

Stanford CS224W: Machine Learning with Graphs
By Luke Park, Irfan Nafi, Ray Hotate as part of the Stanford CS 224W Final Project
DDI 的影响
1. Introduction
Graph Machine Learning (Graph ML) has emerged as a transformative approach to solving complex real-world problems by leveraging the inherent structure of graph-based data. In drug discovery and pharmacology, this approach is especially promising, where molecular, biological, and interaction networks can be modeled as graphs to extract meaningful insights. Predicting drug-drug interactions (DDIs) is a critical challenge in healthcare, as interactions between medications can lead to unforeseen and potentially severe adverse effects. Early identification of these interactions is crucial for ensuring patient safety and optimizing drug efficacy.
图形机器学习 (Graph ML) 已成为一种变革性方法,通过利用基于图形的数据的固有结构来解决复杂的实际问题。在药物发现和药理学中,这种方法尤其有前途,其中分子、生物和交互网络可以建模为图表,以提取有意义的见解。预测药物相互作用 (DDI) 是医疗保健领域的一项关键挑战,因为药物之间的相互作用可能导致不可预见和潜在的严重不良反应。早期识别这些相互作用对于确保患者安全和优化药物疗效至关重要。
链接预测示例
Traditional approaches to DDI prediction often rely on pharmacokinetic models or large-scale clinical data analysis, which are time-consuming and limited in generalizability (Cami et al., 2013). More recently, graph-based machine learning methods, including Graph Neural Networks (GNNs), have shown the ability to predict DDIs effectively by leveraging the topological structure of interaction networks (Sun et al., 2019). These methods provide a scalable and efficient alternative to traditional techniques, addressing the limitations of insufficient clinical evidence and high-dimensional data representation.
传统的 DDI 预测方法通常依赖于药代动力学模型或大规模临床数据分析,这些模型非常耗时且普遍性有限(Cami et al., 2013)。最近,基于图的机器学习方法,包括图神经网络 (GNN),已经显示出通过利用交互网络的拓扑结构来有效预测 DDI 的能力(Sun et al., 2019)。这些方法为传统技术提供了一种可扩展且高效的替代方案,解决了临床证据不足和高维数据表示的局限性。
Our study introduces a hierarchical approach using Graph Attention Networks (GATs) to enhance DDI prediction. Unlike previous methods, our hierarchical model combines local embeddings, which capture immediate interaction patterns, with community-level embeddings, which represent broader network structures. This dual-level approach allows us to incorporate both fine-grained and global perspectives, aiming to improve the robustness and accuracy of predictions.
我们的研究引入了一种使用图注意力网络 (GAT) 的分层方法来增强 DDI 预测。与以前的方法不同,我们的分层模型将捕获即时交互模式的局部嵌入与代表更广泛的网络结构的社区级嵌入相结合。这种双级方法使我们能够同时整合细粒度和全局视角,旨在提高预测的稳健性和准确性。
2. Motivation
Drug interactions can exhibit synergistic or antagonistic effects that significantly alter therapeutic outcomes. Despite substantial advances in computational techniques, many prediction models fail to generalize to unseen data, particularly when tested on drugs with novel mechanisms of action or targeting new proteins. The ogbl-ddi dataset, which represents a comprehensive drug-drug interaction network, provides a unique opportunity to explore advanced modeling techniques in this domain. Its challenging protein-target split ensures that test data involve drugs interacting with different proteins than those in the training data, simulating real-world scenarios where drugs with novel targets emerge (Min & Bae, 2017).
药物相互作用可表现出协同或拮抗作用,从而显着改变治疗结果。尽管计算技术取得了重大进步,但许多预测模型未能推广到看不见的数据,尤其是在具有新作用机制的药物或靶向新蛋白质上进行测试时。ogbl-ddi 数据集代表了一个全面的药物-药物相互作用网络,为探索该领域的高级建模技术提供了独特的机会。其具有挑战性的蛋白质-靶点分裂确保测试数据涉及药物与与训练数据中不同的蛋白质相互作用,模拟具有新靶点的药物出现的真实场景(Min & Bae,2017)。
Our hierarchical GAT model addresses these challenges by leveraging attention mechanisms to focus on relevant portions of the graph at both local and community levels. This design not only enhances interpretability but also offers insights into how drugs with disparate biological mechanisms may interact, thus contributing to a safer drug development pipeline.
我们的分层 GAT 模型通过利用注意力机制来关注本地和社区层面的图表相关部分,从而解决了这些挑战。这种设计不仅增强了可解释性,还提供了对具有不同生物机制的药物如何相互作用的见解,从而有助于更安全的药物开发管道。
3. Dataset
For this project, we utilized the ogbl-ddi dataset, a well-curated graph dataset representing the drug-drug interaction network. This dataset comprises nodes corresponding to FDA-approved or experimental drugs and edges representing interactions between these drugs. These interactions highlight cases where the combined effect of two drugs significantly deviates from their independent actions.
