

速览热门论文
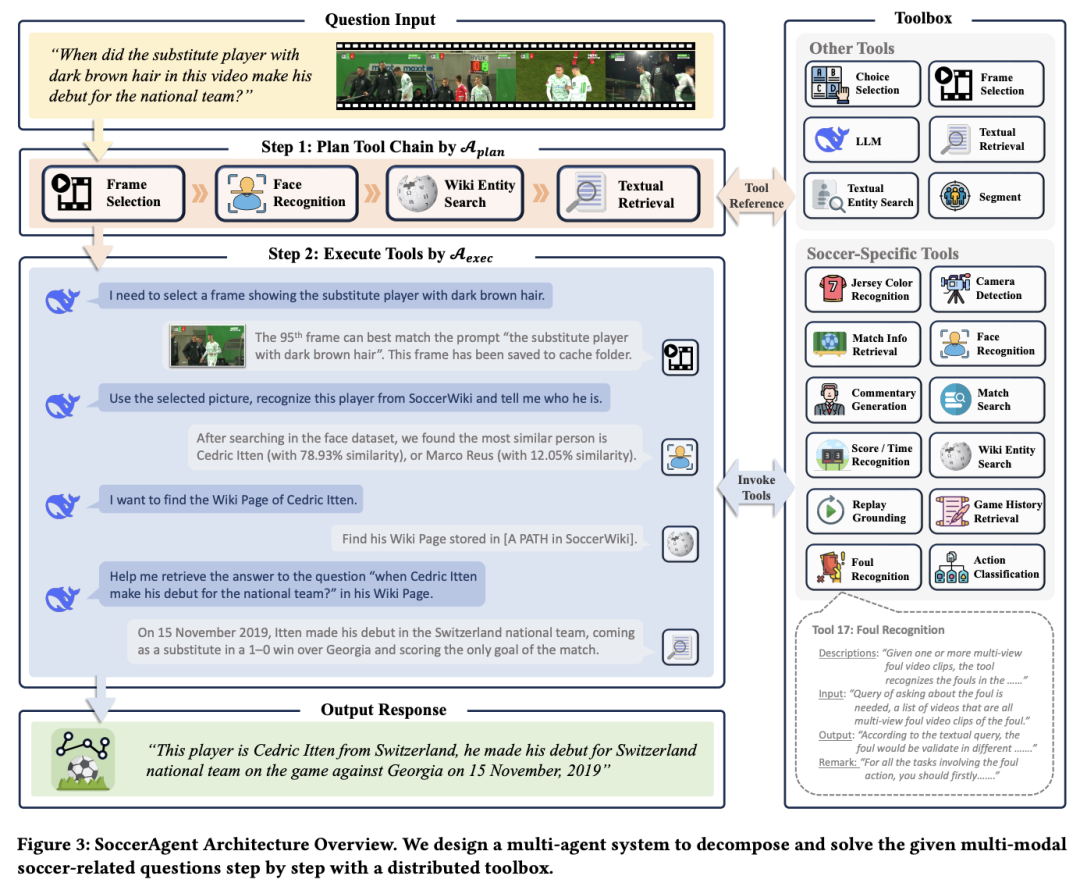
1. AI 比你懂足球!上海交大团队推出 SoccerAgent
1. AI 比你懂足球!上海交大团队推出 SoccerAgent
人工智能(AI)驱动的足球理解技术取得了快速发展,但现有研究主要集中在孤立或狭隘的任务上。为了填补这一空白,上海交通大学团队提出了一个全面的足球理解框架。
具体来说,他们做出了以下贡献:(1)构建了 SoccerWiki,这是首个大规模多模态足球知识库,整合了有关球员、球队、裁判和场地的领域知识,实现了知识驱动推理;(2)提出了 SoccerBench,这是一个规模更大、更全面的足球特定基准,通过自动管道和人工验证,在 13 个不同的理解任务中提供了约 10K 个标准化多模态(文本、图像、视频)多选 QA 对;(3)推出了 SoccerAgent,这是一个多 agent 系统,可以通过协作推理分解复杂的足球问题,利用来自 SoccerWiki 的专业领域知识,实现鲁棒的性能;(4)在 SoccerBench 上对 SOTA MLLM 进行的评估和消融,突出了 SoccerAgent 的更强性能。
论文链接:https://arxiv.org/abs/2505.03735
2. 清华黄高团队新作:“零”数据强化 AI 推理
可验证奖励强化学习(RLVR)通过直接从基于结果的奖励中学习,在增强大语言模型(LLM)的推理能力方面已显示出一定的潜力。最近的 RLVR 研究在零样本设置下进行,避免了在标注推理过程中的监督,但仍依赖于人工收集的问题和答案进行训练。