

World models learn the dynamics of environments in a data-driven manner, enhancing performance and efficiency in downstream tasks such as control, design, recognition, and generation, thanks to cost-effective simulation and differentiability. A pre-trained world model should ideally (1) accurately simulate ground-truth dynamics, (2) adapt easily to novel configurations, and (3) generalize across diverse physical effects. Previous attempts in this area have either utilized differentiable model-based physics with few parameters exposed or trained for specific scenarios with minimal physical priors integrated. These world models fall short of their objectives, limiting their applicability in real-world accuratecritic deployments and scalability to larger pre-trained world models. In this thesis, we aim to build world models with neural physics, a hybrid neural-physics framework that models the basic dynamics with differentiable physics while learning all additional modules through neural networks. By integrating neural physics, the world models adhere closely to physical principles while efficiently learning diverse effects. The modular structure of neural physics allows world models to generalize to novel configurations simply by installing different pretrained neural modules. We will demonstrate the effectiveness of this novel framework in applications such as reconstruction, robotic control, and scientific discovery.
世界模型以数据驱动的方式学习环境的动力学,通过成本效益的模拟和可微性,提高了控制、设计、识别和生成等下游任务的表现和效率。理想的预训练世界模型应(1)准确模拟真实动力学,(2)易于适应新配置,(3)泛化到不同的物理效应。该领域之前的尝试要么利用具有少量参数暴露的可微模型物理,要么在最小物理先验整合的情况下针对特定场景进行训练。这些世界模型未能达到其目标,限制了它们在现实世界准确批评部署中的应用和扩展到更大的预训练世界模型的能力。在本论文中,我们旨在构建具有神经物理的世界模型,这是一个混合神经-物理框架,它使用可微物理来模拟基本动力学,同时通过神经网络学习所有附加模块。通过整合神经物理,世界模型紧密遵循物理原理,同时有效地学习各种效应。 神经物理学的模块化结构使得世界模型能够通过安装不同的预训练神经模块简单地泛化到新的配置。我们将展示这一新颖框架在重建、机器人控制和科学发现等应用中的有效性。

论文题目:Building World Models with Neural Physics
作者:Matusik, Wojciech
类型:2025年博士论文
学校:Massachusetts Institute of Technology(美国麻省理工学院)
下载链接:
链接: https://pan.baidu.com/s/18jyIDfI4jB9-o77v2mxJIQ?pwd=wg4e
硕博论文汇总:
链接: https://pan.baidu.com/s/1Gv3R58pgUfHPu4PYFhCSJw?pwd=svp5
长期以来,科学家们一直在研究开发有效方法来高效地表征世界,这种方法被称为世界模型 [51, 95]。世界模型允许智能体与其环境交互,用于预测未来事件 [54, 57, 58, 80, 209, 211] 或推导相对于当前状态或动作的梯度 [35, 37, 66, 67, 140, 142, 141, 191]。通常,世界模型能够感知来自环境的多模态信号,并通过多模态反馈对输入控制信号做出响应 [51, 80, 113]。经济高效的未来轨迹及其衍生模型的可用性显著提高了数据效率、鲁棒性和下游任务的性能,包括机器人控制和设计 [57, 58, 113, 114]、推理 [51] 和生成 [192]。
最近的研究开发了基于物理的世界模型,这些模型使用可微分物理模拟器或残差物理来模拟已充分研究的物理效应,例如铰接刚体[141, 199]、可变形体[140, 142, 37, 191]、流体[35, 196]和多物理场系统[101]。这些世界模型通常通过优化预定义的系统参数与现实世界物理很好地吻合,从而使其能够有效地推广到未知的配置。然而,对手动设计的物理引擎和系统参数的依赖限制了它们对未建模物理效应的推广能力。例如,使用基于专用有限元方法构建的可微分变形体模拟器来模拟流体环境需要付出巨大的努力,甚至可能是不可能的。这一限制凸显了将这些模型扩展到多样化和复杂的物理现象所面临的挑战。
另一方面,另一项研究尝试使用图神经网络[154, 137]或潜在动态模型[53, 54],以最少的物理先验信息来建模世界。这些方法旨在构建底层世界表征,而无需过度依赖预定义的物理参数,而是利用结构和学习到的表征来理解和预测动态。这可以构建更灵活的模型,摆脱手动设计物理的限制。然而,由于缺乏基本的物理原理,这可能会导致样本效率下降、计算资源浪费以及物理完整性受损。
最近的研究还探索了通过使用物理信息神经网络 (PINN) 将物理先验知识集成到普通神经网络中 [146, 144, 145, 81]。在该方法中,物理约束被表示为损失函数,并以自监督的方式反向传播到神经网络。PINN 通过结合数据和物理定律来建模物理世界,提供了一种新颖的视角。然而,它们的集成能力通常较弱,无法可靠地支持长周期下游任务。此外,PINN 通常针对特定时间跨度内的特定场景配置进行优化,这限制了它们在更广泛场景中的适用性。