在这个项目中,我们使用了 ogbl-ddi 数据集,这是一个精心策划的图形数据集,代表了药物相互作用网络。该数据集包括对应于 FDA 批准或实验药物的节点和代表这些药物之间相互作用的边 。这些相互作用突出了两种药物的综合作用显着偏离其独立作用的情况。
The ogbl-ddi dataset is particularly well-suited for this study due to its homogeneous, unweighted, and undirected graph structure. The primary task is to predict interactions between drugs by leveraging known interactions, with the objective of ranking true interactions higher than negative samples.
ogbl-ddi 数据集特别适合这项研究,因为它是均匀的、未加权的和无向的图形结构 。主要任务是通过利用已知的相互作用来预测药物之间的相互作用,目的是将真实相互作用排在高于阴性样本的排名。
To evaluate the practical utility of our approach, we implemented a protein-target split for dataset splitting. This method ensures that the test set includes drugs targeting proteins significantly different from those in the training and validation sets. By adopting this split, we assess our model’s ability to predict interactions for drugs with novel biological mechanisms. Such capability is crucial for identifying breakthrough discoveries in pharmacology and paving the way for innovative treatments.
为了评估我们方法的实际效用,我们实施了蛋白质-靶标拆分以进行数据集拆分。这种方法确保测试集包含靶向蛋白质的药物,这些蛋白质与训练集和验证集中的蛋白质明显不同。通过采用这种拆分,我们评估了我们的模型预测具有新生物学机制的药物相互作用的能力。这种能力对于确定药理学的突破性发现和为创新治疗铺平道路至关重要。
图形统计
节点数目: 4,267
边数:2,135,822
分体尺寸:
训练边缘:1,067,911
验证边缘:133,489
测试边缘:133,489
边缘分割比:
Train: 80.00%
Valid: 10.00%
Test: 10.00%
4. 先前的工作
The paper “Can GNNs Learn Link Heuristics” by Shuming Liang et al. investigates the effectiveness of GNNs in learning structural information, specifically in the case of link prediction tasks. Although structural identification is not the primary task of link prediction, encapsulating such information is important and would help performance. Their paper questions the ability of GNN aggregation methods in capturing more nuanced and complex structural information and attempts to alleviate this problem by explicitly passing in features that measure certain structural properties.
Shuming Liang 等人的论文“GNNs Can Learn Link Heuristics”研究了 GNN 在学习结构信息方面的有效性,特别是在链接预测任务的情况下。尽管结构识别不是链路预测的主要任务,但封装此类信息很重要,并且有助于性能。他们的论文质疑 GNN 聚合方法捕获更细微和复杂的结构信息的能力,并试图通过显式传递测量某些结构特性的特征来缓解这个问题。
One of the key heuristics in Liang’s paper is the common neighbors metric. The common neighbors metric looks at the sets of neighbors between two entities and if the sets have a non-zero intersection then the two nodes have a common neighbors. In their paper, they run several ablations studies via mean aggregation and graph attention aggregation methods to show that standard GNNs cannot accurately determine whether or not two nodes share a common neighbor. The importance of the common neighbor is further amplified by the fact that drug interactions often occur in multi-hop relations.
Liang 论文中的关键启发式方法之一是公共邻居度量 。公共邻居指标查看两个实体之间的邻居集,如果这些集合具有非零交集,则两个节点具有公共邻居。在他们的论文中,他们通过均值聚合和图注意力聚合方法进行了多项消融研究,以表明标准 GNN 无法准确确定两个节点是否共享一个共同邻居。药物相互作用通常以多跳关系发生这一事实进一步放大了共同邻居的重要性。
The authors further emphasize that the inability of standard GNN aggregation schemes to effectively capture the number of common neighbors stems from the inherent limitations of set-based pooling operations. These aggregation methods, such as mean pooling and attention mechanisms, treat the node neighborhood as an unordered set. Consequently, they fail to encode structural properties such as the size of the intersection of neighborhoods or the presence of specific patterns like common neighbors. Liang et al. argue that this shortcoming significantly hampers the performance of GNN-based link prediction models, particularly in applications where multi-hop relations play a critical role, such as drug interaction networks.
作者进一步强调,标准 GNN 聚合方案无法有效捕获公共邻居的数量,这源于基于集合的池化作的固有局限性 。这些聚合方法(例如均值池化和注意力机制)将节点邻域视为无序集。因此,它们无法对结构属性进行编码,例如邻域交集的大小或特定模式(如共同邻域)的存在。Liang 等人认为,这个缺点严重阻碍了基于 GNN 的链接预测模型的性能,尤其是在多跳关系起关键作用的应用中,例如药物相互作用网络。
To address this limitation, the paper proposes the incorporation of explicit structural features into GNN architectures. These features are derived from traditional link prediction heuristics, such as the Common Neighbors (CN), Adamic-Adar (AA) index, and Jaccard coefficient, which quantify various aspects of the structural relationship between node pairs. By encoding these metrics as additional features or trainable embeddings, Liang et al. demonstrate that GNN-based models can better capture structural dependencies and improve link prediction performance.
