

本文部分内容参考自账号「沉浸式翻译」
沉浸式翻译团队最近开源了他们PDF翻译工具——「BabelDOC PDF」 。BabelDOC 在很大程度上解决了 PDF 机翻中出现的排版乱码、串行等不可用的「老大难」 问题,可以直接输出对版的精准 PDF。
产品发布后,BabelDOC 一举冲进了 Github 全站全开发语言 Trending 榜的前三。
随后,BabelDOC 又上新了多语种支持功能,支持使用拉丁字母的语言翻译成简体中文、繁体中文、日文和韩文。同时,上线了中、日、韩三国文字之间的互译功能。
目前,免费用户每月可享 1000 页解析额度及 GLM-4-FLASH 翻译。Pro 用户最多可享受每月 10000 页解析额度,可以使用 DeepSeek 翻译模型。
沉浸式翻译团队最近开源了他们PDF翻译工具——「BabelDOC PDF」 。BabelDOC 在很大程度上解决了 PDF 机翻中出现的排版乱码、串行等不可用的「老大难」 问题,可以直接输出对版的精准 PDF。
产品发布后,BabelDOC 一举冲进了 Github 全站全开发语言 Trending 榜的前三。
随后,BabelDOC 又上新了多语种支持功能,支持使用拉丁字母的语言翻译成简体中文、繁体中文、日文和韩文。同时,上线了中、日、韩三国文字之间的互译功能。
目前,免费用户每月可享 1000 页解析额度及 GLM-4-FLASH 翻译。Pro 用户最多可享受每月 10000 页解析额度,可以使用 DeepSeek 翻译模型。
Founder Park 正在搭建「AI 产品市集」社群,邀请从业者、开发人员和创业者,扫码加群:

进群后,你有机会得到:
最新、最值得关注的 AI 新品资讯;
不定期赠送热门新品的邀请码、会员码;
最精准的AI产品曝光渠道
如果你想提交自己的产品,点击文末的「阅读原文」即可。
BabelDOC 是如何实现「精准翻译+版式对版」 的?
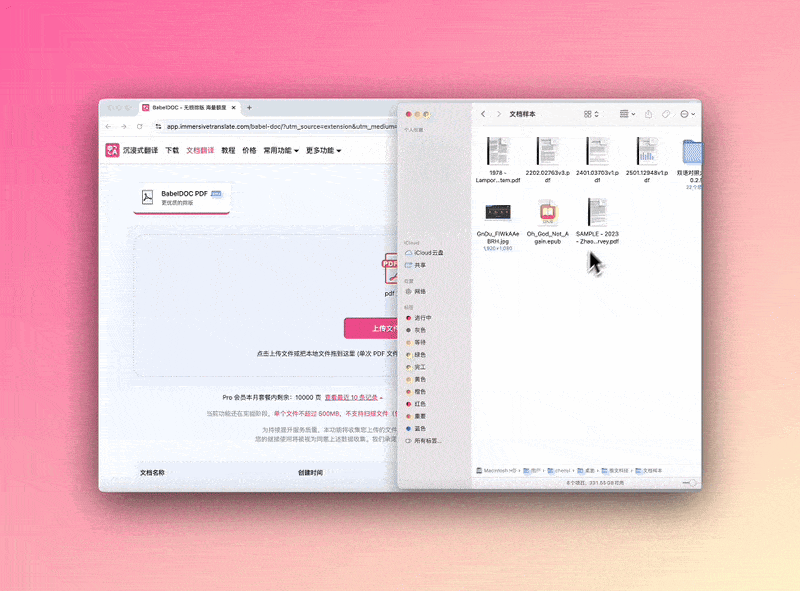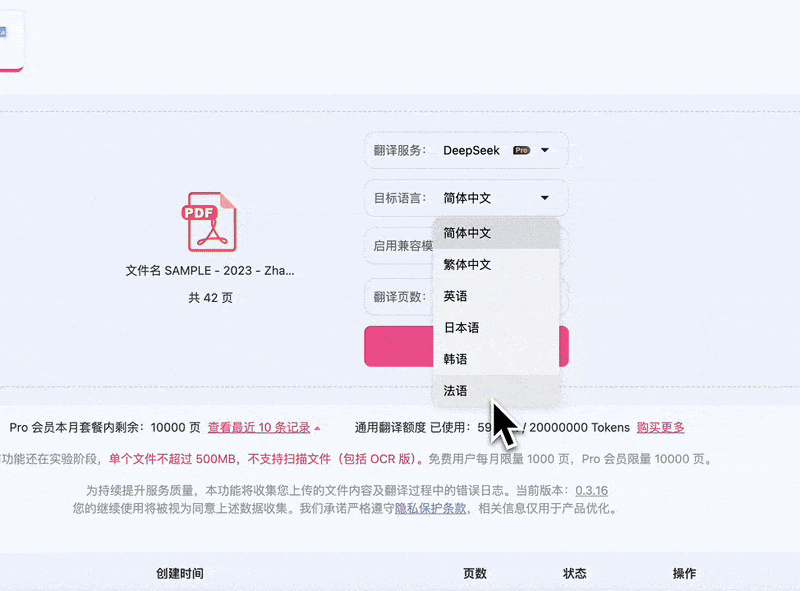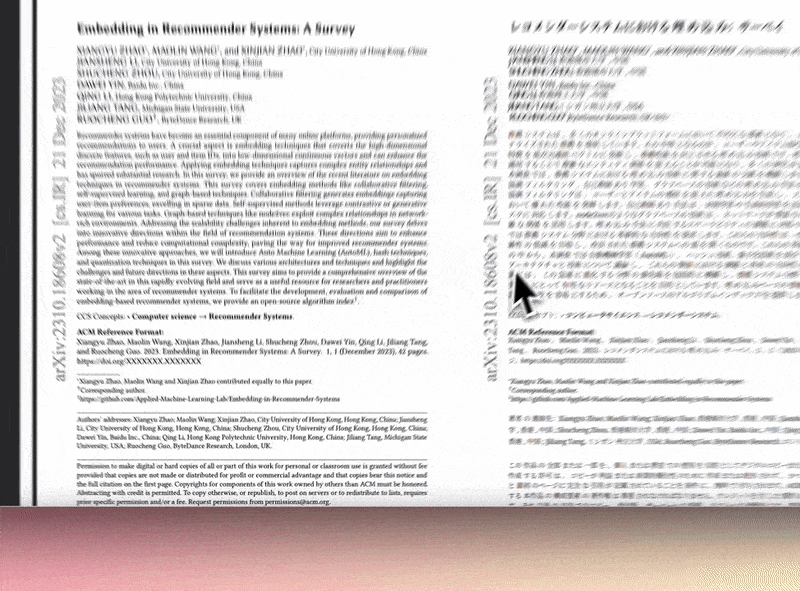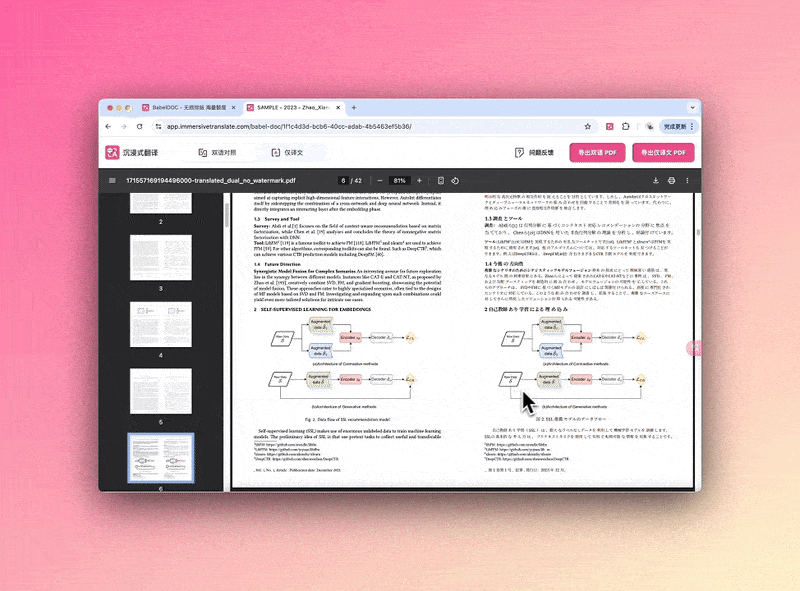