人类制作的高质量示例的稀缺性引发了人们对依赖人工监督的长期可扩展性的担忧,而这一挑战在语言模型预训练领域已经较为明显。此外,在人工智能超越人类智能的假想未来,人类提供的任务可能会为超级智能系统提供有限的学习潜力。
为了解决这些问题,清华大学自动化系副教授黄高团队及其合作者提出了一个全新 RLVR 范式——Absolute Zero。在这种范式中,单个模型学会提出能够最大限度提高自身学习进度的任务,并通过解决这些任务提高推理能力,而无需依赖任何外部数据。基于此,他们还提出了 Absolute Zero Reasoner(AZR),其通过使用代码执行器验证所提出的代码推理任务和验证答案,从而自我进化其训练课程和推理能力,是一个可验证奖励的统一来源,可用于指导开放式且 grounded 的学习。

尽管 AZR 完全是在没有外部数据的情况下进行训练的,但它在编码和数学推理任务上实现了总体 SOTA 性能,超过了依赖于数以万计的域内人类编辑示例的现有零样本设置模型。此外,他们还证明了 AZR 可以有效地应用于不同规模的模型,且兼容各种模型类别。
论文链接:http://arxiv.org/abs/2505.03335
3. 20 秒生成 4 分钟音乐,阶跃星辰开源音乐生成基础模型
Ace Studio 和阶跃星辰团队提出了一个开源音乐生成基础模型 ACE-Step,它克服了现有方法的主要局限性,并通过整体架构设计实现了 SOTA 性能。