为了解决这一限制,本文建议将显式结构特征整合到 GNN 架构中。这些特征源自传统的链路预测启发式方法,例如公共邻居 (CN)、Adamic-Adar (AA) 指数和 Jaccard 系数,它们量化了节点对之间结构关系的各个方面。通过将这些指标编码为附加特征或可训练嵌入,Liang 等人证明基于 GNN 的模型可以更好地捕获结构依赖关系并提高链接预测性能。
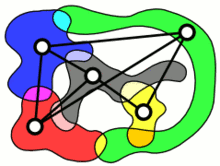
Community level structures communicating with each other
社区层面结构相互通信
In their experimental framework, Liang et al. evaluate the impact of integrating these structural features across multiple datasets with varying graph densities. Their results highlight a strong positive correlation between graph density and the benefits of incorporating structural heuristics. Specifically, on dense graphs, the inclusion of structural features, such as CN, led to significant performance improvements, validating the hypothesis that explicit structural encoding compensates for the limitations of GNN aggregation schemes.
在他们的实验框架中,Liang 等人评估了将这些结构特征整合到具有不同图形密度的多个数据集中的影响。他们的结果突出了图形密度与合并结构启发式方法的好处之间的强烈正相关。具体来说,在密集图上,包含结构特征(如 CN)导致了显著的性能改进,验证了显式结构编码补偿了 GNN 聚合方案的局限性的假设。
Additionally, the paper critiques existing methods such as SEAL and NBFNet, which are popular in the domain of link prediction. SEAL-type models rely on the classification of enclosing subgraphs and assume that GNNs can learn structural heuristics like CN implicitly. However, the findings in Liang et al.’s paper reveal that these models fail to encode structural information effectively due to the same aggregation limitations observed in standard GNNs. Similarly, NBFNet’s edge-centric approach lacks the capacity to train powerful node embeddings, limiting its performance on dense graphs.
此外,该论文还批评了 SEAL 和 NBFNet 等现有方法,这些方法在链接预测领域很流行。SEAL 类型的模型依赖于封闭子图的分类,并假设 GNN 可以隐式学习 CN 等结构启发式方法。然而,Liang 等人论文中的研究结果表明,由于在标准 GNN 中观察到的相同聚合限制,这些模型无法有效地编码结构信息。同样,NBFNet 以边缘为中心的方法缺乏训练强大节点嵌入的能力,限制了它在密集图上的性能。
The insights from Liang et al.’s work provide a strong argument for hybrid approaches that combine the strengths of traditional heuristics with the representational power of GNNs. Their findings underscore the importance of explicitly incorporating structural features into GNN-based link prediction frameworks, paving the way for more robust and interpretable models that can operate effectively across a wide range of graph structures.
Liang 等人的工作中的见解为混合方法提供了强有力的论据,这些方法将传统启发式方法的优势与 GNN 的表示能力相结合。他们的发现强调了将结构特征明确纳入基于 GNN 的链接预测框架的重要性,为更健壮和可解释的模型铺平了道路,这些模型可以在广泛的图形结构中有效运行。
5. 方法
Building on the foundational insights from the work of Liang et al. in “Can GNNs Learn Link Heuristics?”, our team sought to address the limitations of standard GNNs in capturing nuanced structural information critical for link prediction tasks. Liang et al.’s work emphasized the challenges faced by GNN aggregation methods in encoding pair-specific heuristics such as the number of common neighbors, highlighting the inherent limitations of set-based pooling operations. Inspired by their findings and the need to improve GNN performance on tasks requiring complex structural reasoning, we extended this line of research by introducing a novel hierarchical attention-based graph neural network architecture.