这是我们四个环境(从左到右)的图库,涵盖三个渲染域(从上到下)。对于每个环境,我们使用可微分渲染器生成的不同光照、背景和材质下的图像(顶部)来训练 RISP。然后,每个环境都旨在找到合适的系统和控制参数来模拟和渲染物理系统(中间),使其能够与具有未知渲染配置的参考视频(底部)的动态运动相匹配。我们特意让三行使用渲染配置差异很大的渲染器。
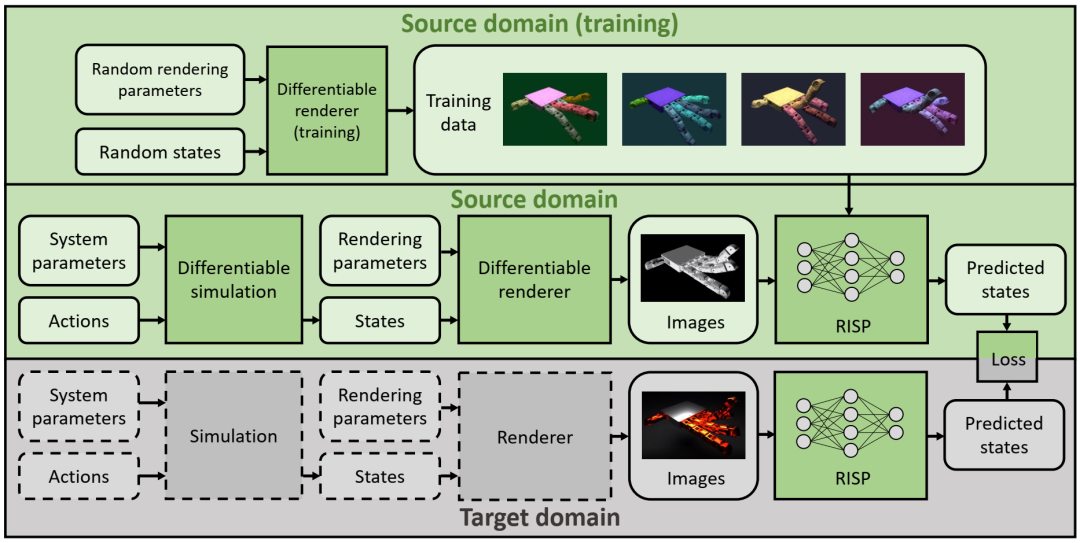
我们的方法概述(第 2.3 节)。我们首先使用以随机状态和渲染参数渲染的图像训练 RISP(顶部)。然后,我们将 RISP 附加到可微分渲染器的输出,从而形成一个从系统和控制参数到图像预测状态的完全可微分的流水线(中间)。给定目标域中由未知参数(虚线灰色框)生成的参考图像(底部),我们将它们输入 RISP,并最小化预测状态之间的差异(最右侧的绿灰色框),以重建底层系统参数、状态或动作。