当前的方法面临着生成速度、音乐连贯性和可控性之间的固有权衡。例如,基于 LLM 的模型(如 Yue、SongGen)在抒情对齐方面表现出色,但在推理速度慢和结构缺陷方面存在问题。另一方面,扩散模型(如 DiffRhythm)尽管可以加快合成速度,但往往缺乏长程结构一致性。
ACE-Step 通过将基于扩散的生成与 Sana 的深度压缩自动编码器(DCAE)和轻量级线性 transformer 相结合,弥补了这一不足。它进一步利用 MERT 和 m-hubert,在训练过程中对齐语义表征(REPA),从而实现快速收敛。因此,ACE-Step 在 A100 GPU 上只需 20 秒就能合成长达 4 分钟的音乐,比基于 LLM 的基线快 15 倍,同时在旋律、和声和节奏指标方面实现了更好的音乐连贯性和歌词对齐。此外,ACE-Step 还保留了细粒度的声学细节,实现了高级控制机制,如声音克隆、歌词编辑、混音和音轨生成(如 lyric2vocal 和 singing2accompaniment)。
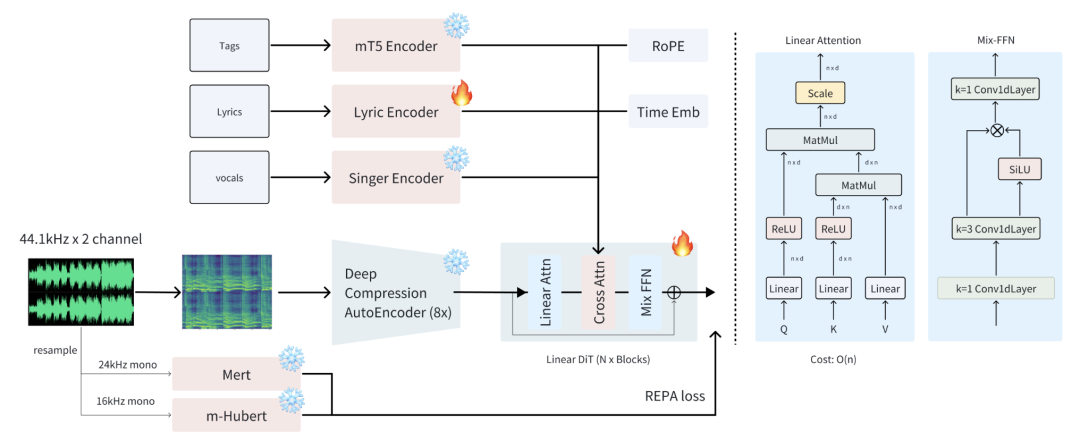
研究团队表示,他们希望为音乐人工智能建立一个基础模型,而不是建立另一个端到端文本到音乐的管道:一个快速、通用、高效而灵活的架构,使在其基础上训练子任务变得容易。
项目地址:https://ace-step.github.io/
4. 微软提出长上下文推理扩展方法 RetroInfer
大语言模型(LLM)的上下文长度不断增加,给高效推理带来了挑战,这主要是由于 GPU 内存和带宽限制造成的。