基于 Liang 等人在 “GNN Can Learn Link Heuristics?” 中工作的基础见解,我们的团队试图解决标准 GNN 在捕获对链接预测任务至关重要的细微结构信息方面的局限性。Liang 等人的工作强调了 GNN 聚合方法在编码特定于对的启发式方法(如公共邻居的数量)时面临的挑战,强调了基于集合的池化作的固有局限性。受到他们的发现以及在需要复杂结构推理的任务上提高 GNN 性能的需要的启发,我们通过引入一种新的基于分层注意力的图神经网络架构来扩展这一研究领域。
classHC-GAM(Predictor):
def__init__(self, args):
super().__init__(args)
# Get the actual dimension being used (from parent class logic)
dim_hidden = args.dim_in if args.dim_hidden isNoneelse args.dim_hidden
# Additional components for hierarchical model
self.text_encoder = nn.Linear(args.text_dim, args.dim_encoding)
self.relation_encoder = nn.Linear(args.relation_dim, args.dim_encoding)
# Local and Global Attention (in addition to existing ComHG layers)
self.local_attention = nn.ModuleList([
MultiHeadAttention(args.dim_encoding, args.n_heads)
for _ inrange(args.n_layers)
])
self.global_attention = nn.ModuleList([
MultiHeadAttention(args.dim_encoding, args.n_heads)
for _ inrange(args.n_layers)
])
# Community-based components
self.community_encoder = nn.Linear(args.num_communities, args.dim_encoding)
# Additional MLP for combining hierarchical features
self.hierarchical_mlp = nn.Sequential(
nn.Linear(dim_hidden * 3, dim_hidden * 2),
nn.ReLU(),
nn.Dropout(args.dropout),
nn.Linear(dim_hidden * 2, dim_hidden)
)
defforward(self, graph, edge_batch):
# Original ComHG processing
x_original = super().forward(graph, edge_batch)
# Additional hierarchical processing
ifhasattr(graph, 'text_features') andhasattr(graph, 'communities'):
# Text embedding processing
text_emb = self.text_encoder(graph.text_features)
# Local attention
local_features = text_emb
for layer in self.local_attention:
local_features = layer(local_features, graph.adj)
# Global community-based attention
community_emb = scatter_mean(text_emb, graph.communities, dim=0)
global_features = text_emb
for layer in self.global_attention:
global_features = layer(global_features, community_emb)
# Community encoding
community_features = self.community_encoder(
F.one_hot(graph.communities, num_classes=self.args.num_communities).float()
)
# Combine features
combined_features = torch.cat([
x_original,
local_features[edge_batch[:, 0]] * local_features[edge_batch[:, 1]],
global_features[edge_batch[:, 0]] * global_features[edge_batch[:, 1]]
], dim=-1)
# Final prediction combining original and hierarchical features
x = self.hierarchical_mlp(combined_features)
return torch.sigmoid(x)
# Fallback to original prediction if hierarchical features aren't available
return x_originalOur model integrates hierarchical and community-based attention mechanisms to enhance structural representation learning. While Liang et al. proposed incorporating explicit structural heuristics, we extended this approach by embedding these heuristics within a broader framework of hierarchical feature interactions. Our architecture, termed the Hierarchical Community-based Graph Attention Model (HC-GAM), was specifically designed to leverage both local and global graph structures through multi-scale attention mechanisms.
我们的模型整合了分层和基于社区的注意力机制,以增强结构性表征学习。虽然 Liang 等人提议纳入显式结构启发式方法,但我们通过将这些启发式方法嵌入到更广泛的分层特征交互框架中来扩展这种方法。我们的架构被称为基于分层社区的图注意力模型 (HC-GAM), 专门设计用于通过多尺度注意力机制利用本地和全局图结构。

A key innovation in our work lies in the use of hierarchical attention mechanisms to model interactions at multiple levels of graph organization. We incorporated community structures derived from algorithms such as the Leiden method, embedding these structural roles into the graph’s representation. Two distinct attention layers — local and global — were employed to capture fine-grained node interactions within communities and broader relational patterns across them. Local attention mechanisms focused on preserving the detailed structural relationships within neighborhoods, while global attention mechanisms captured the influence of higher-order communities, providing a comprehensive hierarchical understanding of the graph.
我们工作中的一个关键创新在于使用分层注意力机制来模拟图组织的多个级别的交互。我们整合了源自 Leiden 方法等算法的社区结构,将这些结构角色嵌入到图的表示中。采用了两个不同的注意力层——本地和全局——来捕捉社区内的细粒度节点交互以及社区之间更广泛的关系模式。局部注意力机制侧重于保留社区内的详细结构关系,而全局注意力机制则捕捉了高阶社区的影响,提供了对图的全面分层理解。

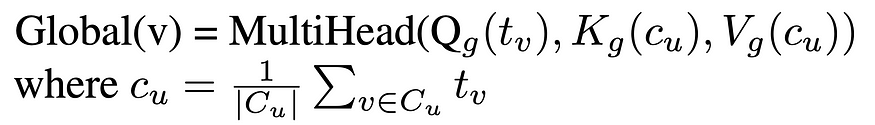

In addition to hierarchical attention, we introduced a multi-level feature fusion process that synthesizes local, global, and community-based features. This fusion was achieved through a hierarchical multi-layer perceptron (MLP), which combined original graph embeddings from extended ComHG layers, node interactions derived through local attention mechanisms, and global community-driven interactions. By integrating these components, the model effectively balances the importance of granular local features and larger-scale structural patterns, addressing a critical gap in traditional GNN designs.