我们先来看 BabelDOC 实现的效果。BabelDOC 能够完整地提取并翻译 PDF 中内嵌图表、脚注、公式等非文本元素,能实现译文与源文件之间像素级版式对齐。同时,BabelDOC 能够自动识别学术论文/招股书/行业白皮书等专业文档结构,确保翻译后布局与数据可视化效果,同原文档高度一致。
在技术方面,首先,BabelDOC 会完整地解析 PDF 的内容,包括读取文件头尾来了解 PDF 的结构、读取图片/文字等元素。在处理以上步骤后,BabelDOC PDF 引入了「AI 布局识别」技术,来辨认文本的布局、段落结构,以及一些复杂的内容排版情况,例如图片、表格和数学公式,并「记忆」下来。
接着,在布局识别完成后,提取文本并交给大语言模型进行翻译。
然后,把翻译好的文字同上面识别记录下来的排版情况进行比对,智能匹配对应的字体、行距等样式,确保文本能够适应新的布局。
当遇到图片和复杂公式时,BabelDOC PDF 会对其进行识别和解析。富文本的文字部分进行对应的翻译,公式则以原封不动地以字符形式保留。
最后,通过智能渲染的方式,将翻译好的文字调整好大小尺寸,将上面所提到的数学公式、图片、表格等重新排版一遍,写入新文档。