为此,微软团队提出了 RetroInfer,它将键值(KV)缓存重新概念化为矢量存储系统,利用固有的注意力稀疏性加速长上下文 LLM 推理。它的核心是波浪指数,这是一种 Attention-aWare VEctor 指数,可以通过三方注意力近似、有精度限制的注意力估计和分段聚类等技术,高效、准确地检索关键 token。作为补充,波缓冲器可协调 KV 缓存位置,并在 GPU 和 CPU 之间重叠计算和数据传输,以维持高吞吐量。
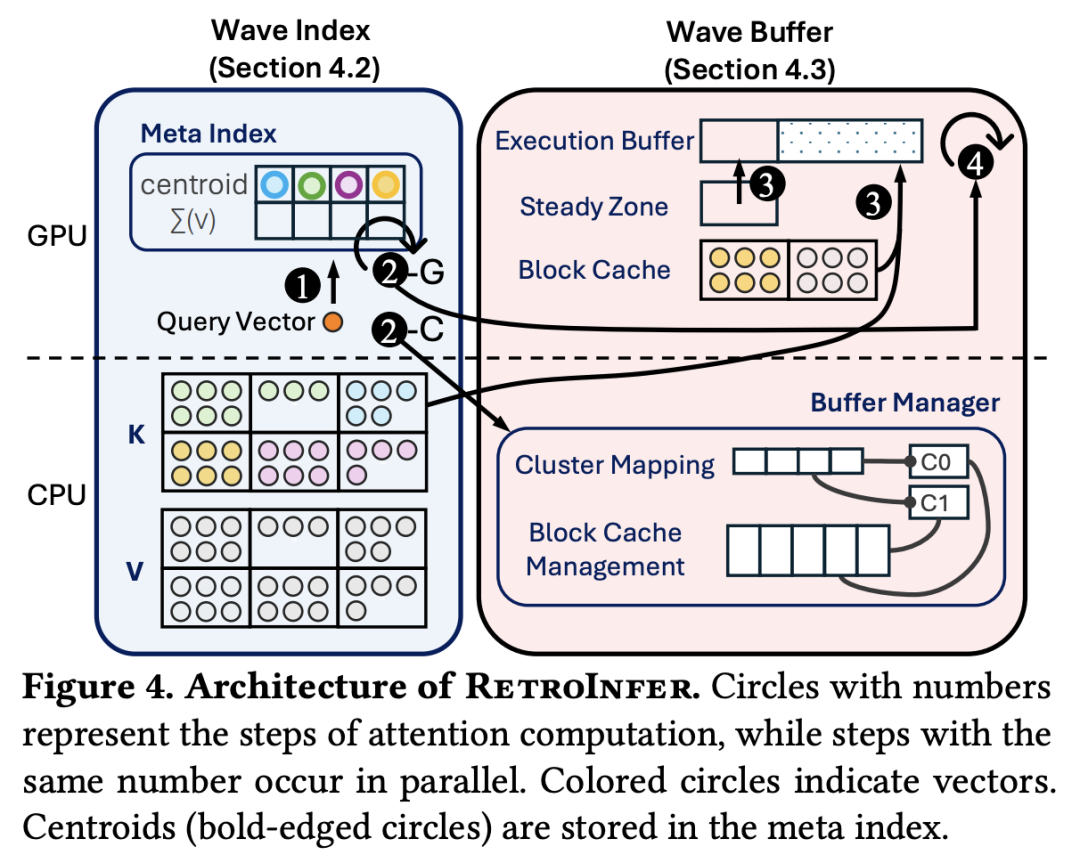
之前基于稀疏性的方法在 token 选择和硬件协调方面面临困难,与之不同的是,RetroInfer 能够在不影响模型准确性的情况下提供更优的性能。对长上下文基准的实验表明,在 GPU 内存限制范围内,与全注意力相比,速度最多可提高 4.5 倍;当 KV 缓存扩展到 CPU 内存时,与稀疏注意力基准相比,速度最多可提高 10.5 倍,同时还能保持全注意力级的准确性。
论文链接:https://arxiv.org/abs/2505.02922
5. TEMPURA:增强视觉语言模型的时间理解能力
对于视觉语言模型来说,理解视频中的因果事件关系和实现精细的时间 grounding 仍然是一项挑战。现有方法要么压缩视频 token 以降低时间分辨率,要么将视频视为未分割的流,从而模糊了细粒度的事件边界,限制了因果依赖关系的建模。
为此,来自华盛顿大学的研究团队及其合作者提出了一个两阶段训练框架——TEMPURA,其可以增强视频的时间理解能力。TEMPURA 首先从有效的填充技术中汲取灵感,应用掩码事件预测推理来重建缺失事件,并从密集的事件标注中逐步生成因果解释。