除了分层关注之外,我们还引入了多级特征融合流程 ,用于综合本地、全局和基于社区的特征。这种融合是通过分层多层感知器 (MLP) 实现的,该感知器结合了来自扩展 ComHG 层的原始图形嵌入、通过本地注意力机制派生的节点交互以及全球社区驱动的交互。通过集成这些组件,该模型有效地平衡了精细局部特征和更大规模结构模式的重要性,解决了传统 GNN 设计中的关键差距。
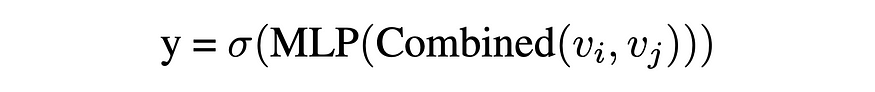
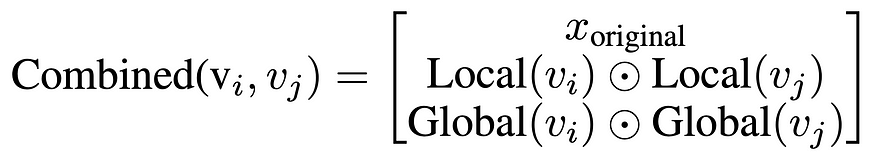

To further enhance structural learning, we adopted and extended explicit structural heuristics such as Common Neighbors (CN), Adamic-Adar, and Jaccard coefficients. These heuristics were encoded as additional trainable embeddings, complementing the learned features generated by the GNN. This integration of heuristic-based and learned features allowed the model to better capture relational properties that are vital for link prediction, particularly in dense and complex graphs.
为了进一步增强结构学习,我们采用并扩展了显式结构启发式方法,例如公邻 (CN)、Adamic-Adar 和 Jaccard 系数。这些启发式算法被编码为额外的可训练嵌入,补充了 GNN 生成的学习特征。这种基于启发式和学习特征的集成使模型能够更好地捕获对链接预测至关重要的关系属性,尤其是在密集和复杂的图形中。
Our architecture also incorporated multi-head attention mechanisms that enabled flexible and adaptive processing of node and adjacency matrix features. By employing combinatorial strategies such as concatenation and multiplication, the attention layers dynamically adapted to the graph’s structural characteristics, further improving the model’s ability to represent intricate graph relationships. This innovation, coupled with the hierarchical modeling approach, provided a significant improvement in the model’s capacity to represent long-range dependencies and higher-order graph interactions.
我们的架构还整合了多头注意力机制 ,实现了节点和邻接矩阵特征的灵活和自适应处理。通过采用串联和乘法等组合策略,注意力层动态适应图的结构特征,进一步提高了模型表示复杂图关系的能力。这项创新与分层建模方法相结合,显著提高了模型表示长距离依赖关系和高阶图交互的能力。
classMultiHeadAttention(nn.Module):
def__init__(self, dim_in, n_heads):
super().__init__()
self.n_heads = n_heads
self.dim_k = dim_in // n_heads
self.Q = nn.Linear(dim_in, dim_in)
self.K = nn.Linear(dim_in, dim_in)
self.V = nn.Linear(dim_in, dim_in)
self.out = nn.Linear(dim_in, dim_in)
defforward(self, x, adj, mask=None):
B = x.size(0)
N = x.size(0) iflen(x.size()) == 2else x.size(1)
# Reshape for multi-head attention
Q = self.Q(x).view(B, N, self.n_heads, self.dim_k)
K = self.K(x).view(B, N, self.n_heads, self.dim_k)
V = self.V(x).view(B, N, self.n_heads, self.dim_k)
# Scaled dot-product attention
scores = torch.matmul(Q, K.transpose(-2, -1)) / math.sqrt(self.dim_k)
if mask isnotNone:
scores = scores.masked_fill(mask == 0, -1e9)
# Apply attention
attention = F.softmax(scores, dim=-1)
out = torch.matmul(attention, V)
# Reshape and project output
out = out.reshape(B, N, -1)
return self.out(out)Training and testing were done using the following functions. The GPU we leveraged was NVIDIA L40S with 64G RAM.