手部环境中的模仿学习(第 2.4.4 节)。给定一个参考视频(底行,显示为五个中间帧),目标是重建与其运动相似的一系列动作。我们展示了使用随机选择的动作初始猜测(顶行)生成的动作,以及使用我们的方法结合渲染梯度优化的动作(中间行)。

现实世界实验中的模仿学习(第 2.4.5 节)。给定一段参考视频(上行),目标是重建发送给虚拟四旋翼飞行器的动作序列,使其运动轨迹与飞行器的运动轨迹相似。我们演示了使用我们的方法重建的运动轨迹(下行)。
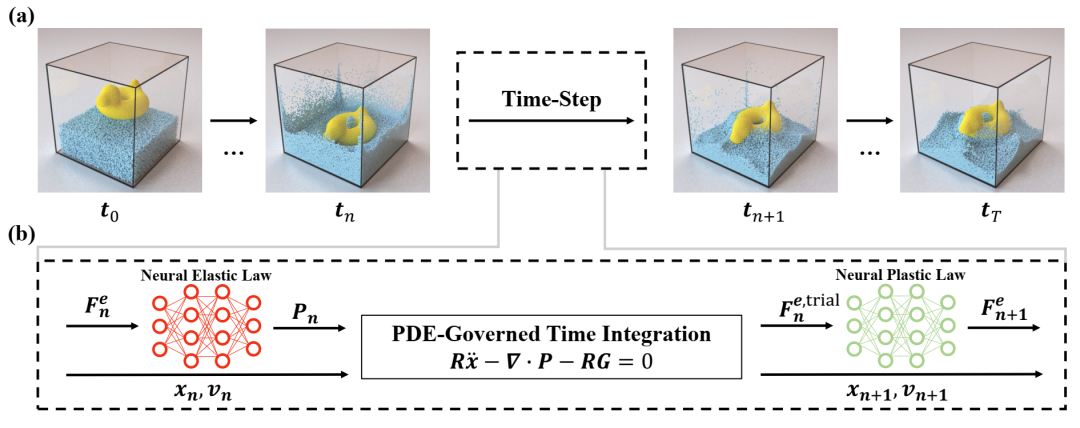
混合神经网络-偏微分方程 (NN-PDE) 时间步进。(a) 我们的方法按顺序进行“时间步进”以获得动力系统的解。(b) 在时间步进算法中,我们 (i)利用神经弹性本构定律获取应力;(ii) 通过求解控制偏微分方程 (PDE)(方程 (3.1))来更新状态;(iii) 通过神经塑性本构定律获取新的弹性变形梯度。算法 2 列出了相应的伪代码。

泛化。我们首先在训练集中指定的环境中训练所有方法,初始速度用黑色箭头表示。然后,我们在测试集中指定的四个任务上评估所有方法的泛化能力:(a) 延长时间,(b) 未知的初始速度,(c) 具有挑战性的几何形状,以及 (d) 倾斜边界。虚线左侧显示初始化,右侧显示一段时间后的模拟结果。我们将我们的方法(我们的)与基线(神经和 gnn)、我们的初始化(ours-init)以及真实模拟(ground-truth)进行比较。我们用红色框突出显示我们的方法和真实模拟结果。

极端泛化。我们在两个极端泛化实验中比较了初始状态、我们的方法以及传统模拟的真实结果:(a) 一条装载了超过 100 万个粒子的复杂水龙;(b) 四个橡胶玩具剧烈地相互碰撞并与地板碰撞。