然后,TEMPURA 学习执行视频分割和密集字幕,将视频分解为非重叠事件,并进行详细的时间戳对齐描述。他们在 VER 上对 TEMPURA 进行了训练,VER 是一个大型数据集,包括 100 万个训练实例和 50 万个具有时间对齐事件描述和结构化推理步骤的视频。
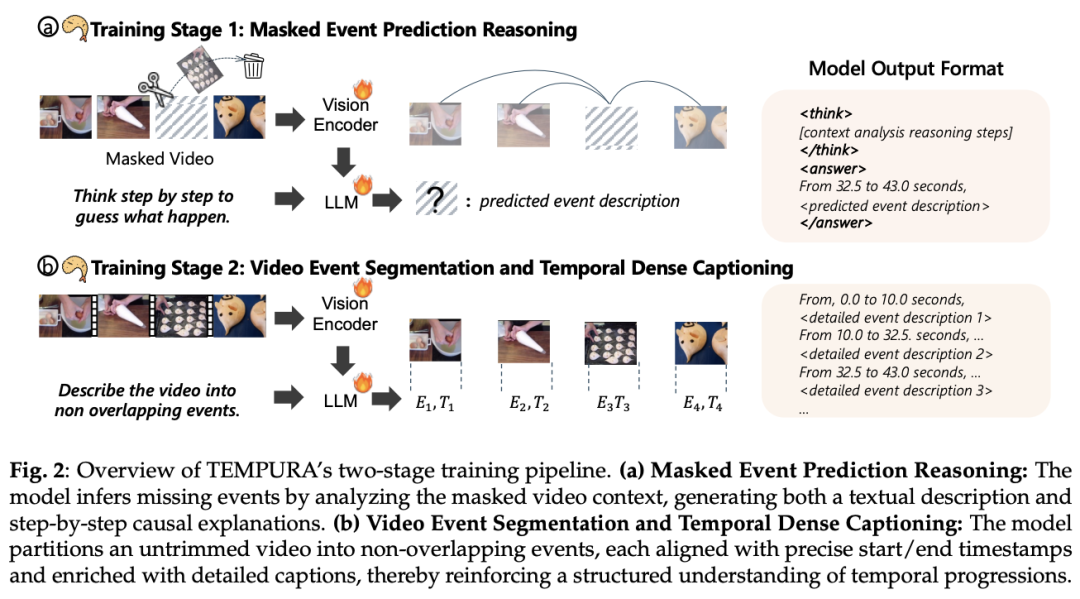
在时间 grounding 和亮点检测基准上进行的实验表明,TEMPURA 的表现优于其他基准模型,证实了结合因果推理与细粒度时间分割可以提高视频理解能力。
论文链接:https://arxiv.org/abs/2505.01583
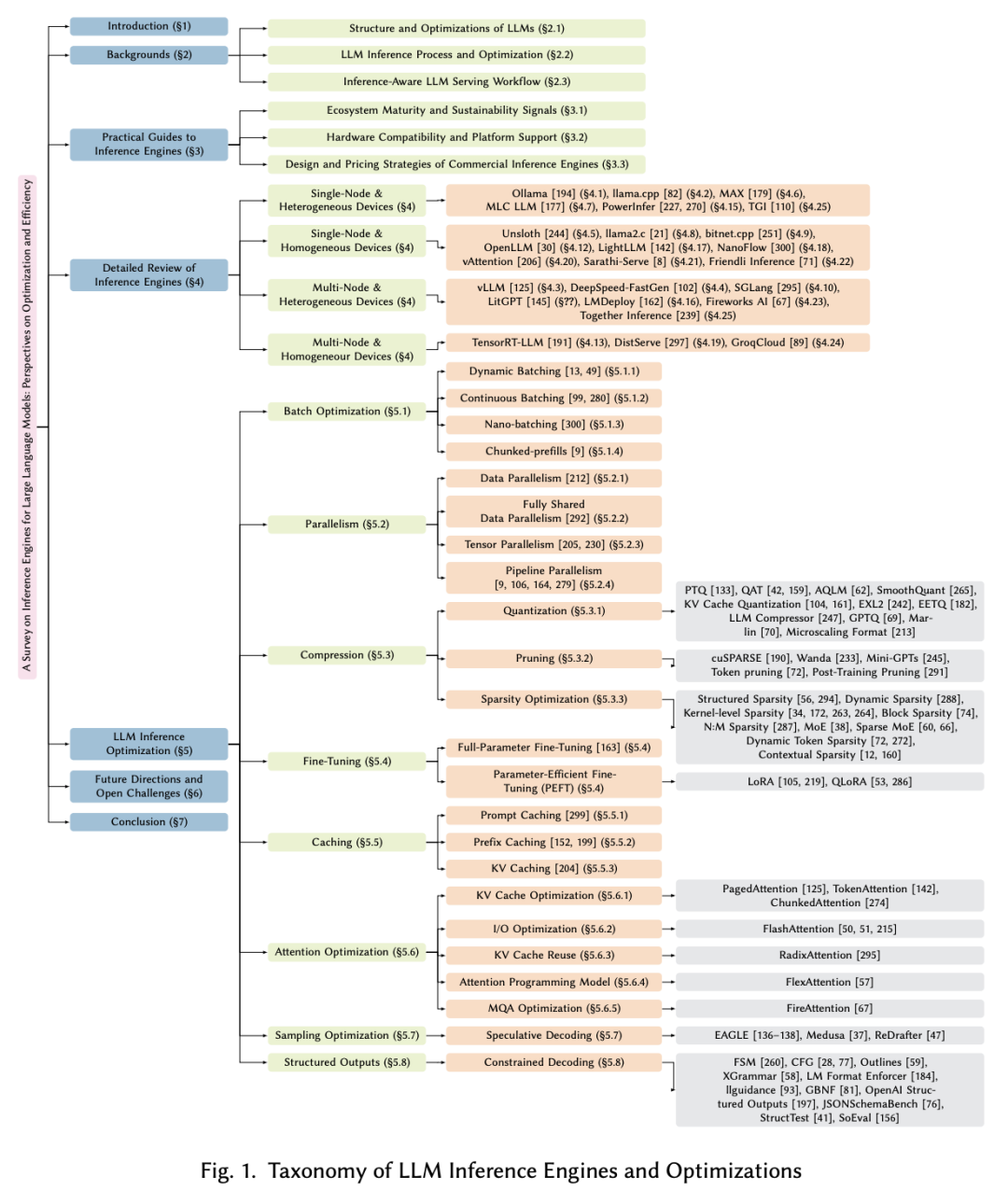
6. 综述:大语言模型推理引擎
大语言模型(LLM)被广泛应用于聊天机器人、代码生成器和搜索引擎中。思维链、复杂推理和 agent 服务等工作负载通过重复调用模型大大增加了推理成本。为了降低成本,人们采用了并行、压缩和缓存等优化方法,但由于服务需求各不相同,很难选择合适的方法。最近,专门的 LLM 推理引擎已成为将优化方法集成到面向服务的基础设施中的关键组件。然而,目前仍缺乏对推理引擎的系统研究。
为此,来自韩国电子部品研究院和韩国电子通信研究院的研究团队对 25 个开源和商业推理引擎进行了全面评估。他们从易用性、易部署性、通用支持、可扩展性以及对吞吐量和延迟感知计算的适用性等方面考察了每个推理引擎,也通过研究每个推理引擎所支持的优化技术来探索其设计目标。他们还评估了开源推理引擎生态系统的成熟度,并处理了商业解决方案的性能和成本政策。此外,他们也概述了未来的研究方向,包括支持基于 LLM 的复杂服务、支持各种硬件和增强安全性,为研究人员和开发人员选择和设计优化的 LLM 推断引擎提供指导。