使用以下函数完成训练和测试。我们使用的 GPU 是具有 64G RAM 的 NVIDIA L40S。
deftrain(args, predictor, optimizer, scheduler, data_pos, data_neg):
predictor.train()
running_loss = running_examples = 0
pos_edges, pos_perms = DataLoader(args, data_pos)
neg_edges, neg_perms = DataLoader(args, data_neg)
leniter = min(len(pos_perms), len(neg_perms))
for i inrange(leniter):
optimizer.zero_grad()
edge_pos = pos_edges[pos_perms[i]]
edge_neg = neg_edges[neg_perms[i]]
y_pos = predictor(data_pos, edge_pos)
y_neg = predictor(data_neg, edge_neg)
iflen(y_pos) != len(y_neg):
break
pos_loss = (-torch.log(y_pos + 1e-15)).mean()
neg_loss = (-torch.log(1.0 - y_neg + 1e-15)).mean()
loss = pos_loss + neg_loss
loss.backward()
torch.nn.utils.clip_grad_norm_(predictor.parameters(), args.clip_grad_norm)
optimizer.step()
running_loss += loss.item()
running_examples += 1
return running_loss / running_examples@torch.no_grad()
deftest(args, predictor, data_pos, data_neg):
predictor.eval()
defget_predictions(args, predictor, data_pred):
pred = []
edges = data_pred.edges
num_edge = edges.size(0)
step, end = args.batch_size * 100, num_edge
perms = [np.array(range(i, i + step)) if i + step < end else np.array(range(i, end)) for i inrange(0, end, step)]
for perm in perms:
edge_batch = edges[perm]
y = predictor(data_pred, edge_batch)
pred.append(y.detach().cpu().squeeze(1))
return torch.cat(pred, dim=0)
pred = torch.cat([get_predictions(args, predictor,data_pos), get_predictions(args, predictor,data_neg)], dim=0)
true = torch.cat([torch.ones(data_pos.edges.size(0)), torch.zeros(data_neg.edges.size(0))], dim=0)
return pred, trueOur HC-GAM demonstrated robust performance, significantly outperforming baseline methods on Hits@20. The inclusion of hierarchical attention mechanisms and multi-scale feature fusion proved instrumental in achieving these results. Ablation studies confirmed the complementary contributions of local and global attention mechanisms, as well as the critical role of heuristic embedding in enhancing predictive accuracy. The full code for the execution of the model is accessible in the Google Colab.
我们的 HC-GAM 表现出稳健的性能,在 Hits@20 上的性能明显优于基线方法。事实证明,分层注意力机制和多尺度特征融合的纳入有助于实现这些结果。消融研究证实了局部和全局注意力机制的互补作用,以及启发式嵌入在提高预测准确性方面的关键作用。执行模型的完整代码可在 Google Colab 中访问。
6. 结果
The model was trained over 1,000 epochs, achieving an final test accuracy of 96.69%, outperforming Liang et al.’s model, which reported a test accuracy of 95.49%. Utilizing 8,896,994 parameters, the model showcased efficiency and precision. For comparison, the state-of-the-art HyperFusion model employs nearly 1 billion parameters, while the second and third-ranking models leverage approximately 10 million and 5 million parameters, respectively, highlighting the balance of scalability and performance in our approach.
该模型经过 1000 多个 epoch 的训练,最终测试准确率达到 96.69%, 优于 Liang 等人的模型,后者报告的测试准确率为 95.49%。 该模型利用 8,896,994 个参数 ,展示了效率和精度。相比之下,最先进的 HyperFusion 模型使用了近 10 亿个参数 ,而排名第二和第三的模型分别使用了大约 1000 万和 500 万个参数 ,突出了我们方法中可扩展性和性能的平衡。
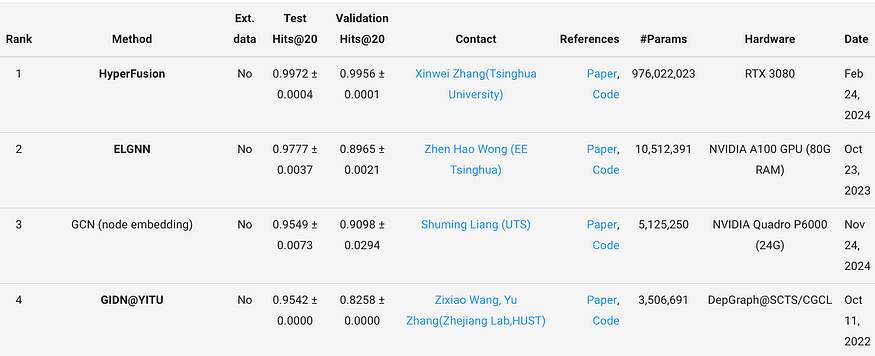
ogbl-ddi 数据集的排行榜
Our model performs better than Graph Inception Diffusion Networks (GIDN) by Wang et al., which generalizes graph diffusion across multiple feature spaces a incorporates an inception module to reduce the computational overhead caused by complex network structures. However, we perform worse than Hyperfusion by Zhang et al. and Ensemble Learning for GNNs (ELGNN) by Wong et al., which both deploy ensembles of GNNS, with Hyperfusion using a hypergraph to “fuse” outputs from various GNNs. These ensembles have many more parameters and have more diverse exploration of features than we are capable of with a single instance of our hierarchical GAT, which may explain increased accuracy.
我们的模型比 Wang 等人的 Graph Inception Diffusion Networks (GIDN) 表现更好,后者将图扩散泛化到多个特征空间,并包含一个 inception 模块来减少复杂网络结构引起的计算开销。然而,我们的表现比 Zhang 等人的 Hyperfusion 和 Wong 等人的 GNN 集成学习 (ELGNN) 差,它们都部署了 GNNS 的集成,Hyperfusion 使用超图来“融合”来自各种 GNN 的输出。这些集成具有比我们使用分层 GAT 的单个实例所能实现的更多的参数和更多样化的特征探索,这可能解释了准确性的提高。
The graph below compares the test error rates of the HC-GAM model and Liang et al.’s model over epochs.