由此,做好翻译和排版复原 PDF 文档完成。
PDF 翻译为什么那么复杂?
要了解 BabelDOC PDF,我们需要花一点时间了解 PDF (Portable Document Format),这个堪称数字出版历史上最有影响的发明之一。
PDF 文档源自行业内响当当的 Adobe 公司,是该公司联合创始人约翰·沃诺克(John Warnock)于上世纪 90 年代初发明的,目的是为了解决文档不同设备上显示效果不一致的问题。PDF 问世后增加了大量交互、加密等功能,并于 2008 年被国际标准化组织(ISO)采纳为国际标准(ISO 32000-1:2008)。相比于常见的 。DOCX 格式文档,PDF 在可编辑性上略逊一筹,但有自己独特的优势,可以参考下表:

这些优缺点都源自 PDF 的文件结构。PDF 的文件结构可以理解为「一张充满二进制代码和文本的纸」,其架构如同枝繁叶茂的大树,结构是这样构成的——
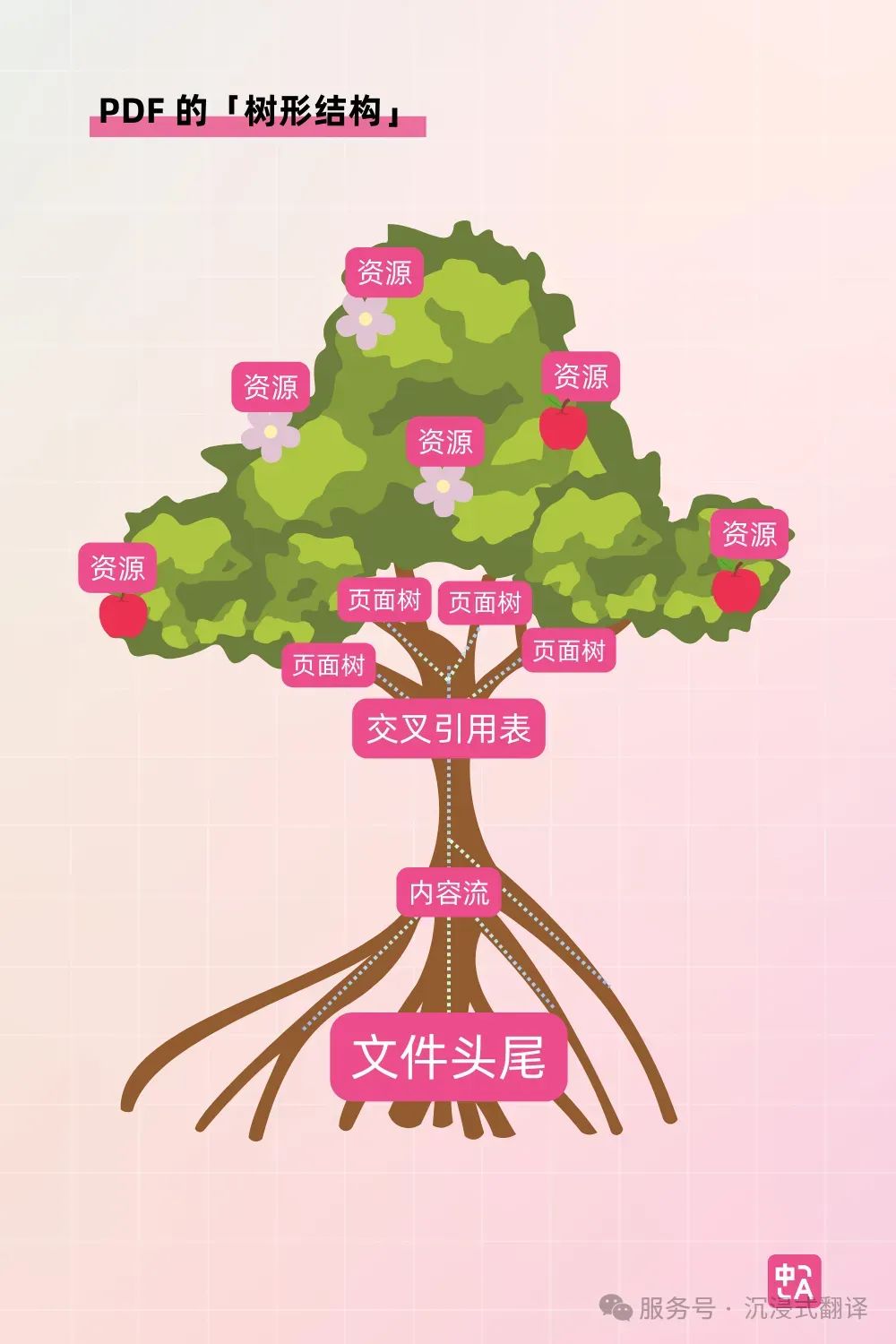