论文链接:https://arxiv.org/abs/2505.01658
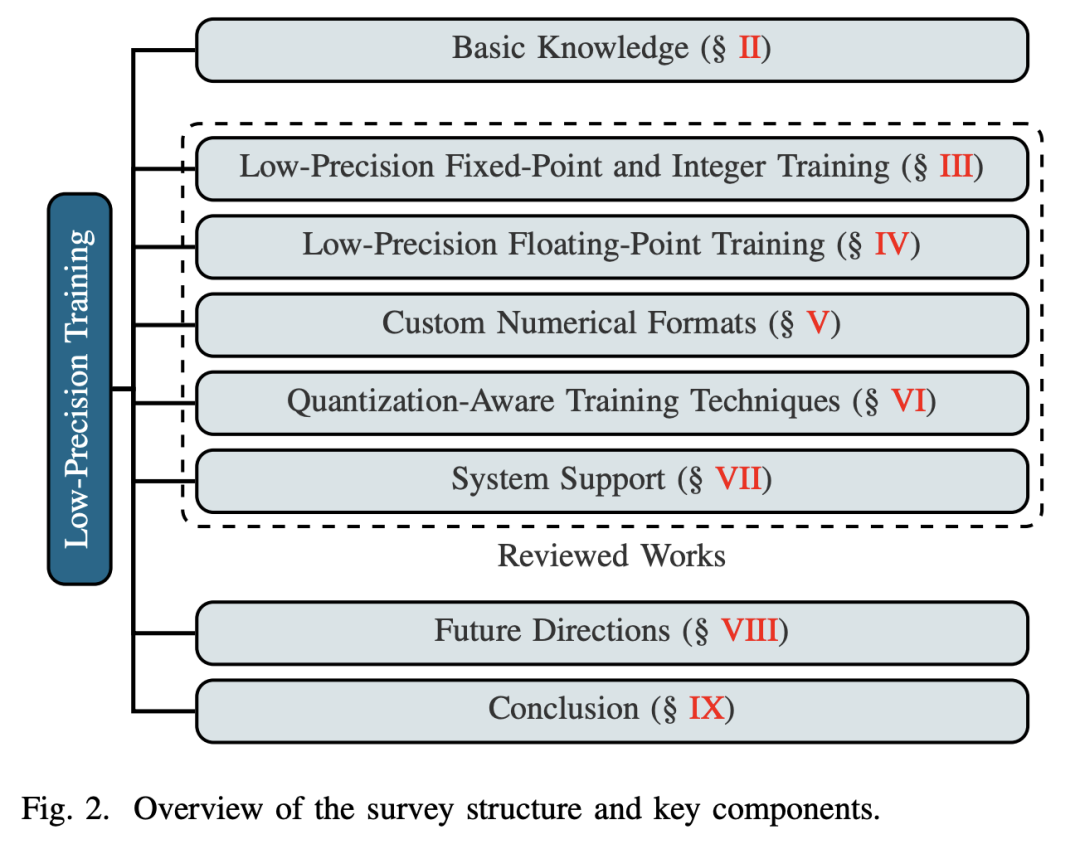
7. 综述:LLM 低精度训练方法、挑战和机遇
训练大语言模型(LLM)所需的大量硬件资源对效率和可扩展性构成了障碍。为了缓解这一挑战,低精度训练技术被广泛采用,从而提高了训练效率。然而,低精度训练涉及多个组件,如权重、激活和梯度,每个组件都可以用不同的数字格式表示。由此产生的多样性造成了低精度训练研究的碎片化,使研究人员很难对该领域有一个统一的认识。
为此,来自北京理工大学的研究团队及其合作者全面回顾了现有的低精度训练方法。为了系统地组织这些方法,他们根据其基础数值格式将其分为三个主要类别,这是影响硬件兼容性、计算效率和读者参考便利性的关键因素。这些类别是(1)基于固定点数和整数的方法,(3)基于浮点的方法,以及(3)基于自定义格式的方法。此外,他们还讨论了量化感知训练方法,这些方法与前向传播过程中的低精度训练方法有很多相似之处。最后,他们强调了几个有望推动这一领域发展的研究方向。
论文链接:https://arxiv.org/abs/2505.01043
整理:学术君
如需转载或投稿,请直接在公众号内留言

内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