下图比较了 HC-GAM 模型和 Liang 等人的模型在历代上的测试误差率。
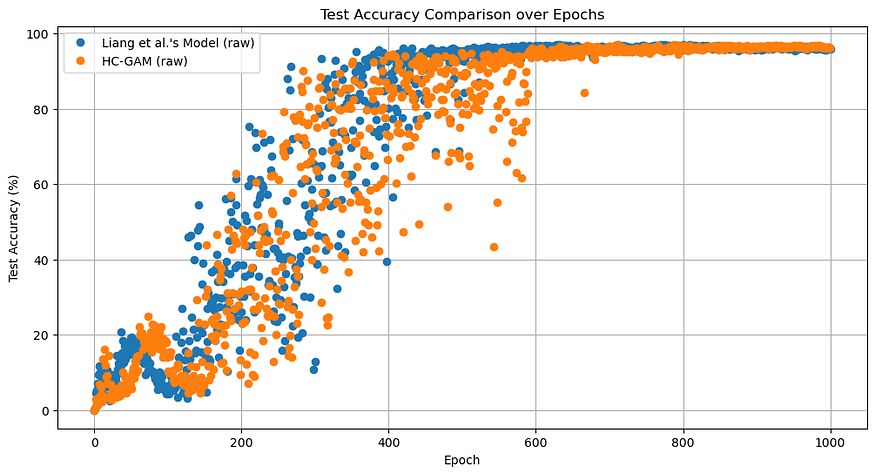
Both models consistently achieved over 90% accuracy after the 600th epoch. To facilitate a more detailed comparison, we visualized the log-scaled error rates below.
在第 600 个 epoch 之后,这两个模型始终保持超过 90% 的准确率。为了便于进行更详细的比较,我们在下面可视化了对数标度误差率。
Initially, the HC-GAM model exhibited a higher error rate, indicating lower accuracy compared to Liang et al.’s model. However, after approximately the 850th epoch, HC-GAM consistently achieved superior accuracy. To address the high variance in test accuracy observed between epochs 200–600 for both models, a moving average with a window size of 10 epochs is shown in red and green for clarity. The translucent dots in blue and orange shows the test accuracy for each epoch.
最初,HC-GAM 模型表现出较高的误差率,表明与 Liang 等人的模型相比,准确性较低。然而,在大约第 850 个纪元之后,HC-GAM 始终保持着卓越的准确度 。为了解决两种模型在 200-600 时期之间观察到的测试准确性的高差异,为清楚起见,窗口大小为 10 个时期的移动平均线以红色和绿色显示。蓝色和橙色的半透明点显示每个 epoch 的测试准确性。
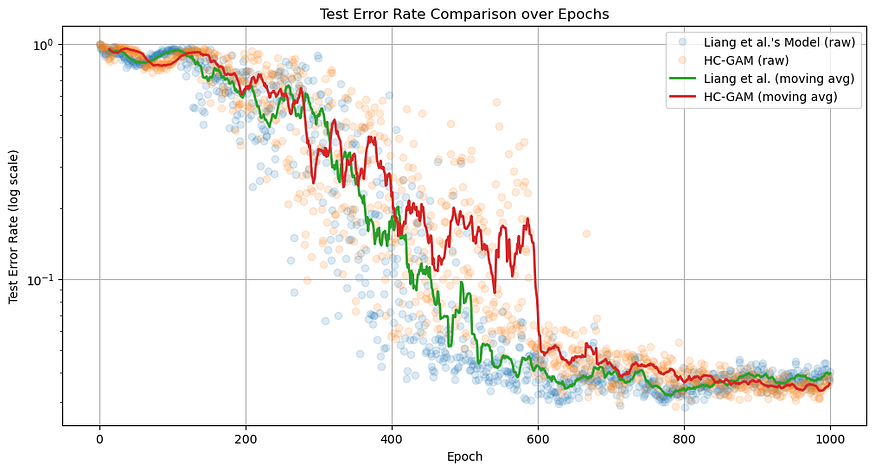
The graph highlights the effectiveness of our hierarchical attention mechanism. Additionally, given that our model utilized 1.6 times more parameters than Liang et al.’s model, it is reasonable that it required more epochs to achieve superior accuracy.
该图突出了我们的分层注意力机制的有效性。此外,鉴于我们的模型使用的参数是 Liang 等人的模型的 1.6 倍,因此需要更多的 epoch 才能获得卓越的准确性是合理的。
7. 未来的工作
The field of drug-drug interaction (DDI) prediction holds immense potential for further advancements, particularly through the integration of emerging techniques and technologies. One promising direction involves the application of pre-trained Large Language Models (LLMs) for link prediction tasks. As demonstrated in approaches like GraphGPT (Zhao et al., 2013), Next Token Prediction (NTP) can effectively encode graph structures into sequences of tokens. By leveraging such pre-trained LLMs, future research can explore their ability to predict new edges in heterogeneous graphs, potentially enhancing the capacity to capture complex relationships in networks such as those representing DDIs.