大树的根部是「文件头尾」:包含一系列二进制代码,让读文件的程序(包括 BabelDOC PDF)将其识别为二进制文件,而不是纯文本,并给出交叉引用表等资源的位置。
大树的末端枝干是 Page Tree,又称「页面树」:每个分支代表 PDF 中的一个页面,记录了图片、文字等元素的「引用」情况
大树的主干分叉部分是「交叉引用表」:当读文件的程序遇到交叉引用表,就如同看到了什么信息存放在哪里(页面树)的指路牌,可以顺藤摸瓜找到对应的信息
大树的叶子、花朵、果实是「资源」:包含了组成文档所需的各种细节,如具体的字体、图像、颜色空间等
大树的导管系统是「内容流」:记录了 PDF 页面的绘制指令,描述了程序如何在页面上还原出文本、图像等元素。
所以当一个程序打开 PDF 文档时,我们可以大致把打开的过程想象为下图的流程——
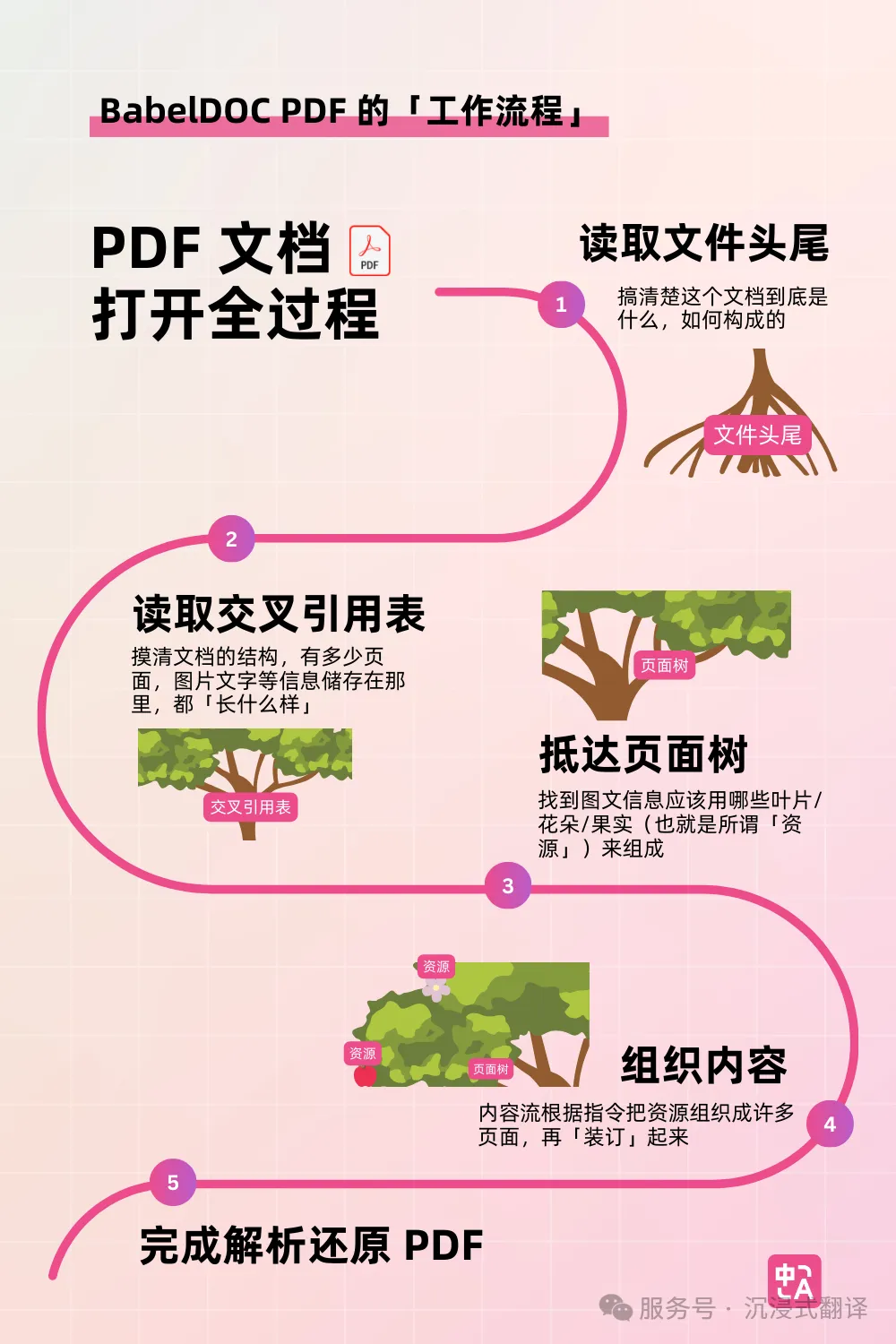
当然,这只是个形象的比喻,实际上的过程比这个复杂很多,大家能理解基本的原理就好。
转载原创文章请添加微信:founderparker
内容中包含的图片若涉及版权问题,请及时与我们联系删除


评论
沙发等你来抢