高级实验。左图:我们将我们的方法与传统模拟在两个多物理环境中的真实结果进行比较:(a) 一只小黄鸭掉进游泳池;(b) 融化的冰淇淋逐渐从一种材料变为另一种材料。右图:我们利用真实世界的面团掉落数据训练我们的方法,以学习面团的本构规律:(c) 我们的方法成功地重建了训练序列;(d) 我们的方法能够很好地推广到未知条件,例如复杂的几何形状。
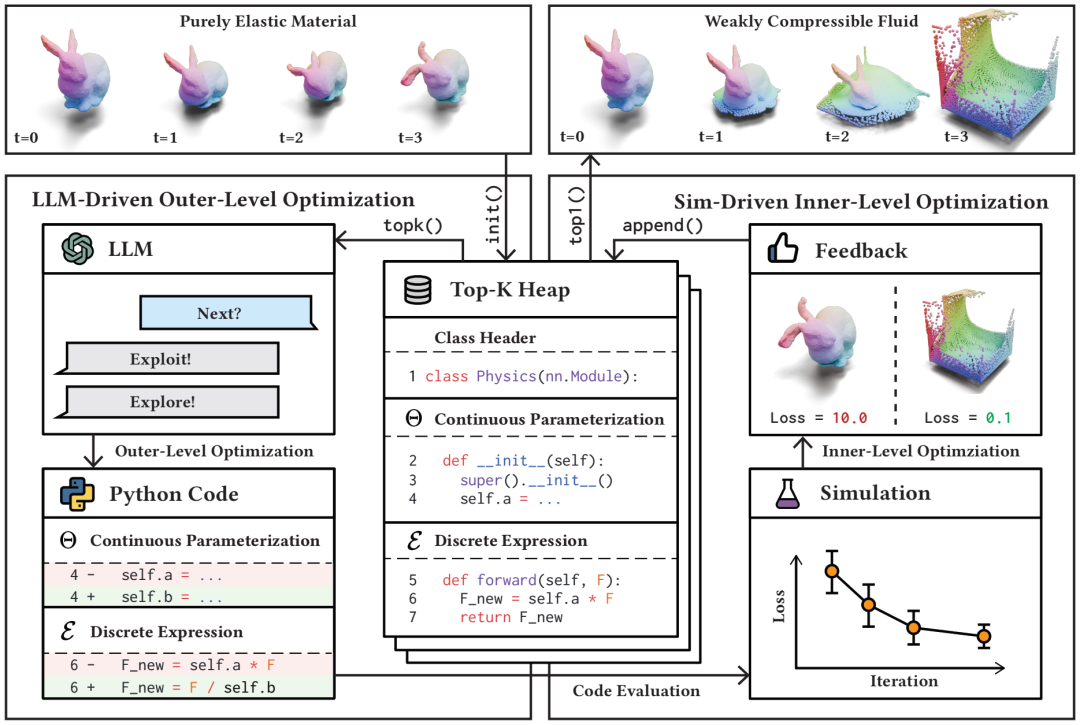
科学生成代理 (SGA) 的整体流程。以本构律搜索问题为例,输入是一个初始猜测(纯弹性材料),输出是另一个针对真实值(弱可压缩流体)进行优化的本构律。初始猜测首先初始化一个 top-𝐾 堆用于存储解。在外层优化中,LLM 接收先前提出的 top-𝐾 解,并使用改进的连续参数化 Θ 和离散表达式 ℰ 生成一个更优解。