药物相互作用 (DDI) 预测领域具有进一步发展的巨大潜力,特别是通过整合新兴技术和技术。一个有前途的方向涉及将预先训练的大型语言模型 (LLM) 应用于链接预测任务。正如 GraphGPT 等方法所证明的那样(Zhao et al., 2013),Next Token Prediction (NTP) 可以有效地将图结构编码为标记序列。通过利用这种预先训练的 LLM,未来的研究可以探索它们在异构图中预测新边缘的能力,从而有可能增强在网络中捕获复杂关系的能力,例如表示 DDI 的关系。
Another critical avenue for exploration is the incorporation of multimodal data. Current graph-based models can benefit from integrating diverse data types, including chemical structures, clinical trial results, and pharmacological properties, to develop more informative node and edge representations. By combining graph embeddings with text or image embeddings from LLMs, models may achieve improved generalization across diverse datasets, enabling a broader range of applications in pharmacology.
另一个重要的探索途径是整合多模态数据。当前基于图形的模型可以从集成各种数据类型(包括化学结构、临床试验结果和药理学特性)中受益,以开发信息量更大的节点和边缘表示。通过将图形嵌入与 LLM 中的文本或图像嵌入相结合,模型可以实现跨不同数据集的改进泛化,从而在药理学中实现更广泛的应用。
Scalability and computational efficiency are also key challenges that must be addressed to extend the hierarchical GAT approach to larger-scale datasets. Implementing techniques such as subgraph sampling and scaling mechanisms, as proposed in transformer-based graph models, can allow for real-time predictions on extensive biological networks without compromising performance. In parallel, future efforts should prioritize improving biological interpretability. Beyond predictive accuracy, it is important to link model predictions to specific biological pathways or mechanisms of action, providing insights that can inform drug safety and development.
可扩展性和计算效率也是将分层 GAT 方法扩展到更大规模数据集必须解决的关键挑战。实现基于 transformer 的图模型中提出的子图采样和缩放机制等技术,可以在不影响性能的情况下对广泛的生物网络进行实时预测。同时,未来的工作应优先考虑提高生物可解释性。除了预测准确性之外,重要的是将模型预测与特定的生物途径或作用机制联系起来,从而提供可以为药物安全和开发提供信息的见解。
参考
Liang, S., Ding, Y., Li, Z., Liang, B., Zhang, S., Wang, Y., & Chen, F. (2024). Can GNNs Learn Link Heuristics? A Concise Review and Evaluation of Link Prediction Methods. arXiv preprint arXiv:2411.14711.
Cami, A., Manzi, S., Arnold, A., & Reis, B. Y. (2013). Pharmacointeraction network models predict unknown drug-drug interactions. PLoS ONE, 8(4), e61468. https://doi.org/10.1371/journal.pone.0061468
Cascorbi, I. (2012). Drug interactions. Deutsches Ärzteblatt International. https://doi.org/10.3238/arztebl.2012.0546
Link property prediction. (2024, December 4). Open Graph Benchmark. https://snap-stanford.github.io/ogb-web/docs/linkprop/
Min, J. S., & Bae, S. K. (2017). Prediction of drug–drug interaction potential using physiologically based pharmacokinetic modeling. Archives of Pharmacal Research, 40(12), 1356–1379. https://doi.org/10.1007/s12272-017-0976-0
Sun, M., Zhao, S., Gilvary, C., Elemento, O., Zhou, J., & Wang, F. (2019). Graph convolutional networks for computational drug development and discovery. Briefings in bioinformatics. https://doi.org/10.1093/bib/bbz042.
Wang, Z., Guo, Y., Zhao, J., Zhang, Y., Yu, H., Liao, X., Wang, B., & Yu, T. (2024). Gidn: A lightweight graph inception diffusion network for high-efficient link prediction (arXiv:2210.01301). arXiv. https://doi.org/10.48550/arXiv.2210.01301
Wong, Z. H., Yue, L., & Yao, Q. (2023). Ensemble learning for graph neural networks (arXiv:2310.14166). arXiv. https://doi.org/10.48550/arXiv.2310.14166
Zhang, X. (n.d.). HyperFusion/Multi_Model_Ensemble_on_Hypergraph.pdf at master · zhangxwww/HyperFusion. GitHub. Retrieved December 12, 2024, from https://github.com/zhangxwww/HyperFusion/blob/master/Multi_Model_Ensemble_on_Hypergraph.pdf
Zhao, Q., Ren, W., Li, T., Xu, X., & Liu, H. (2023). Graphgpt: Graph learning with generative pre-trained transformers (arXiv:2401.00529). arXiv. https://doi.org/10.48550/arXiv.2401.00529



内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