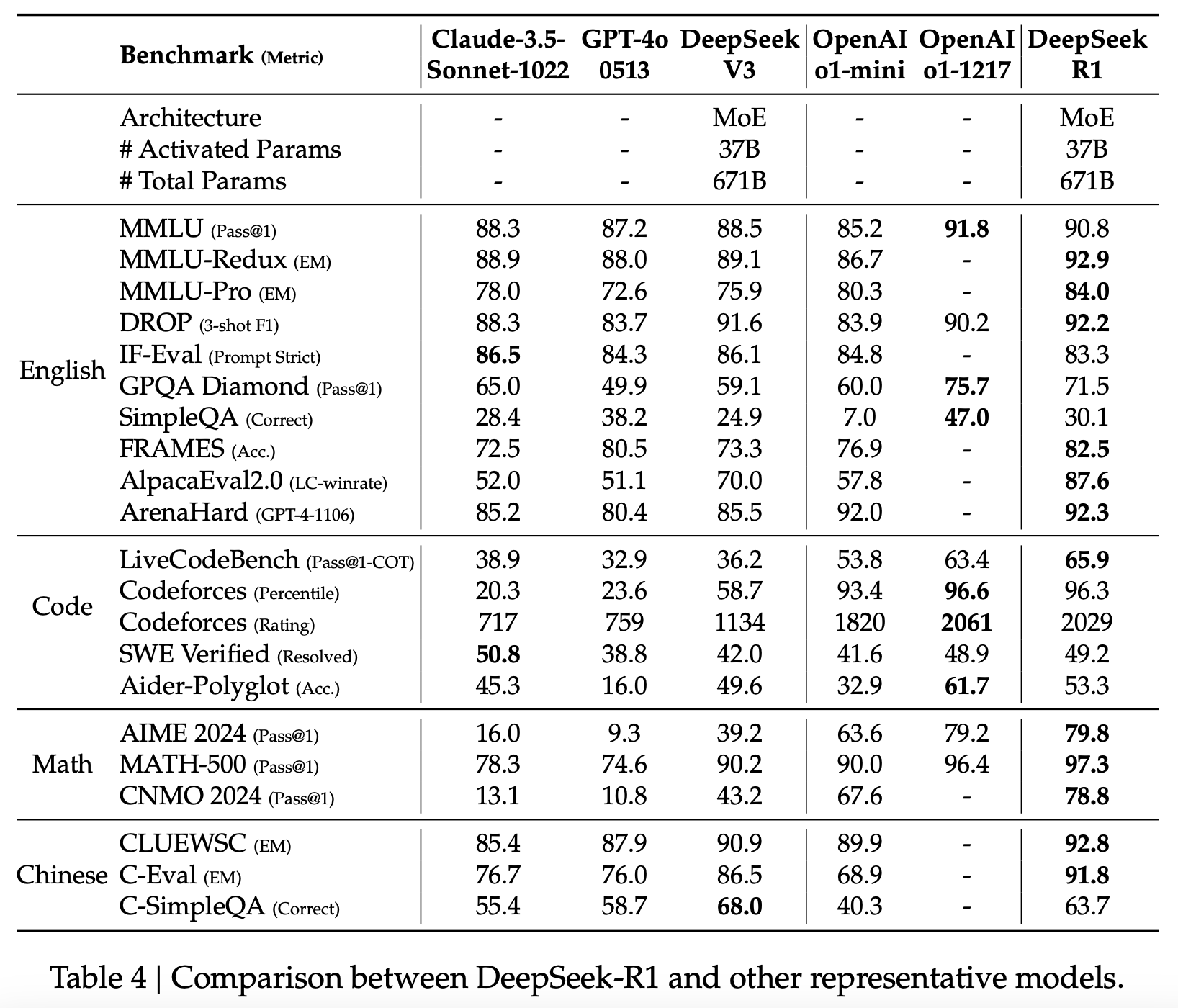
图 2:DeepSeek-R1 与其他代表性模型的比较表。来自 DeepSeek R1 技术报告。
然而,虽然两种型号之间的性能差异很小,但价格差异绝对不是。R1 的定价为每百万个输出令牌 2.2 美元,而 o1 的价格为每百万个输出令牌 60 美元,而且 R1 的推理速度也不慢。这种巨大的差异意味着,当根据消费者的价格进行调整时,R1 只是优于 o1 的型号。
我不认为这种差异是由于 R1 作为一个模型本质上更高效,而是因为与 OpenAI 收取的高利润率相比,DeepSeek 以非常低的毛利率为模型提供服务。R1 平均而言也可能具有较短的推理跟踪,尽管这不太清楚。来自 DeepSeek 和其他中国实验室的成本竞争将在多大程度上影响美国实验室的 API 利润率还有待观察,但我认为这对他们来说不是好消息。
结论
以下是我希望读者从这个问题中学到的要点:
-
虽然在 R1 发布后,公众对 DeepSeek 模型的兴趣呈爆炸式增长,但从技术角度来看,R1 成功的大部分要素都是由 DeepSeek 在 2024 年逐步开发的。拥有高质量、廉价且快速的基本模型(如 v3)是使这种 RL 设置工作的大部分困难。
-
DeepSeek 报告的 v3 集群大小和训练成本估计值与我们对于使用 v3 架构的模型进行预训练的预期一致,并且没有证据表明他们低估了成本。
-
虽然 DeepSeek 没有对 DeepSeek-R1 的 RL 成本做出任何明确声明,但根据他们论文中披露的信息,我估计它大约是 $1M。
-
DeepSeek-R1 与 OpenAI 通过 API 服务的最佳 o1 版本大致相当,同时对消费者来说便宜约 30 倍。这种差异可能主要是由于 OpenAI 的大加价,尽管我们不能排除其中一些是由于 R1 只是一个更高效的模型。
我最好的猜测是,在软件效率方面,DeepSeek 仍然落后于 OpenAI 和 Anthropic 等美国前沿实验室。然而,差距并不远:根据将 DeepSeek v3 基础模型与我们在 Frontier Labs 看到的模型进行比较,我估计 DeepSeek 落后了大约 6 个月。此外,DeepSeek 愿意以接近边际成本的方式为他们的模型提供服务,这使得它们对整体用户更具吸引力。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