在内层优化中,基于梯度的优化通过模拟求解最优 Θ,并将这些优化解添加到堆中。经过几轮双层优化迭代后,堆返回 top-1 解作为最终解。
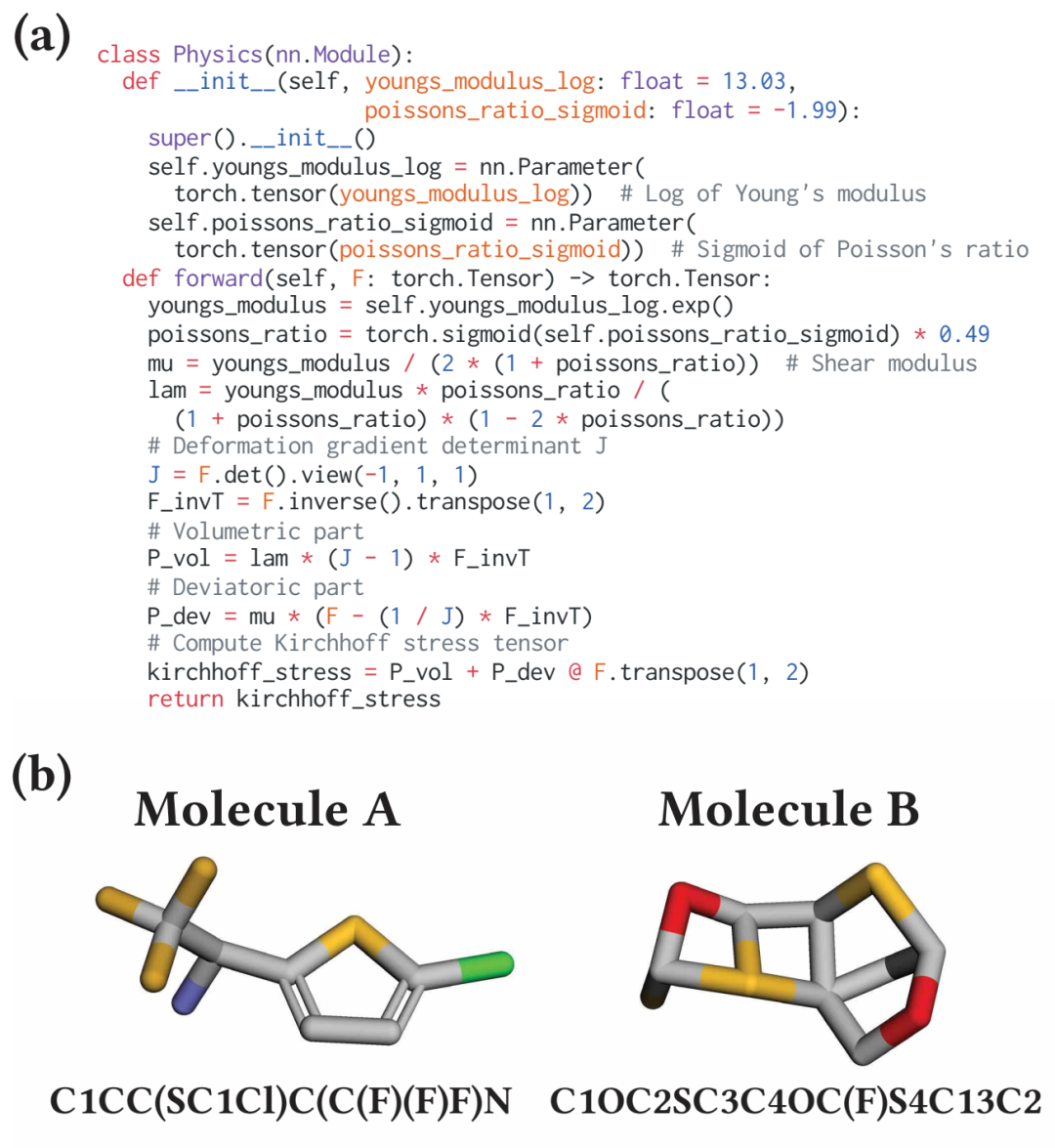
案例研究。(a)我们给出了所搜索的本构定律的具体示例。(b)我们提供了 2 种针对不同目标进行了优化的新型分子,它们具有 SMILES 刺痛。

真实实验。我们展示了实验装置的正面和侧面视图。我们用虚线轮廓表示面团的落下位置,用虚线箭头表示落下方向。

训练数据。我们展示了(a)果冻、(b)沙子、(c)橡皮泥和(d)水的颗粒感和真实感渲染效果。








内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